 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModalities, a PyTorch-native Framework For Large-scale LLM Training and Research
Feb 09, 2026Today's LLM (pre-) training and research workflows typically allocate a significant amount of compute to large-scale ablation studies. Despite the substantial compute costs of these ablations, existing open-source frameworks provide limited tooling for these experiments, often forcing researchers to write their own wrappers and scripts. We propose Modalities, an end-to-end PyTorch-native framework that integrates data-driven LLM research with large-scale model training from two angles. Firstly, by integrating state-of-the-art parallelization strategies, it enables both efficient pretraining and systematic ablations at trillion-token and billion-parameter scale. Secondly, Modalities adopts modular design with declarative, self-contained configuration, enabling reproducibility and extensibility levels that are difficult to achieve out-of-the-box with existing LLM training frameworks.
Judging Quality Across Languages: A Multilingual Approach to Pretraining Data Filtering with Language Models
May 28, 2025



High-quality multilingual training data is essential for effectively pretraining large language models (LLMs). Yet, the availability of suitable open-source multilingual datasets remains limited. Existing state-of-the-art datasets mostly rely on heuristic filtering methods, restricting both their cross-lingual transferability and scalability. Here, we introduce JQL, a systematic approach that efficiently curates diverse and high-quality multilingual data at scale while significantly reducing computational demands. JQL distills LLMs' annotation capabilities into lightweight annotators based on pretrained multilingual embeddings. These models exhibit robust multilingual and cross-lingual performance, even for languages and scripts unseen during training. Evaluated empirically across 35 languages, the resulting annotation pipeline substantially outperforms current heuristic filtering methods like Fineweb2. JQL notably enhances downstream model training quality and increases data retention rates. Our research provides practical insights and valuable resources for multilingual data curation, raising the standards of multilingual dataset development.
Towards Multilingual LLM Evaluation for European Languages
Oct 17, 2024



The rise of Large Language Models (LLMs) has revolutionized natural language processing across numerous languages and tasks. However, evaluating LLM performance in a consistent and meaningful way across multiple European languages remains challenging, especially due to the scarcity of language-parallel multilingual benchmarks. We introduce a multilingual evaluation approach tailored for European languages. We employ translated versions of five widely-used benchmarks to assess the capabilities of 40 LLMs across 21 European languages. Our contributions include examining the effectiveness of translated benchmarks, assessing the impact of different translation services, and offering a multilingual evaluation framework for LLMs that includes newly created datasets: EU20-MMLU, EU20-HellaSwag, EU20-ARC, EU20-TruthfulQA, and EU20-GSM8K. The benchmarks and results are made publicly available to encourage further research in multilingual LLM evaluation.
Data Processing for the OpenGPT-X Model Family
Oct 11, 2024



This paper presents a comprehensive overview of the data preparation pipeline developed for the OpenGPT-X project, a large-scale initiative aimed at creating open and high-performance multilingual large language models (LLMs). The project goal is to deliver models that cover all major European languages, with a particular focus on real-world applications within the European Union. We explain all data processing steps, starting with the data selection and requirement definition to the preparation of the final datasets for model training. We distinguish between curated data and web data, as each of these categories is handled by distinct pipelines, with curated data undergoing minimal filtering and web data requiring extensive filtering and deduplication. This distinction guided the development of specialized algorithmic solutions for both pipelines. In addition to describing the processing methodologies, we provide an in-depth analysis of the datasets, increasing transparency and alignment with European data regulations. Finally, we share key insights and challenges faced during the project, offering recommendations for future endeavors in large-scale multilingual data preparation for LLMs.
Towards Cross-Lingual LLM Evaluation for European Languages
Oct 11, 2024The rise of Large Language Models (LLMs) has revolutionized natural language processing across numerous languages and tasks. However, evaluating LLM performance in a consistent and meaningful way across multiple European languages remains challenging, especially due to the scarcity of multilingual benchmarks. We introduce a cross-lingual evaluation approach tailored for European languages. We employ translated versions of five widely-used benchmarks to assess the capabilities of 40 LLMs across 21 European languages. Our contributions include examining the effectiveness of translated benchmarks, assessing the impact of different translation services, and offering a multilingual evaluation framework for LLMs that includes newly created datasets: EU20-MMLU, EU20-HellaSwag, EU20-ARC, EU20-TruthfulQA, and EU20-GSM8K. The benchmarks and results are made publicly available to encourage further research in multilingual LLM evaluation.
A Study on the Ambiguity in Human Annotation of German Oral History Interviews for Perceived Emotion Recognition and Sentiment Analysis
Jan 18, 2022
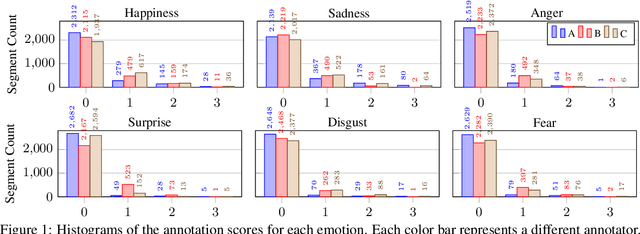
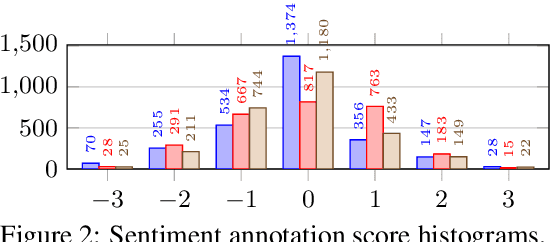
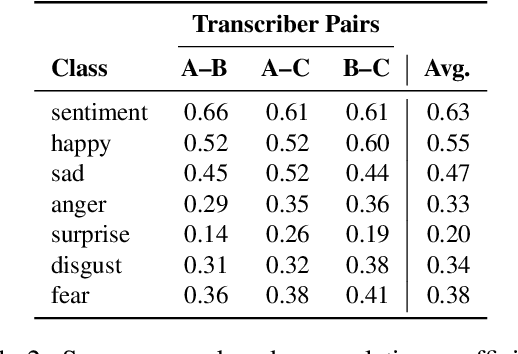
For research in audiovisual interview archives often it is not only of interest what is said but also how. Sentiment analysis and emotion recognition can help capture, categorize and make these different facets searchable. In particular, for oral history archives, such indexing technologies can be of great interest. These technologies can help understand the role of emotions in historical remembering. However, humans often perceive sentiments and emotions ambiguously and subjectively. Moreover, oral history interviews have multi-layered levels of complex, sometimes contradictory, sometimes very subtle facets of emotions. Therefore, the question arises of the chance machines and humans have capturing and assigning these into predefined categories. This paper investigates the ambiguity in human perception of emotions and sentiment in German oral history interviews and the impact on machine learning systems. Our experiments reveal substantial differences in human perception for different emotions. Furthermore, we report from ongoing machine learning experiments with different modalities. We show that the human perceptual ambiguity and other challenges, such as class imbalance and lack of training data, currently limit the opportunities of these technologies for oral history archives. Nonetheless, our work uncovers promising observations and possibilities for further research.
Human and Automatic Speech Recognition Performance on German Oral History Interviews
Jan 18, 2022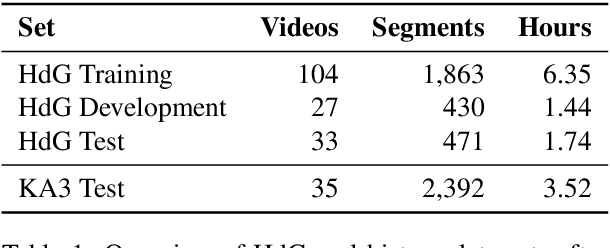
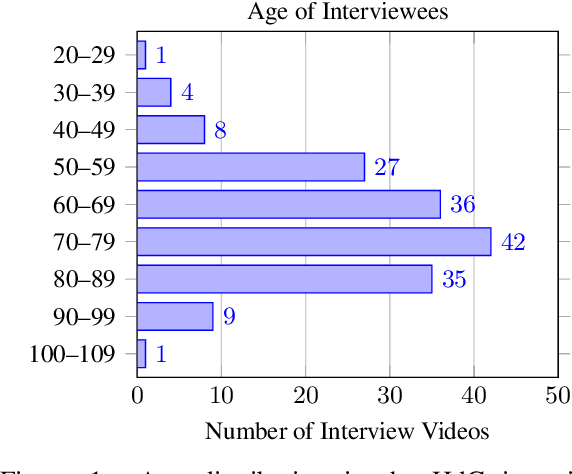
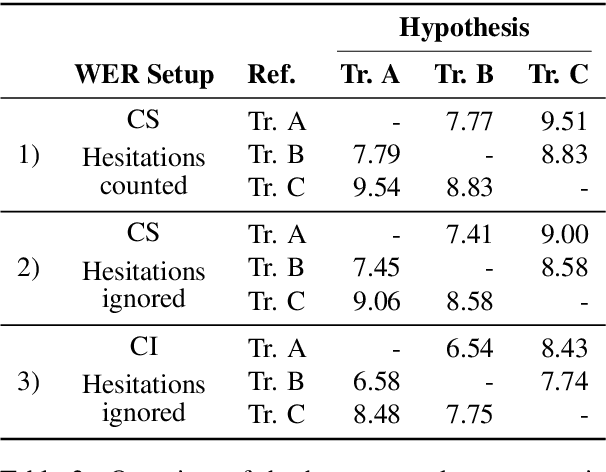
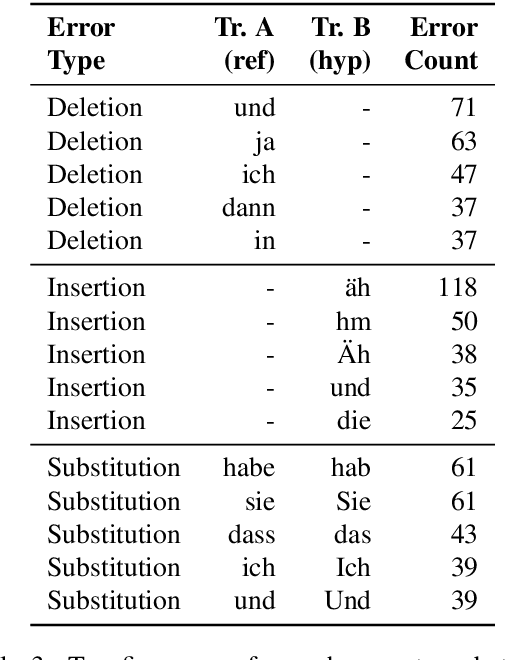
Automatic speech recognition systems have accomplished remarkable improvements in transcription accuracy in recent years. On some domains, models now achieve near-human performance. However, transcription performance on oral history has not yet reached human accuracy. In the present work, we investigate how large this gap between human and machine transcription still is. For this purpose, we analyze and compare transcriptions of three humans on a new oral history data set. We estimate a human word error rate of 8.7% for recent German oral history interviews with clean acoustic conditions. For comparison with recent machine transcription accuracy, we present experiments on the adaptation of an acoustic model achieving near-human performance on broadcast speech. We investigate the influence of different adaptation data on robustness and generalization for clean and noisy oral history interviews. We optimize our acoustic models by 5 to 8% relative for this task and achieve 23.9% WER on noisy and 15.6% word error rate on clean oral history interviews.
Tab.IAIS: Flexible Table Recognition and Semantic Interpretation System
May 25, 2021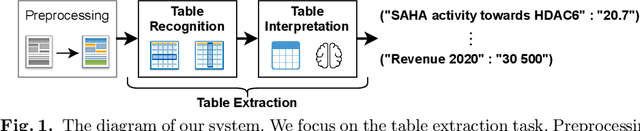

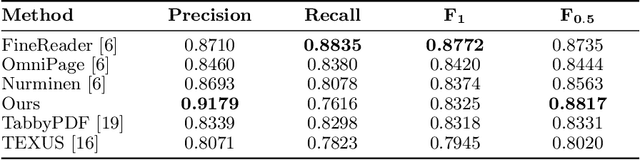

Table extraction is an important but still unsolved problem. In this paper, we introduce a flexible end-to-end table extraction system. We develop two rule-based algorithms that perform the complete table recognition process and support the most frequent table formats found in the scientific literature. Moreover, to incorporate the extraction of semantic information into the table recognition process, we develop a graph-based table interpretation method. We conduct extensive experiments on the challenging table recognition benchmarks ICDAR 2013 and ICDAR 2019. Our table recognition approach achieves results competitive with state-of-the-art approaches. Moreover, our complete information extraction system exhibited a high F1 score of 0.7380 proving the utility of our approach.
Empirical Error Modeling Improves Robustness of Noisy Neural Sequence Labeling
May 25, 2021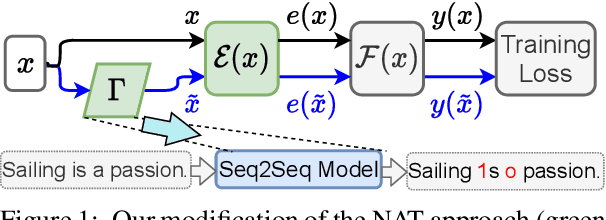
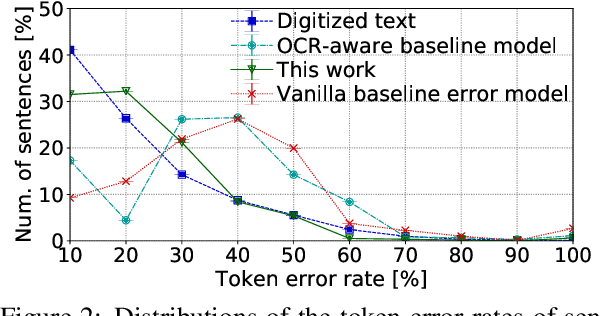
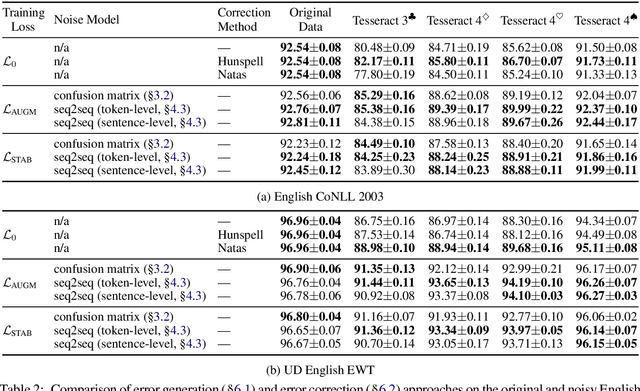
Despite recent advances, standard sequence labeling systems often fail when processing noisy user-generated text or consuming the output of an Optical Character Recognition (OCR) process. In this paper, we improve the noise-aware training method by proposing an empirical error generation approach that employs a sequence-to-sequence model trained to perform translation from error-free to erroneous text. Using an OCR engine, we generated a large parallel text corpus for training and produced several real-world noisy sequence labeling benchmarks for evaluation. Moreover, to overcome the data sparsity problem that exacerbates in the case of imperfect textual input, we learned noisy language model-based embeddings. Our approach outperformed the baseline noise generation and error correction techniques on the erroneous sequence labeling data sets. To facilitate future research on robustness, we make our code, embeddings, and data conversion scripts publicly available.
NAT: Noise-Aware Training for Robust Neural Sequence Labeling
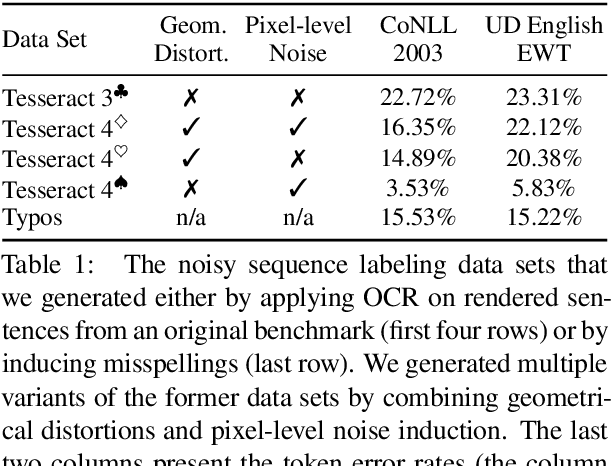
May 14, 2020Sequence labeling systems should perform reliably not only under ideal conditions but also with corrupted inputs - as these systems often process user-generated text or follow an error-prone upstream component. To this end, we formulate the noisy sequence labeling problem, where the input may undergo an unknown noising process and propose two Noise-Aware Training (NAT) objectives that improve robustness of sequence labeling performed on perturbed input: Our data augmentation method trains a neural model using a mixture of clean and noisy samples, whereas our stability training algorithm encourages the model to create a noise-invariant latent representation. We employ a vanilla noise model at training time. For evaluation, we use both the original data and its variants perturbed with real OCR errors and misspellings. Extensive experiments on English and German named entity recognition benchmarks confirmed that NAT consistently improved robustness of popular sequence labeling models, preserving accuracy on the original input. We make our code and data publicly available for the research community.