 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of State Aliasing in Structured Prediction with RNNs
Jun 21, 2019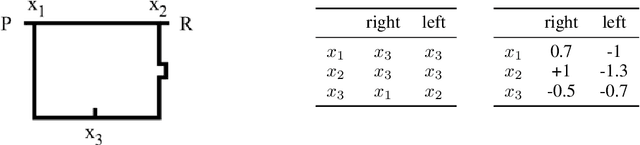
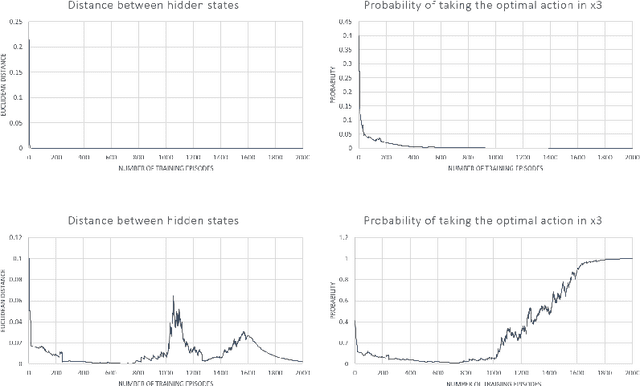
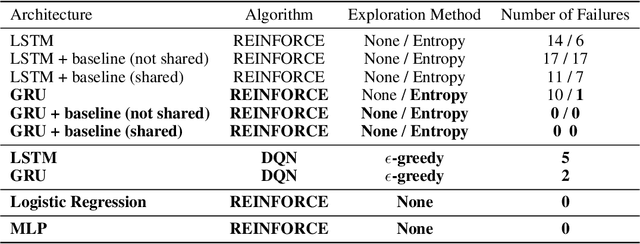
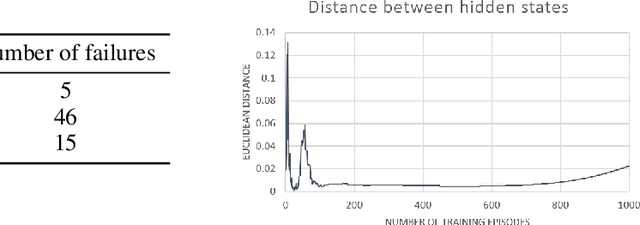
End-to-end reinforcement learning agents learn a state representation and a policy at the same time. Recurrent neural networks (RNNs) have been trained successfully as reinforcement learning agents in settings like dialogue that require structured prediction. In this paper, we investigate the representations learned by RNN-based agents when trained with both policy gradient and value-based methods. We show through extensive experiments and analysis that, when trained with policy gradient, recurrent neural networks often fail to learn a state representation that leads to an optimal policy in settings where the same action should be taken at different states. To explain this failure, we highlight the problem of state aliasing, which entails conflating two or more distinct states in the representation space. We demonstrate that state aliasing occurs when several states share the same optimal action and the agent is trained via policy gradient. We characterize this phenomenon through experiments on a simple maze setting and a more complex text-based game, and make recommendations for training RNNs with reinforcement learning.
An Empirical Study of Example Forgetting during Deep Neural Network Learning
Dec 12, 2018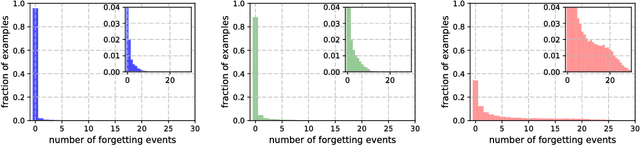

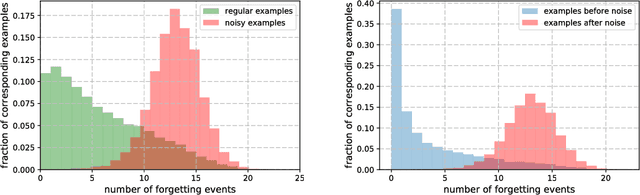
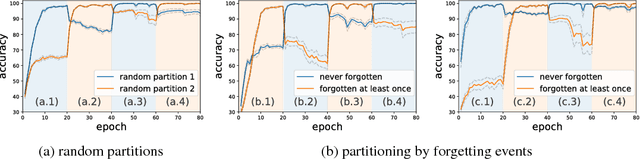
Inspired by the phenomenon of catastrophic forgetting, we investigate the learning dynamics of neural networks as they train on single classification tasks. Our goal is to understand whether a related phenomenon occurs when data does not undergo a clear distributional shift. We define a `forgetting event' to have occurred when an individual training example transitions from being classified correctly to incorrectly over the course of learning. Across several benchmark data sets, we find that: (i) certain examples are forgotten with high frequency, and some not at all; (ii) a data set's (un)forgettable examples generalize across neural architectures; and (iii) based on forgetting dynamics, a significant fraction of examples can be omitted from the training data set while still maintaining state-of-the-art generalization performance.
On the Evaluation of Common-Sense Reasoning in Natural Language Understanding
Nov 05, 2018
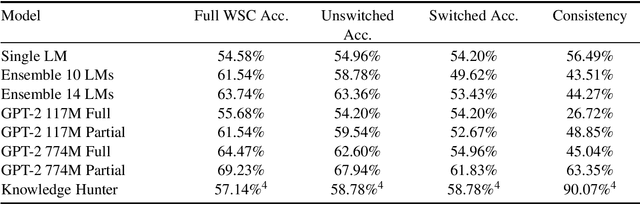
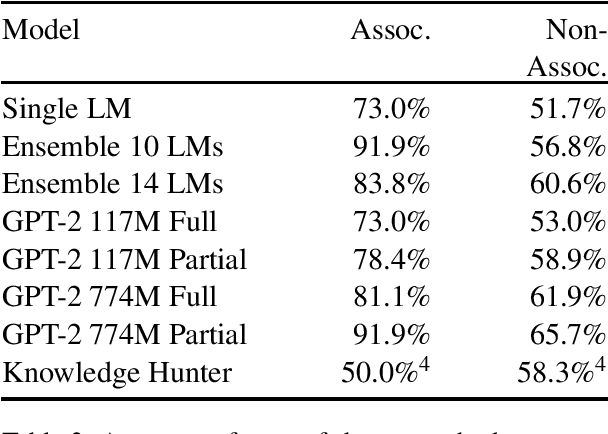
The NLP and ML communities have long been interested in developing models capable of common-sense reasoning, and recent works have significantly improved the state of the art on benchmarks like the Winograd Schema Challenge (WSC). Despite these advances, the complexity of tasks designed to test common-sense reasoning remains under-analyzed. In this paper, we make a case study of the Winograd Schema Challenge and, based on two new measures of instance-level complexity, design a protocol that both clarifies and qualifies the results of previous work. Our protocol accounts for the WSC's limited size and variable instance difficulty, properties common to other common-sense benchmarks. Accounting for these properties when assessing model results may prevent unjustified conclusions.
The Hard-CoRe Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution
Nov 02, 2018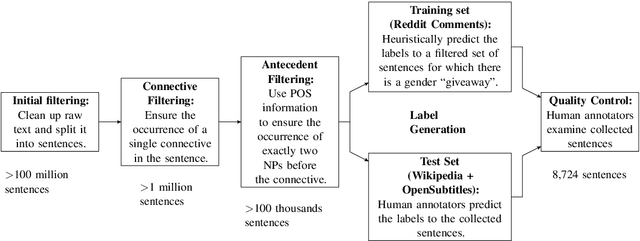
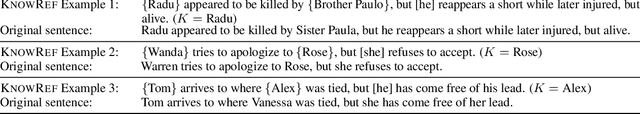

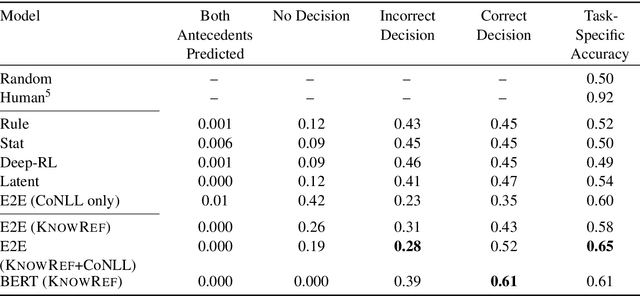
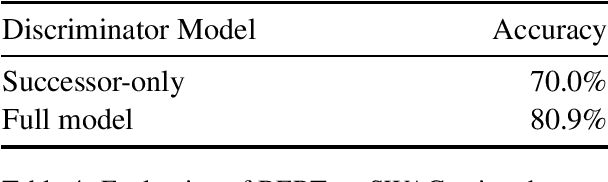
We introduce a new benchmark task for coreference resolution, Hard-CoRe, that targets common-sense reasoning and world knowledge. Previous coreference resolution tasks have been overly vulnerable to systems that simply exploit the number and gender of the antecedents, or have been handcrafted and do not reflect the diversity of sentences in naturally occurring text. With these limitations in mind, we present a resolution task that is both challenging and realistic. We demonstrate that various coreference systems, whether rule-based, feature-rich, graphical, or neural-based, perform at random or slightly above-random on the task, whereas human performance is very strong with high inter-annotator agreement. To explain this performance gap, we show empirically that state-of-the art models often fail to capture context and rely only on the antecedents to make a decision.
Building Dynamic Knowledge Graphs from Text using Machine Reading Comprehension
Oct 12, 2018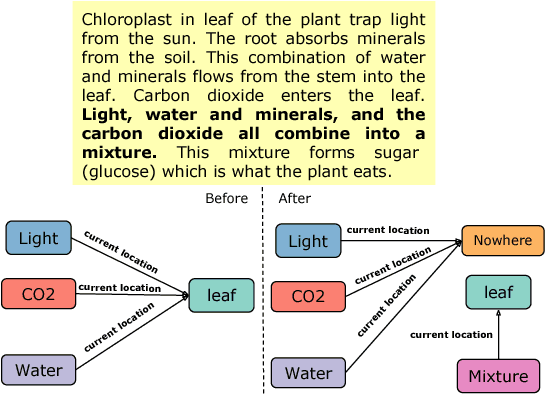

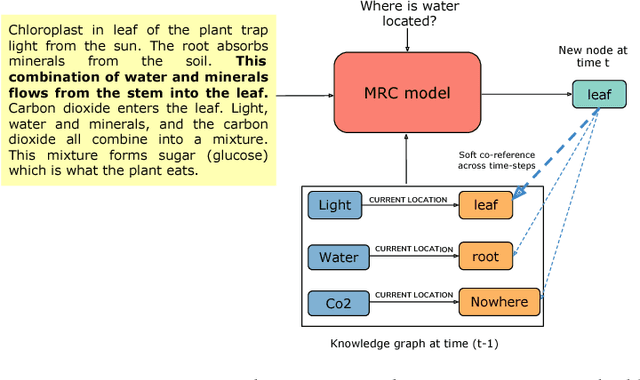
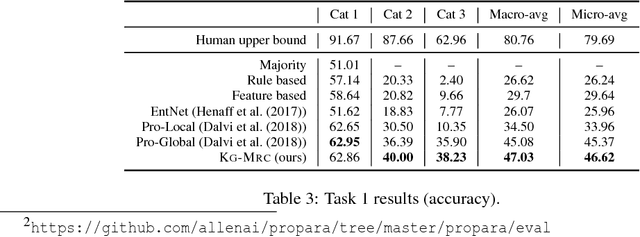
We propose a neural machine-reading model that constructs dynamic knowledge graphs from procedural text. It builds these graphs recurrently for each step of the described procedure, and uses them to track the evolving states of participant entities. We harness and extend a recently proposed machine reading comprehension (MRC) model to query for entity states, since these states are generally communicated in spans of text and MRC models perform well in extracting entity-centric spans. The explicit, structured, and evolving knowledge graph representations that our model constructs can be used in downstream question answering tasks to improve machine comprehension of text, as we demonstrate empirically. On two comprehension tasks from the recently proposed PROPARA dataset (Dalvi et al., 2018), our model achieves state-of-the-art results. We further show that our model is competitive on the RECIPES dataset (Kiddon et al., 2015), suggesting it may be generally applicable. We present some evidence that the model's knowledge graphs help it to impose commonsense constraints on its predictions.
Generating Diverse Numbers of Diverse Keyphrases
Oct 11, 2018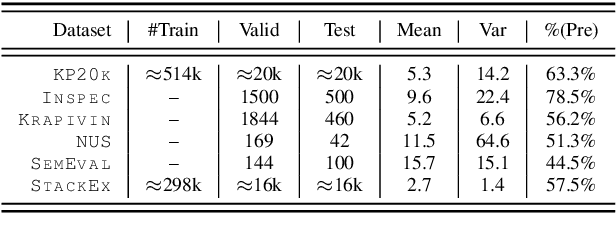
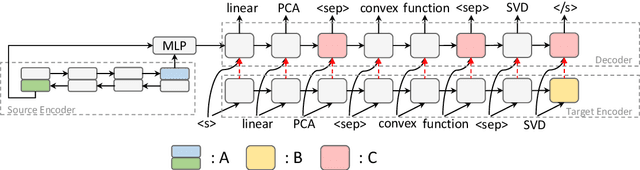
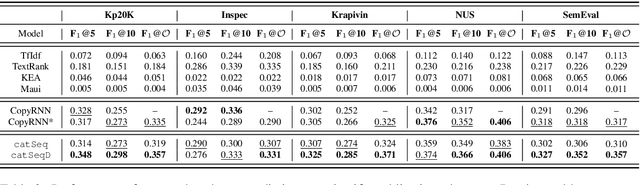
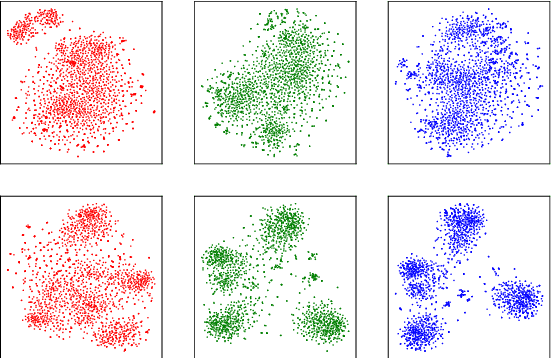
Existing keyphrase generation studies suffer from the problems of generating duplicate phrases and deficient evaluation based on a fixed number of predicted phrases. We propose a recurrent generative model that generates multiple keyphrases sequentially from a text, with specific modules that promote generation diversity. We further propose two new metrics that consider a variable number of phrases. With both existing and proposed evaluation setups, our model demonstrates superior performance to baselines on three types of keyphrase generation datasets, including two newly introduced in this work: StackExchange and TextWorld ACG. In contrast to previous keyphrase generation approaches, our model generates sets of diverse keyphrases of a variable number.
Learning deep representations by mutual information estimation and maximization
Oct 03, 2018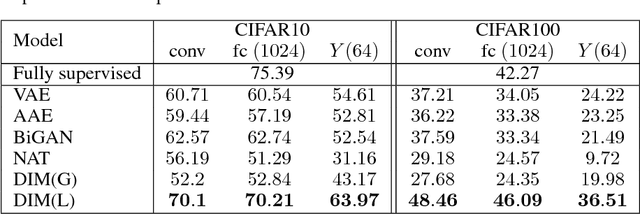
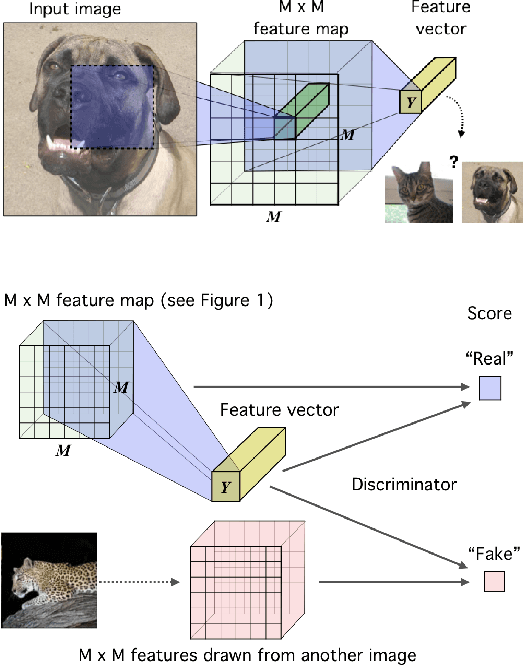
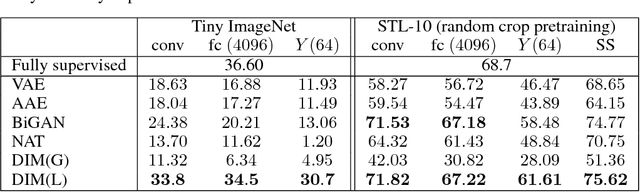
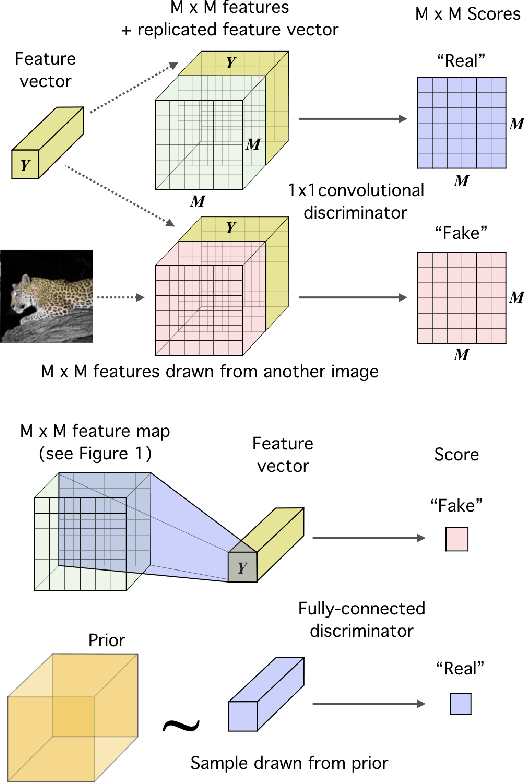
In this work, we perform unsupervised learning of representations by maximizing mutual information between an input and the output of a deep neural network encoder. Importantly, we show that structure matters: incorporating knowledge about locality of the input to the objective can greatly influence a representation's suitability for downstream tasks. We further control characteristics of the representation by matching to a prior distribution adversarially. Our method, which we call Deep InfoMax (DIM), outperforms a number of popular unsupervised learning methods and competes with fully-supervised learning on several classification tasks. DIM opens new avenues for unsupervised learning of representations and is an important step towards flexible formulations of representation-learning objectives for specific end-goals.
A Knowledge Hunting Framework for Common Sense Reasoning
Oct 02, 2018
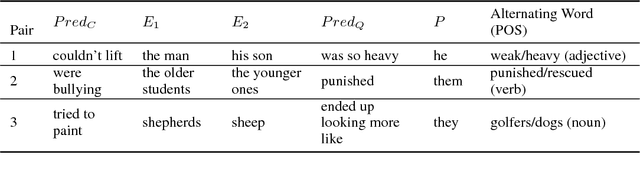

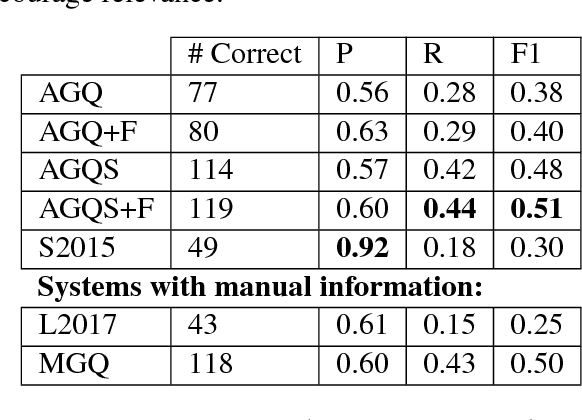
We introduce an automatic system that achieves state-of-the-art results on the Winograd Schema Challenge (WSC), a common sense reasoning task that requires diverse, complex forms of inference and knowledge. Our method uses a knowledge hunting module to gather text from the web, which serves as evidence for candidate problem resolutions. Given an input problem, our system generates relevant queries to send to a search engine, then extracts and classifies knowledge from the returned results and weighs them to make a resolution. Our approach improves F1 performance on the full WSC by 0.21 over the previous best and represents the first system to exceed 0.5 F1. We further demonstrate that the approach is competitive on the Choice of Plausible Alternatives (COPA) task, which suggests that it is generally applicable.
Metalearning with Hebbian Fast Weights
Jul 12, 2018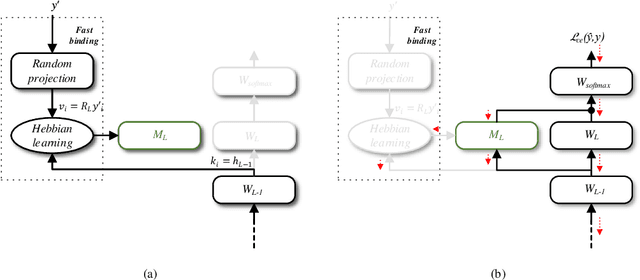
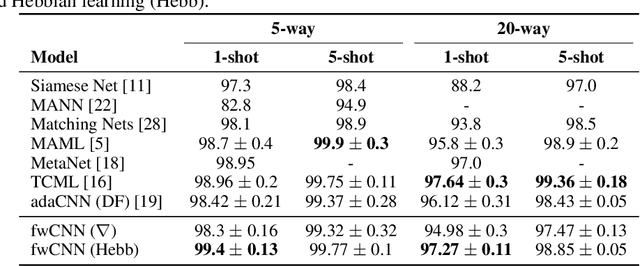
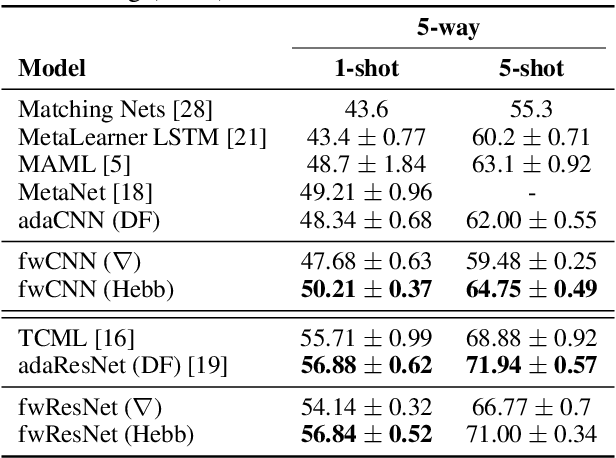
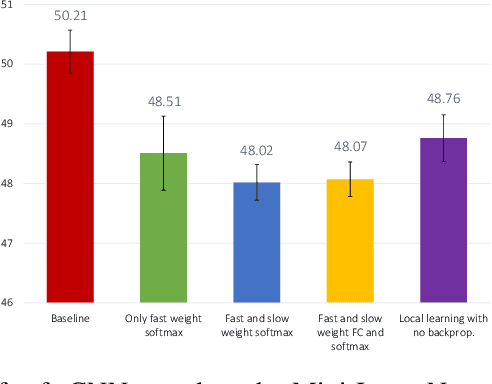
We unify recent neural approaches to one-shot learning with older ideas of associative memory in a model for metalearning. Our model learns jointly to represent data and to bind class labels to representations in a single shot. It builds representations via slow weights, learned across tasks through SGD, while fast weights constructed by a Hebbian learning rule implement one-shot binding for each new task. On the Omniglot, Mini-ImageNet, and Penn Treebank one-shot learning benchmarks, our model achieves state-of-the-art results.
Rapid Adaptation with Conditionally Shifted Neurons
Jul 03, 2018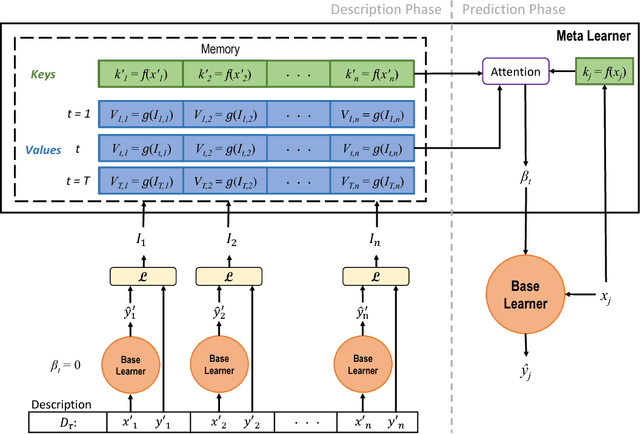
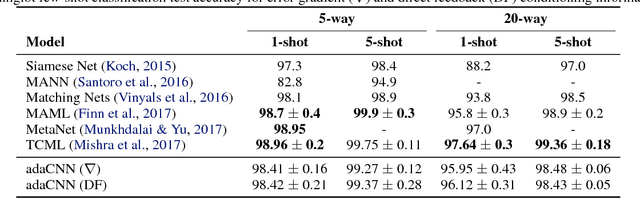
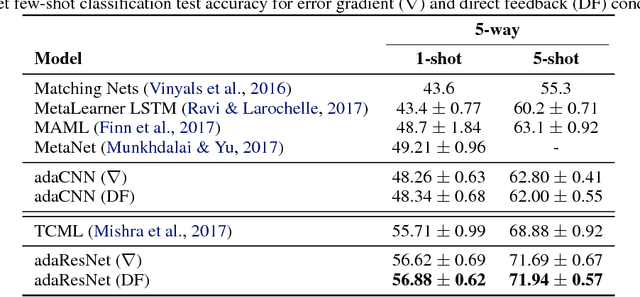
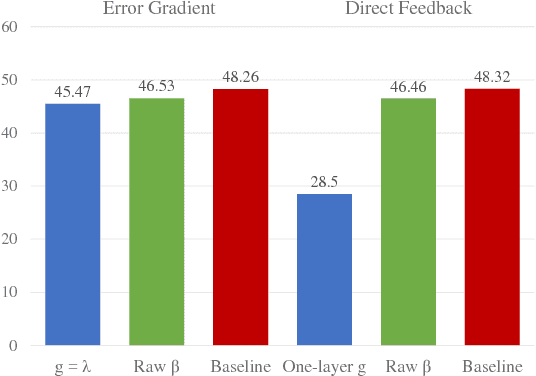
We describe a mechanism by which artificial neural networks can learn rapid adaptation - the ability to adapt on the fly, with little data, to new tasks - that we call conditionally shifted neurons. We apply this mechanism in the framework of metalearning, where the aim is to replicate some of the flexibility of human learning in machines. Conditionally shifted neurons modify their activation values with task-specific shifts retrieved from a memory module, which is populated rapidly based on limited task experience. On metalearning benchmarks from the vision and language domains, models augmented with conditionally shifted neurons achieve state-of-the-art results.