 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture factorized auto-encoder for unsupervised hierarchical deep factorization of speech signal
Paper and Code
Oct 30, 2019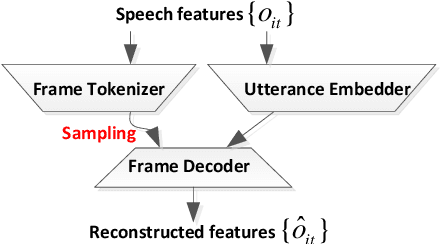

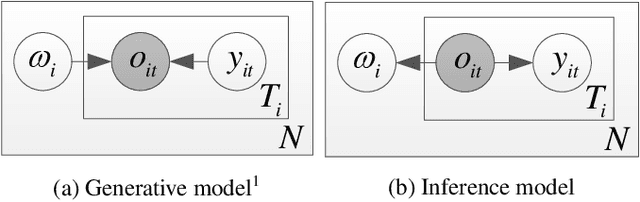
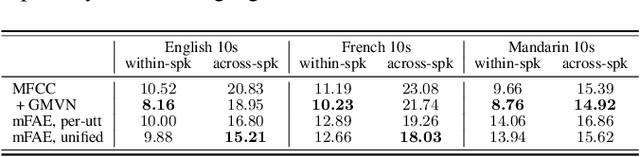
Speech signal is constituted and contributed by various informative factors, such as linguistic content and speaker characteristic. There have been notable recent studies attempting to factorize speech signal into these individual factors without requiring any annotation. These studies typically assume continuous representation for linguistic content, which is not in accordance with general linguistic knowledge and may make the extraction of speaker information less successful. This paper proposes the mixture factorized auto-encoder (mFAE) for unsupervised deep factorization. The encoder part of mFAE comprises a frame tokenizer and an utterance embedder. The frame tokenizer models linguistic content of input speech with a discrete categorical distribution. It performs frame clustering by assigning each frame a soft mixture label. The utterance embedder generates an utterance-level vector representation. A frame decoder serves to reconstruct speech features from the encoders'outputs. The mFAE is evaluated on speaker verification (SV) task and unsupervised subword modeling (USM) task. The SV experiments on VoxCeleb 1 show that the utterance embedder is capable of extracting speaker-discriminative embeddings with performance comparable to a x-vector baseline. The USM experiments on ZeroSpeech 2017 dataset verify that the frame tokenizer is able to capture linguistic content and the utterance embedder can acquire speaker-related information.