 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Equivalent Mechanistic Interpretations Across Neural Networks
Mar 31, 2026Mechanistic interpretability (MI) is an emerging framework for interpreting neural networks. Given a task and model, MI aims to discover a succinct algorithmic process, an interpretation, that explains the model's decision process on that task. However, MI is difficult to scale and generalize. This stems in part from two key challenges: there is no precise notion of a valid interpretation; and, generating interpretations is often an ad hoc process. In this paper, we address these challenges by defining and studying the problem of interpretive equivalence: determining whether two different models share a common interpretation, without requiring an explicit description of what that interpretation is. At the core of our approach, we propose and formalize the principle that two interpretations of a model are equivalent if all of their possible implementations are also equivalent. We develop an algorithm to estimate interpretive equivalence and case study its use on Transformer-based models. To analyze our algorithm, we introduce necessary and sufficient conditions for interpretive equivalence based on models' representation similarity. We provide guarantees that simultaneously relate a model's algorithmic interpretations, circuits, and representations. Our framework lays a foundation for the development of more rigorous evaluation methods of MI and automated, generalizable interpretation discovery methods.
When Language Models Lose Their Mind: The Consequences of Brain Misalignment
Mar 24, 2026While brain-aligned large language models (LLMs) have garnered attention for their potential as cognitive models and for potential for enhanced safety and trustworthiness in AI, the role of this brain alignment for linguistic competence remains uncertain. In this work, we investigate the functional implications of brain alignment by introducing brain-misaligned models--LLMs intentionally trained to predict brain activity poorly while maintaining high language modeling performance. We evaluate these models on over 200 downstream tasks encompassing diverse linguistic domains, including semantics, syntax, discourse, reasoning, and morphology. By comparing brain-misaligned models with well-matched brain-aligned counterparts, we isolate the specific impact of brain alignment on language understanding. Our experiments reveal that brain misalignment substantially impairs downstream performance, highlighting the critical role of brain alignment in achieving robust linguistic competence. These findings underscore the importance of brain alignment in LLMs and offer novel insights into the relationship between neural representations and linguistic processing.
CLIP is All You Need for Human-like Semantic Representations in Stable Diffusion
Nov 11, 2025Latent diffusion models such as Stable Diffusion achieve state-of-the-art results on text-to-image generation tasks. However, the extent to which these models have a semantic understanding of the images they generate is not well understood. In this work, we investigate whether the internal representations used by these models during text-to-image generation contain semantic information that is meaningful to humans. To do so, we perform probing on Stable Diffusion with simple regression layers that predict semantic attributes for objects and evaluate these predictions against human annotations. Surprisingly, we find that this success can actually be attributed to the text encoding occurring in CLIP rather than the reverse diffusion process. We demonstrate that groups of specific semantic attributes have markedly different decoding accuracy than the average, and are thus represented to different degrees. Finally, we show that attributes become more difficult to disambiguate from one another during the inverse diffusion process, further demonstrating the strongest semantic representation of object attributes in CLIP. We conclude that the separately trained CLIP vision-language model is what determines the human-like semantic representation, and that the diffusion process instead takes the role of a visual decoder.
The One Where They Brain-Tune for Social Cognition: Multi-Modal Brain-Tuning on Friends
Nov 11, 2025



Recent studies on audio models show brain-tuning - fine-tuning models to better predict corresponding fMRI activity - improves brain alignment and increases performance on downstream semantic and audio tasks. We extend this approach to a multimodal audio-video model to enhance social cognition, targeting the Superior Temporal Sulcus (STS), a key region for social processing, while subjects watch Friends. We find significant increases in brain alignment to the STS and an adjacent ROI, as well as improvements to a social cognition task related to the training data - sarcasm detection in sitcoms. In summary, our study extends brain-tuning to the multi-modal domain, demonstrating improvements to a downstream task after tuning to a relevant functional region.
Brain-tuning Improves Generalizability and Efficiency of Brain Alignment in Speech Models
Oct 24, 2025Pretrained language models are remarkably effective in aligning with human brain responses elicited by natural language stimuli, positioning them as promising model organisms for studying language processing in the brain. However, existing approaches for both estimating and improving this brain alignment are participant-dependent and highly affected by the amount of data available per participant, hindering both generalization to new participants and population-level analyses. In this work, we address these limitations by introducing a scalable, generalizable brain-tuning method, in which we fine-tune pretrained speech language models to jointly predict fMRI responses from multiple participants. We demonstrate that the resulting brain-tuned models exhibit strong individual brain alignment while generalizing across participants. Specifically, our method leads to 1) a 5-fold decrease in the amount of fMRI data needed to predict brain data from new participants, 2) up to a 50% increase in the overall brain alignment, and 3) strong generalization to new unseen datasets. Furthermore, this multi-participant brain-tuning additionally improves downstream performance on semantic tasks, suggesting that training using brain data from multiple participants leads to more generalizable semantic representations. Taken together, these findings demonstrate a bidirectional benefit between neuroscience and AI, helping bridge the gap between the two fields. We make our code and models publicly available at https://github.com/bridge-ai-neuro/multi-brain-tuning.
Fine-grained Analysis of Brain-LLM Alignment through Input Attribution
Oct 14, 2025



Understanding the alignment between large language models (LLMs) and human brain activity can reveal computational principles underlying language processing. We introduce a fine-grained input attribution method to identify the specific words most important for brain-LLM alignment, and leverage it to study a contentious research question about brain-LLM alignment: the relationship between brain alignment (BA) and next-word prediction (NWP). Our findings reveal that BA and NWP rely on largely distinct word subsets: NWP exhibits recency and primacy biases with a focus on syntax, while BA prioritizes semantic and discourse-level information with a more targeted recency effect. This work advances our understanding of how LLMs relate to human language processing and highlights differences in feature reliance between BA and NWP. Beyond this study, our attribution method can be broadly applied to explore the cognitive relevance of model predictions in diverse language processing tasks.
Positional Biases Shift as Inputs Approach Context Window Limits
Aug 10, 2025


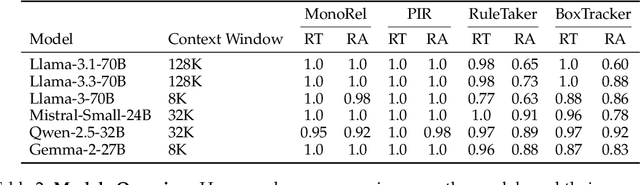
Large Language Models (LLMs) often struggle to use information across long inputs effectively. Prior work has identified positional biases, such as the Lost in the Middle (LiM) effect, where models perform better when information appears at the beginning (primacy bias) or end (recency bias) of the input, rather than in the middle. However, long-context studies have not consistently replicated these effects, raising questions about their intensity and the conditions under which they manifest. To address this, we conducted a comprehensive analysis using relative rather than absolute input lengths, defined with respect to each model's context window. Our findings reveal that the LiM effect is strongest when inputs occupy up to 50% of a model's context window. Beyond that, the primacy bias weakens, while recency bias remains relatively stable. This effectively eliminates the LiM effect; instead, we observe a distance-based bias, where model performance is better when relevant information is closer to the end of the input. Furthermore, our results suggest that successful retrieval is a prerequisite for reasoning in LLMs, and that the observed positional biases in reasoning are largely inherited from retrieval. These insights have implications for long-context tasks, the design of future LLM benchmarks, and evaluation methodologies for LLMs handling extended inputs.
Brain-tuned Speech Models Better Reflect Speech Processing Stages in the Brain
Jun 04, 2025Pretrained self-supervised speech models excel in speech tasks but do not reflect the hierarchy of human speech processing, as they encode rich semantics in middle layers and poor semantics in late layers. Recent work showed that brain-tuning (fine-tuning models using human brain recordings) improves speech models' semantic understanding. Here, we examine how well brain-tuned models further reflect the brain's intermediate stages of speech processing. We find that late layers of brain-tuned models substantially improve over pretrained models in their alignment with semantic language regions. Further layer-wise probing reveals that early layers remain dedicated to low-level acoustic features, while late layers become the best at complex high-level tasks. These findings show that brain-tuned models not only perform better but also exhibit a well-defined hierarchical processing going from acoustic to semantic representations, making them better model organisms for human speech processing.
Position: Episodic Memory is the Missing Piece for Long-Term LLM Agents
Feb 10, 2025


As Large Language Models (LLMs) evolve from text-completion tools into fully fledged agents operating in dynamic environments, they must address the challenge of continually learning and retaining long-term knowledge. Many biological systems solve these challenges with episodic memory, which supports single-shot learning of instance-specific contexts. Inspired by this, we present an episodic memory framework for LLM agents, centered around five key properties of episodic memory that underlie adaptive and context-sensitive behavior. With various research efforts already partially covering these properties, this position paper argues that now is the right time for an explicit, integrated focus on episodic memory to catalyze the development of long-term agents. To this end, we outline a roadmap that unites several research directions under the goal to support all five properties of episodic memory for more efficient long-term LLM agents.
SLayR: Scene Layout Generation with Rectified Flow
Dec 06, 2024



We introduce SLayR, Scene Layout Generation with Rectified flow. State-of-the-art text-to-image models achieve impressive results. However, they generate images end-to-end, exposing no fine-grained control over the process. SLayR presents a novel transformer-based rectified flow model for layout generation over a token space that can be decoded into bounding boxes and corresponding labels, which can then be transformed into images using existing models. We show that established metrics for generated images are inconclusive for evaluating their underlying scene layout, and introduce a new benchmark suite, including a carefully designed repeatable human-evaluation procedure that assesses the plausibility and variety of generated layouts. In contrast to previous works, which perform well in either high variety or plausibility, we show that our approach performs well on both of these axes at the same time. It is also at least 5x times smaller in the number of parameters and 37% faster than the baselines. Our complete text-to-image pipeline demonstrates the added benefits of an interpretable and editable intermediate representation.