 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Two-Staged Acoustic Modeling Adaption for Robust Speech Recognition by the Example of German Oral History Interviews
Aug 19, 2019
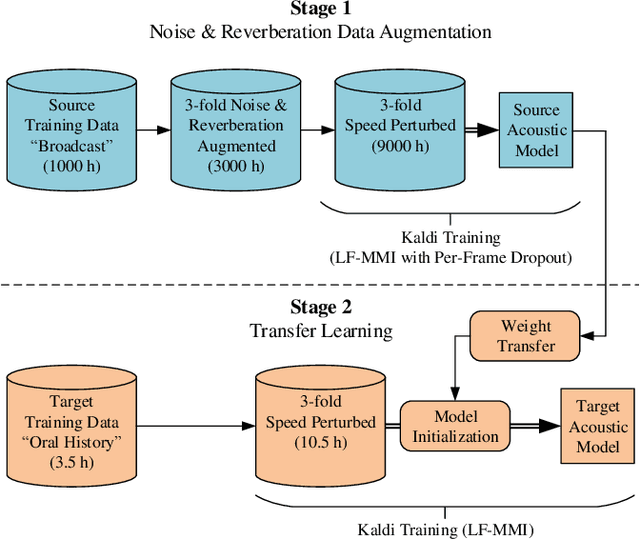


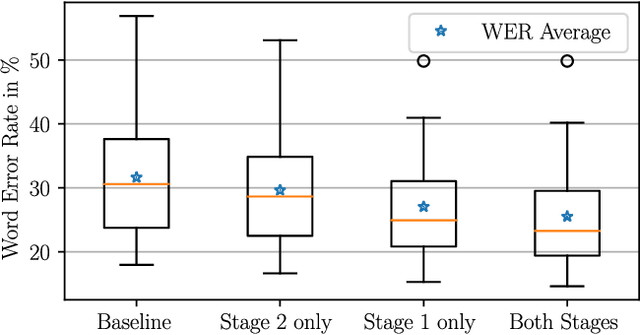
In automatic speech recognition, often little training data is available for specific challenging tasks, but training of state-of-the-art automatic speech recognition systems requires large amounts of annotated speech. To address this issue, we propose a two-staged approach to acoustic modeling that combines noise and reverberation data augmentation with transfer learning to robustly address challenges such as difficult acoustic recording conditions, spontaneous speech, and speech of elderly people. We evaluate our approach using the example of German oral history interviews, where a relative average reduction of the word error rate by 19.3% is achieved.
* Accepted for IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, July 2019
Attentive Temporal Pooling for Conformer-based Streaming Language Identification in Long-form Speech
Feb 24, 2022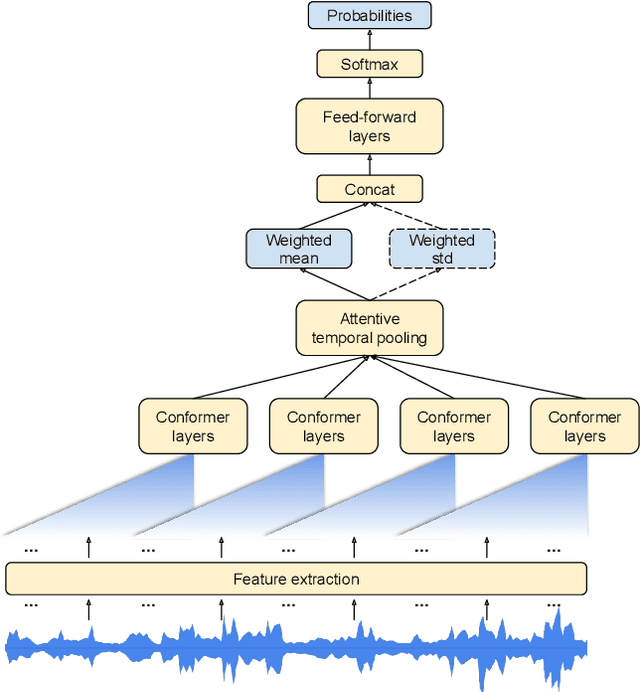
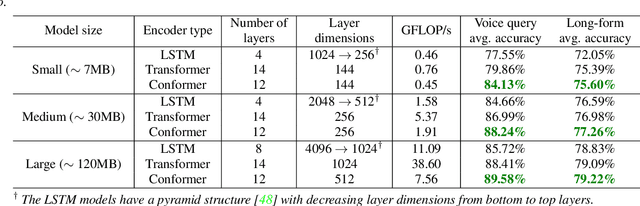
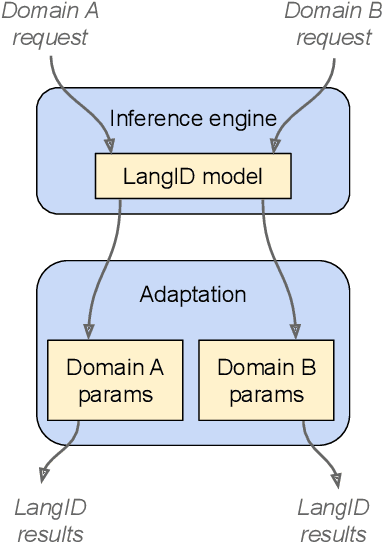
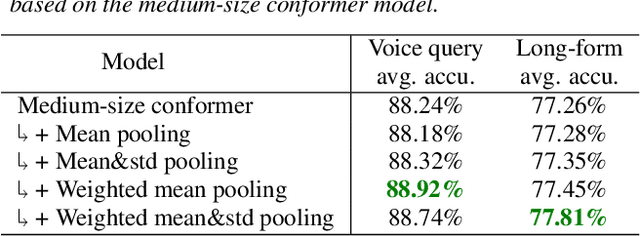
In this paper, we introduce a novel language identification system based on conformer layers. We propose an attentive temporal pooling mechanism to allow the model to carry information in long-form audio via a recurrent form, such that the inference can be performed in a streaming fashion. Additionally, a simple domain adaptation mechanism is introduced to allow adapting an existing language identification model to a new domain where the prior language distribution is different. We perform a comparative study of different model topologies under different constraints of model size, and find that conformer-base models outperform LSTM and transformer based models. Our experiments also show that attentive temporal pooling and domain adaptation significantly improve the model accuracy.
A small Griko-Italian speech translation corpus
Jul 27, 2018


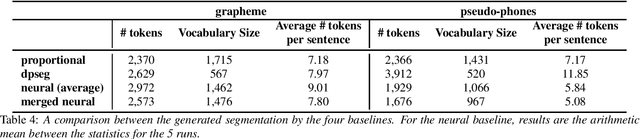
This paper presents an extension to a very low-resource parallel corpus collected in an endangered language, Griko, making it useful for computational research. The corpus consists of 330 utterances (about 20 minutes of speech) which have been transcribed and translated in Italian, with annotations for word-level speech-to-transcription and speech-to-translation alignments. The corpus also includes morphosyntactic tags and word-level glosses. Applying an automatic unit discovery method, pseudo-phones were also generated. We detail how the corpus was collected, cleaned and processed, and we illustrate its use on zero-resource tasks by presenting some baseline results for the task of speech-to-translation alignment and unsupervised word discovery. The dataset is available online, aiming to encourage replicability and diversity in computational language documentation experiments.
Speech Map: A Statistical Multimodal Atlas of 4D Tongue Motion During Speech from Tagged and Cine MR Images
Sep 15, 2018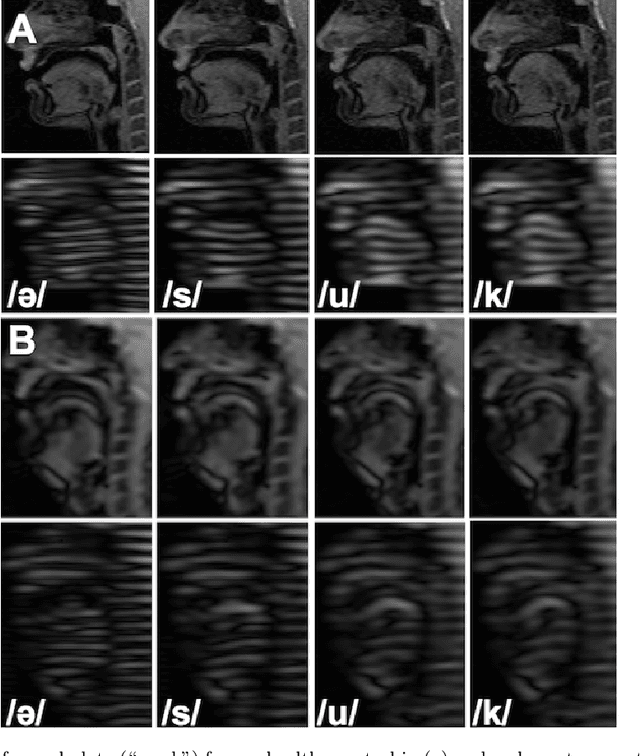
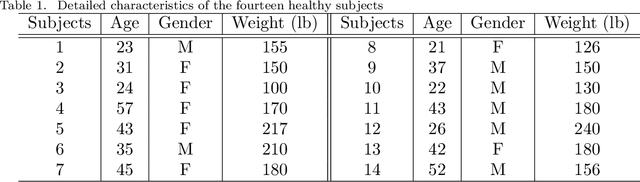

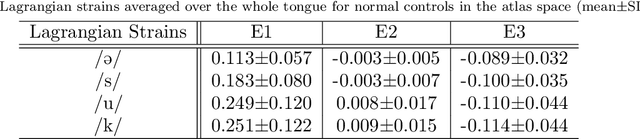
Quantitative measurement of functional and anatomical traits of 4D tongue motion in the course of speech or other lingual behaviors remains a major challenge in scientific research and clinical applications. Here, we introduce a statistical multimodal atlas of 4D tongue motion using healthy subjects, which enables a combined quantitative characterization of tongue motion in a reference anatomical configuration. This atlas framework, termed Speech Map, combines cine- and tagged-MRI in order to provide both the anatomic reference and motion information during speech. Our approach involves a series of steps including (1) construction of a common reference anatomical configuration from cine-MRI, (2) motion estimation from tagged-MRI, (3) transformation of the motion estimations to the reference anatomical configuration, and (4) computation of motion quantities such as Lagrangian strain. Using this framework, the anatomic configuration of the tongue appears motionless, while the motion fields and associated strain measurements change over the time course of speech. In addition, to form a succinct representation of the high-dimensional and complex motion fields, principal component analysis is carried out to characterize the central tendencies and variations of motion fields of our speech tasks. Our proposed method provides a platform to quantitatively and objectively explain the differences and variability of tongue motion by illuminating internal motion and strain that have so far been intractable. The findings are used to understand how tongue function for speech is limited by abnormal internal motion and strain in glossectomy patients.
Right-wing German Hate Speech on Twitter: Analysis and Automatic Detection
Oct 16, 2019
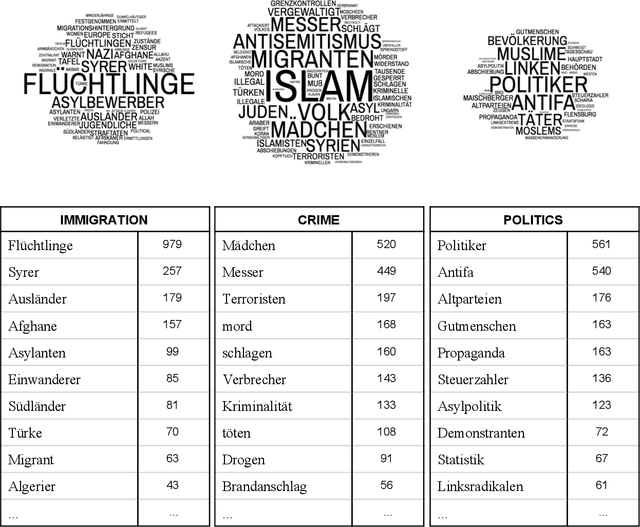
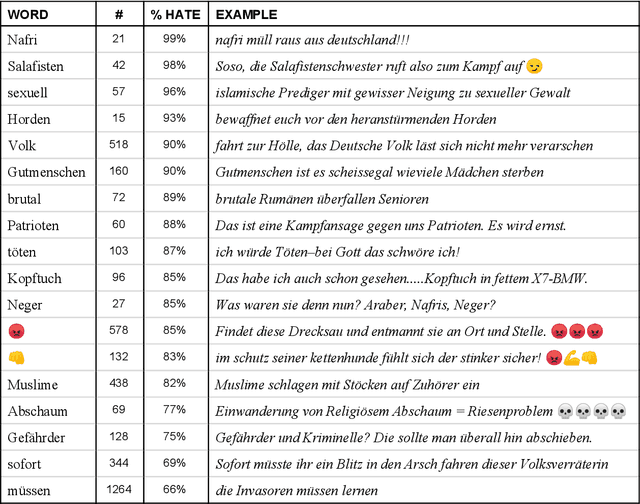
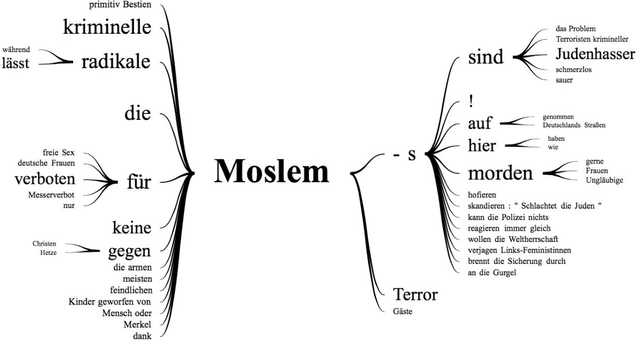
Discussion about the social network Twitter often concerns its role in political discourse, involving the question of when an expression of opinion becomes offensive, immoral, and/or illegal, and how to deal with it. Given the growing amount of offensive communication on the internet, there is a demand for new technology that can automatically detect hate speech, to assist content moderation by humans. This comes with new challenges, such as defining exactly what is free speech and what is illegal in a specific country, and knowing exactly what the linguistic characteristics of hate speech are. To shed light on the German situation, we analyzed over 50,000 right-wing German hate tweets posted between August 2017 and April 2018, at the time of the 2017 German federal elections, using both quantitative and qualitative methods. In this paper, we discuss the results of the analysis and demonstrate how the insights can be employed for the development of automatic detection systems.
Multi-task RNN-T with Semantic Decoder for Streamable Spoken Language Understanding
Apr 01, 2022
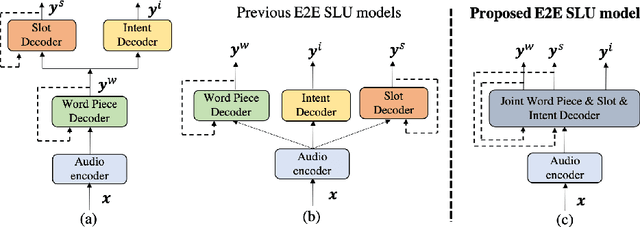
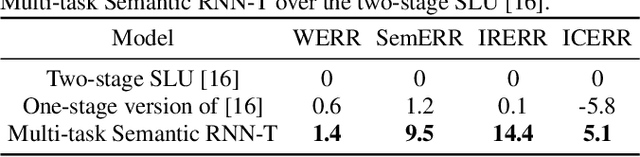
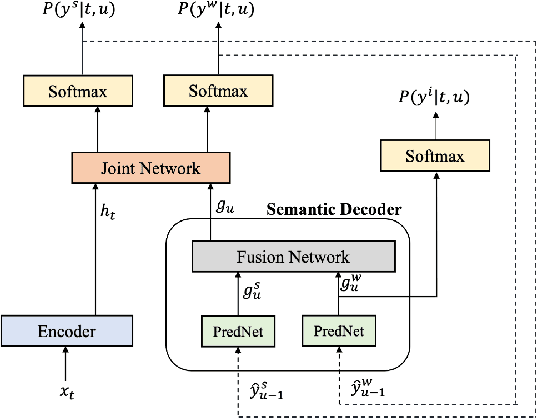
End-to-end Spoken Language Understanding (E2E SLU) has attracted increasing interest due to its advantages of joint optimization and low latency when compared to traditionally cascaded pipelines. Existing E2E SLU models usually follow a two-stage configuration where an Automatic Speech Recognition (ASR) network first predicts a transcript which is then passed to a Natural Language Understanding (NLU) module through an interface to infer semantic labels, such as intent and slot tags. This design, however, does not consider the NLU posterior while making transcript predictions, nor correct the NLU prediction error immediately by considering the previously predicted word-pieces. In addition, the NLU model in the two-stage system is not streamable, as it must wait for the audio segments to complete processing, which ultimately impacts the latency of the SLU system. In this work, we propose a streamable multi-task semantic transducer model to address these considerations. Our proposed architecture predicts ASR and NLU labels auto-regressively and uses a semantic decoder to ingest both previously predicted word-pieces and slot tags while aggregating them through a fusion network. Using an industry scale SLU and a public FSC dataset, we show the proposed model outperforms the two-stage E2E SLU model for both ASR and NLU metrics.
Leveraging End-to-End Speech Recognition with Neural Architecture Search
Dec 11, 2019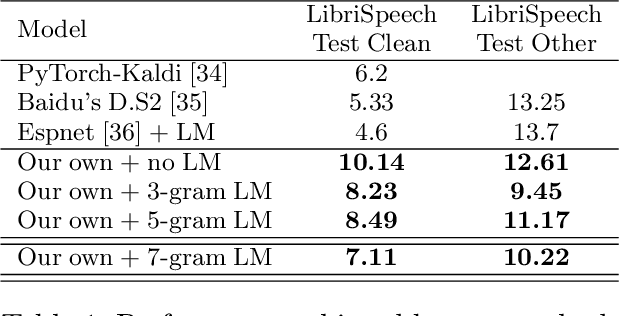
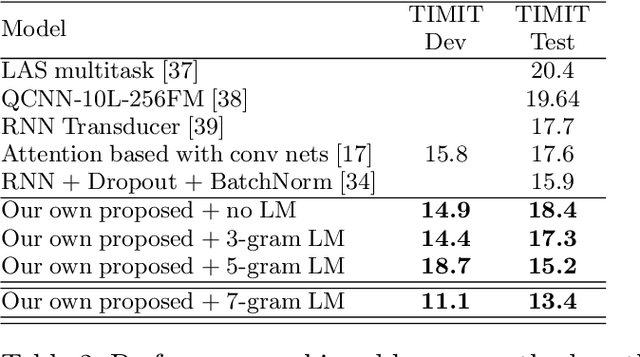

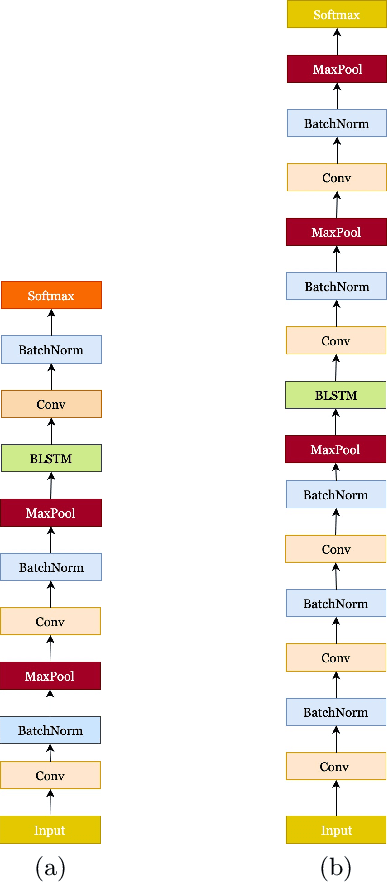
Deep neural networks (DNNs) have been demonstrated to outperform many traditional machine learning algorithms in Automatic Speech Recognition (ASR). In this paper, we show that a large improvement in the accuracy of deep speech models can be achieved with effective Neural Architecture Optimization at a very low computational cost. Phone recognition tests with the popular LibriSpeech and TIMIT benchmarks proved this fact by displaying the ability to discover and train novel candidate models within a few hours (less than a day) many times faster than the attention-based seq2seq models. Our method achieves test error of 7% Word Error Rate (WER) on the LibriSpeech corpus and 13% Phone Error Rate (PER) on the TIMIT corpus, on par with state-of-the-art results.
Quantitative phase and absorption contrast imaging
Mar 23, 2022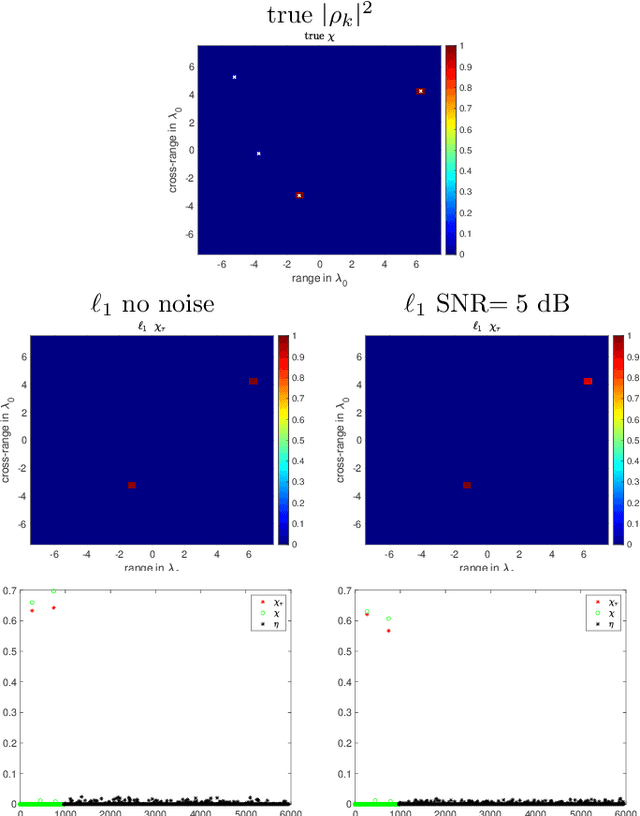
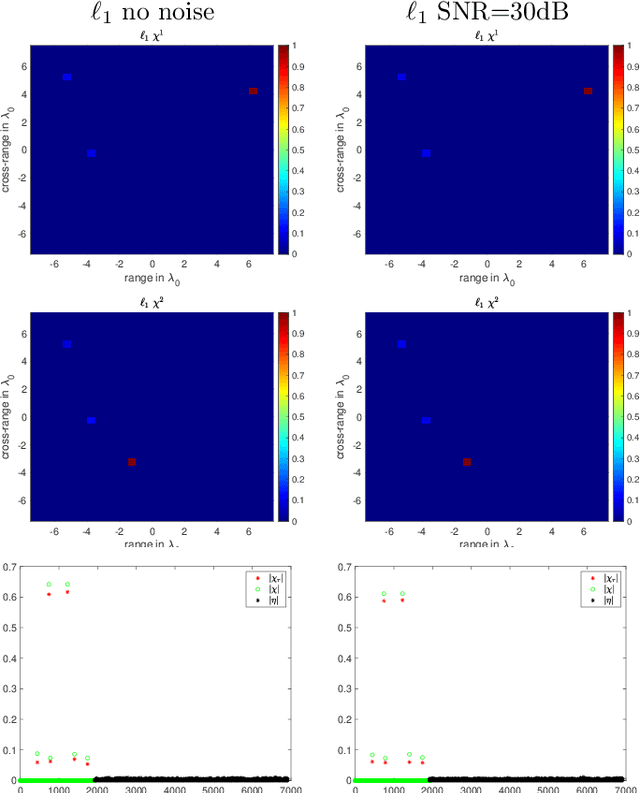
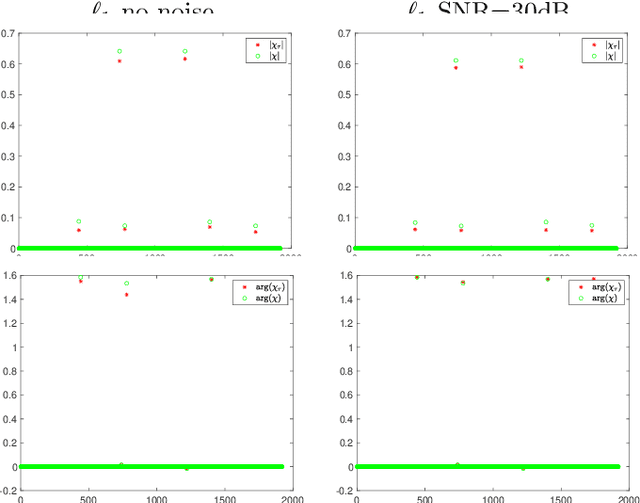
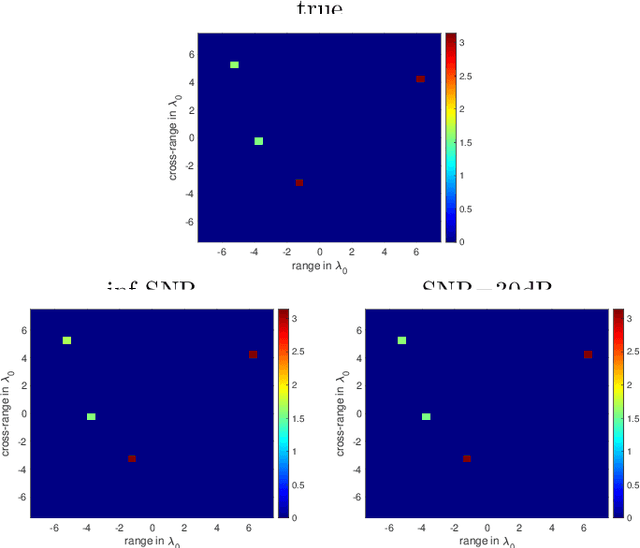
Phase retrieval in its most general form is the problem of reconstructing a complex valued function from phaseless information of some transform of that function. This problem arises in various fields such as X-ray crystallography, electron microscopy, coherent diffractive imaging, astronomy, speech recognition, and quantum mechanics. The mathematical and computational analysis of these problems has a long history and a variety of different algorithms has been proposed in the literature. The performance of which usually depends on the constraints imposed on the sought function and the number of measurements. In this paper, we present an algorithm for coherent diffractive imaging with phaseless measurements. The algorithm accounts for both coherent and incoherent wave propagation and allows for reconstructing absorption as well as phase images that quantify the attenuation and the refraction of the waves when they go through an object. The algorithm requires coherent or partially coherent illumination, and several detectors to record the intensity of the distorted wave that passes through the object under inspection. To obtain enough information for imaging, a series of masks are introduced between the source and the object that create a diversity of illumination patterns.
MeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021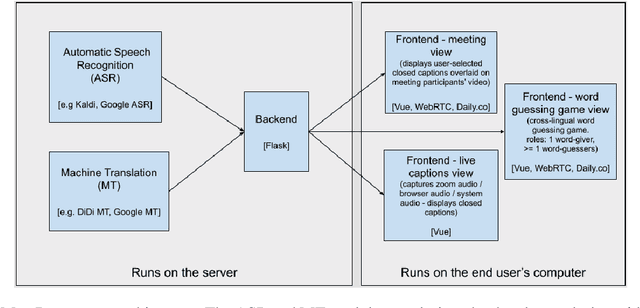

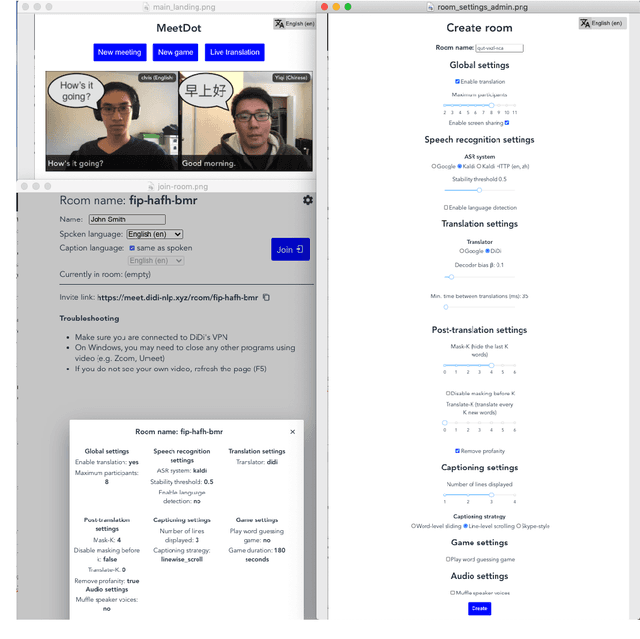
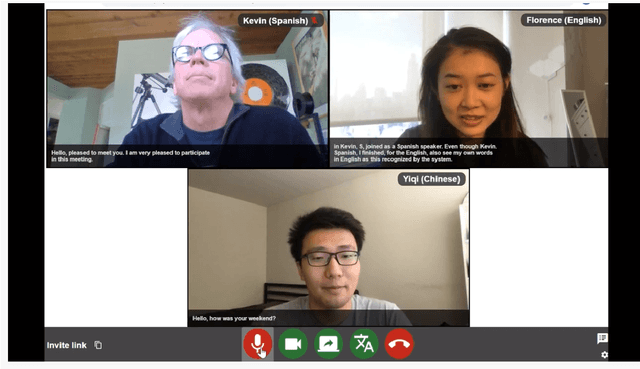
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
A Context-Aware Feature Fusion Framework for Punctuation Restoration
Mar 23, 2022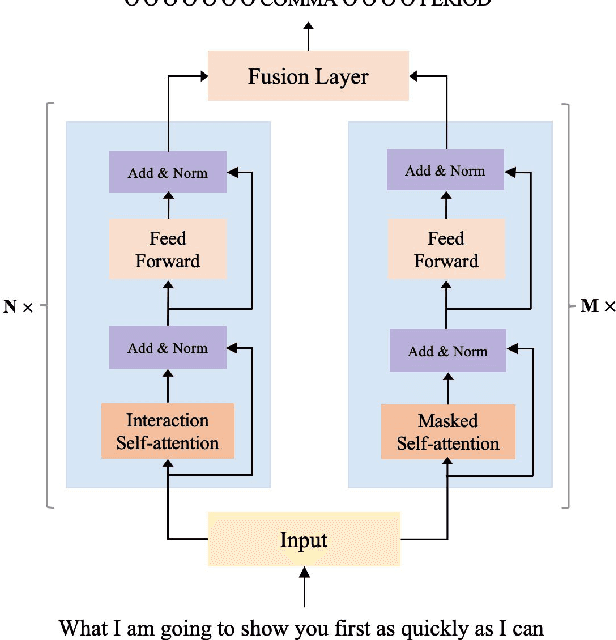
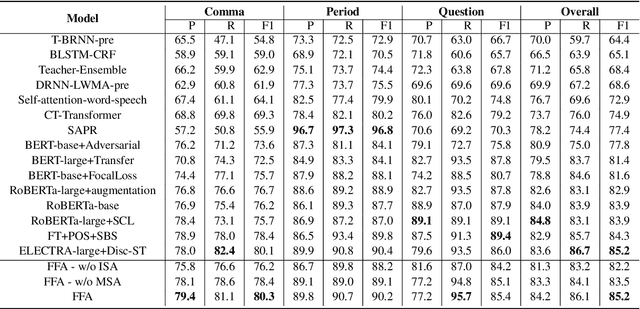
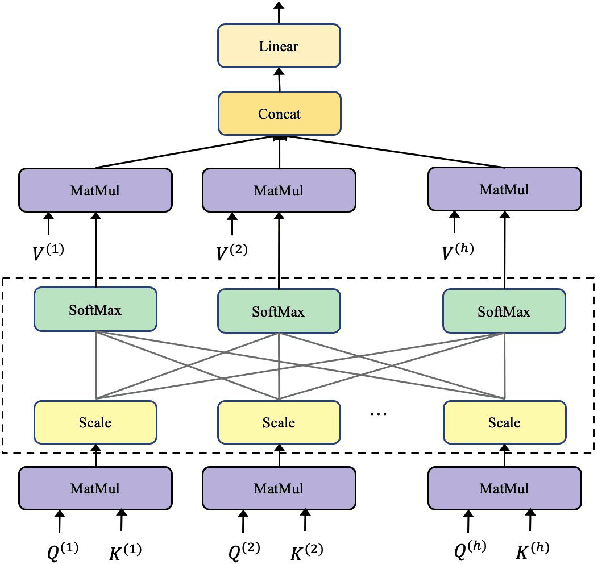
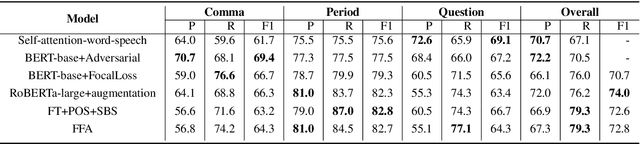
To accomplish the punctuation restoration task, most existing approaches focused on leveraging extra information (e.g., part-of-speech tags) or addressing the class imbalance problem. Recent works have widely applied the transformer-based language models and significantly improved their effectiveness. To the best of our knowledge, an inherent issue has remained neglected: the attention of individual heads in the transformer will be diluted or powerless while feeding the long non-punctuation utterances. Since those previous contexts, not the followings, are comparatively more valuable to the current position, it's hard to achieve a good balance by independent attention. In this paper, we propose a novel Feature Fusion framework based on two-type Attentions (FFA) to alleviate the shortage. It introduces a two-stream architecture. One module involves interaction between attention heads to encourage the communication, and another masked attention module captures the dependent feature representation. Then, it aggregates two feature embeddings to fuse information and enhances context-awareness. The experiments on the popular benchmark dataset IWSLT demonstrate that our approach is effective. Without additional data, it obtains comparable performance to the current state-of-the-art models.