 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Reinforcement Learning with PAC and Regret Guarantees
Sep 18, 2020
Motivated by high-stakes decision-making domains like personalized medicine where user information is inherently sensitive, we design privacy preserving exploration policies for episodic reinforcement learning (RL). We first provide a meaningful privacy formulation using the notion of joint differential privacy (JDP)--a strong variant of differential privacy for settings where each user receives their own sets of output (e.g., policy recommendations). We then develop a private optimism-based learning algorithm that simultaneously achieves strong PAC and regret bounds, and enjoys a JDP guarantee. Our algorithm only pays for a moderate privacy cost on exploration: in comparison to the non-private bounds, the privacy parameter only appears in lower-order terms. Finally, we present lower bounds on sample complexity and regret for reinforcement learning subject to JDP.
Contrastive learning, multi-view redundancy, and linear models
Aug 24, 2020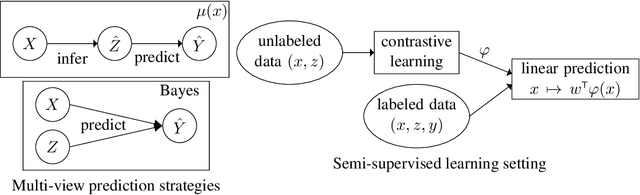
Self-supervised learning is an empirically successful approach to unsupervised learning based on creating artificial supervised learning problems. A popular self-supervised approach to representation learning is contrastive learning, which leverages naturally occurring pairs of similar and dissimilar data points, or multiple views of the same data. This work provides a theoretical analysis of contrastive learning in the multi-view setting, where two views of each datum are available. The main result is that linear functions of the learned representations are nearly optimal on downstream prediction tasks whenever the two views provide redundant information about the label.
Sample-Efficient Reinforcement Learning of Undercomplete POMDPs
Jun 22, 2020Partial observability is a common challenge in many reinforcement learning applications, which requires an agent to maintain memory, infer latent states, and integrate this past information into exploration. This challenge leads to a number of computational and statistical hardness results for learning general Partially Observable Markov Decision Processes (POMDPs). This work shows that these hardness barriers do not preclude efficient reinforcement learning for rich and interesting subclasses of POMDPs. In particular, we present a sample-efficient algorithm, OOM-UCB, for episodic finite undercomplete POMDPs, where the number of observations is larger than the number of latent states and where exploration is essential for learning, thus distinguishing our results from prior works. OOM-UCB achieves an optimal sample complexity of $O(1/\epsilon^2)$ for finding an $\epsilon$-optimal policy, along with being polynomial in all other relevant quantities. As an interesting special case, we also provide a computationally and statistically efficient algorithm for POMDPs with deterministic state transitions.
Information Theoretic Regret Bounds for Online Nonlinear Control
Jun 22, 2020
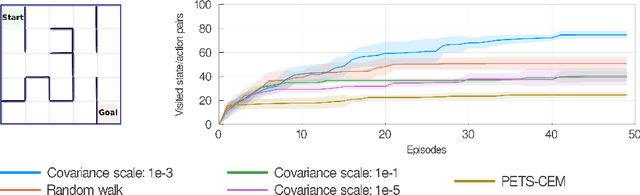
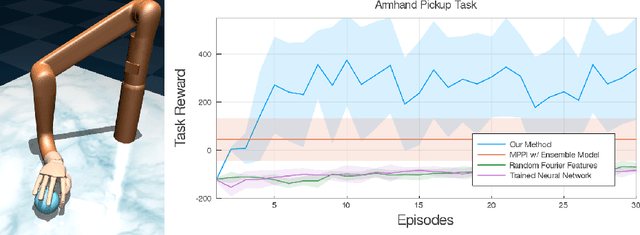
This work studies the problem of sequential control in an unknown, nonlinear dynamical system, where we model the underlying system dynamics as an unknown function in a known Reproducing Kernel Hilbert Space. This framework yields a general setting that permits discrete and continuous control inputs as well as non-smooth, non-differentiable dynamics. Our main result, the Lower Confidence-based Continuous Control ($LC^3$) algorithm, enjoys a near-optimal $O(\sqrt{T})$ regret bound against the optimal controller in episodic settings, where $T$ is the number of episodes. The bound has no explicit dependence on dimension of the system dynamics, which could be infinite, but instead only depends on information theoretic quantities. We empirically show its application to a number of nonlinear control tasks and demonstrate the benefit of exploration for learning model dynamics.
Open Problem: Model Selection for Contextual Bandits
Jun 19, 2020In statistical learning, algorithms for model selection allow the learner to adapt to the complexity of the best hypothesis class in a sequence. We ask whether similar guarantees are possible for contextual bandit learning.
Provably adaptive reinforcement learning in metric spaces
Jun 18, 2020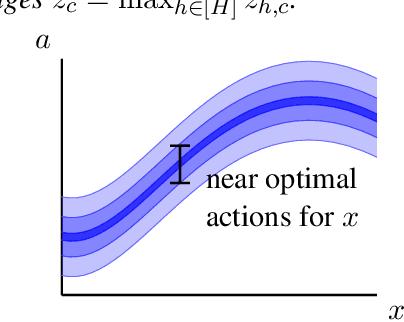
We study reinforcement learning in continuous state and action spaces endowed with a metric. We provide a refined analysis of the algorithm of Sinclair, Banerjee, and Yu (2019) and show that its regret scales with the \emph{zooming dimension} of the instance. This parameter, which originates in the bandit literature, captures the size of the subsets of near optimal actions and is always smaller than the covering dimension used in previous analyses. As such, our results are the first provably adaptive guarantees for reinforcement learning in metric spaces.
FLAMBE: Structural Complexity and Representation Learning of Low Rank MDPs
Jun 18, 2020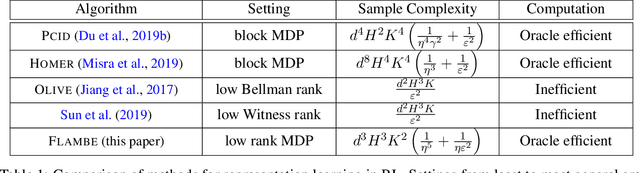
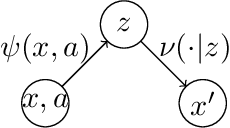

In order to deal with the curse of dimensionality in reinforcement learning (RL), it is common practice to make parametric assumptions where values or policies are functions of some low dimensional feature space. This work focuses on the representation learning question: how can we learn such features? Under the assumption that the underlying (unknown) dynamics correspond to a low rank transition matrix, we show how the representation learning question is related to a particular non-linear matrix decomposition problem. Structurally, we make precise connections between these low rank MDPs and latent variable models, showing how they significantly generalize prior formulations for representation learning in RL. Algorithmically, we develop FLAMBE, which engages in exploration and representation learning for provably efficient RL in low rank transition models.
Efficient Contextual Bandits with Continuous Actions
Jun 10, 2020
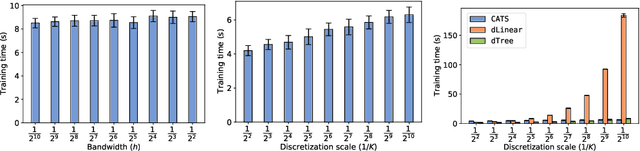
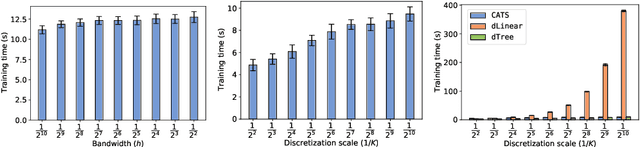
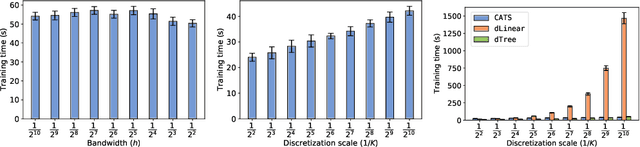
We create a computationally tractable algorithm for contextual bandits with continuous actions having unknown structure. Our reduction-style algorithm composes with most supervised learning representations. We prove that it works in a general sense and verify the new functionality with large-scale experiments.
Contrastive estimation reveals topic posterior information to linear models
Mar 04, 2020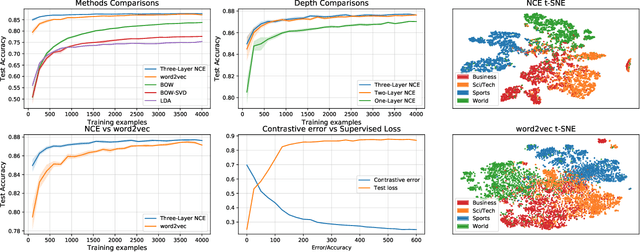
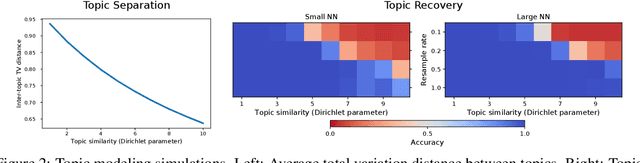
Contrastive learning is an approach to representation learning that utilizes naturally occurring similar and dissimilar pairs of data points to find useful embeddings of data. In the context of document classification under topic modeling assumptions, we prove that contrastive learning is capable of recovering a representation of documents that reveals their underlying topic posterior information to linear models. We apply this procedure in a semi-supervised setup and demonstrate empirically that linear classifiers with these representations perform well in document classification tasks with very few training examples.
Corrupted Multidimensional Binary Search: Learning in the Presence of Irrational Agents
Feb 27, 2020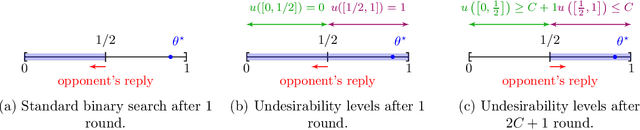
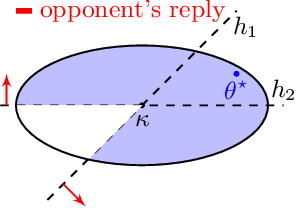
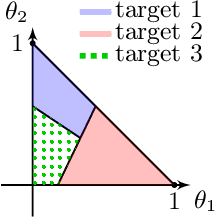
Standard game-theoretic formulations for settings like contextual pricing and security games assume that agents act in accordance with a specific behavioral model. In practice however, some agents may not prescribe to the dominant behavioral model or may act in ways that are arbitrarily inconsistent. Existing algorithms heavily depend on the model being (approximately) accurate for all agents and have poor performance in the presence of even a few such arbitrarily irrational agents. How do we design learning algorithms that are robust to the presence of arbitrarily irrational agents? We address this question for a number of canonical game-theoretic applications by designing a robust algorithm for the fundamental problem of multidimensional binary search. The performance of our algorithm degrades gracefully with the number of corrupted rounds, which correspond to irrational agents and need not be known in advance. As binary search is the key primitive in algorithms for contextual pricing, Stackelberg Security Games, and other game-theoretic applications, we immediately obtain robust algorithms for these settings. Our techniques draw inspiration from learning theory, game theory, high-dimensional geometry, and convex analysis, and may be of independent algorithmic interest.