 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hard-CoRe Coreference Corpus: Removing Gender and Number Cues for Difficult Pronominal Anaphora Resolution
Paper and Code
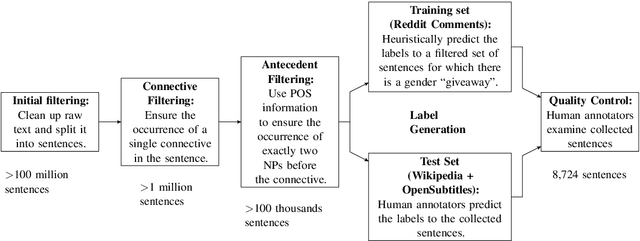
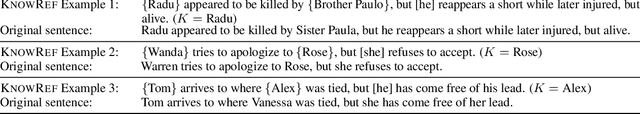

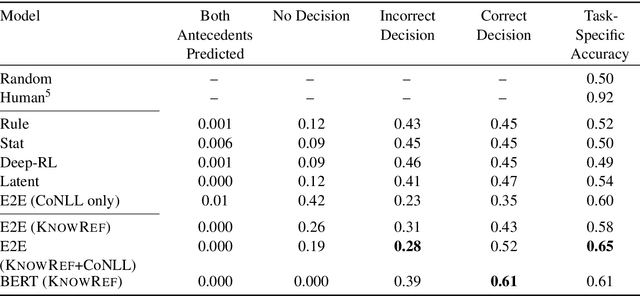
We introduce a new benchmark task for coreference resolution, Hard-CoRe, that targets common-sense reasoning and world knowledge. Previous coreference resolution tasks have been overly vulnerable to systems that simply exploit the number and gender of the antecedents, or have been handcrafted and do not reflect the diversity of sentences in naturally occurring text. With these limitations in mind, we present a resolution task that is both challenging and realistic. We demonstrate that various coreference systems, whether rule-based, feature-rich, graphical, or neural-based, perform at random or slightly above-random on the task, whereas human performance is very strong with high inter-annotator agreement. To explain this performance gap, we show empirically that state-of-the art models often fail to capture context and rely only on the antecedents to make a decision.