 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale High-Quality 3D Gaussian Head Reconstruction from Multi-View Captures
May 05, 2026We propose HeadsUp, a scalable feed-forward method for reconstructing high-quality 3D Gaussian heads from large-scale multi-camera setups. Our method employs an efficient encoder-decoder architecture that compresses input views into a compact latent representation. This latent representation is then decoded into a set of UV-parameterized 3D Gaussians anchored to a neutral head template. This UV representation decouples the number of 3D Gaussians from the number and resolution of input images, enabling training with many high-resolution input views. We train and evaluate our model on an internal dataset with more than 10,000 subjects, which is an order of magnitude larger than existing multi-view human head datasets. HeadsUp achieves state-of-the-art reconstruction quality and generalizes to novel identities without test-time optimization. We extensively analyze the scaling behavior of our model across identities, views, and model capacity, revealing practical insights for quality-compute trade-offs. Finally, we highlight the strength of our latent space by showcasing two downstream applications: generating novel 3D identities and animating the 3D heads with expression blendshapes.
Modality Dropout for Improved Performance-driven Talking Faces
May 27, 2020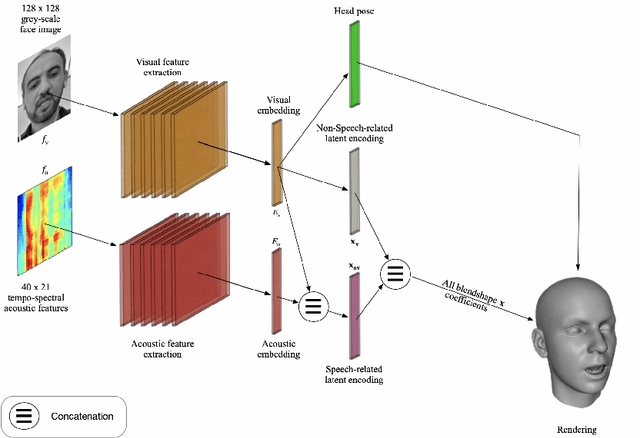
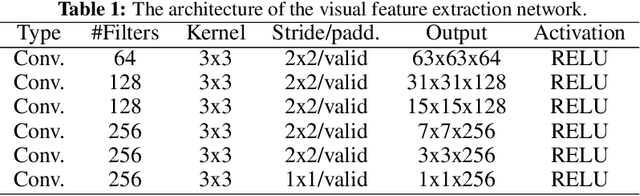
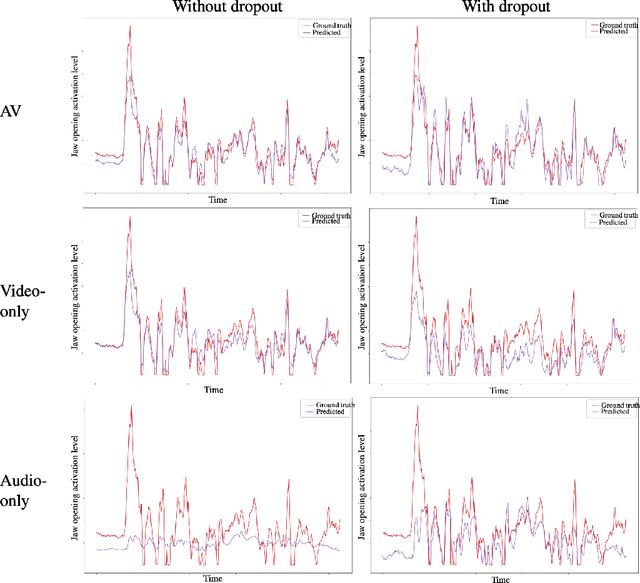

We describe our novel deep learning approach for driving animated faces using both acoustic and visual information. In particular, speech-related facial movements are generated using audiovisual information, and non-speech facial movements are generated using only visual information. To ensure that our model exploits both modalities during training, batches are generated that contain audio-only, video-only, and audiovisual input features. The probability of dropping a modality allows control over the degree to which the model exploits audio and visual information during training. Our trained model runs in real-time on resource limited hardware (e.g.\ a smart phone), it is user agnostic, and it is not dependent on a potentially error-prone transcription of the speech. We use subjective testing to demonstrate: 1) the improvement of audiovisual-driven animation over the equivalent video-only approach, and 2) the improvement in the animation of speech-related facial movements after introducing modality dropout. Before introducing dropout, viewers prefer audiovisual-driven animation in 51% of the test sequences compared with only 18% for video-driven. After introducing dropout viewer preference for audiovisual-driven animation increases to 74%, but decreases to 8% for video-only.