 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Visual Models From Natural Language Supervision
Feb 26, 2021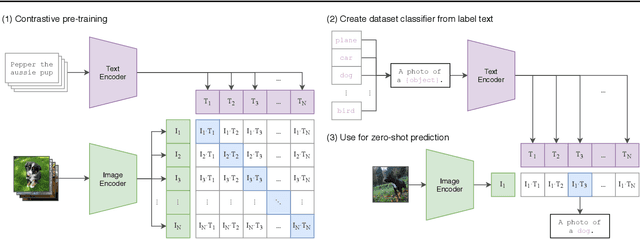
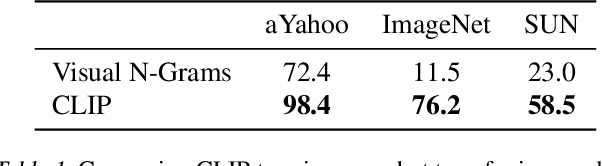
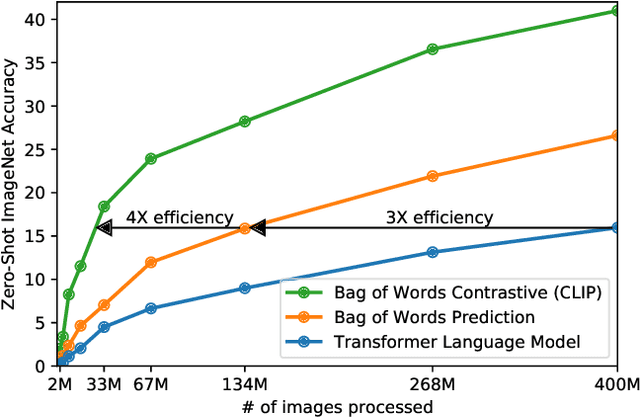
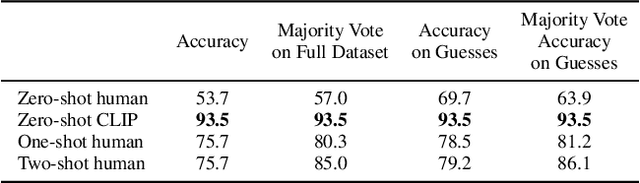
State-of-the-art computer vision systems are trained to predict a fixed set of predetermined object categories. This restricted form of supervision limits their generality and usability since additional labeled data is needed to specify any other visual concept. Learning directly from raw text about images is a promising alternative which leverages a much broader source of supervision. We demonstrate that the simple pre-training task of predicting which caption goes with which image is an efficient and scalable way to learn SOTA image representations from scratch on a dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones) enabling zero-shot transfer of the model to downstream tasks. We study the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. The model transfers non-trivially to most tasks and is often competitive with a fully supervised baseline without the need for any dataset specific training. For instance, we match the accuracy of the original ResNet-50 on ImageNet zero-shot without needing to use any of the 1.28 million training examples it was trained on. We release our code and pre-trained model weights at https://github.com/OpenAI/CLIP.
Scaling Laws for Autoregressive Generative Modeling
Nov 06, 2020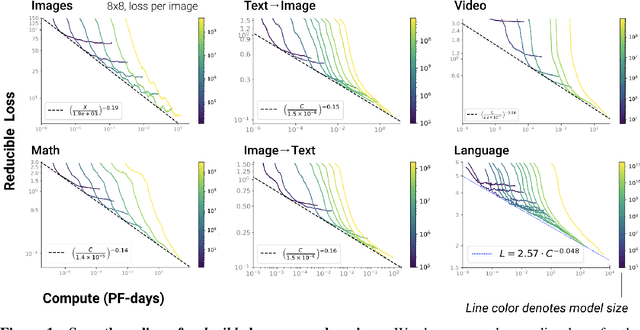
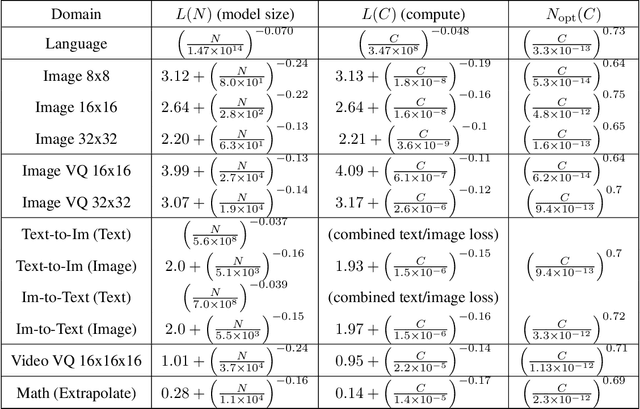
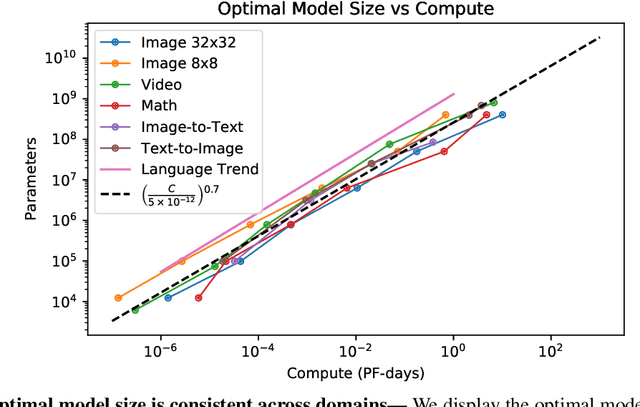

We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image$\leftrightarrow$text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains. The cross-entropy loss has an information theoretic interpretation as $S($True$) + D_{\mathrm{KL}}($True$||$Model$)$, and the empirical scaling laws suggest a prediction for both the true data distribution's entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an $8\times 8$ resolution, and we can forecast the model size needed to achieve any given reducible loss (ie $D_{\mathrm{KL}}$) in nats/image for other resolutions. We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question "Is a picture worth a thousand words?"; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.
Recurrent Neural-Linear Posterior Sampling for Non-Stationary Contextual Bandits
Jul 09, 2020



An agent in a non-stationary contextual bandit problem should balance between exploration and the exploitation of (periodic or structured) patterns present in its previous experiences. Handcrafting an appropriate historical context is an attractive alternative to transform a non-stationary problem into a stationary problem that can be solved efficiently. However, even a carefully designed historical context may introduce spurious relationships or lack a convenient representation of crucial information. In order to address these issues, we propose an approach that learns to represent the relevant context for a decision based solely on the raw history of interactions between the agent and the environment. This approach relies on a combination of features extracted by recurrent neural networks with a contextual linear bandit algorithm based on posterior sampling. Our experiments on a diverse selection of contextual and non-contextual non-stationary problems show that our recurrent approach consistently outperforms its feedforward counterpart, which requires handcrafted historical contexts, while being more widely applicable than conventional non-stationary bandit algorithms.
CompressNet: Generative Compression at Extremely Low Bitrates
Jun 14, 2020
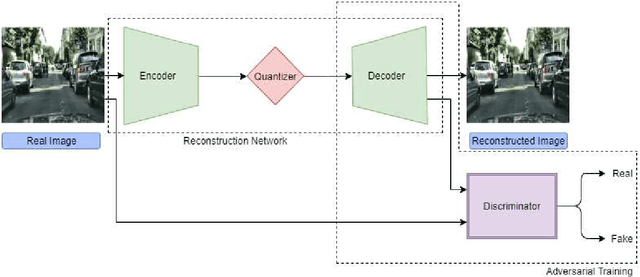
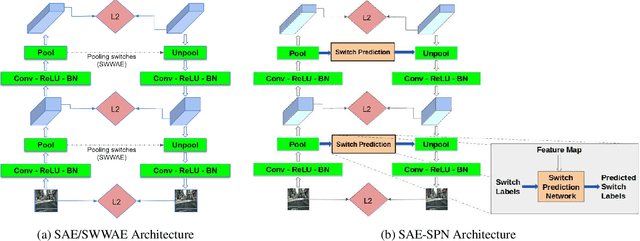

Compressing images at extremely low bitrates (< 0.1 bpp) has always been a challenging task since the quality of reconstruction significantly reduces due to the strong imposed constraint on the number of bits allocated for the compressed data. With the increasing need to transfer large amounts of images with limited bandwidth, compressing images to very low sizes is a crucial task. However, the existing methods are not effective at extremely low bitrates. To address this need, we propose a novel network called CompressNet which augments a Stacked Autoencoder with a Switch Prediction Network (SAE-SPN). This helps in the reconstruction of visually pleasing images at these low bitrates (< 0.1 bpp). We benchmark the performance of our proposed method on the Cityscapes dataset, evaluating over different metrics at extremely low bitrates to show that our method outperforms the other state-of-the-art. In particular, at a bitrate of 0.07, CompressNet achieves 22% lower Perceptual Loss and 55% lower Frechet Inception Distance (FID) compared to the deep learning SOTA methods.
Language Models are Few-Shot Learners
Jun 05, 2020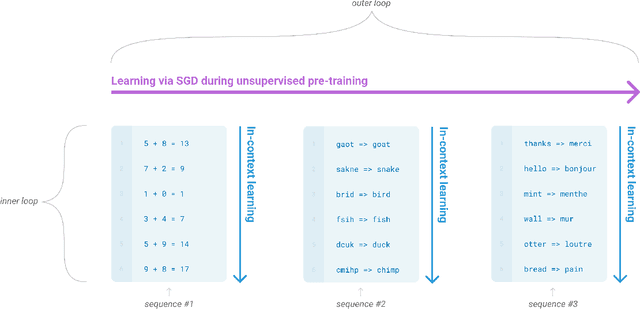
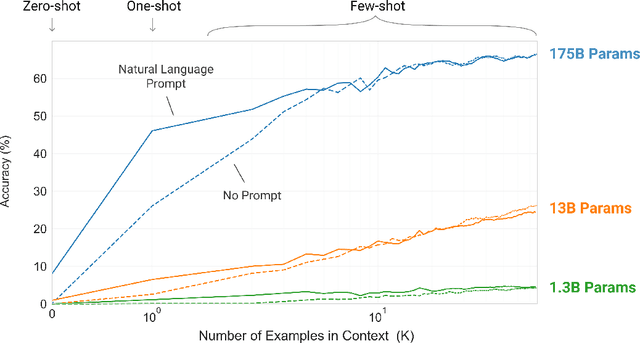
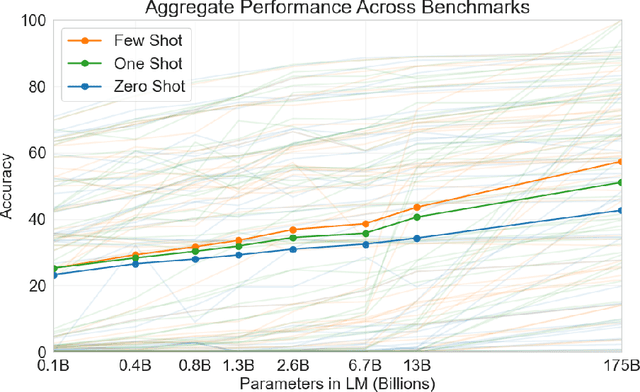
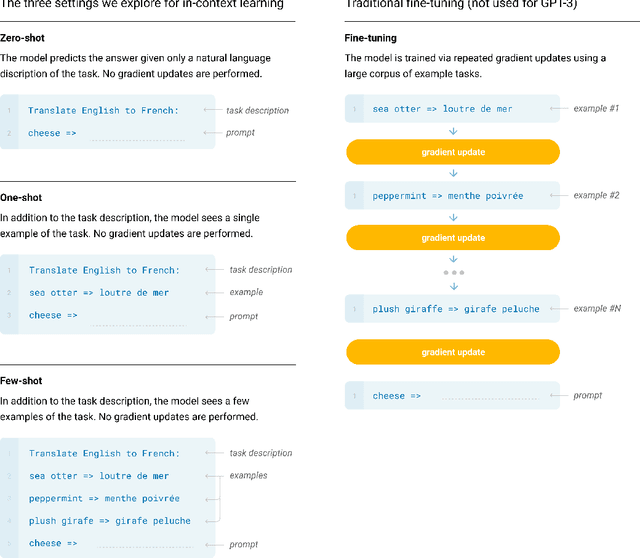
Recent work has demonstrated substantial gains on many NLP tasks and benchmarks by pre-training on a large corpus of text followed by fine-tuning on a specific task. While typically task-agnostic in architecture, this method still requires task-specific fine-tuning datasets of thousands or tens of thousands of examples. By contrast, humans can generally perform a new language task from only a few examples or from simple instructions - something which current NLP systems still largely struggle to do. Here we show that scaling up language models greatly improves task-agnostic, few-shot performance, sometimes even reaching competitiveness with prior state-of-the-art fine-tuning approaches. Specifically, we train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting. For all tasks, GPT-3 is applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model. GPT-3 achieves strong performance on many NLP datasets, including translation, question-answering, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic. At the same time, we also identify some datasets where GPT-3's few-shot learning still struggles, as well as some datasets where GPT-3 faces methodological issues related to training on large web corpora. Finally, we find that GPT-3 can generate samples of news articles which human evaluators have difficulty distinguishing from articles written by humans. We discuss broader societal impacts of this finding and of GPT-3 in general.
Clustering of Driving Encounter Scenarios Using Connected Vehicle Trajectories
Mar 16, 2019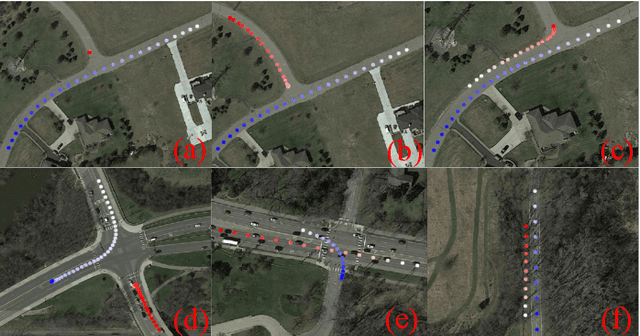
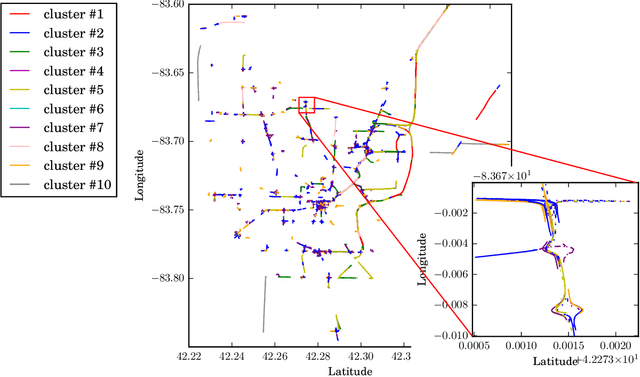
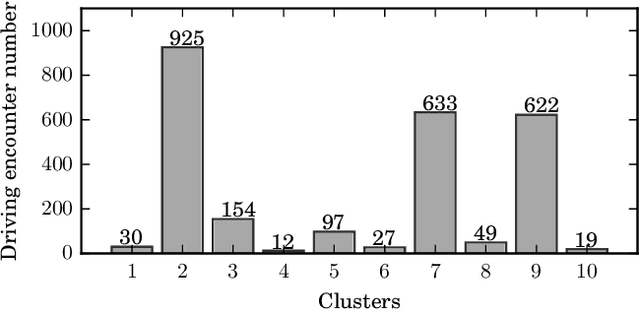
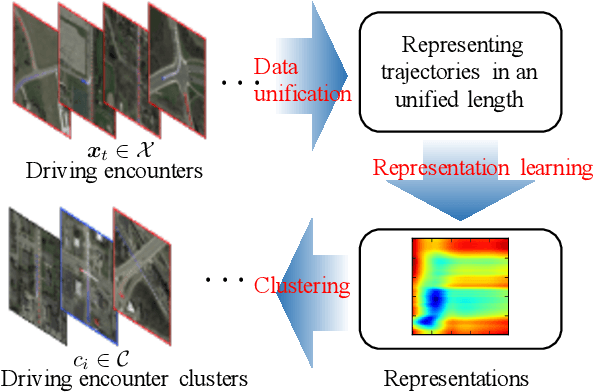
Multi-vehicle interaction behavior classification and analysis offer in-depth knowledge to make an efficient decision for autonomous vehicles. This paper aims to cluster a wide range of driving encounter scenarios based only on multi-vehicle GPS trajectories. Towards this end, we propose a generic unsupervised learning framework comprising two layers: feature representation layer and clustering layer. In the layer of feature representation, we combine the deep autoencoders with a distance-based measure to map the sequential observations of driving encounters into a computationally tractable space that allows quantifying the spatiotemporal interaction characteristics of two vehicles. The clustering algorithm is then applied to the extracted representations to gather homogeneous driving encounters into groups. Our proposed generic framework is then evaluated using 2,568 naturalistic driving encounters. Experimental results demonstrate that our proposed generic framework incorporated with unsupervised learning can cluster multi-trajectory data into distinct groups. These clustering results could benefit decision-making policy analysis and design for autonomous vehicles.
A Spectral Regularizer for Unsupervised Disentanglement
Dec 04, 2018
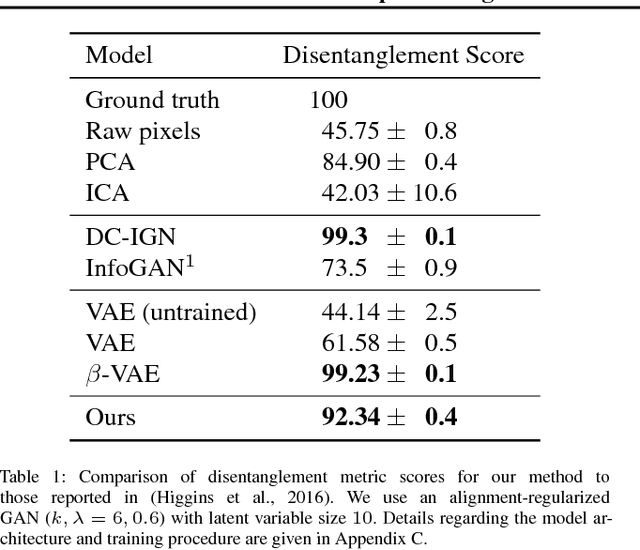
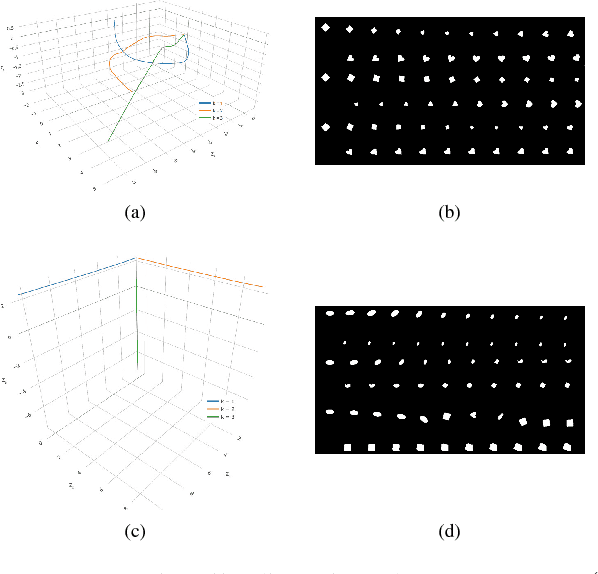

Generative models that learn to associate variations in the output along isolated attributes with coordinate directions in latent space are said to possess disentangled representations. This has been a recent topic of great interest, but remains poorly understood. We show that even for GANs that do not possess disentangled representations, one can find paths in latent space over which local disentanglement occurs. These paths are determined by the leading right-singular vectors of the Jacobian of the generator with respect to its input. We describe an efficient regularizer that aligns these vectors with the coordinate axes, and show that it can be used to induce high-quality, disentangled representations in GANs, in a completely unsupervised manner.
Backpropagation for Implicit Spectral Densities
Jun 01, 2018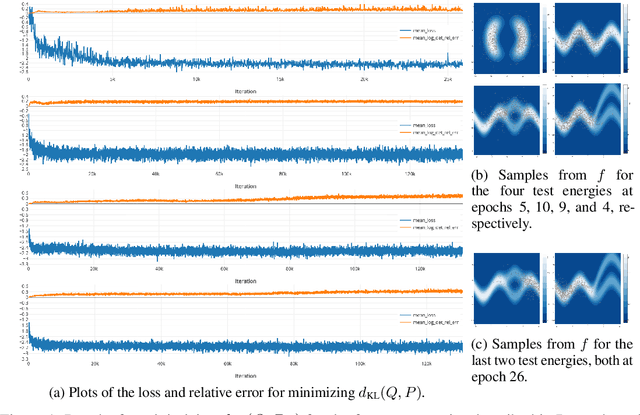
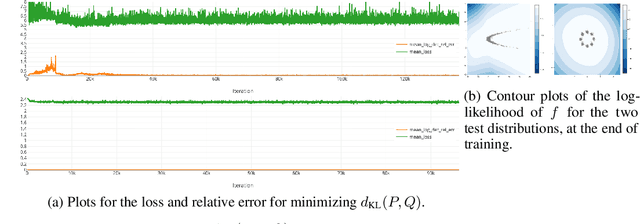


Most successful machine intelligence systems rely on gradient-based learning, which is made possible by backpropagation. Some systems are designed to aid us in interpreting data when explicit goals cannot be provided. These unsupervised systems are commonly trained by backpropagating through a likelihood function. We introduce a tool that allows us to do this even when the likelihood is not explicitly set, by instead using the implicit likelihood of the model. Explicitly defining the likelihood often entails making heavy-handed assumptions that impede our ability to solve challenging tasks. On the other hand, the implicit likelihood of the model is accessible without the need for such assumptions. Our tool, which we call spectral backpropagation, allows us to optimize it in much greater generality than what has been attempted before. GANs can also be viewed as a technique for optimizing implicit likelihoods. We study them using spectral backpropagation in order to demonstrate robustness for high-dimensional problems, and identify two novel properties of the generator G: (1) there exist aberrant, nonsensical outputs to which G assigns very high likelihood, and (2) the eigenvectors of the metric induced by G over latent space correspond to quasi-disentangled explanatory factors.
Disentangling factors of variation in deep representations using adversarial training
Nov 10, 2016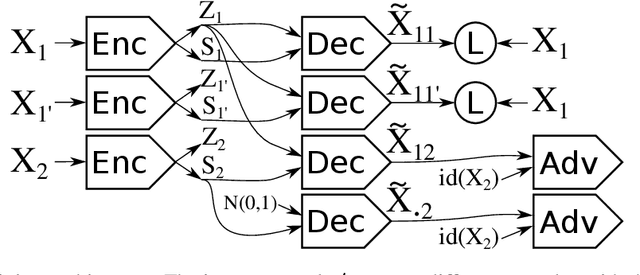



We introduce a conditional generative model for learning to disentangle the hidden factors of variation within a set of labeled observations, and separate them into complementary codes. One code summarizes the specified factors of variation associated with the labels. The other summarizes the remaining unspecified variability. During training, the only available source of supervision comes from our ability to distinguish among different observations belonging to the same class. Examples of such observations include images of a set of labeled objects captured at different viewpoints, or recordings of set of speakers dictating multiple phrases. In both instances, the intra-class diversity is the source of the unspecified factors of variation: each object is observed at multiple viewpoints, and each speaker dictates multiple phrases. Learning to disentangle the specified factors from the unspecified ones becomes easier when strong supervision is possible. Suppose that during training, we have access to pairs of images, where each pair shows two different objects captured from the same viewpoint. This source of alignment allows us to solve our task using existing methods. However, labels for the unspecified factors are usually unavailable in realistic scenarios where data acquisition is not strictly controlled. We address the problem of disentanglement in this more general setting by combining deep convolutional autoencoders with a form of adversarial training. Both factors of variation are implicitly captured in the organization of the learned embedding space, and can be used for solving single-image analogies. Experimental results on synthetic and real datasets show that the proposed method is capable of generalizing to unseen classes and intra-class variabilities.