 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Bimanual Manipulation Using Learned Task Schemas
Sep 30, 2019
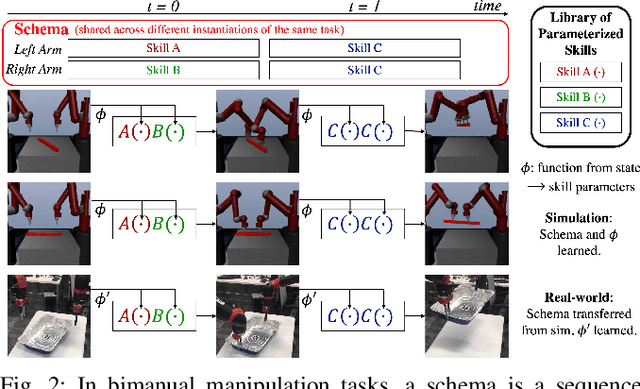
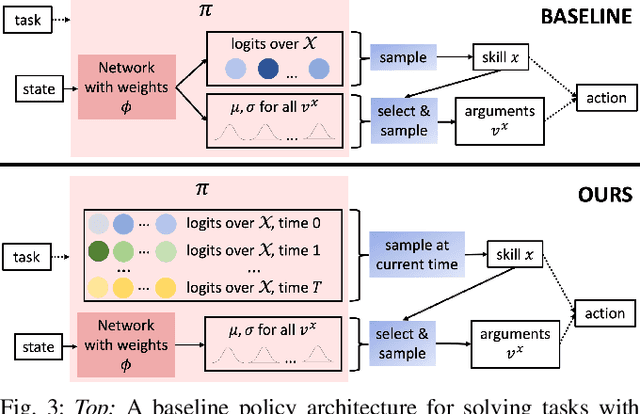
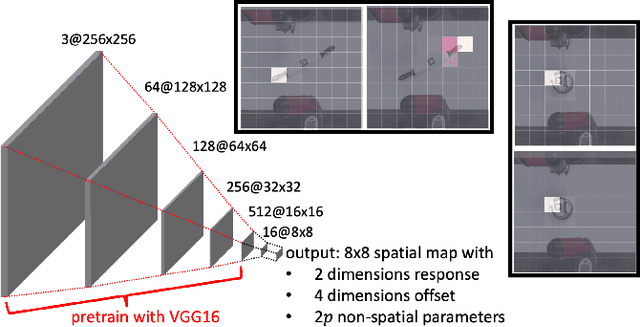
We address the problem of effectively composing skills to solve sparse-reward tasks in the real world. Given a set of parameterized skills (such as exerting a force or doing a top grasp at a location), our goal is to learn policies that invoke these skills to efficiently solve such tasks. Our insight is that for many tasks, the learning process can be decomposed into learning a state-independent task schema (a sequence of skills to execute) and a policy to choose the parameterizations of the skills in a state-dependent manner. For such tasks, we show that explicitly modeling the schema's state-independence can yield significant improvements in sample efficiency for model-free reinforcement learning algorithms. Furthermore, these schemas can be transferred to solve related tasks, by simply re-learning the parameterizations with which the skills are invoked. We find that doing so enables learning to solve sparse-reward tasks on real-world robotic systems very efficiently. We validate our approach experimentally over a suite of robotic bimanual manipulation tasks, both in simulation and on real hardware. See videos at http://tinyurl.com/chitnis-schema .
Dynamics-aware Embeddings
Sep 01, 2019
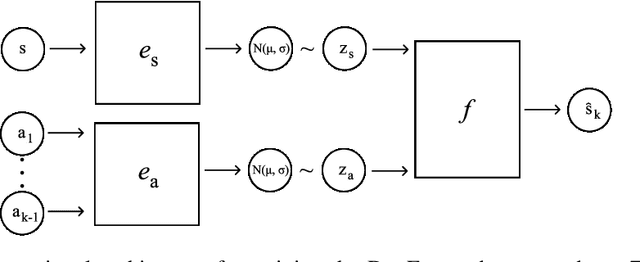
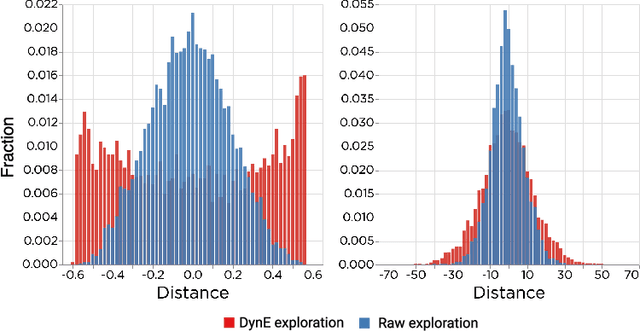
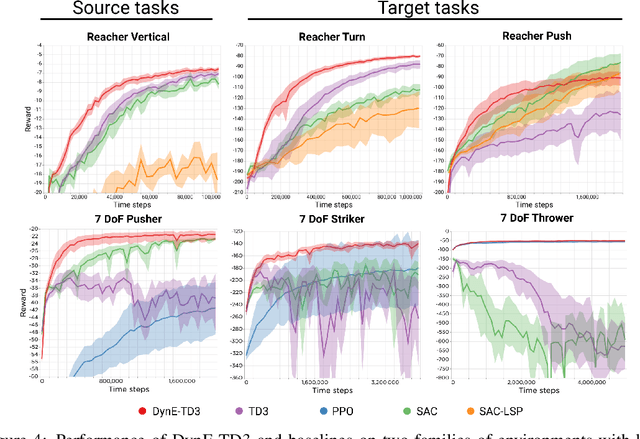
In this paper we consider self-supervised representation learning to improve sample efficiency in reinforcement learning (RL). We propose a forward prediction objective for simultaneously learning embeddings of states and actions. These embeddings capture the structure of the environment's dynamics, enabling efficient policy learning. We demonstrate that our action embeddings alone improve the sample efficiency and peak performance of model-free RL on control from low-dimensional states. By combining state and action embeddings, we achieve efficient learning of high-quality policies on goal-conditioned continuous control from pixel observations in only 1-2 million environment steps.
Compositional Video Prediction
Aug 22, 2019
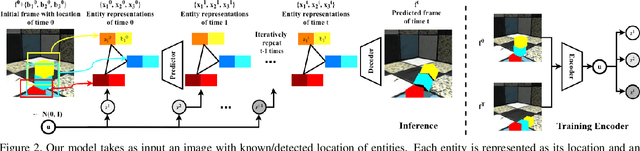
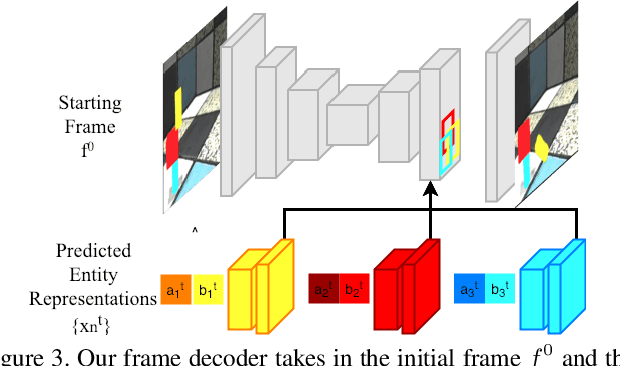
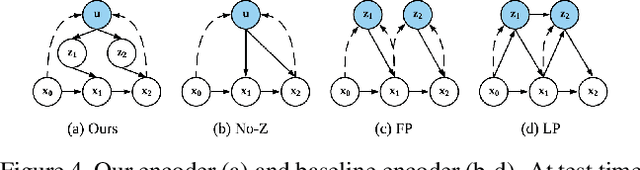
We present an approach for pixel-level future prediction given an input image of a scene. We observe that a scene is comprised of distinct entities that undergo motion and present an approach that operationalizes this insight. We implicitly predict future states of independent entities while reasoning about their interactions, and compose future video frames using these predicted states. We overcome the inherent multi-modality of the task using a global trajectory-level latent random variable, and show that this allows us to sample diverse and plausible futures. We empirically validate our approach against alternate representations and ways of incorporating multi-modality. We examine two datasets, one comprising of stacked objects that may fall, and the other containing videos of humans performing activities in a gym, and show that our approach allows realistic stochastic video prediction across these diverse settings. See https://judyye.github.io/CVP/ for video predictions.
Canonical Surface Mapping via Geometric Cycle Consistency
Aug 15, 2019
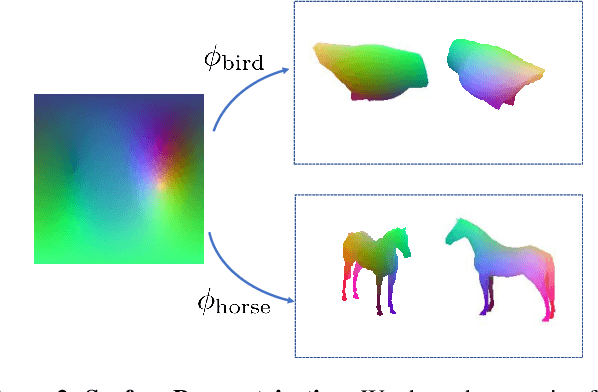
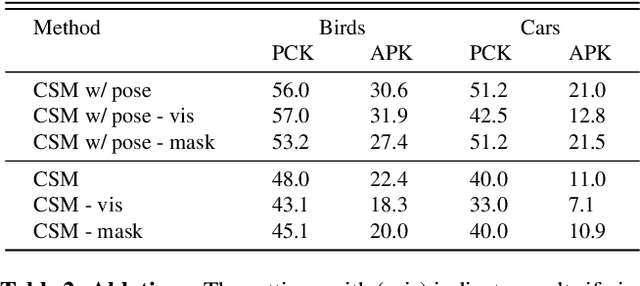
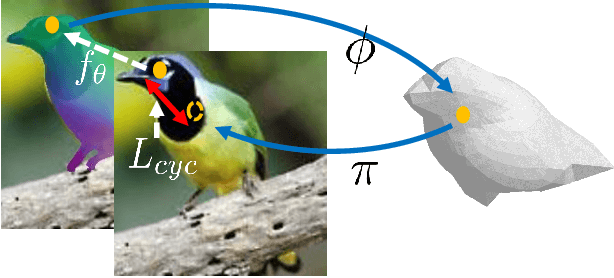
We explore the task of Canonical Surface Mapping (CSM). Specifically, given an image, we learn to map pixels on the object to their corresponding locations on an abstract 3D model of the category. But how do we learn such a mapping? A supervised approach would require extensive manual labeling which is not scalable beyond a few hand-picked categories. Our key insight is that the CSM task (pixel to 3D), when combined with 3D projection (3D to pixel), completes a cycle. Hence, we can exploit a geometric cycle consistency loss, thereby allowing us to forgo the dense manual supervision. Our approach allows us to train a CSM model for a diverse set of classes, without sparse or dense keypoint annotation, by leveraging only foreground mask labels for training. We show that our predictions also allow us to infer dense correspondence between two images, and compare the performance of our approach against several methods that predict correspondence by leveraging varying amount of supervision.
Environment Probing Interaction Policies
Jul 26, 2019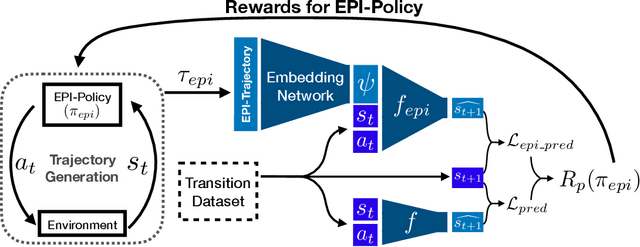
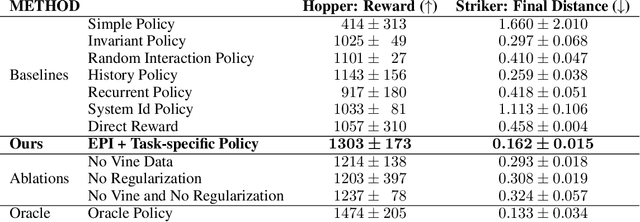
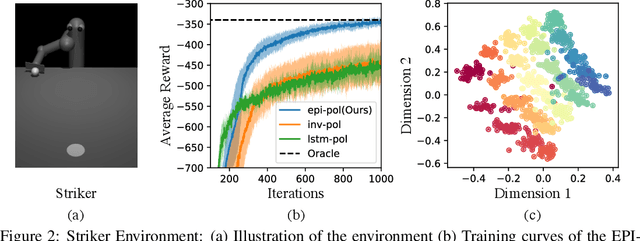
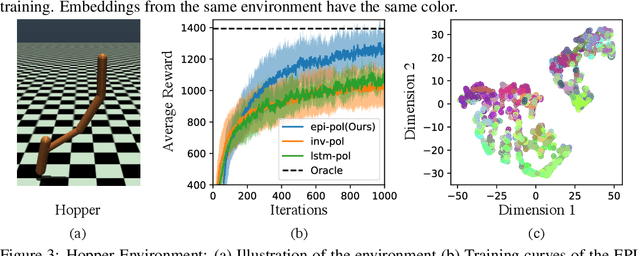
A key challenge in reinforcement learning (RL) is environment generalization: a policy trained to solve a task in one environment often fails to solve the same task in a slightly different test environment. A common approach to improve inter-environment transfer is to learn policies that are invariant to the distribution of testing environments. However, we argue that instead of being invariant, the policy should identify the specific nuances of an environment and exploit them to achieve better performance. In this work, we propose the 'Environment-Probing' Interaction (EPI) policy, a policy that probes a new environment to extract an implicit understanding of that environment's behavior. Once this environment-specific information is obtained, it is used as an additional input to a task-specific policy that can now perform environment-conditioned actions to solve a task. To learn these EPI-policies, we present a reward function based on transition predictability. Specifically, a higher reward is given if the trajectory generated by the EPI-policy can be used to better predict transitions. We experimentally show that EPI-conditioned task-specific policies significantly outperform commonly used policy generalization methods on novel testing environments.
PyRobot: An Open-source Robotics Framework for Research and Benchmarking
Jun 19, 2019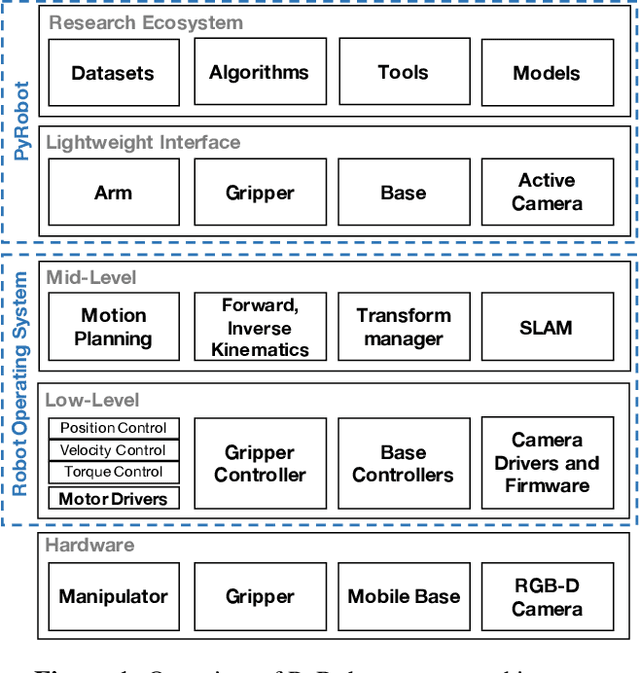
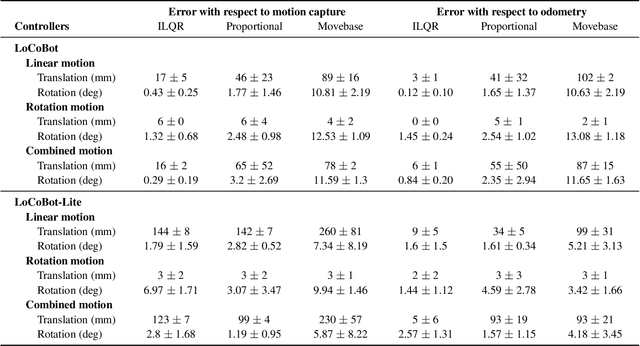

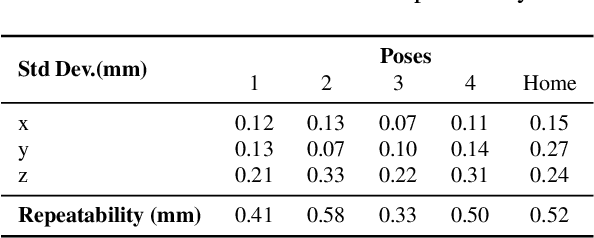
This paper introduces PyRobot, an open-source robotics framework for research and benchmarking. PyRobot is a light-weight, high-level interface on top of ROS that provides a consistent set of hardware independent mid-level APIs to control different robots. PyRobot abstracts away details about low-level controllers and inter-process communication, and allows non-robotics researchers (ML, CV researchers) to focus on building high-level AI applications. PyRobot aims to provide a research ecosystem with convenient access to robotics datasets, algorithm implementations and models that can be used to quickly create a state-of-the-art baseline. We believe PyRobot, when paired up with low-cost robot platforms such as LoCoBot, will reduce the entry barrier into robotics, and democratize robotics. PyRobot is open-source, and can be accessed via https://pyrobot.org.
Self-Supervised Exploration via Disagreement
Jun 10, 2019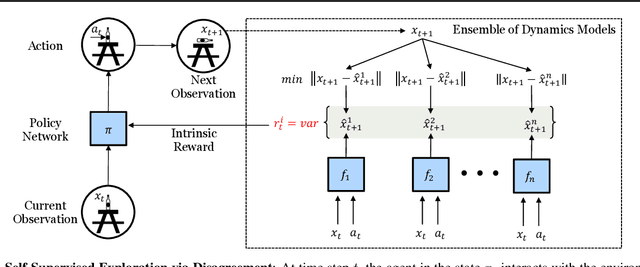
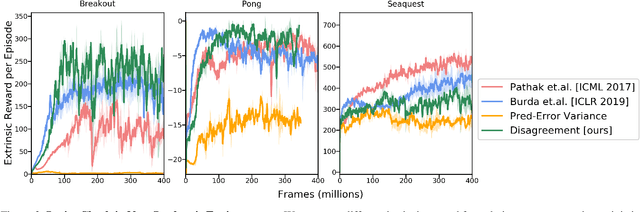
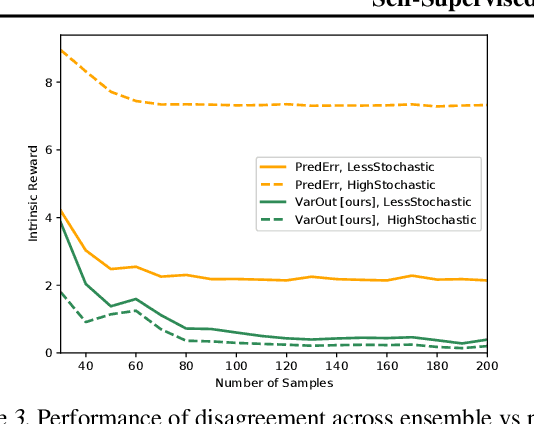
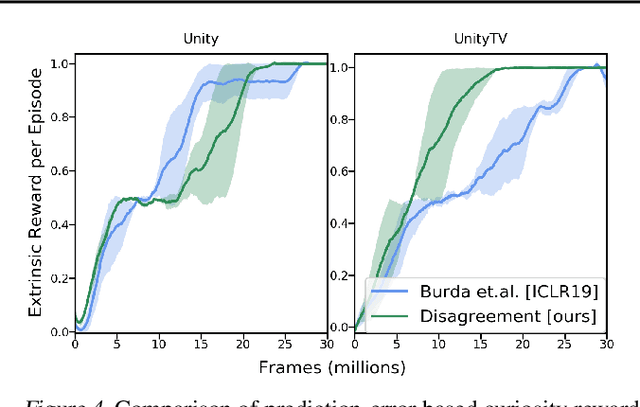
Efficient exploration is a long-standing problem in sensorimotor learning. Major advances have been demonstrated in noise-free, non-stochastic domains such as video games and simulation. However, most of these formulations either get stuck in environments with stochastic dynamics or are too inefficient to be scalable to real robotics setups. In this paper, we propose a formulation for exploration inspired by the work in active learning literature. Specifically, we train an ensemble of dynamics models and incentivize the agent to explore such that the disagreement of those ensembles is maximized. This allows the agent to learn skills by exploring in a self-supervised manner without any external reward. Notably, we further leverage the disagreement objective to optimize the agent's policy in a differentiable manner, without using reinforcement learning, which results in a sample-efficient exploration. We demonstrate the efficacy of this formulation across a variety of benchmark environments including stochastic-Atari, Mujoco and Unity. Finally, we implement our differentiable exploration on a real robot which learns to interact with objects completely from scratch. Project videos and code are at https://pathak22.github.io/exploration-by-disagreement/
3D-RelNet: Joint Object and Relational Network for 3D Prediction
Jun 06, 2019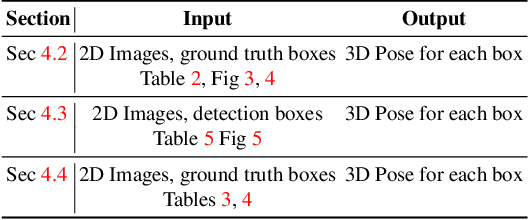
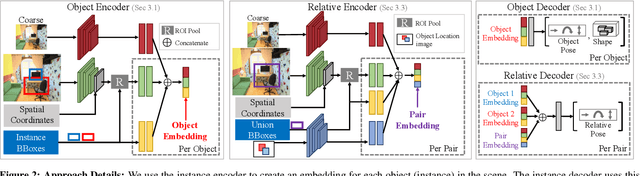
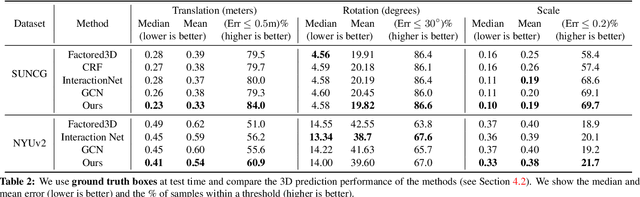
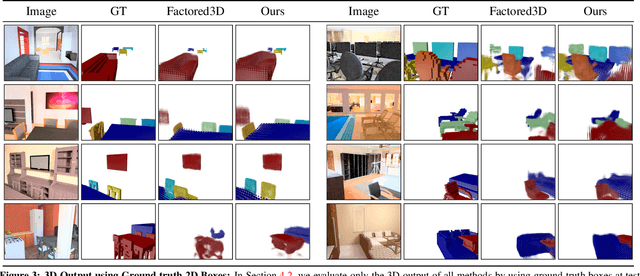
We propose an approach to predict the 3D shape and pose for the objects present in a scene. Existing learning based methods that pursue this goal make independent predictions per object, and do not leverage the relationships amongst them. We argue that reasoning about these relationships is crucial, and present an approach to incorporate these in a 3D prediction framework. In addition to independent per-object predictions, we predict pairwise relations in the form of relative 3D pose, and demonstrate that these can be easily incorporated to improve object level estimates. We report performance across different datasets (SUNCG, NYUv2), and show that our approach significantly improves over independent prediction approaches while also outperforming alternate implicit reasoning methods.
Scaling and Benchmarking Self-Supervised Visual Representation Learning
Jun 06, 2019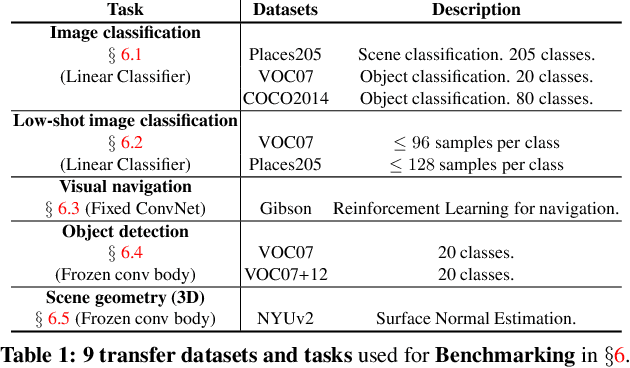
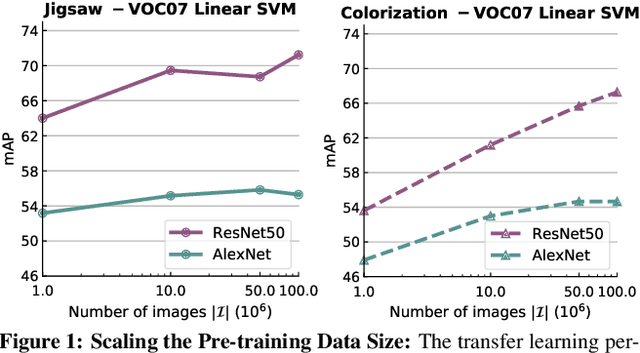

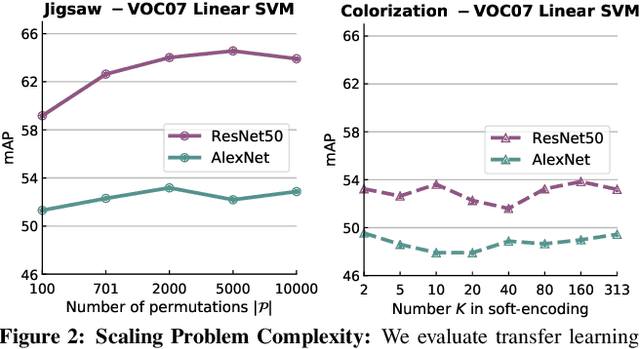
Self-supervised learning aims to learn representations from the data itself without explicit manual supervision. Existing efforts ignore a crucial aspect of self-supervised learning - the ability to scale to large amount of data because self-supervision requires no manual labels. In this work, we revisit this principle and scale two popular self-supervised approaches to 100 million images. We show that by scaling on various axes (including data size and problem 'hardness'), one can largely match or even exceed the performance of supervised pre-training on a variety of tasks such as object detection, surface normal estimation (3D) and visual navigation using reinforcement learning. Scaling these methods also provides many interesting insights into the limitations of current self-supervised techniques and evaluations. We conclude that current self-supervised methods are not 'hard' enough to take full advantage of large scale data and do not seem to learn effective high level semantic representations. We also introduce an extensive benchmark across 9 different datasets and tasks. We believe that such a benchmark along with comparable evaluation settings is necessary to make meaningful progress. Code is at: https://github.com/facebookresearch/fair_self_supervision_benchmark.
Task-Driven Modular Networks for Zero-Shot Compositional Learning
May 15, 2019

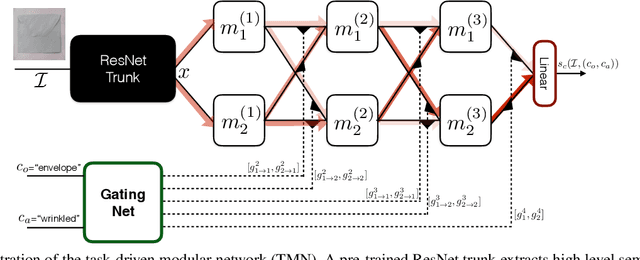

One of the hallmarks of human intelligence is the ability to compose learned knowledge into novel concepts which can be recognized without a single training example. In contrast, current state-of-the-art methods require hundreds of training examples for each possible category to build reliable and accurate classifiers. To alleviate this striking difference in efficiency, we propose a task-driven modular architecture for compositional reasoning and sample efficient learning. Our architecture consists of a set of neural network modules, which are small fully connected layers operating in semantic concept space. These modules are configured through a gating function conditioned on the task to produce features representing the compatibility between the input image and the concept under consideration. This enables us to express tasks as a combination of sub-tasks and to generalize to unseen categories by reweighting a set of small modules. Furthermore, the network can be trained efficiently as it is fully differentiable and its modules operate on small sub-spaces. We focus our study on the problem of compositional zero-shot classification of object-attribute categories. We show in our experiments that current evaluation metrics are flawed as they only consider unseen object-attribute pairs. When extending the evaluation to the generalized setting which accounts also for pairs seen during training, we discover that naive baseline methods perform similarly or better than current approaches. However, our modular network is able to outperform all existing approaches on two widely-used benchmark datasets.