 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Direction of Arrival Estimation of Noisy Speech Using Convolutional Recurrent Neural Networks with Higher-Order Ambisonics Signals
Mar 01, 2021
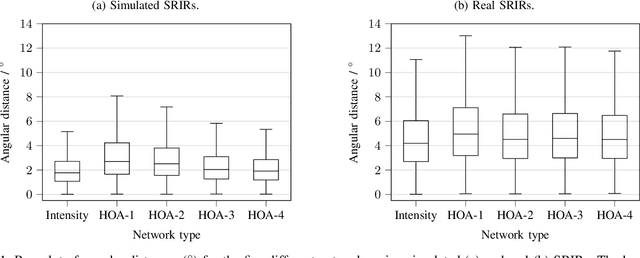
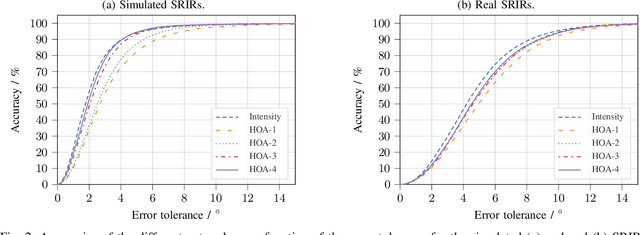
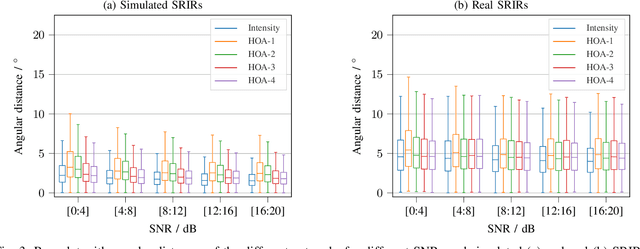
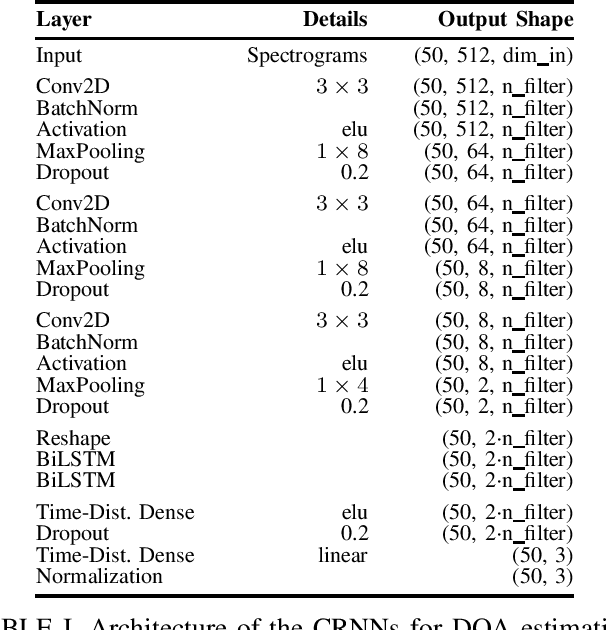
Training convolutional recurrent neural networks on first-order Ambisonics signals is a well-known approach when estimating the direction of arrival for speech/sound signals. In this work, we investigate whether increasing the order of Ambisonics up to the fourth order further improves the estimation performance of convolutional recurrent neural networks. While our results on data based on simulated spatial room impulse responses show that the use of higher Ambisonics orders does have the potential to provide better localization results, no further improvement was shown on data based on real spatial room impulse responses from order two onwards. Rather, it seems to be crucial to extract meaningful features from the raw data. First order features derived from the acoustic intensity vector were superior to pure higher-order magnitude and phase features in almost all scenarios.
Enrollment-less training for personalized voice activity detection
Jun 23, 2021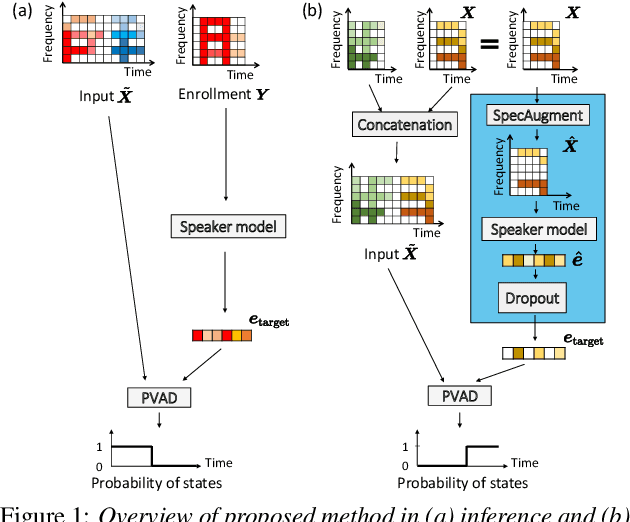
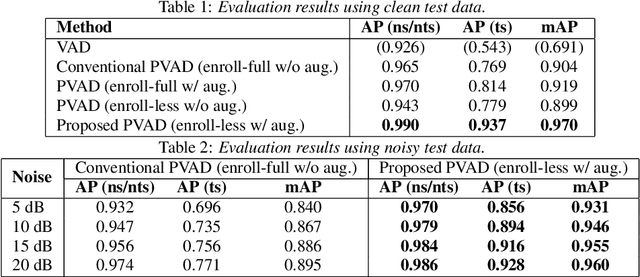
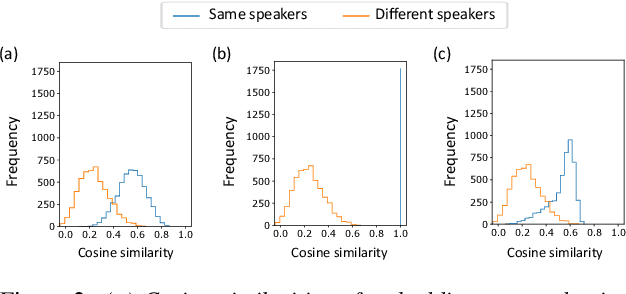
We present a novel personalized voice activity detection (PVAD) learning method that does not require enrollment data during training. PVAD is a task to detect the speech segments of a specific target speaker at the frame level using enrollment speech of the target speaker. Since PVAD must learn speakers' speech variations to clarify the boundary between speakers, studies on PVAD used large-scale datasets that contain many utterances for each speaker. However, the datasets to train a PVAD model are often limited because substantial cost is needed to prepare such a dataset. In addition, we cannot utilize the datasets used to train the standard VAD because they often lack speaker labels. To solve these problems, our key idea is to use one utterance as both a kind of enrollment speech and an input to the PVAD during training, which enables PVAD training without enrollment speech. In our proposed method, called enrollment-less training, we augment one utterance so as to create variability between the input and the enrollment speech while keeping the speaker identity, which avoids the mismatch between training and inference. Our experimental results demonstrate the efficacy of the method.
Deep Factorization for Speech Signal
Jun 25, 2017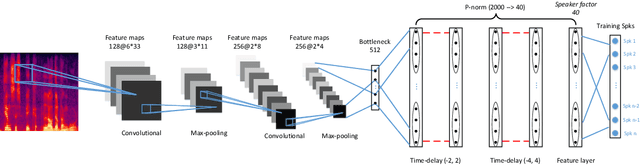
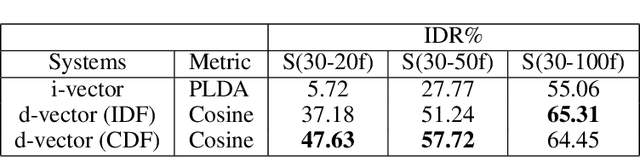
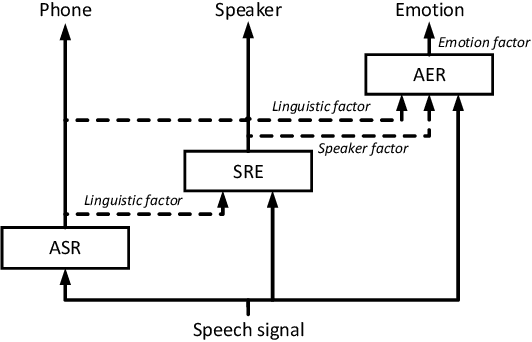
Speech signals are complex intermingling of various informative factors, and this information blending makes decoding any of the individual factors extremely difficult. A natural idea is to factorize each speech frame into independent factors, though it turns out to be even more difficult than decoding each individual factor. A major encumbrance is that the speaker trait, a major factor in speech signals, has been suspected to be a long-term distributional pattern and so not identifiable at the frame level. In this paper, we demonstrated that the speaker factor is also a short-time spectral pattern and can be largely identified with just a few frames using a simple deep neural network (DNN). This discovery motivated a cascade deep factorization (CDF) framework that infers speech factors in a sequential way, and factors previously inferred are used as conditional variables when inferring other factors. Our experiment on an automatic emotion recognition (AER) task demonstrated that this approach can effectively factorize speech signals, and using these factors, the original speech spectrum can be recovered with high accuracy. This factorization and reconstruction approach provides a novel tool for many speech processing tasks.
Mixture factorized auto-encoder for unsupervised hierarchical deep factorization of speech signal
Oct 30, 2019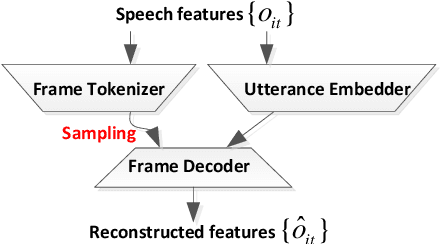

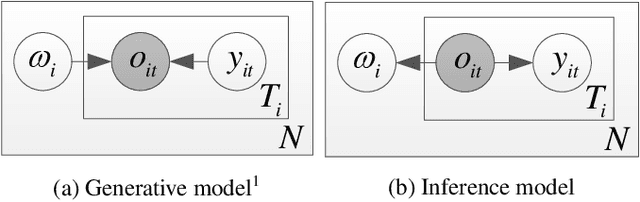
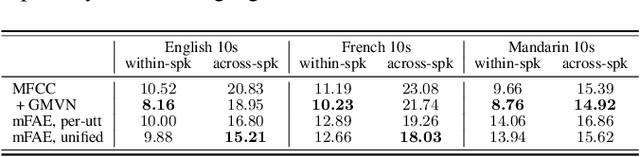
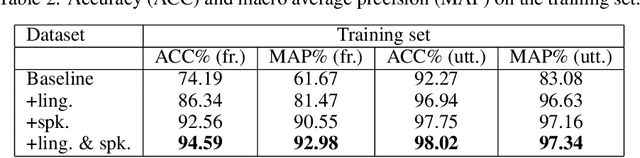
Speech signal is constituted and contributed by various informative factors, such as linguistic content and speaker characteristic. There have been notable recent studies attempting to factorize speech signal into these individual factors without requiring any annotation. These studies typically assume continuous representation for linguistic content, which is not in accordance with general linguistic knowledge and may make the extraction of speaker information less successful. This paper proposes the mixture factorized auto-encoder (mFAE) for unsupervised deep factorization. The encoder part of mFAE comprises a frame tokenizer and an utterance embedder. The frame tokenizer models linguistic content of input speech with a discrete categorical distribution. It performs frame clustering by assigning each frame a soft mixture label. The utterance embedder generates an utterance-level vector representation. A frame decoder serves to reconstruct speech features from the encoders'outputs. The mFAE is evaluated on speaker verification (SV) task and unsupervised subword modeling (USM) task. The SV experiments on VoxCeleb 1 show that the utterance embedder is capable of extracting speaker-discriminative embeddings with performance comparable to a x-vector baseline. The USM experiments on ZeroSpeech 2017 dataset verify that the frame tokenizer is able to capture linguistic content and the utterance embedder can acquire speaker-related information.
WaveNODE: A Continuous Normalizing Flow for Speech Synthesis
Jul 02, 2020
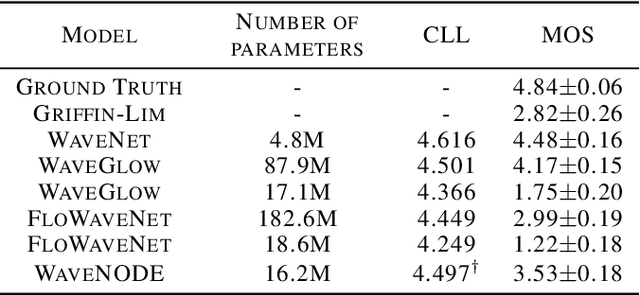
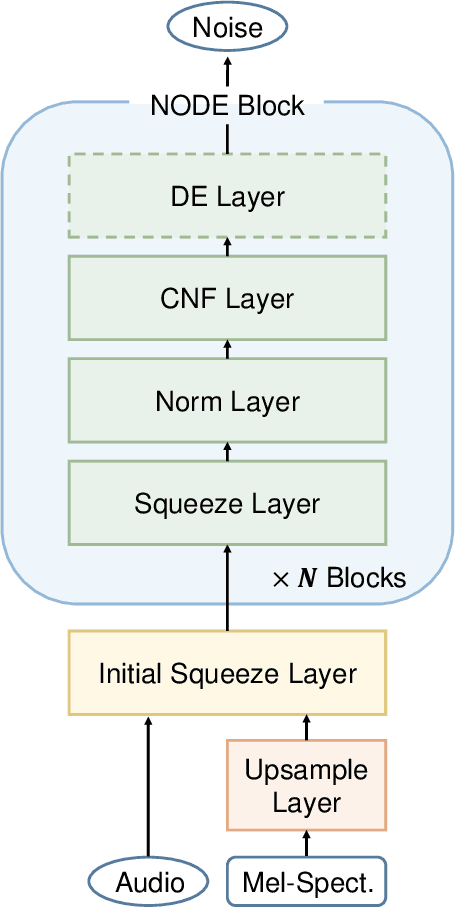

In recent years, various flow-based generative models have been proposed to generate high-fidelity waveforms in real-time. However, these models require either a well-trained teacher network or a number of flow steps making them memory-inefficient. In this paper, we propose a novel generative model called WaveNODE which exploits a continuous normalizing flow for speech synthesis. Unlike the conventional models, WaveNODE places no constraint on the function used for flow operation, thus allowing the usage of more flexible and complex functions. Moreover, WaveNODE can be optimized to maximize the likelihood without requiring any teacher network or auxiliary loss terms. We experimentally show that WaveNODE achieves comparable performance with fewer parameters compared to the conventional flow-based vocoders.
GPT-D: Inducing Dementia-related Linguistic Anomalies by Deliberate Degradation of Artificial Neural Language Models
Mar 25, 2022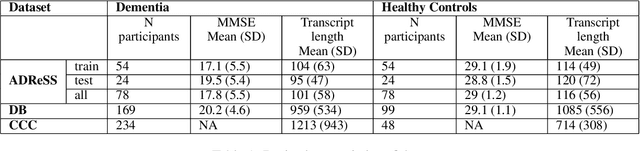

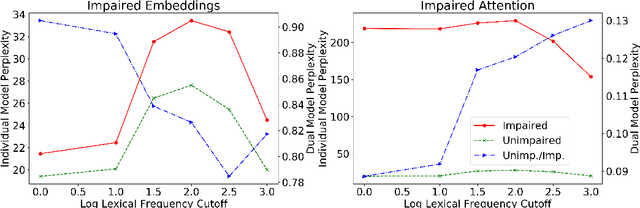

Deep learning (DL) techniques involving fine-tuning large numbers of model parameters have delivered impressive performance on the task of discriminating between language produced by cognitively healthy individuals, and those with Alzheimer's disease (AD). However, questions remain about their ability to generalize beyond the small reference sets that are publicly available for research. As an alternative to fitting model parameters directly, we propose a novel method by which a Transformer DL model (GPT-2) pre-trained on general English text is paired with an artificially degraded version of itself (GPT-D), to compute the ratio between these two models' \textit{perplexities} on language from cognitively healthy and impaired individuals. This technique approaches state-of-the-art performance on text data from a widely used "Cookie Theft" picture description task, and unlike established alternatives also generalizes well to spontaneous conversations. Furthermore, GPT-D generates text with characteristics known to be associated with AD, demonstrating the induction of dementia-related linguistic anomalies. Our study is a step toward better understanding of the relationships between the inner workings of generative neural language models, the language that they produce, and the deleterious effects of dementia on human speech and language characteristics.
High Performance Sequence-to-Sequence Model for Streaming Speech Recognition
Mar 22, 2020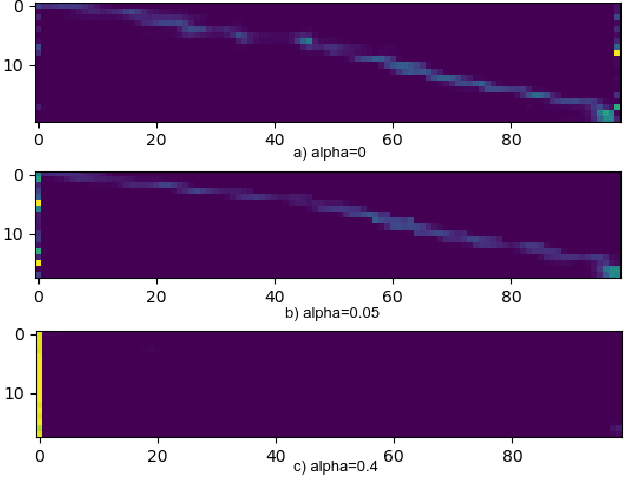
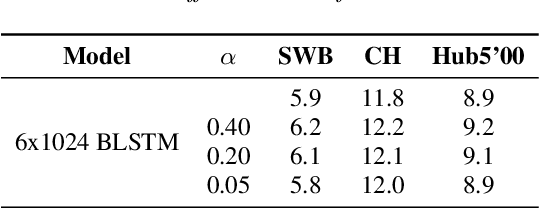
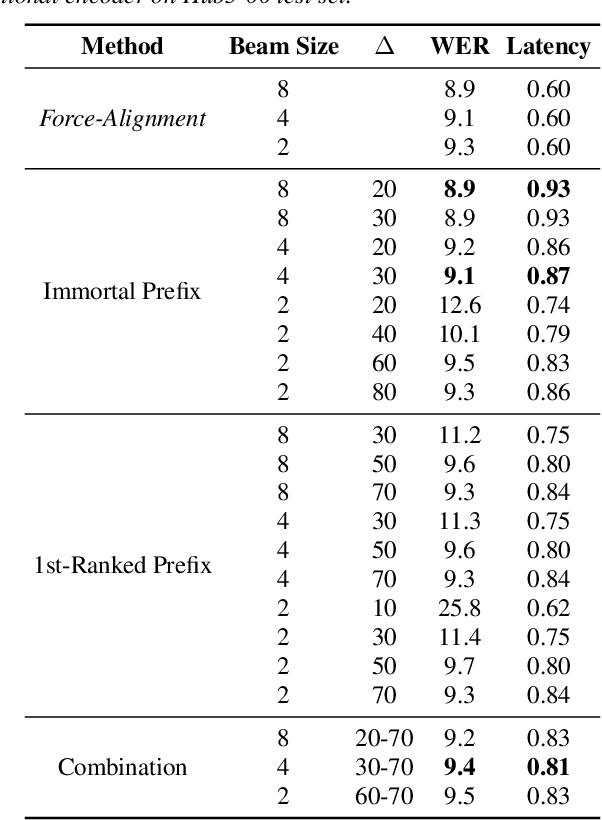
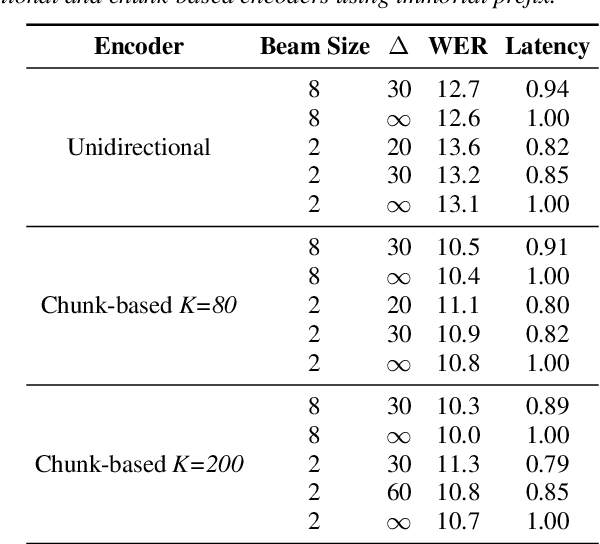
Recently sequence-to-sequence models have started to achieve state-of-the art performance on standard speech recognition tasks when processing audio data in batch mode, i.e., the complete audio data is available when starting processing. However, when it comes to perform run-on recognition on an input stream of audio data while producing recognition results in real-time and with a low word-based latency, these models face several challenges. For many techniques, the whole audio sequence to be decoded needs to be available at the start of the processing, e.g., for the attention mechanism or for the bidirectional LSTM (BLSTM). In this paper we propose several techniques to mitigate these problems. We introduce an additional loss function controlling the uncertainty of the attention mechanism, a modified beam search identifying partial, stable hypotheses, ways of working with BLSTM in the encoder, and the use of chunked BLSTM. Our experiments show that with the right combination of these techniques it is possible to perform run-on speech recognition with a low word-based latency without sacrificing performance in terms of word error rate.
Speaker-Targeted Audio-Visual Models for Speech Recognition in Cocktail-Party Environments
Jun 13, 2019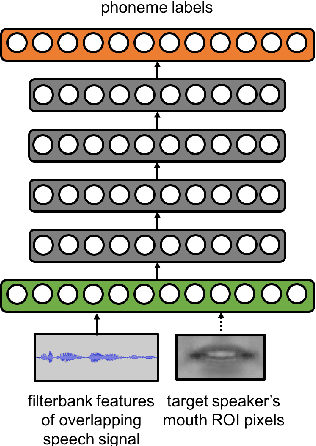
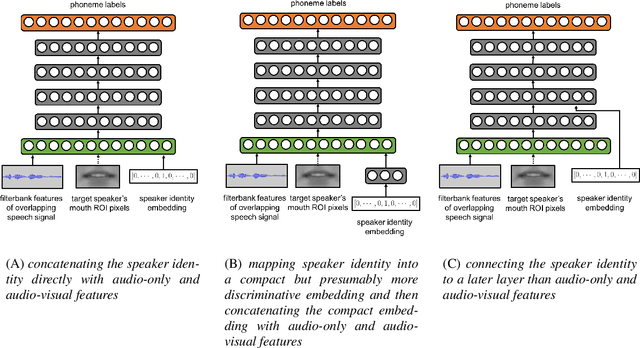

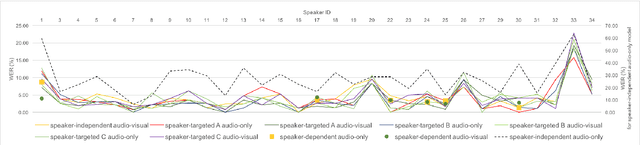
Speech recognition in cocktail-party environments remains a significant challenge for state-of-the-art speech recognition systems, as it is extremely difficult to extract an acoustic signal of an individual speaker from a background of overlapping speech with similar frequency and temporal characteristics. We propose the use of speaker-targeted acoustic and audio-visual models for this task. We complement the acoustic features in a hybrid DNN-HMM model with information of the target speaker's identity as well as visual features from the mouth region of the target speaker. Experimentation was performed using simulated cocktail-party data generated from the GRID audio-visual corpus by overlapping two speakers's speech on a single acoustic channel. Our audio-only baseline achieved a WER of 26.3%. The audio-visual model improved the WER to 4.4%. Introducing speaker identity information had an even more pronounced effect, improving the WER to 3.6%. Combining both approaches, however, did not significantly improve performance further. Our work demonstrates that speaker-targeted models can significantly improve the speech recognition in cocktail party environments.
A wearable sensor vest for social humanoid robots with GPGPU, IoT, and modular software architecture
Jan 06, 2022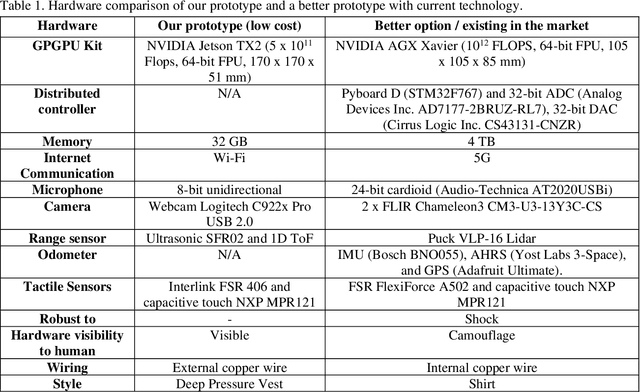

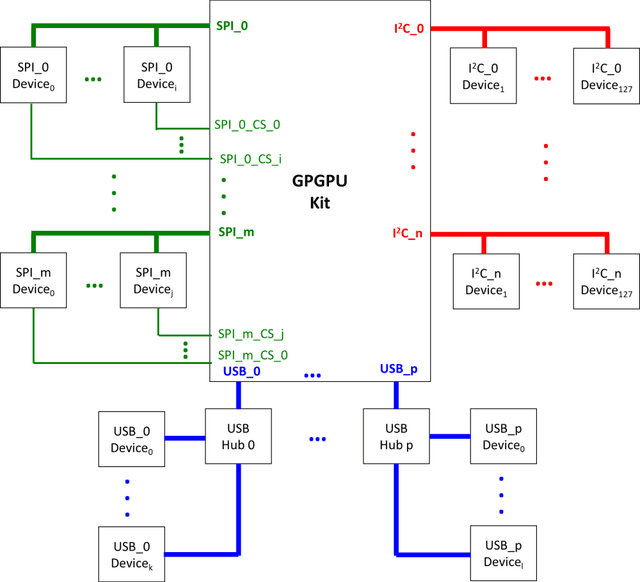
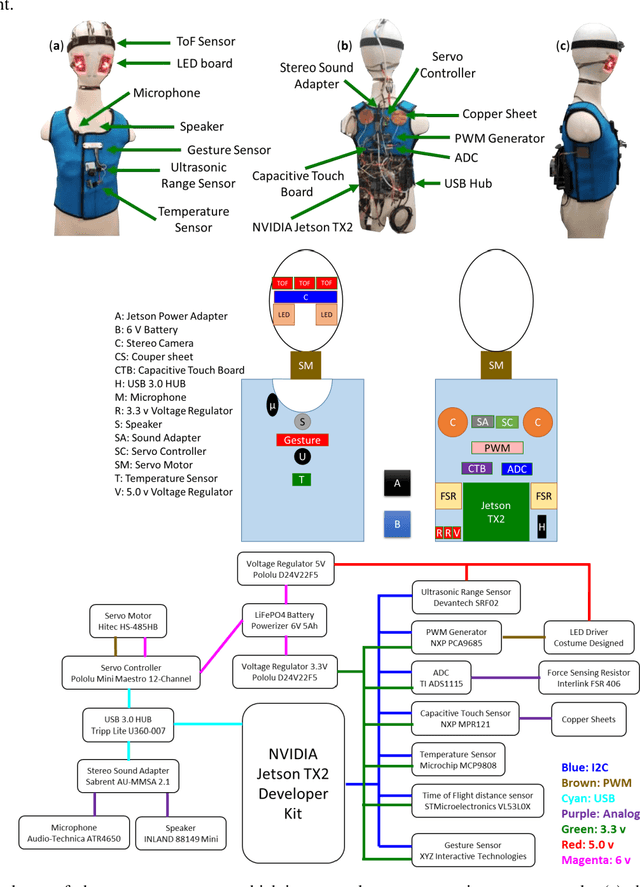
Currently, most social robots interact with their surroundings and humans through sensors that are integral parts of the robots, which limits the usability of the sensors, human-robot interaction, and interchangeability. A wearable sensor garment that fits many robots is needed in many applications. This article presents an affordable wearable sensor vest, and an open-source software architecture with the Internet of Things (IoT) for social humanoid robots. The vest consists of touch, temperature, gesture, distance, vision sensors, and a wireless communication module. The IoT feature allows the robot to interact with humans locally and over the Internet. The designed architecture works for any social robot that has a general-purpose graphics processing unit (GPGPU), I2C/SPI buses, Internet connection, and the Robotics Operating System (ROS). The modular design of this architecture enables developers to easily add/remove/update complex behaviors. The proposed software architecture provides IoT technology, GPGPU nodes, I2C and SPI bus mangers, audio-visual interaction nodes (speech to text, text to speech, and image understanding), and isolation between behavior nodes and other nodes. The proposed IoT solution consists of related nodes in the robot, a RESTful web service, and user interfaces. We used the HTTP protocol as a means of two-way communication with the social robot over the Internet. Developers can easily edit or add nodes in C, C++, and Python programming languages. Our architecture can be used for designing more sophisticated behaviors for social humanoid robots.
* This is the preprint version. The final version is published in Robotics and Autonomous Systems, Volume 139, 2021, Page 103536, ISSN 0921-8890, https://doi.org/10.1016/j.robot.2020.103536
Monaural Multi-Talker Speech Recognition using Factorial Speech Processing Models
Oct 05, 2016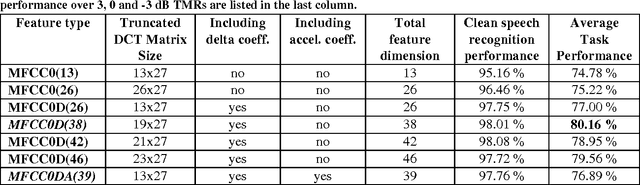
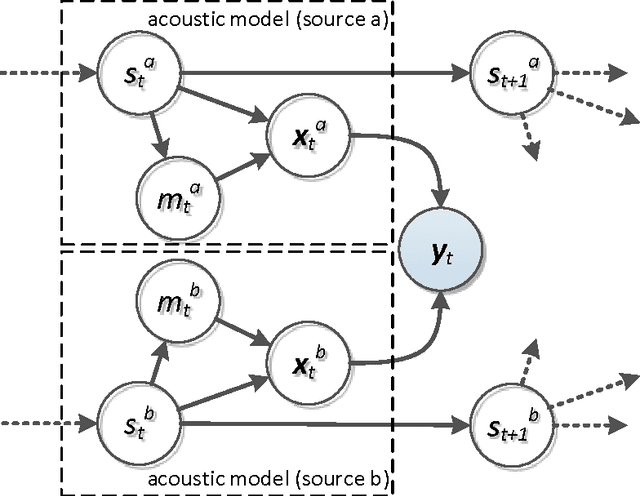

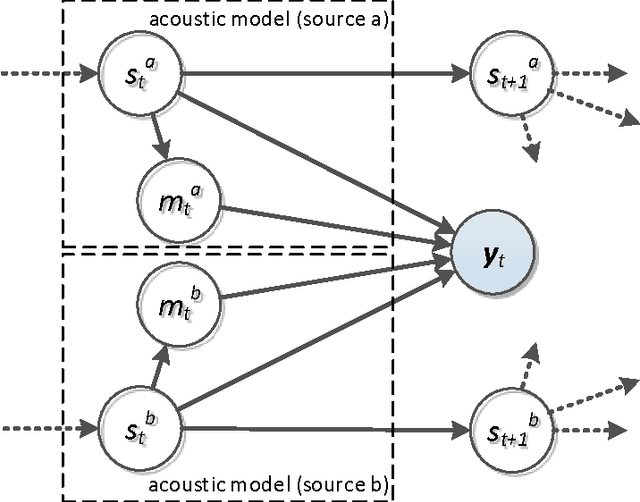
A Pascal challenge entitled monaural multi-talker speech recognition was developed, targeting the problem of robust automatic speech recognition against speech like noises which significantly degrades the performance of automatic speech recognition systems. In this challenge, two competing speakers say a simple command simultaneously and the objective is to recognize speech of the target speaker. Surprisingly during the challenge, a team from IBM research, could achieve a performance better than human listeners on this task. The proposed method of the IBM team, consist of an intermediate speech separation and then a single-talker speech recognition. This paper reconsiders the task of this challenge based on gain adapted factorial speech processing models. It develops a joint-token passing algorithm for direct utterance decoding of both target and masker speakers, simultaneously. Comparing it to the challenge winner, it uses maximum uncertainty during the decoding which cannot be used in the past two-phased method. It provides detailed derivation of inference on these models based on general inference procedures of probabilistic graphical models. As another improvement, it uses deep neural networks for joint-speaker identification and gain estimation which makes these two steps easier than before producing competitive results for these steps. The proposed method of this work outperforms past super-human results and even the results were achieved recently by Microsoft research, using deep neural networks. It achieved 5.5% absolute task performance improvement compared to the first super-human system and 2.7% absolute task performance improvement compared to its recent competitor.