 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Lesion Detection by Learning from Multiple Heterogeneously Labeled Datasets
May 28, 2020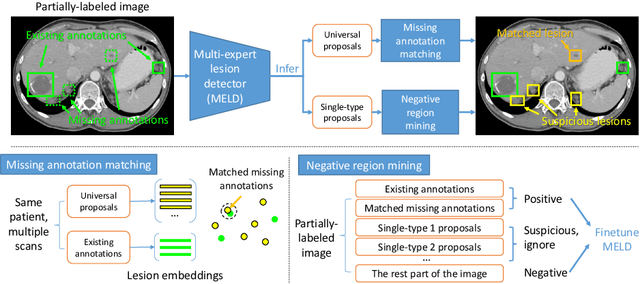
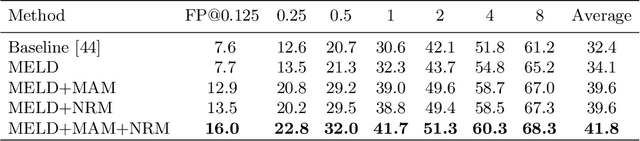
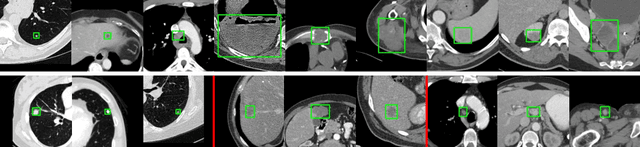
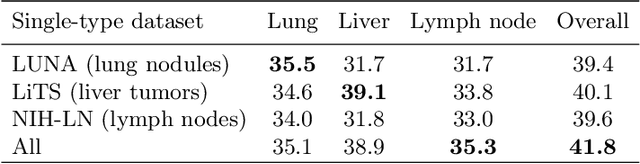
Lesion detection is an important problem within medical imaging analysis. Most previous work focuses on detecting and segmenting a specialized category of lesions (e.g., lung nodules). However, in clinical practice, radiologists are responsible for finding all possible types of anomalies. The task of universal lesion detection (ULD) was proposed to address this challenge by detecting a large variety of lesions from the whole body. There are multiple heterogeneously labeled datasets with varying label completeness: DeepLesion, the largest dataset of 32,735 annotated lesions of various types, but with even more missing annotation instances; and several fully-labeled single-type lesion datasets, such as LUNA for lung nodules and LiTS for liver tumors. In this work, we propose a novel framework to leverage all these datasets together to improve the performance of ULD. First, we learn a multi-head multi-task lesion detector using all datasets and generate lesion proposals on DeepLesion. Second, missing annotations in DeepLesion are retrieved by a new method of embedding matching that exploits clinical prior knowledge. Last, we discover suspicious but unannotated lesions using knowledge transfer from single-type lesion detectors. In this way, reliable positive and negative regions are obtained from partially-labeled and unlabeled images, which are effectively utilized to train ULD. To assess the clinically realistic protocol of 3D volumetric ULD, we fully annotated 1071 CT sub-volumes in DeepLesion. Our method outperforms the current state-of-the-art approach by 29% in the metric of average sensitivity.
Organ at Risk Segmentation for Head and Neck Cancer using Stratified Learning and Neural Architecture Search
Apr 17, 2020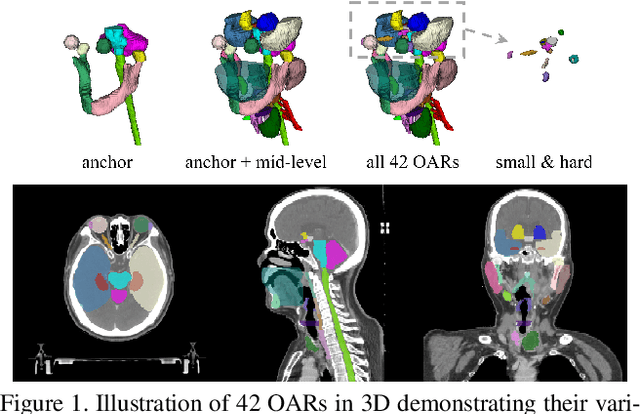

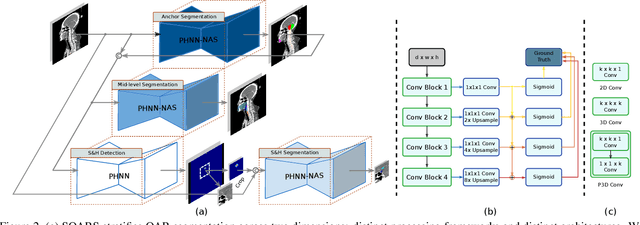
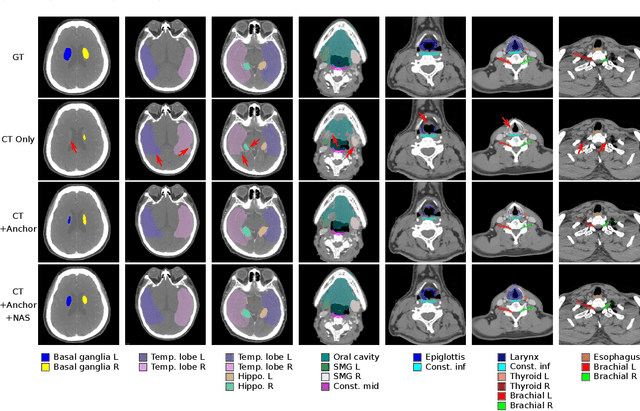
OAR segmentation is a critical step in radiotherapy of head and neck (H&N) cancer, where inconsistencies across radiation oncologists and prohibitive labor costs motivate automated approaches. However, leading methods using standard fully convolutional network workflows that are challenged when the number of OARs becomes large, e.g. > 40. For such scenarios, insights can be gained from the stratification approaches seen in manual clinical OAR delineation. This is the goal of our work, where we introduce stratified organ at risk segmentation (SOARS), an approach that stratifies OARs into anchor, mid-level, and small & hard (S&H) categories. SOARS stratifies across two dimensions. The first dimension is that distinct processing pipelines are used for each OAR category. In particular, inspired by clinical practices, anchor OARs are used to guide the mid-level and S&H categories. The second dimension is that distinct network architectures are used to manage the significant contrast, size, and anatomy variations between different OARs. We use differentiable neural architecture search (NAS), allowing the network to choose among 2D, 3D or Pseudo-3D convolutions. Extensive 4-fold cross-validation on 142 H&N cancer patients with 42 manually labeled OARs, the most comprehensive OAR dataset to date, demonstrates that both pipeline- and NAS-stratification significantly improves quantitative performance over the state-of-the-art (from 69.52% to 73.68% in absolute Dice scores). Thus, SOARS provides a powerful and principled means to manage the highly complex segmentation space of OARs.
Lesion Harvester: Iteratively Mining Unlabeled Lesions and Hard-Negative Examples at Scale
Jan 28, 2020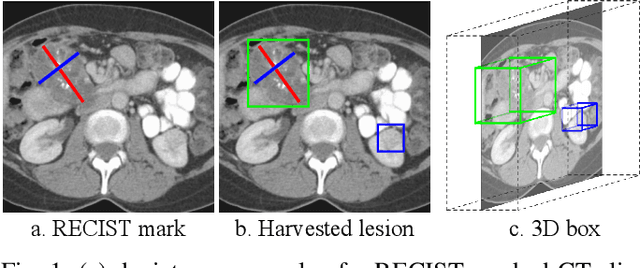
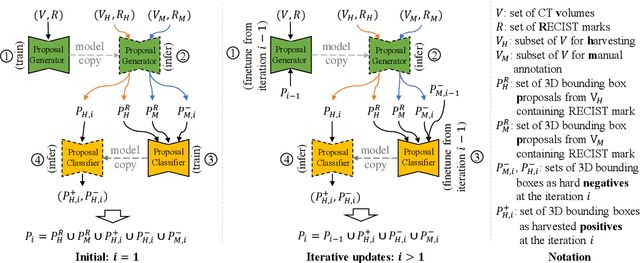
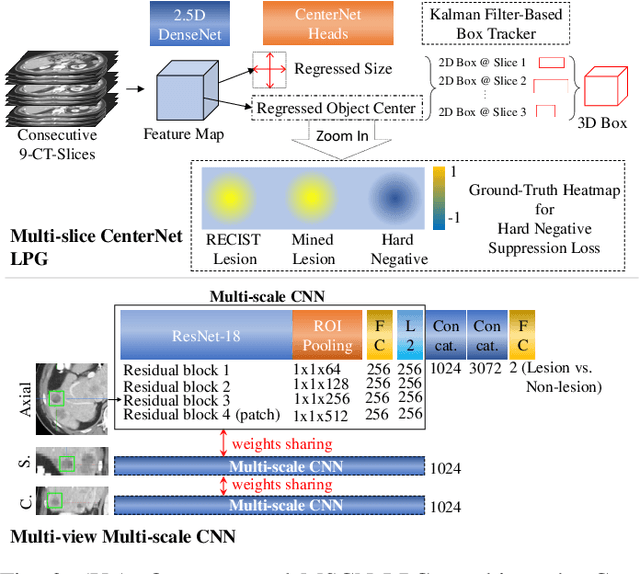
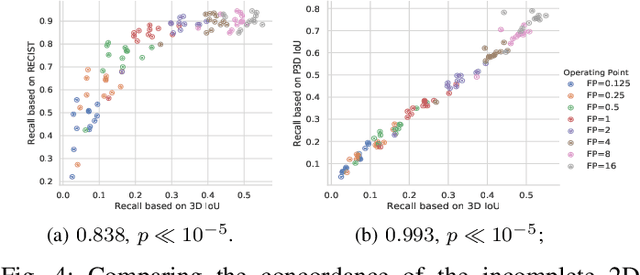
Acquiring large-scale medical image data, necessary for training machine learning algorithms, is frequently intractable, due to prohibitive expert-driven annotation costs. Recent datasets extracted from hospital archives, e.g., DeepLesion, have begun to address this problem. However, these are often incompletely or noisily labeled, e.g., DeepLesion leaves over 50% of its lesions unlabeled. Thus, effective methods to harvest missing annotations are critical for continued progress in medical image analysis. This is the goal of our work, where we develop a powerful system to harvest missing lesions from the DeepLesion dataset at high precision. Accepting the need for some degree of expert labor to achieve high fidelity, we exploit a small fully-labeled subset of medical image volumes and use it to intelligently mine annotations from the remainder. To do this, we chain together a highly sensitive lesion proposal generator and a very selective lesion proposal classifier. While our framework is generic, we optimize our performance by proposing a 3D contextual lesion proposal generator and by using a multi-view multi-scale lesion proposal classifier. These produce harvested and hard-negative proposals, which we then re-use to finetune our proposal generator by using a novel hard negative suppression loss, continuing this process until no extra lesions are found. Extensive experimental analysis demonstrates that our method can harvest an additional 9,805 lesions while keeping precision above 90%. To demonstrate the benefits of our approach, we show that lesion detectors trained on our harvested lesions can significantly outperform the same variants only trained on the original annotations, with boost of average precision of 7% to 10%. We open source our annotations at https://github.com/JimmyCai91/DeepLesionAnnotation.
CT Data Curation for Liver Patients: Phase Recognition in Dynamic Contrast-Enhanced CT
Sep 27, 2019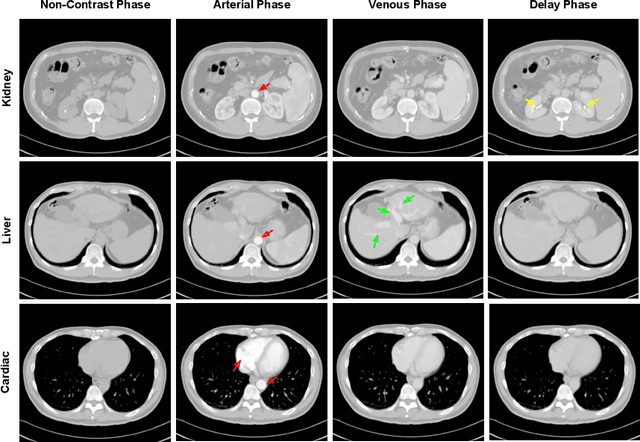
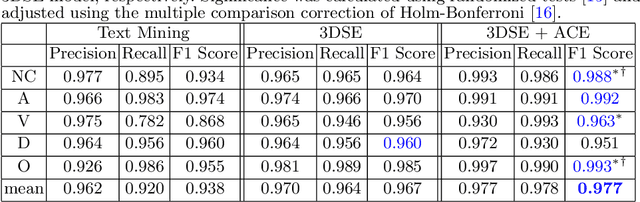
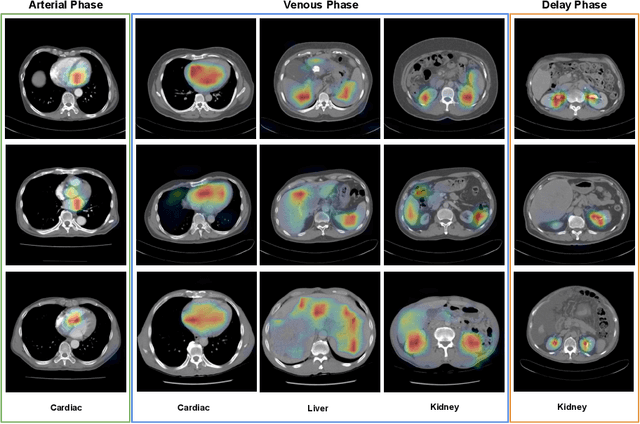

As the demand for more descriptive machine learning models grows within medical imaging, bottlenecks due to data paucity will exacerbate. Thus, collecting enough large-scale data will require automated tools to harvest data/label pairs from messy and real-world datasets, such as hospital PACS. This is the focus of our work, where we present a principled data curation tool to extract multi-phase CT liver studies and identify each scan's phase from a real-world and heterogenous hospital PACS dataset. Emulating a typical deployment scenario, we first obtain a set of noisy labels from our institutional partners that are text mined using simple rules from DICOM tags. We train a deep learning system, using a customized and streamlined 3D SE architecture, to identify non-contrast, arterial, venous, and delay phase dynamic CT liver scans, filtering out anything else, including other types of liver contrast studies. To exploit as much training data as possible, we also introduce an aggregated cross entropy loss that can learn from scans only identified as "contrast". Extensive experiments on a dataset of 43K scans of 7680 patient imaging studies demonstrate that our 3DSE architecture, armed with our aggregated loss, can achieve a mean F1 of 0.977 and can correctly harvest up to 92.7% of studies, which significantly outperforms the text-mined and standard-loss approach, and also outperforms other, and more complex, model architectures.
Deep Esophageal Clinical Target Volume Delineation using Encoded 3D Spatial Context of Tumors, Lymph Nodes, and Organs At Risk
Sep 06, 2019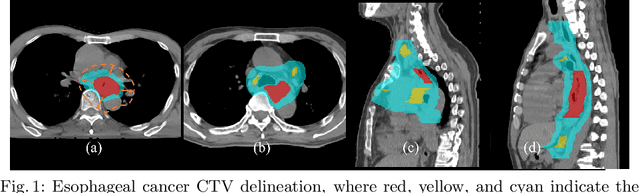

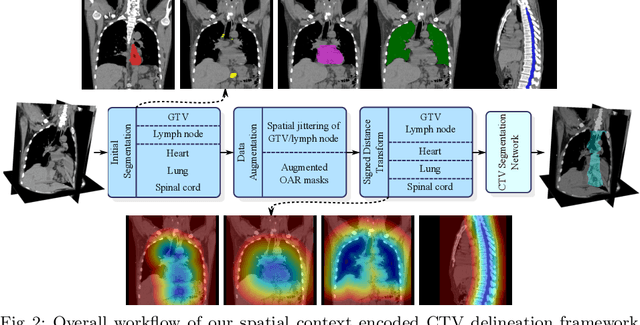
Clinical target volume (CTV) delineation from radiotherapy computed tomography (RTCT) images is used to define the treatment areas containing the gross tumor volume (GTV) and/or sub-clinical malignant disease for radiotherapy (RT). High intra- and inter-user variability makes this a particularly difficult task for esophageal cancer. This motivates automated solutions, which is the aim of our work. Because CTV delineation is highly context-dependent--it must encompass the GTV and regional lymph nodes (LNs) while also avoiding excessive exposure to the organs at risk (OARs)--we formulate it as a deep contextual appearance-based problem using encoded spatial contexts of these anatomical structures. This allows the deep network to better learn from and emulate the margin- and appearance-based delineation performed by human physicians. Additionally, we develop domain-specific data augmentation to inject robustness to our system. Finally, we show that a simple 3D progressive holistically nested network (PHNN), which avoids computationally heavy decoding paths while still aggregating features at different levels of context, can outperform more complicated networks. Cross-validated experiments on a dataset of 135 esophageal cancer patients demonstrate that our encoded spatial context approach can produce concrete performance improvements, with an average Dice score of 83.9% and an average surface distance of 4.2 mm, representing improvements of 3.8% and 2.4 mm, respectively, over the state-of-the-art approach.
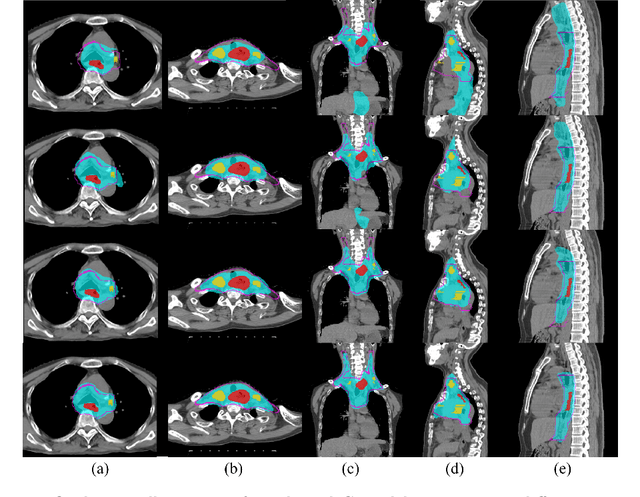
Accurate Esophageal Gross Tumor Volume Segmentation in PET/CT using Two-Stream Chained 3D Deep Network Fusion
Sep 06, 2019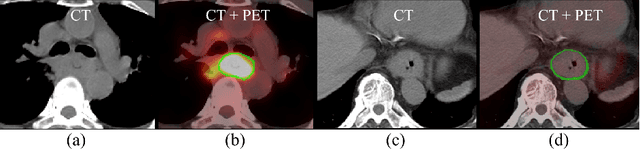
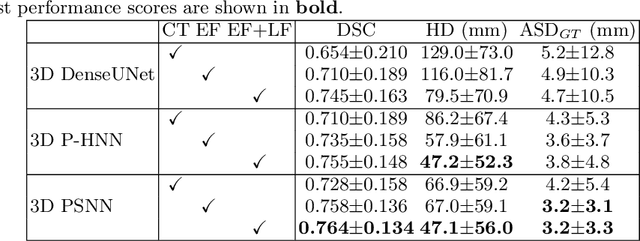
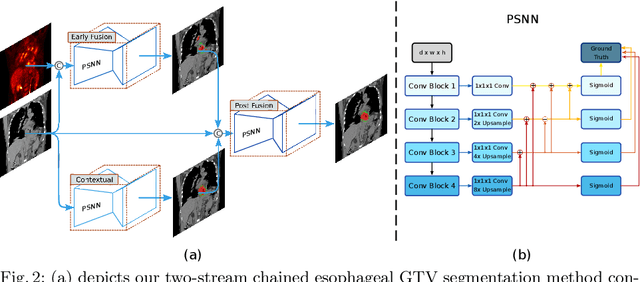
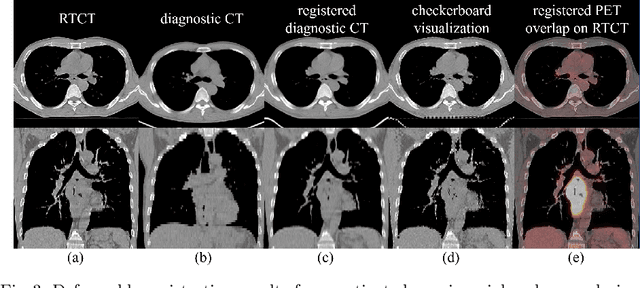
Gross tumor volume (GTV) segmentation is a critical step in esophageal cancer radiotherapy treatment planning. Inconsistencies across oncologists and prohibitive labor costs motivate automated approaches for this task. However, leading approaches are only applied to radiotherapy computed tomography (RTCT) images taken prior to treatment. This limits the performance as RTCT suffers from low contrast between the esophagus, tumor, and surrounding tissues. In this paper, we aim to exploit both RTCT and positron emission tomography (PET) imaging modalities to facilitate more accurate GTV segmentation. By utilizing PET, we emulate medical professionals who frequently delineate GTV boundaries through observation of the RTCT images obtained after prescribing radiotherapy and PET/CT images acquired earlier for cancer staging. To take advantage of both modalities, we present a two-stream chained segmentation approach that effectively fuses the CT and PET modalities via early and late 3D deep-network-based fusion. Furthermore, to effect the fusion and segmentation we propose a simple yet effective progressive semantically nested network (PSNN) model that outperforms more complicated models. Extensive 5-fold cross-validation on 110 esophageal cancer patients, the largest analysis to date, demonstrates that both the proposed two-stream chained segmentation pipeline and the PSNN model can significantly improve the quantitative performance over the previous state-of-the-art work by 11% in absolute Dice score (DSC) (from 0.654 to 0.764) and, at the same time, reducing the Hausdorff distance from 129 mm to 47 mm.
Weakly Supervised Universal Fracture Detection in Pelvic X-rays
Sep 04, 2019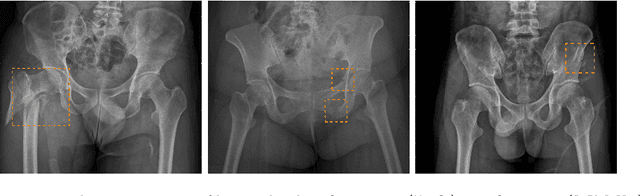
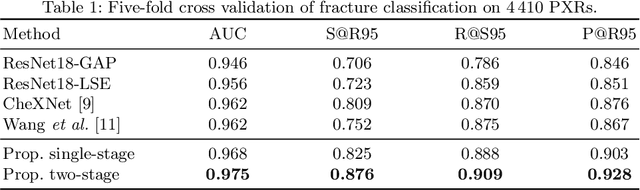
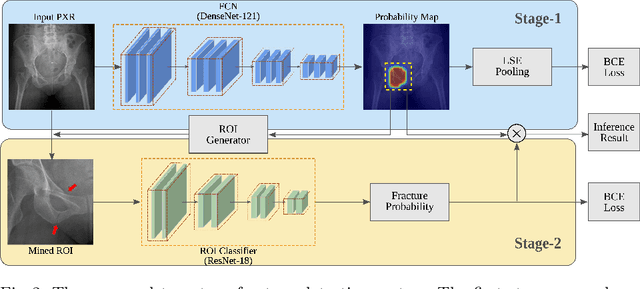
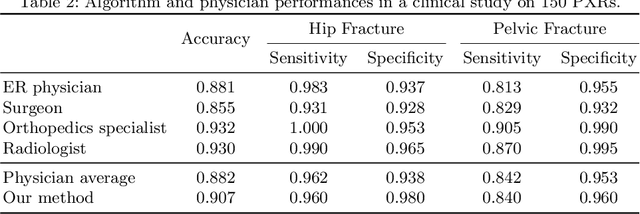
Hip and pelvic fractures are serious injuries with life-threatening complications. However, diagnostic errors of fractures in pelvic X-rays (PXRs) are very common, driving the demand for computer-aided diagnosis (CAD) solutions. A major challenge lies in the fact that fractures are localized patterns that require localized analyses. Unfortunately, the PXRs residing in hospital picture archiving and communication system do not typically specify region of interests. In this paper, we propose a two-stage hip and pelvic fracture detection method that executes localized fracture classification using weakly supervised ROI mining. The first stage uses a large capacity fully-convolutional network, i.e., deep with high levels of abstraction, in a multiple instance learning setting to automatically mine probable true positive and definite hard negative ROIs from the whole PXR in the training data. The second stage trains a smaller capacity model, i.e., shallower and more generalizable, with the mined ROIs to perform localized analyses to classify fractures. During inference, our method detects hip and pelvic fractures in one pass by chaining the probability outputs of the two stages together. We evaluate our method on 4 410 PXRs, reporting an area under the ROC curve value of 0.975, the highest among state-of-the-art fracture detection methods. Moreover, we show that our two-stage approach can perform comparably to human physicians (even outperforming emergency physicians and surgeons), in a preliminary reader study of 23 readers.
Attention-Guided Curriculum Learning for Weakly Supervised Classification and Localization of Thoracic Diseases on Chest Radiographs
Jul 19, 2018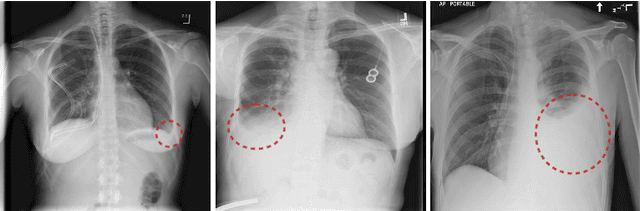
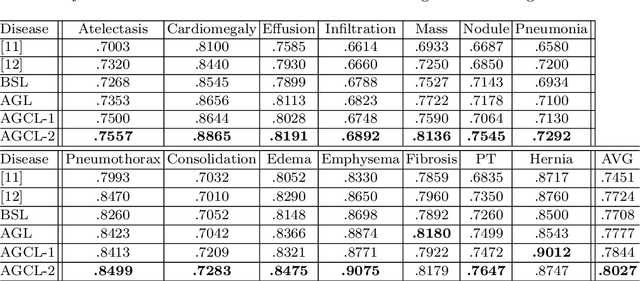
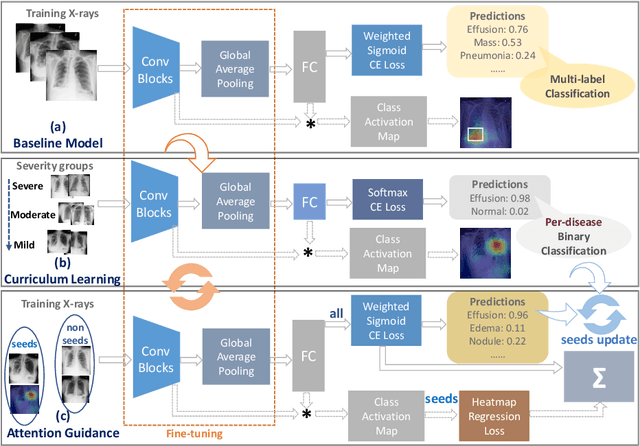
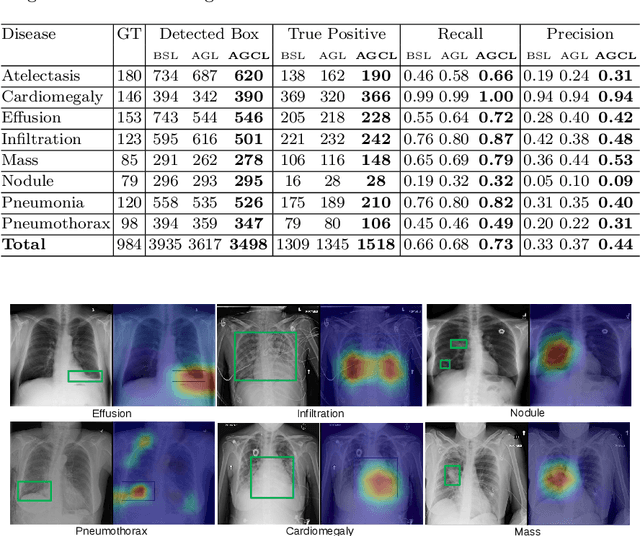
In this work, we exploit the task of joint classification and weakly supervised localization of thoracic diseases from chest radiographs, with only image-level disease labels coupled with disease severity-level (DSL) information of a subset. A convolutional neural network (CNN) based attention-guided curriculum learning (AGCL) framework is presented, which leverages the severity-level attributes mined from radiology reports. Images in order of difficulty (grouped by different severity-levels) are fed to CNN to boost the learning gradually. In addition, highly confident samples (measured by classification probabilities) and their corresponding class-conditional heatmaps (generated by the CNN) are extracted and further fed into the AGCL framework to guide the learning of more distinctive convolutional features in the next iteration. A two-path network architecture is designed to regress the heatmaps from selected seed samples in addition to the original classification task. The joint learning scheme can improve the classification and localization performance along with more seed samples for the next iteration. We demonstrate the effectiveness of this iterative refinement framework via extensive experimental evaluations on the publicly available ChestXray14 dataset. AGCL achieves over 5.7\% (averaged over 14 diseases) increase in classification AUC and 7%/11% increases in Recall/Precision for the localization task compared to the state of the art.
CT Image Enhancement Using Stacked Generative Adversarial Networks and Transfer Learning for Lesion Segmentation Improvement
Jul 18, 2018
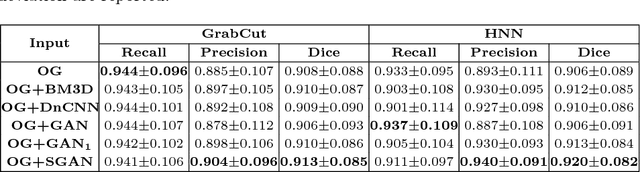


Automated lesion segmentation from computed tomography (CT) is an important and challenging task in medical image analysis. While many advancements have been made, there is room for continued improvements. One hurdle is that CT images can exhibit high noise and low contrast, particularly in lower dosages. To address this, we focus on a preprocessing method for CT images that uses stacked generative adversarial networks (SGAN) approach. The first GAN reduces the noise in the CT image and the second GAN generates a higher resolution image with enhanced boundaries and high contrast. To make up for the absence of high quality CT images, we detail how to synthesize a large number of low- and high-quality natural images and use transfer learning with progressively larger amounts of CT images. We apply both the classic GrabCut method and the modern holistically nested network (HNN) to lesion segmentation, testing whether SGAN can yield improved lesion segmentation. Experimental results on the DeepLesion dataset demonstrate that the SGAN enhancements alone can push GrabCut performance over HNN trained on original images. We also demonstrate that HNN + SGAN performs best compared against four other enhancement methods, including when using only a single GAN.
Iterative Attention Mining for Weakly Supervised Thoracic Disease Pattern Localization in Chest X-Rays
Jul 03, 2018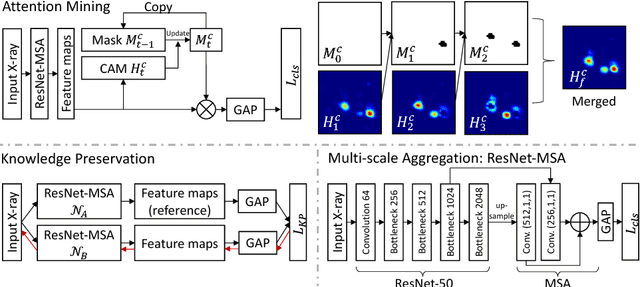
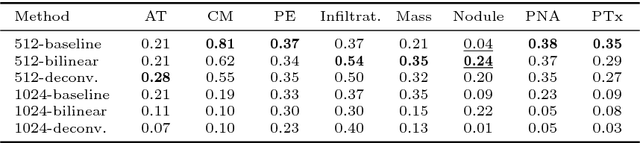
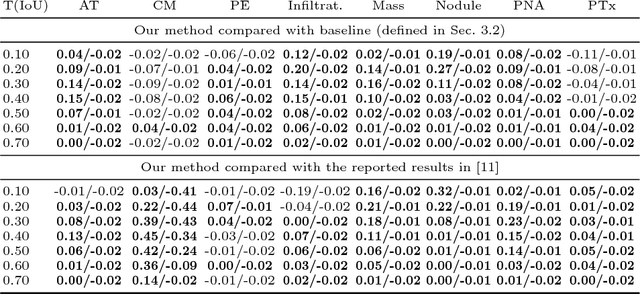

Given image labels as the only supervisory signal, we focus on harvesting, or mining, thoracic disease localizations from chest X-ray images. Harvesting such localizations from existing datasets allows for the creation of improved data sources for computer-aided diagnosis and retrospective analyses. We train a convolutional neural network (CNN) for image classification and propose an attention mining (AM) strategy to improve the model's sensitivity or saliency to disease patterns. The intuition of AM is that once the most salient disease area is blocked or hidden from the CNN model, it will pay attention to alternative image regions, while still attempting to make correct predictions. However, the model requires to be properly constrained during AM, otherwise, it may overfit to uncorrelated image parts and forget the valuable knowledge that it has learned from the original image classification task. To alleviate such side effects, we then design a knowledge preservation (KP) loss, which minimizes the discrepancy between responses for X-ray images from the original and the updated networks. Furthermore, we modify the CNN model to include multi-scale aggregation (MSA), improving its localization ability on small-scale disease findings, e.g., lung nodules. We experimentally validate our method on the publicly-available ChestX-ray14 dataset, outperforming a class activation map (CAM)-based approach, and demonstrating the value of our novel framework for mining disease locations.