 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adapting End-to-End Speech Recognition for Readable Subtitles
May 25, 2020

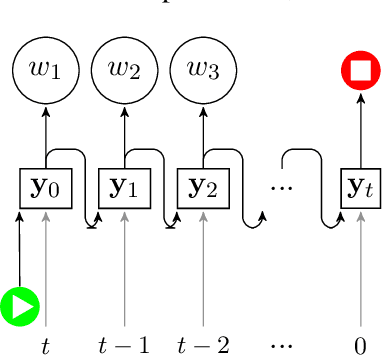

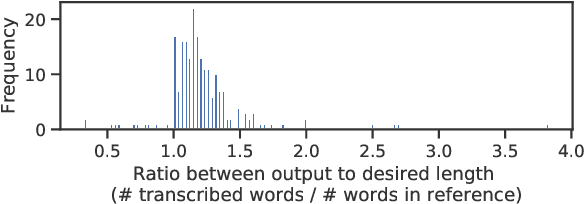
Automatic speech recognition (ASR) systems are primarily evaluated on transcription accuracy. However, in some use cases such as subtitling, verbatim transcription would reduce output readability given limited screen size and reading time. Therefore, this work focuses on ASR with output compression, a task challenging for supervised approaches due to the scarcity of training data. We first investigate a cascaded system, where an unsupervised compression model is used to post-edit the transcribed speech. We then compare several methods of end-to-end speech recognition under output length constraints. The experiments show that with limited data far less than needed for training a model from scratch, we can adapt a Transformer-based ASR model to incorporate both transcription and compression capabilities. Furthermore, the best performance in terms of WER and ROUGE scores is achieved by explicitly modeling the length constraints within the end-to-end ASR system.
Convolutional Neural Networks for Speech Controlled Prosthetic Hands
Oct 03, 2019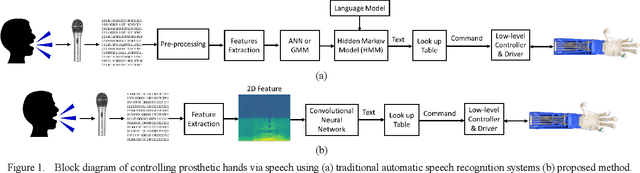
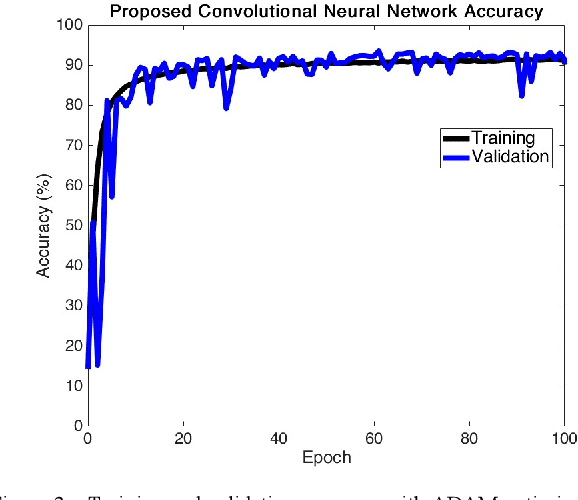
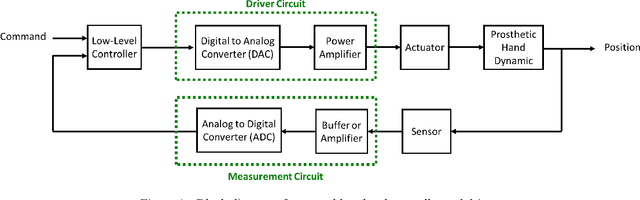
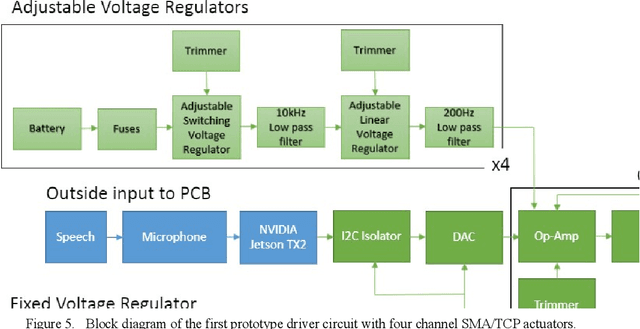
Speech recognition is one of the key topics in artificial intelligence, as it is one of the most common forms of communication in humans. Researchers have developed many speech-controlled prosthetic hands in the past decades, utilizing conventional speech recognition systems that use a combination of neural network and hidden Markov model. Recent advancements in general-purpose graphics processing units (GPGPUs) enable intelligent devices to run deep neural networks in real-time. Thus, state-of-the-art speech recognition systems have rapidly shifted from the paradigm of composite subsystems optimization to the paradigm of end-to-end optimization. However, a low-power embedded GPGPU cannot run these speech recognition systems in real-time. In this paper, we show the development of deep convolutional neural networks (CNN) for speech control of prosthetic hands that run in real-time on a NVIDIA Jetson TX2 developer kit. First, the device captures and converts speech into 2D features (like spectrogram). The CNN receives the 2D features and classifies the hand gestures. Finally, the hand gesture classes are sent to the prosthetic hand motion control system. The whole system is written in Python with Keras, a deep learning library that has a TensorFlow backend. Our experiments on the CNN demonstrate the 91% accuracy and 2ms running time of hand gestures (text output) from speech commands, which can be used to control the prosthetic hands in real-time.
* 2019 First International Conference on Transdisciplinary AI (TransAI), Laguna Hills, California, USA, 2019, pp. 35-42
End-to-end Anchored Speech Recognition
Feb 06, 2019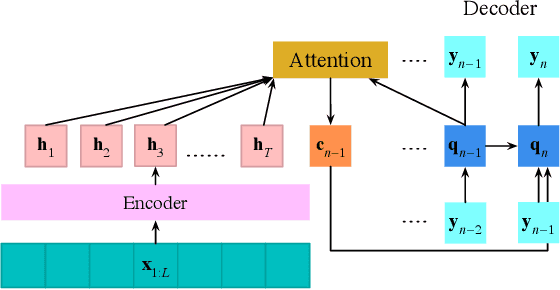
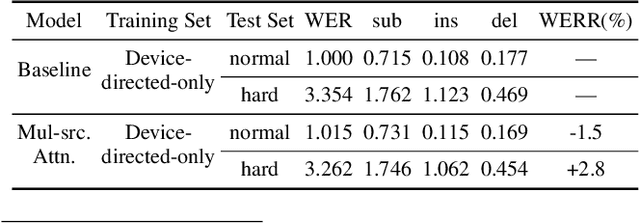

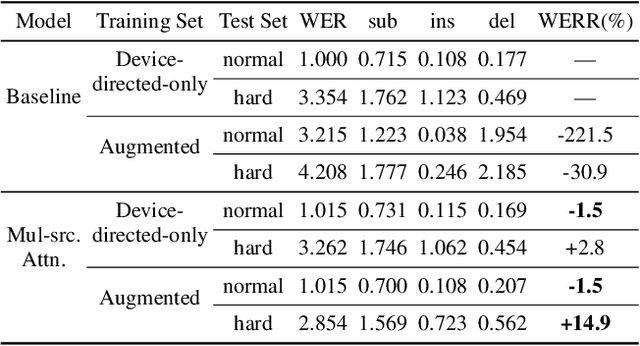
Voice-controlled house-hold devices, like Amazon Echo or Google Home, face the problem of performing speech recognition of device-directed speech in the presence of interfering background speech, i.e., background noise and interfering speech from another person or media device in proximity need to be ignored. We propose two end-to-end models to tackle this problem with information extracted from the "anchored segment". The anchored segment refers to the wake-up word part of an audio stream, which contains valuable speaker information that can be used to suppress interfering speech and background noise. The first method is called "Multi-source Attention" where the attention mechanism takes both the speaker information and decoder state into consideration. The second method directly learns a frame-level mask on top of the encoder output. We also explore a multi-task learning setup where we use the ground truth of the mask to guide the learner. Given that audio data with interfering speech is rare in our training data set, we also propose a way to synthesize "noisy" speech from "clean" speech to mitigate the mismatch between training and test data. Our proposed methods show up to 15% relative reduction in WER for Amazon Alexa live data with interfering background speech without significantly degrading on clean speech.
To BAN or not to BAN: Bayesian Attention Networks for Reliable Hate Speech Detection
Jul 14, 2020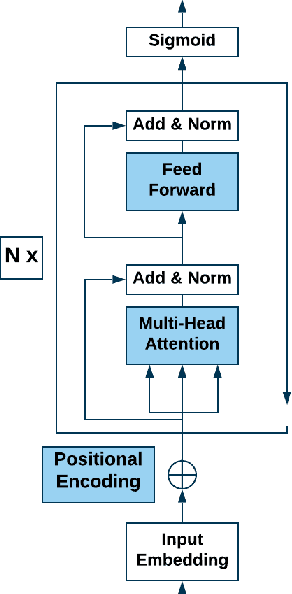

Hate speech is an important problem in the management of user-generated content. In order to remove offensive content or ban misbehaving users, content moderators need reliable hate speech detectors. Recently, deep neural networks based on transformer architecture, such as (multilingual) BERT model, achieve superior performance in many natural language classification tasks, including hate speech detection. So far, these methods have not been able to quantify their output in terms of reliability. We propose a Bayesian method using Monte Carlo Dropout within the attention layers of the transformer models to provide well-calibrated reliability estimates. We evaluate and visualize the introduced approach on hate speech detection problems in several languages. From the experiments performed it was observed that our approach significantly improve the hate speech detection that can not be trusted. Our approach not only improves classification performance of the state-of-the-art multilingual BERT model, but the computed reliability scores also significantly reduce the workload in the inspection of offending cases and in reannotation campaigns. The provided visualization helps to understand the borderline outcomes.
Prediction Uncertainty Estimation for Hate Speech Classification
Sep 16, 2019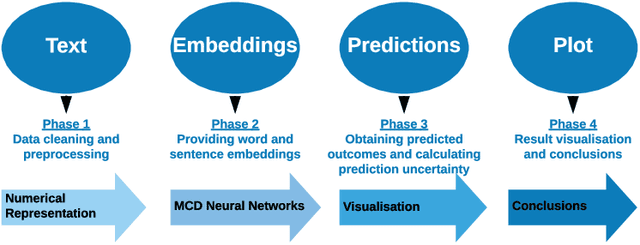
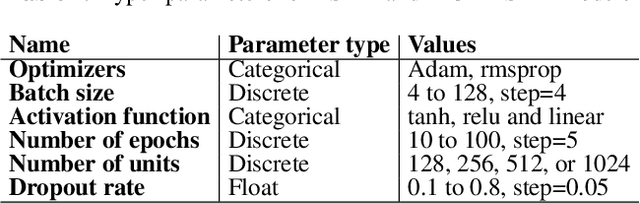
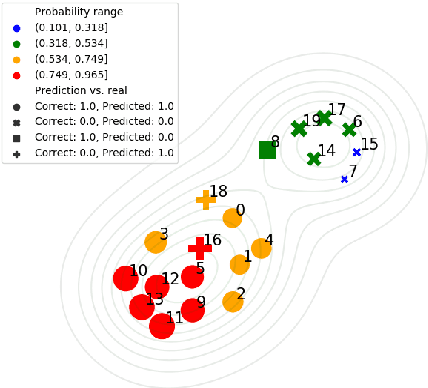
As a result of social network popularity, in recent years, hate speech phenomenon has significantly increased. Due to its harmful effect on minority groups as well as on large communities, there is a pressing need for hate speech detection and filtering. However, automatic approaches shall not jeopardize free speech, so they shall accompany their decisions with explanations and assessment of uncertainty. Thus, there is a need for predictive machine learning models that not only detect hate speech but also help users understand when texts cross the line and become unacceptable. The reliability of predictions is usually not addressed in text classification. We fill this gap by proposing the adaptation of deep neural networks that can efficiently estimate prediction uncertainty. To reliably detect hate speech, we use Monte Carlo dropout regularization, which mimics Bayesian inference within neural networks. We evaluate our approach using different text embedding methods. We visualize the reliability of results with a novel technique that aids in understanding the classification reliability and errors.
Twitter Dataset on the Russo-Ukrainian War
Apr 07, 2022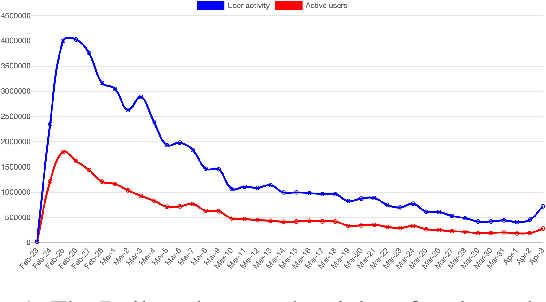
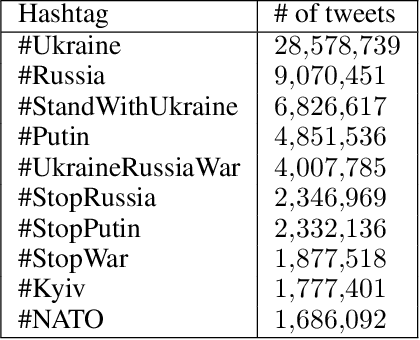
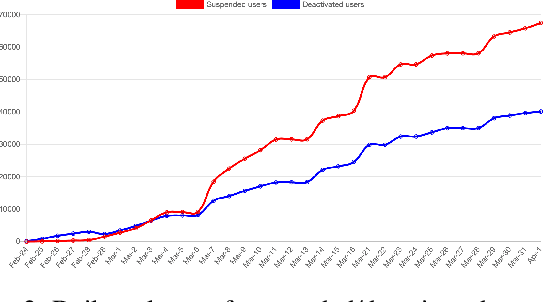
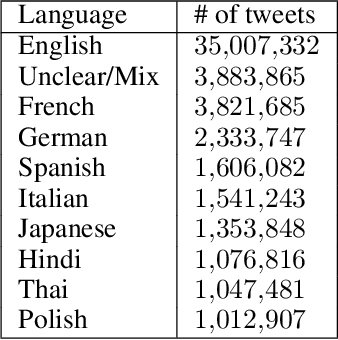
On 24 February 2022, Russia invaded Ukraine, also known now as Russo-Ukrainian War. We have initiated an ongoing dataset acquisition from Twitter API. Until the day this paper was written the dataset has reached the amount of 57.3 million tweets, originating from 7.7 million users. We apply an initial volume and sentiment analysis, while the dataset can be used to further exploratory investigation towards topic analysis, hate speech, propaganda recognition, or even show potential malicious entities like botnets.
Hate Speech detection in the Bengali language: A dataset and its baseline evaluation
Dec 17, 2020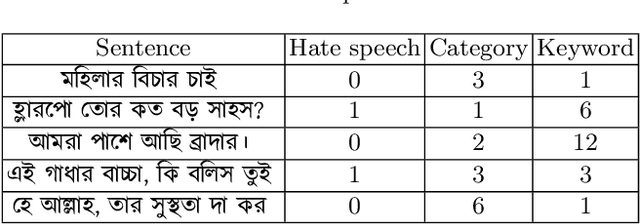
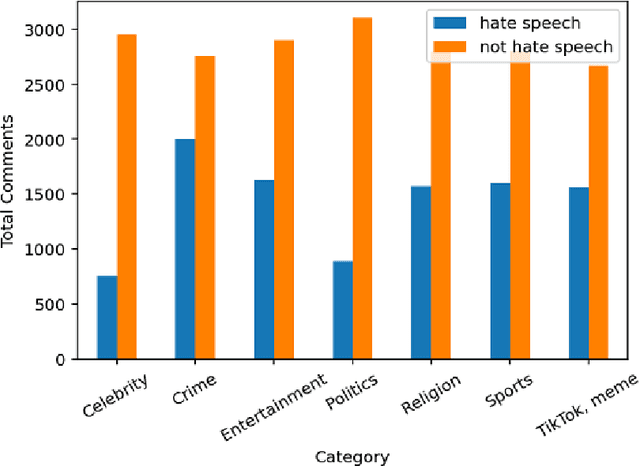
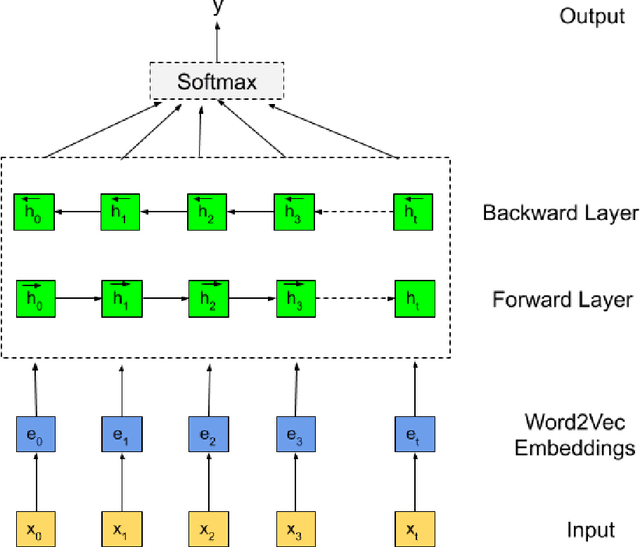
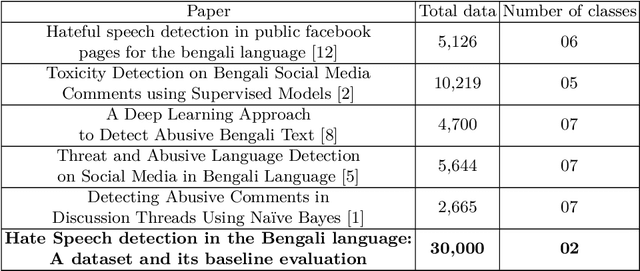
Social media sites such as YouTube and Facebook have become an integral part of everyone's life and in the last few years, hate speech in the social media comment section has increased rapidly. Detection of hate speech on social media websites faces a variety of challenges including small imbalanced data sets, the findings of an appropriate model and also the choice of feature analysis method. further more, this problem is more severe for the Bengali speaking community due to the lack of gold standard labelled datasets. This paper presents a new dataset of 30,000 user comments tagged by crowd sourcing and varified by experts. All the comments are collected from YouTube and Facebook comment section and classified into seven categories: sports, entertainment, religion, politics, crime, celebrity and TikTok & meme. A total of 50 annotators annotated each comment three times and the majority vote was taken as the final annotation. Nevertheless, we have conducted base line experiments and several deep learning models along with extensive pre-trained Bengali word embedding such as Word2Vec, FastText and BengFastText on this dataset to facilitate future research opportunities. The experiment illustrated that although all deep learning models performed well, SVM achieved the best result with 87.5% accuracy. Our core contribution is to make this benchmark dataset available and accessible to facilitate further research in the field of in the field of Bengali hate speech detection.
Gesticulator: A framework for semantically-aware speech-driven gesture generation
Jan 25, 2020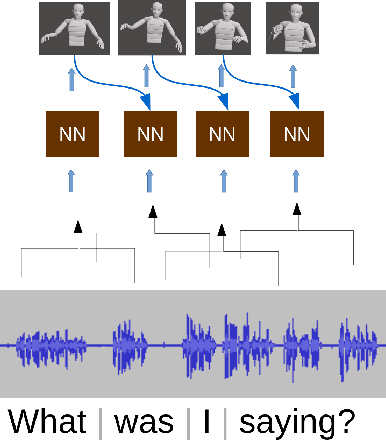
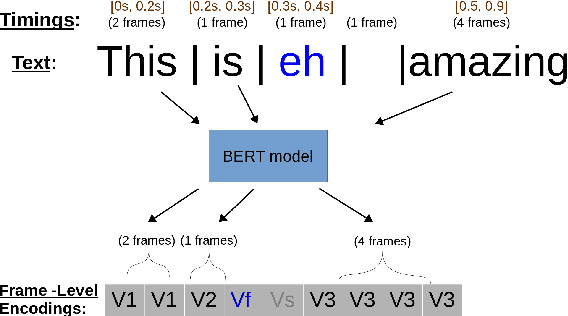

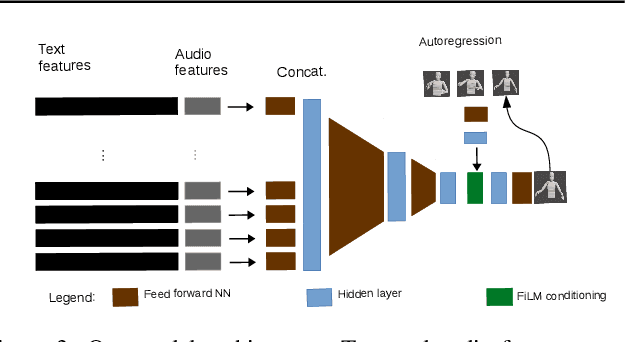
During speech, people spontaneously gesticulate, which plays a key role in conveying information. Similarly, realistic co-speech gestures are crucial to enable natural and smooth interactions with social agents. Current data-driven co-speech gesture generation systems use a single modality for representing speech: either audio or text. These systems are therefore confined to producing either acoustically-linked beat gestures or semantically-linked gesticulation (e.g., raising a hand when saying ``high''): they cannot appropriately learn to generate both gesture types. We present a model designed to produce arbitrary beat and semantic gestures together. Our deep-learning based model takes both acoustic and semantic representations of speech as input, and generates gestures as a sequence of joint angle rotations as output. The resulting gestures can be applied to both virtual agents and humanoid robots. We illustrate the model's efficacy with subjective and objective evaluations.
Characterizing Therapist's Speaking Style in Relation to Empathy in Psychotherapy
Mar 24, 2022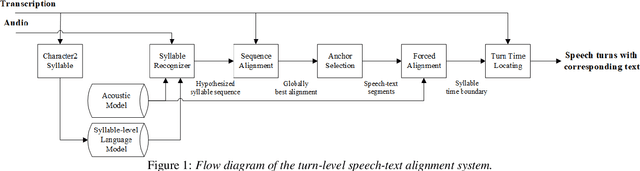
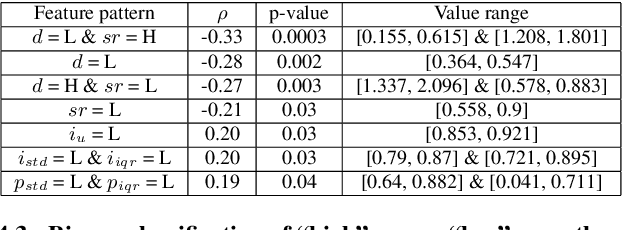
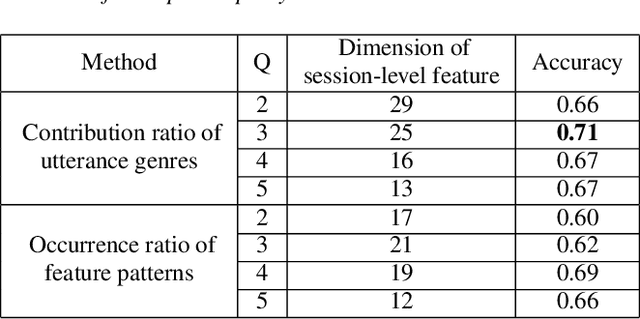
In conversation-based psychotherapy, therapists use verbal techniques to help clients express thoughts and feelings and change behaviors. In particular, how well therapists convey empathy is an essential quality index of psychotherapy sessions and is associated with psychotherapy outcome. In this paper, we analyze the prosody of therapist speech and attempt to associate the therapist's speaking style with subjectively perceived empathy. An automatic speech and text processing system is developed to segment long recordings of psychotherapy sessions into pause-delimited utterances with text transcriptions. Data-driven clustering is applied to the utterances from different therapists in multiple sessions. For each cluster, a typological representation of utterance genre is derived based on quantized prosodic feature parameters. Prominent speaking styles of the therapist can be observed and interpreted from salient utterance genres that are correlated with empathy. Using the salient utterance genres, an accuracy of 71% is achieved in classifying psychotherapy sessions into "high" and "low" empathy level. Analysis of results suggests that empathy level tends to be (1) low if therapists speak long utterances slowly or speak short utterances quickly; and (2) high if therapists talk to clients with a steady tone and volume.
Generative Pre-Training for Speech with Autoregressive Predictive Coding
Oct 23, 2019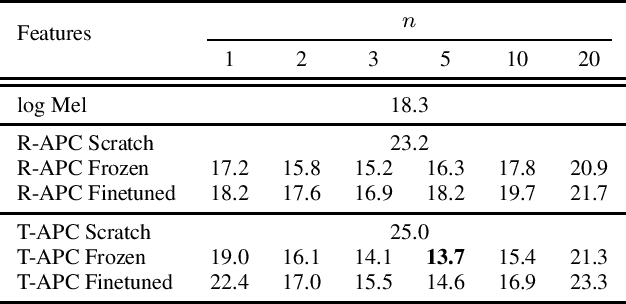
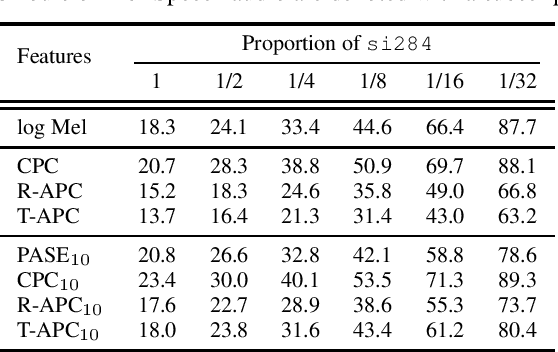
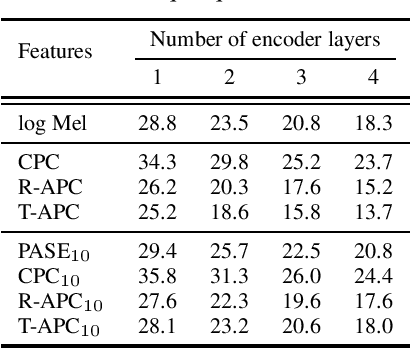
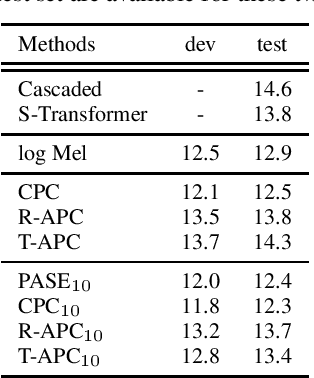
Learning meaningful and general representations from unannotated speech that are applicable to a wide range of tasks remains challenging. In this paper we propose to use autoregressive predictive coding (APC), a recently proposed self-supervised objective, as a generative pre-training approach for learning meaningful, non-specific, and transferable speech representations. We pre-train APC on large-scale unlabeled data and conduct transfer learning experiments on three speech applications that require different information about speech characteristics to perform well: speech recognition, speech translation, and speaker identification. Extensive experiments show that APC not only outperforms surface features (e.g., log Mel spectrograms) and other popular representation learning methods on all three tasks, but is also effective at reducing downstream labeled data size and model parameters. We also investigate the use of Transformers for modeling APC and find it superior to RNNs.