 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyaNet: A Lyapunov Framework for Training Neural ODEs
Feb 05, 2022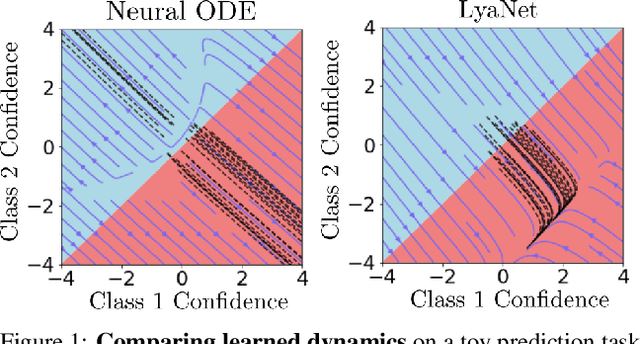
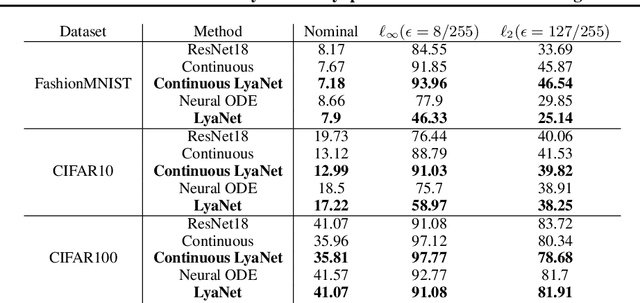
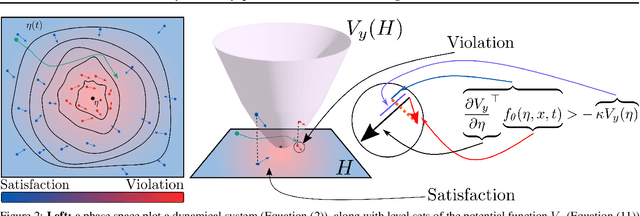
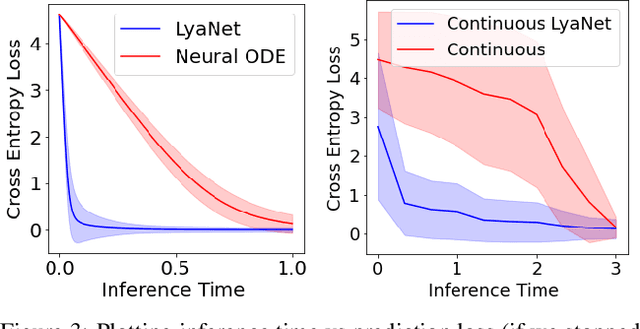
We propose a method for training ordinary differential equations by using a control-theoretic Lyapunov condition for stability. Our approach, called LyaNet, is based on a novel Lyapunov loss formulation that encourages the inference dynamics to converge quickly to the correct prediction. Theoretically, we show that minimizing Lyapunov loss guarantees exponential convergence to the correct solution and enables a novel robustness guarantee. We also provide practical algorithms, including one that avoids the cost of backpropagating through a solver or using the adjoint method. Relative to standard Neural ODE training, we empirically find that LyaNet can offer improved prediction performance, faster convergence of inference dynamics, and improved adversarial robustness. Our code available at https://github.com/ivandariojr/LyapunovLearning .
Onboard Safety Guarantees for Racing Drones: High-speed Geofencing with Control Barrier Functions
Jan 12, 2022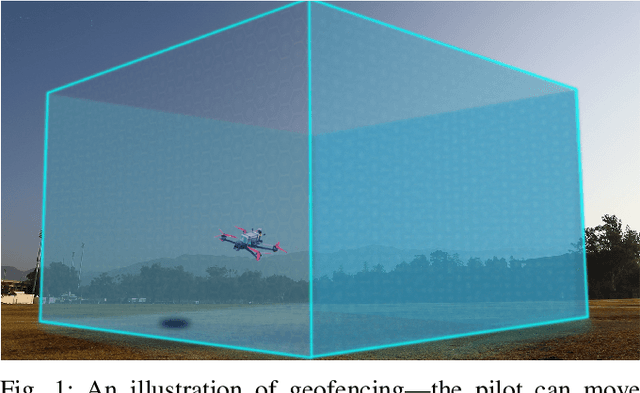
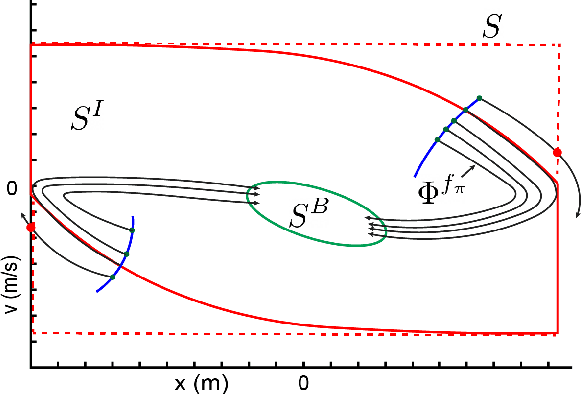
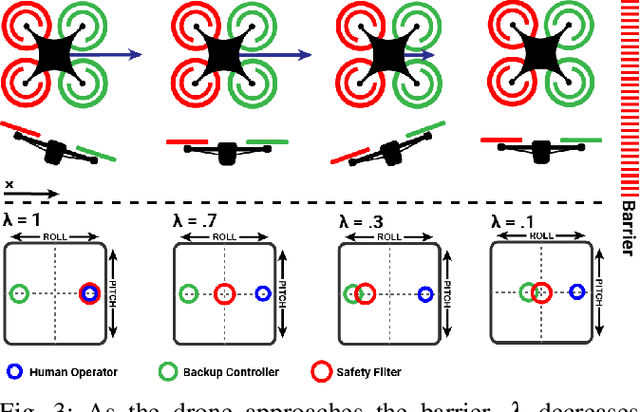
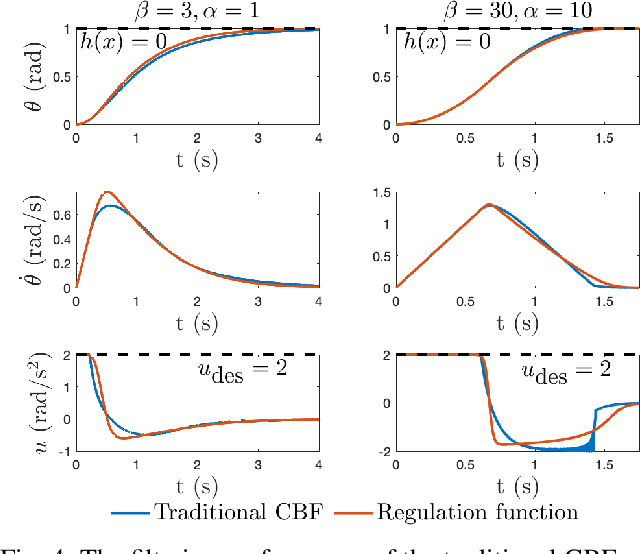
This paper details the theory and implementation behind practically ensuring safety of remotely piloted racing drones. We demonstrate robust and practical safety guarantees on a 7" racing drone at speeds exceeding 100 km/h, utilizing only online computations on a 10 gram micro-controller. To achieve this goal, we utilize the framework of control barrier functions (CBFs) which give guaranteed safety encoded as forward set invariance. To make this methodology practically applicable, we present an implicitly defined CBF which leverages backup controllers to enable gradient-free evaluations that ensure safety. The method applied to hardware results in smooth, minimally conservative alterations of the pilots' desired inputs, enabling them to push the limits of their drone without fear of crashing. Moreover, the method works in conjunction with the preexisting flight controller, resulting in unaltered flight when there are no nearby safety risks. Additional benefits include safety and stability of the drone when losing line-of-sight or in the event of radio failure.
Test and Evaluation of Quadrupedal Walking Gaits through Sim2Real Gap Quantification
Jan 04, 2022
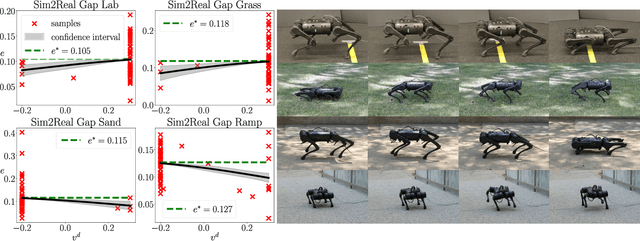
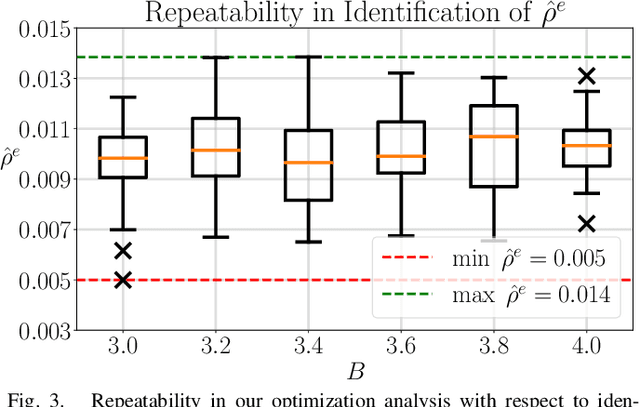
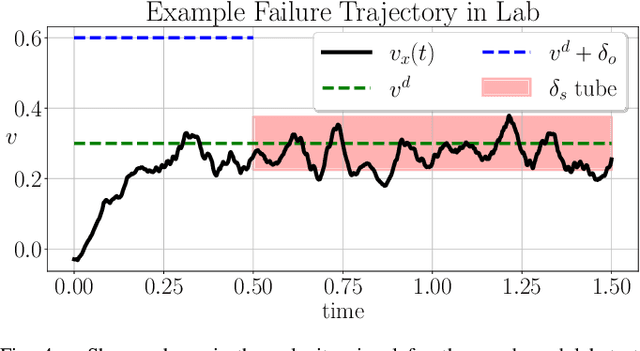
In this letter, the authors propose a two-step approach to evaluate and verify a true system's capacity to satisfy its operational objective. Specifically, whenever the system objective has a quantifiable measure of satisfaction, i.e. a signal temporal logic specification, a barrier function, etc - the authors develop two separate optimization problems solvable via a Bayesian Optimization procedure detailed within. This dual approach has the added benefit of quantifying the Sim2Real Gap between a system simulator and its hardware counterpart. Our contributions are twofold. First, we show repeatability with respect to our outlined optimization procedure in solving these optimization problems. Second, we show that the same procedure can discriminate between different environments by identifying the Sim2Real Gap between a simulator and its hardware counterpart operating in different environments.
Safety-Aware Preference-Based Learning for Safety-Critical Control
Dec 15, 2021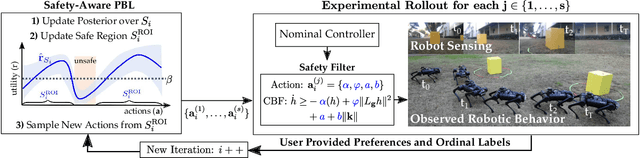
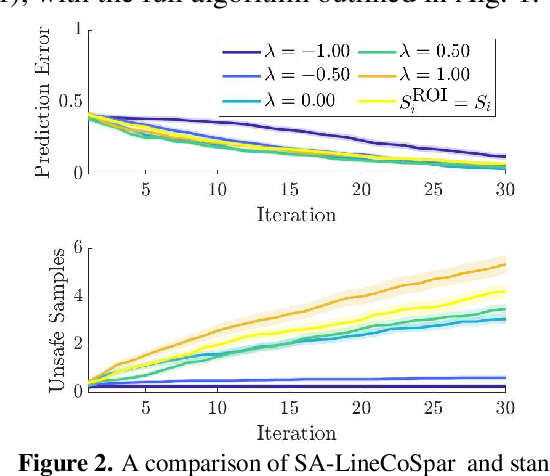
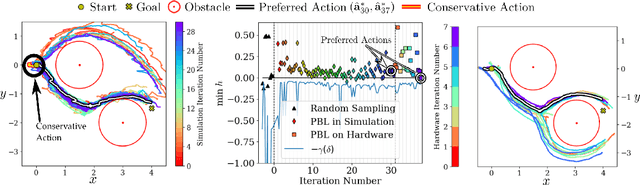

Bringing dynamic robots into the wild requires a tenuous balance between performance and safety. Yet controllers designed to provide robust safety guarantees often result in conservative behavior, and tuning these controllers to find the ideal trade-off between performance and safety typically requires domain expertise or a carefully constructed reward function. This work presents a design paradigm for systematically achieving behaviors that balance performance and robust safety by integrating safety-aware Preference-Based Learning (PBL) with Control Barrier Functions (CBFs). Fusing these concepts -- safety-aware learning and safety-critical control -- gives a robust means to achieve safe behaviors on complex robotic systems in practice. We demonstrate the capability of this design paradigm to achieve safe and performant perception-based autonomous operation of a quadrupedal robot both in simulation and experimentally on hardware.
Safety-Critical Control with Input Delay in Dynamic Environment
Dec 15, 2021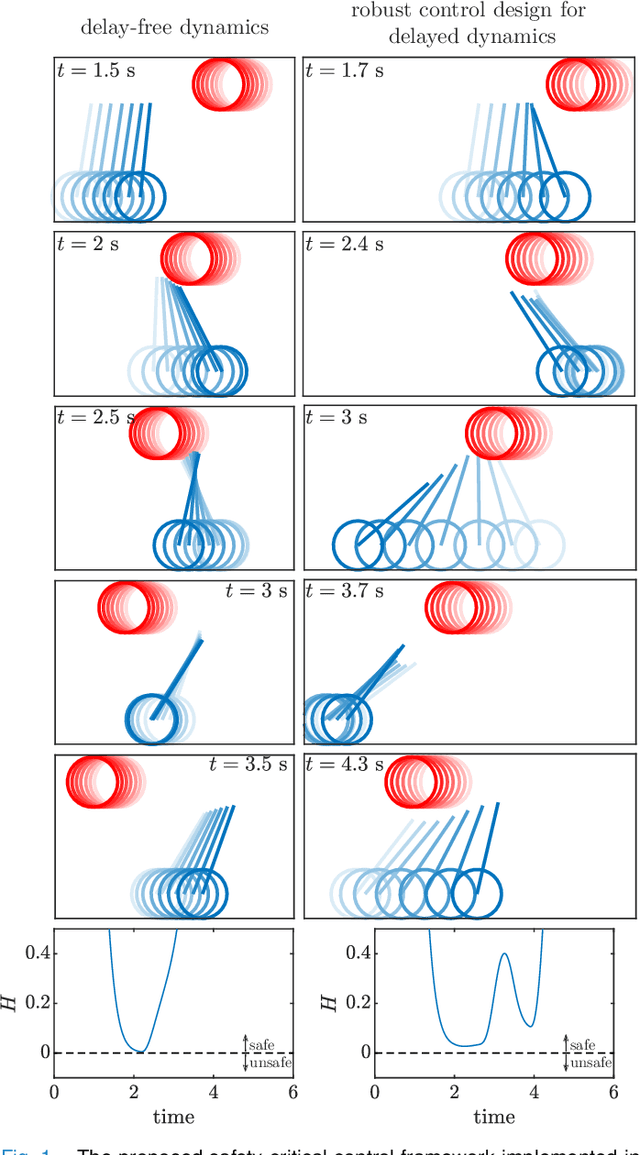
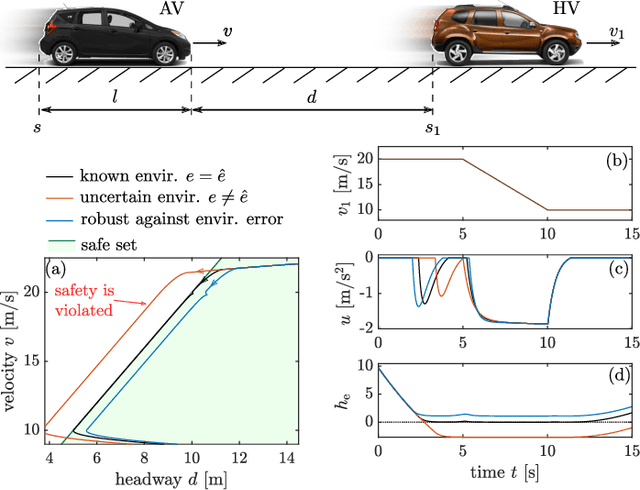
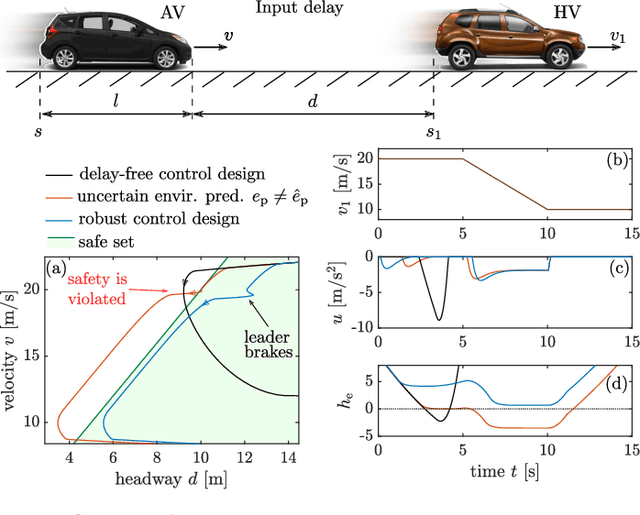
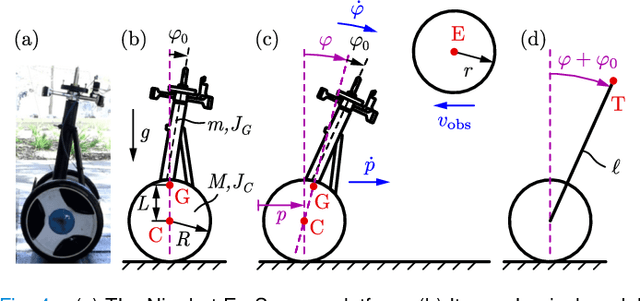
Endowing nonlinear systems with safe behavior is increasingly important in modern control. This task is particularly challenging for real-life control systems that must operate safely in dynamically changing environments. This paper develops a framework for safety-critical control in dynamic environments, by establishing the notion of environmental control barrier functions (ECBFs). The framework is able to guarantee safety even in the presence of input delay, by accounting for the evolution of the environment during the delayed response of the system. The underlying control synthesis relies on predicting the future state of the system and the environment over the delay interval, with robust safety guarantees against prediction errors. The efficacy of the proposed method is demonstrated by a simple adaptive cruise control problem and a more complex robotics application on a Segway platform.
Mixed Observable RRT: Multi-Agent Mission-Planning in Partially Observable Environments
Oct 03, 2021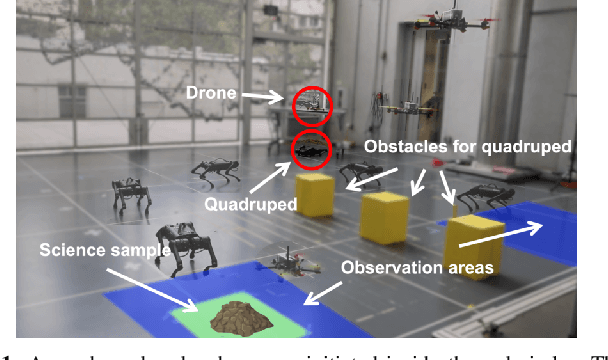
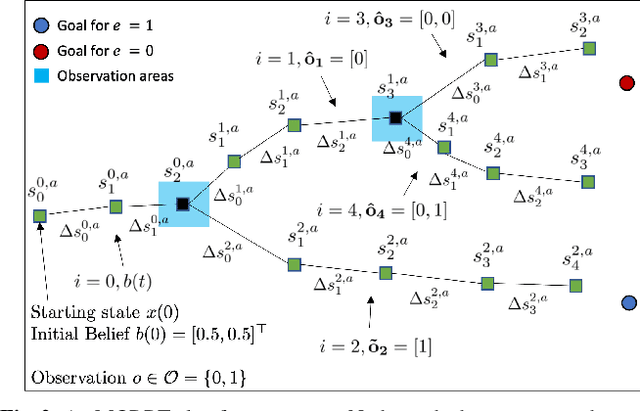

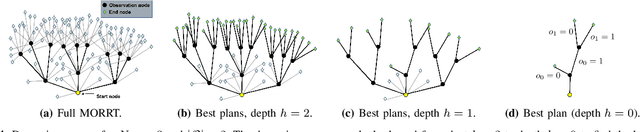
This paper considers centralized mission-planning for a heterogeneous multi-agent system with the aim of locating a hidden target. We propose a mixed observable setting, consisting of a fully observable state-space and a partially observable environment, using a hidden Markov model. First, we construct rapidly exploring random trees (RRTs) to introduce the mixed observable RRT for finding plausible mission plans giving way-points for each agent. Leveraging this construction, we present a path-selection strategy based on a dynamic programming approach, which accounts for the uncertainty from partial observations and minimizes the expected cost. Finally, we combine the high-level plan with model predictive controllers to evaluate the approach on an experimental setup consisting of a quadruped robot and a drone. It is shown that agents are able to make intelligent decisions to explore the area efficiently and to locate the target through collaborative actions.
Model-Free Safety-Critical Control for Robotic Systems
Sep 19, 2021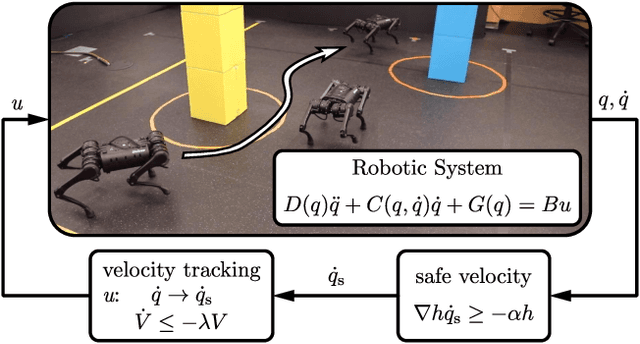
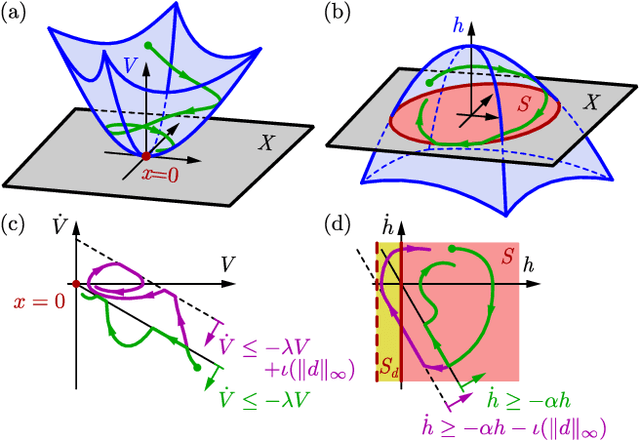
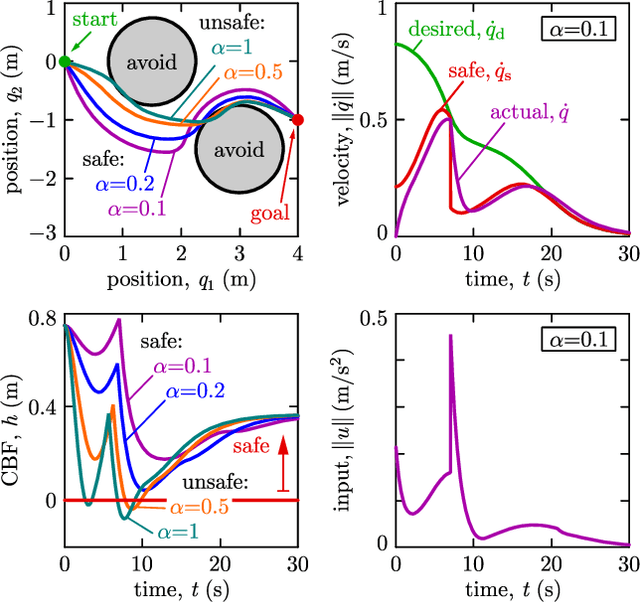
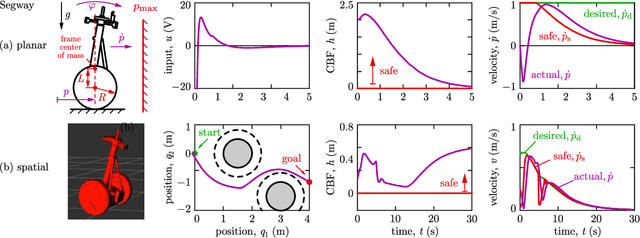
This paper presents a framework for the safety-critical control of robotic systems, when safety is defined on safe regions in the configuration space. To maintain safety, we synthesize a safe velocity based on control barrier function theory without relying on a -- potentially complicated -- high-fidelity dynamical model of the robot. Then, we track the safe velocity with a tracking controller. This culminates in model-free safety critical control. We prove theoretical safety guarantees for the proposed method. Finally, we demonstrate that this approach is application-agnostic. We execute an obstacle avoidance task with a Segway in high-fidelity simulation, as well as with a Drone and a Quadruped in hardware experiments.
Interactive multi-modal motion planning with Branch Model Predictive Control
Sep 18, 2021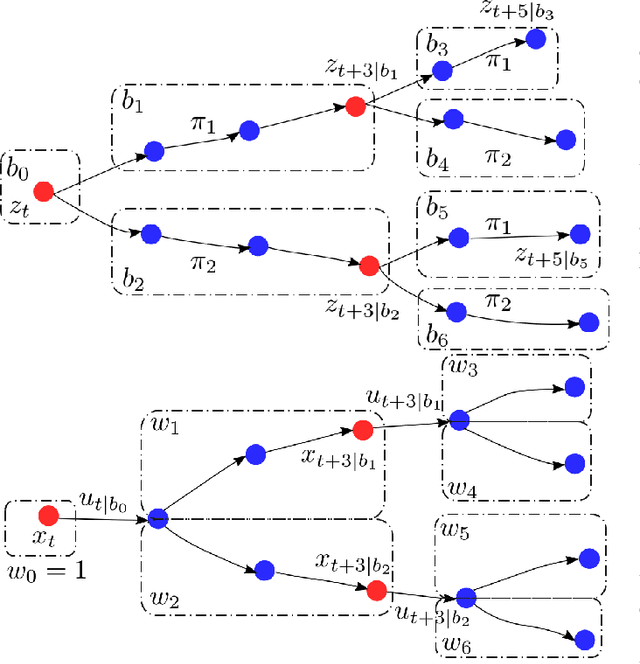
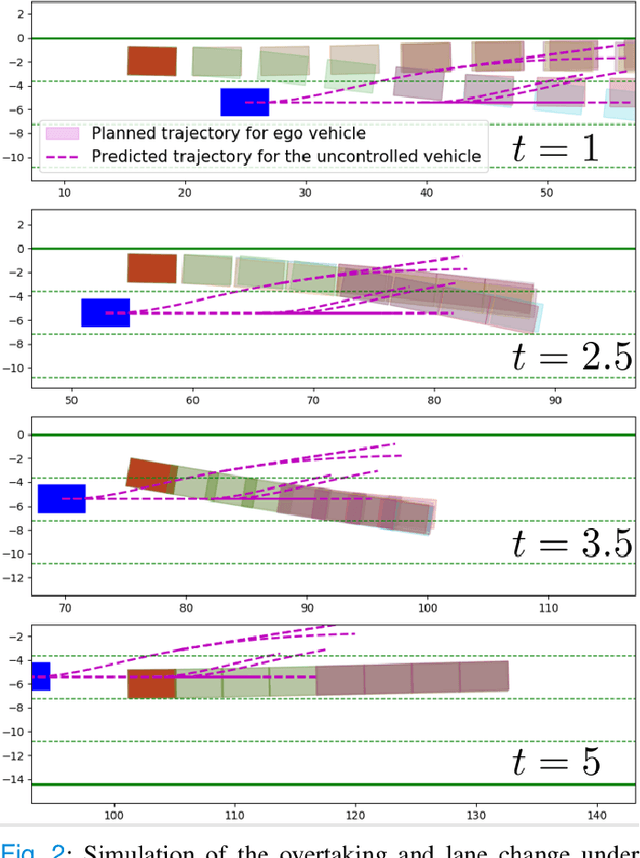
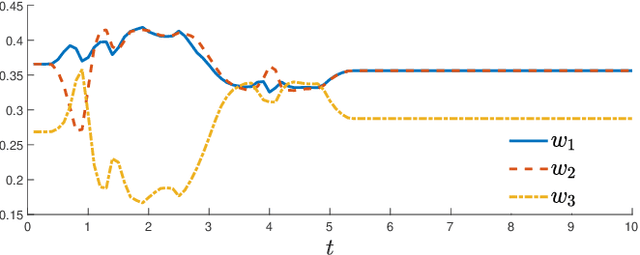
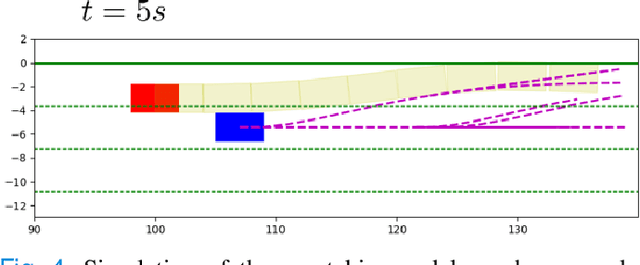
Motion planning for autonomous robots and vehicles in presence of uncontrolled agents remains a challenging problem as the reactive behaviors of the uncontrolled agents must be considered. Since the uncontrolled agents usually demonstrate multimodal reactive behavior, the motion planner needs to solve a continuous motion planning problem under these behaviors, which contains a discrete element. We propose a branch Model Predictive Control (MPC) framework that plans over feedback policies to leverage the reactive behavior of the uncontrolled agent. In particular, a scenario tree is constructed from a finite set of policies of the uncontrolled agent, and the branch MPC solves for a feedback policy in the form of a trajectory tree, which shares the same topology as the scenario tree. Moreover, coherent risk measures such as the Conditional Value at Risk (CVaR) are used as a tuning knob to adjust the tradeoff between performance and robustness. The proposed branch MPC framework is tested on an overtake and lane change task and a merging task for autonomous vehicles in simulation, and on the motion planning of an autonomous quadruped robot alongside an uncontrolled quadruped in experiments. The result demonstrates interesting human-like behaviors, achieving a balance between safety and performance.
Natural Multicontact Walking for Robotic Assistive Devices via Musculoskeletal Models and Hybrid Zero Dynamics
Sep 10, 2021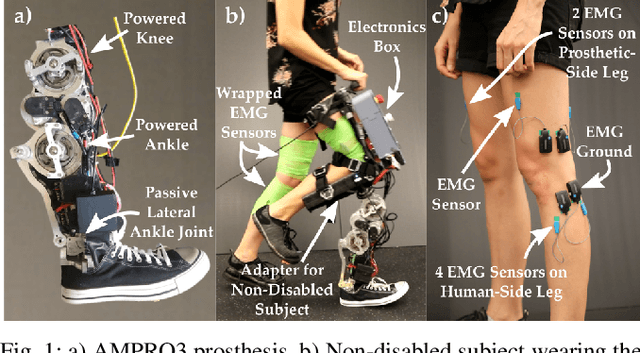
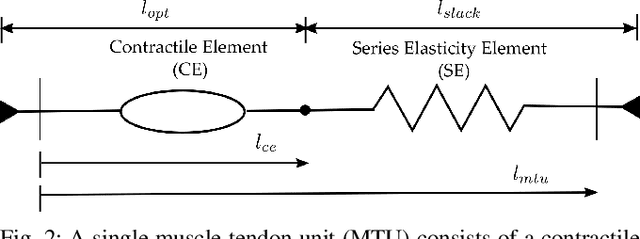
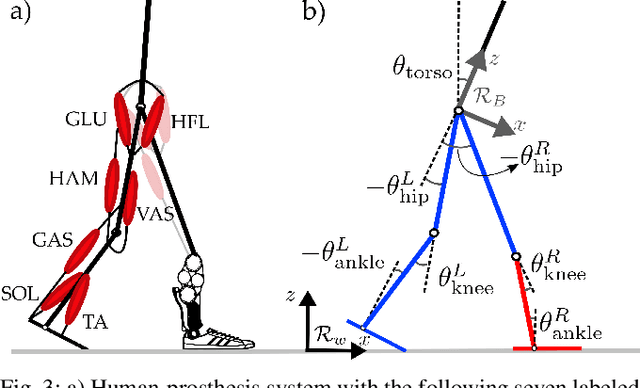
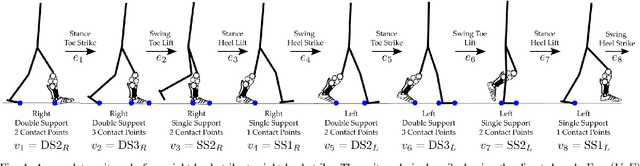
Generating provably stable walking gaits that yield natural locomotion when executed on robotic-assistive devices is a challenging task that often requires hand-tuning by domain experts. This paper presents an alternative methodology, where we propose the addition of musculoskeletal models directly into the gait generation process to intuitively shape the resulting behavior. In particular, we construct a multi-domain hybrid system model that combines the system dynamics with muscle models to represent natural multicontact walking. Stable walking gaits can then be formally generated for this model via the hybrid zero dynamics method. We experimentally apply our framework towards achieving multicontact locomotion on a dual-actuated transfemoral prosthesis, AMPRO3. The results demonstrate that enforcing feasible muscle dynamics produces gaits that yield natural locomotion (as analyzed via electromyography), without the need for extensive manual tuning. Moreover, these gaits yield similar behavior to expert-tuned gaits. We conclude that the novel approach of combining robotic walking methods (specifically HZD) with muscle models successfully generates anthropomorphic robotic-assisted locomotion.
Risk-Averse Decision Making Under Uncertainty
Sep 09, 2021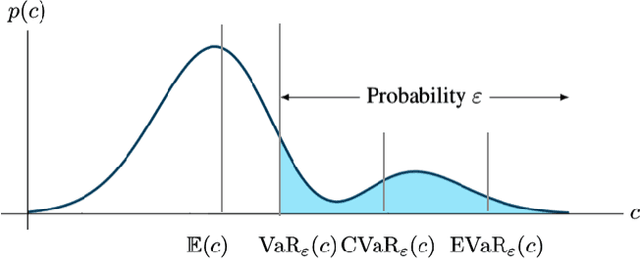


A large class of decision making under uncertainty problems can be described via Markov decision processes (MDPs) or partially observable MDPs (POMDPs), with application to artificial intelligence and operations research, among others. Traditionally, policy synthesis techniques are proposed such that a total expected cost or reward is minimized or maximized. However, optimality in the total expected cost sense is only reasonable if system behavior in the large number of runs is of interest, which has limited the use of such policies in practical mission-critical scenarios, wherein large deviations from the expected behavior may lead to mission failure. In this paper, we consider the problem of designing policies for MDPs and POMDPs with objectives and constraints in terms of dynamic coherent risk measures, which we refer to as the constrained risk-averse problem. For MDPs, we reformulate the problem into a infsup problem via the Lagrangian framework and propose an optimization-based method to synthesize Markovian policies. For MDPs, we demonstrate that the formulated optimization problems are in the form of difference convex programs (DCPs) and can be solved by the disciplined convex-concave programming (DCCP) framework. We show that these results generalize linear programs for constrained MDPs with total discounted expected costs and constraints. For POMDPs, we show that, if the coherent risk measures can be defined as a Markov risk transition mapping, an infinite-dimensional optimization can be used to design Markovian belief-based policies. For stochastic finite-state controllers (FSCs), we show that the latter optimization simplifies to a (finite-dimensional) DCP and can be solved by the DCCP framework. We incorporate these DCPs in a policy iteration algorithm to design risk-averse FSCs for POMDPs.