 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Consistent Transcription and Translation of Speech
Jul 24, 2020

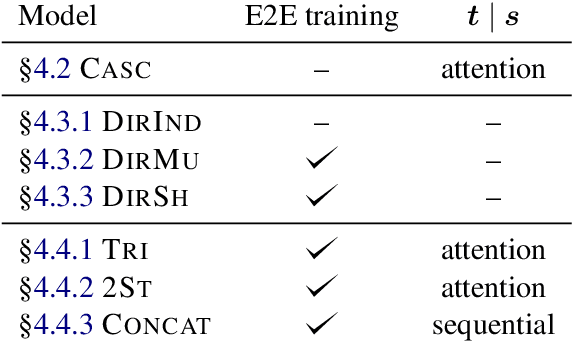

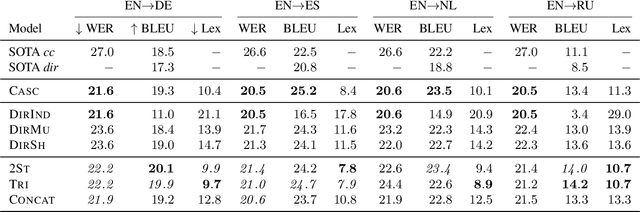
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.
Alzheimer's Dementia Recognition through Spontaneous Speech: The ADReSS Challenge
Apr 30, 2020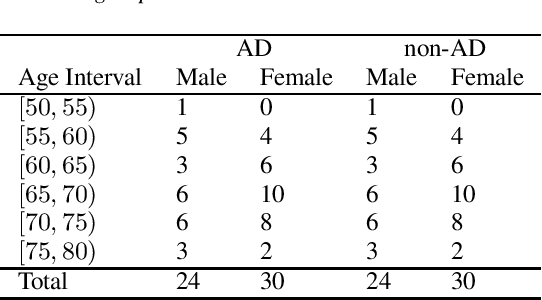
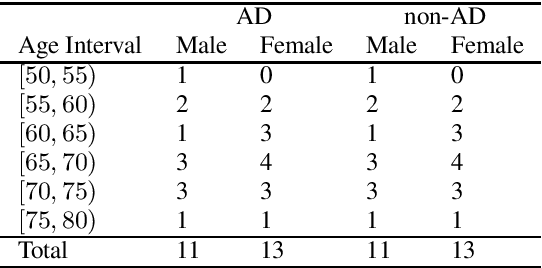

The ADReSS Challenge at INTERSPEECH 2020 defines a shared task through which different approaches to the automated recognition of Alzheimer's dementia based on spontaneous speech can be compared. ADReSS provides researchers with a benchmark speech dataset which has been acoustically pre-processed and balanced in terms of age and gender, defining two cognitive assessment tasks, namely: the Alzheimer's speech classification task and the neuropsychological score regression task. In the Alzheimer's speech classification task, ADReSS challenge participants create models for classifying speech as dementia or healthy control speech. In the the neuropsychological score regression task, participants create models to predict mini-mental state examination scores. This paper describes the ADReSS Challenge in detail and presents a baseline for both tasks, including a feature extraction procedure and results for a classification and a regression model. ADReSS aims to provide the speech and language Alzheimer's research community with a platform for comprehensive methodological comparisons. This will contribute to addressing the lack of standardisation that currently affects the field and shed light on avenues for future research and clinical applicability.
The Perceptimatic English Benchmark for Speech Perception Models
May 07, 2020
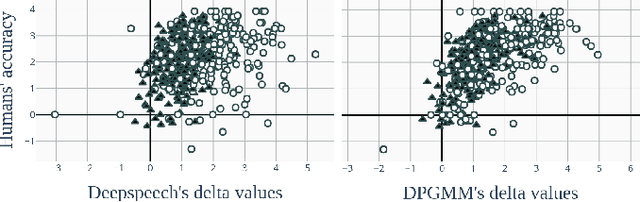

We present the Perceptimatic English Benchmark, an open experimental benchmark for evaluating quantitative models of speech perception in English. The benchmark consists of ABX stimuli along with the responses of 91 American English-speaking listeners. The stimuli test discrimination of a large number of English and French phonemic contrasts. They are extracted directly from corpora of read speech, making them appropriate for evaluating statistical acoustic models (such as those used in automatic speech recognition) trained on typical speech data sets. We show that phone discrimination is correlated with several types of models, and give recommendations for researchers seeking easily calculated norms of acoustic distance on experimental stimuli. We show that DeepSpeech, a standard English speech recognizer, is more specialized on English phoneme discrimination than English listeners, and is poorly correlated with their behaviour, even though it yields a low error on the decision task given to humans.
Applying Speech Tempo-Derived Features, BoAW and Fisher Vectors to Detect Elderly Emotion and Speech in Surgical Masks
Aug 07, 2020
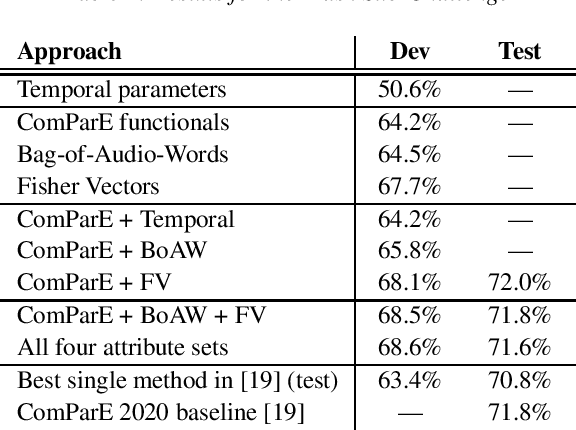
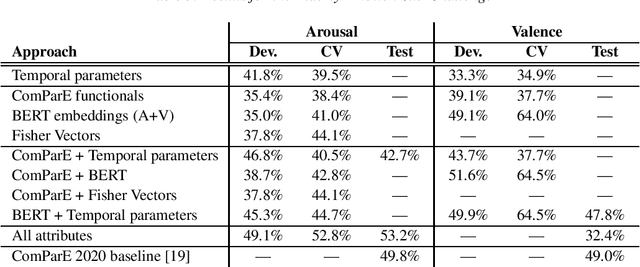
The 2020 INTERSPEECH Computational Paralinguistics Challenge (ComParE) consists of three Sub-Challenges, where the tasks are to identify the level of arousal and valence of elderly speakers, determine whether the actual speaker wearing a surgical mask, and estimate the actual breathing of the speaker. In our contribution to the Challenge, we focus on the Elderly Emotion and the Mask sub-challenges. Besides utilizing standard or close-to-standard features such as ComParE functionals, Bag-of-Audio-Words and Fisher vectors, we exploit that emotion is related to the velocity of speech (i.e. speech rate). To utilize this, we perform phone-level recognition using an ASR system, and extract features from the output such as articulation tempo, speech tempo, and various attributes measuring the amount of pauses. We also hypothesize that wearing a surgical mask makes the speaker feel uneasy, leading to a slower speech rate and more hesitations; hence, we experiment with the same features in the Mask sub-challenge as well. Although this theory was not justified by the experimental results on the Mask Sub-Challenge, in the Elderly Emotion Sub-Challenge we got significantly improved arousal and valence values with this feature type both on the development set and in cross-validation.
Continuous speech separation: dataset and analysis
Jan 30, 2020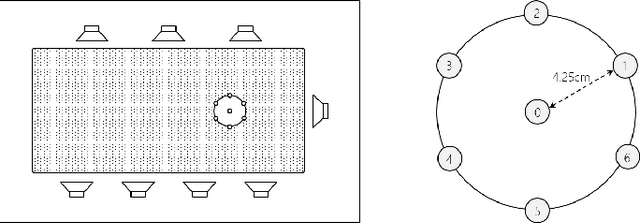
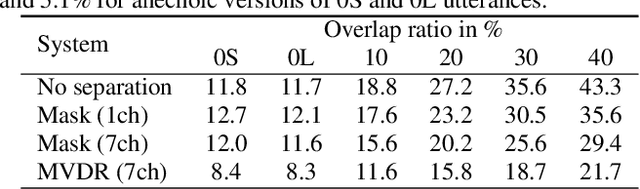
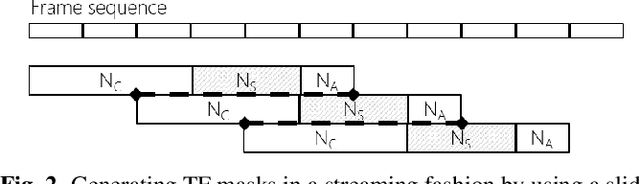
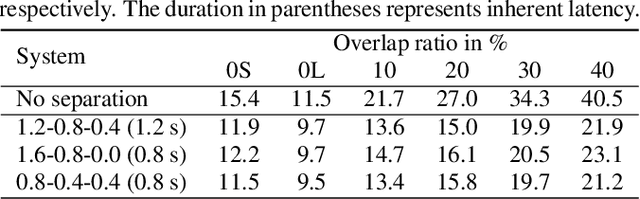
This paper describes a dataset and protocols for evaluating continuous speech separation algorithms. Most prior studies on speech separation use pre-segmented signals of artificially mixed speech utterances which are mostly \emph{fully} overlapped, and the algorithms are evaluated based on signal-to-distortion ratio or similar performance metrics. However, in natural conversations, a speech signal is continuous, containing both overlapped and overlap-free components. In addition, the signal-based metrics have very weak correlations with automatic speech recognition (ASR) accuracy. We think that not only does this make it hard to assess the practical relevance of the tested algorithms, it also hinders researchers from developing systems that can be readily applied to real scenarios. In this paper, we define continuous speech separation (CSS) as a task of generating a set of non-overlapped speech signals from a \textit{continuous} audio stream that contains multiple utterances that are \emph{partially} overlapped by a varying degree. A new real recorded dataset, called LibriCSS, is derived from LibriSpeech by concatenating the corpus utterances to simulate a conversation and capturing the audio replays with far-field microphones. A Kaldi-based ASR evaluation protocol is also established by using a well-trained multi-conditional acoustic model. By using this dataset, several aspects of a recently proposed speaker-independent CSS algorithm are investigated. The dataset and evaluation scripts are available to facilitate the research in this direction.
Gaze-enhanced Crossmodal Embeddings for Emotion Recognition
Apr 30, 2022
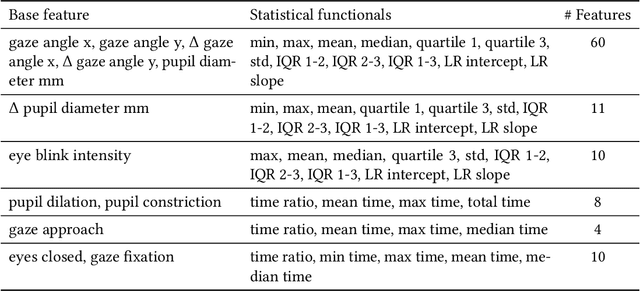

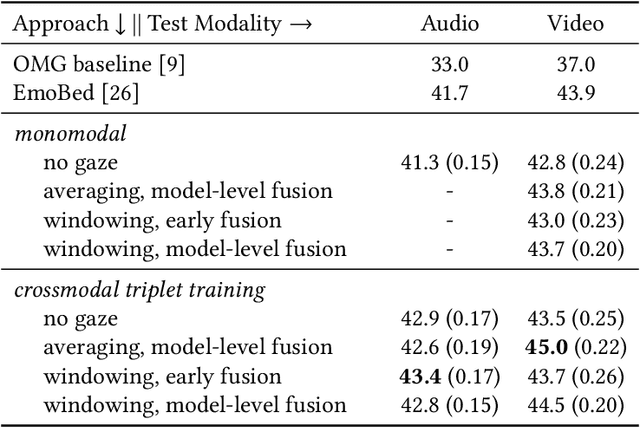
Emotional expressions are inherently multimodal -- integrating facial behavior, speech, and gaze -- but their automatic recognition is often limited to a single modality, e.g. speech during a phone call. While previous work proposed crossmodal emotion embeddings to improve monomodal recognition performance, despite its importance, an explicit representation of gaze was not included. We propose a new approach to emotion recognition that incorporates an explicit representation of gaze in a crossmodal emotion embedding framework. We show that our method outperforms the previous state of the art for both audio-only and video-only emotion classification on the popular One-Minute Gradual Emotion Recognition dataset. Furthermore, we report extensive ablation experiments and provide detailed insights into the performance of different state-of-the-art gaze representations and integration strategies. Our results not only underline the importance of gaze for emotion recognition but also demonstrate a practical and highly effective approach to leveraging gaze information for this task.
dictNN: A Dictionary-Enhanced CNN Approach for Classifying Hate Speech on Twitter
Mar 16, 2021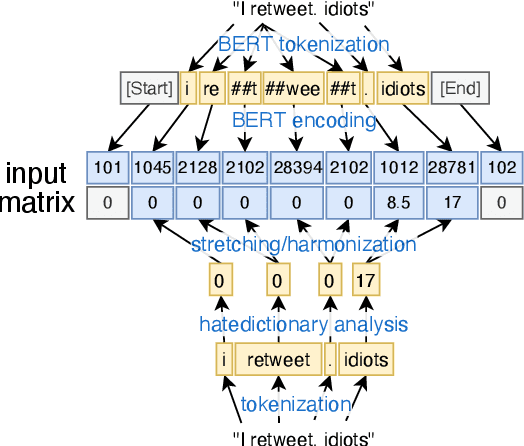
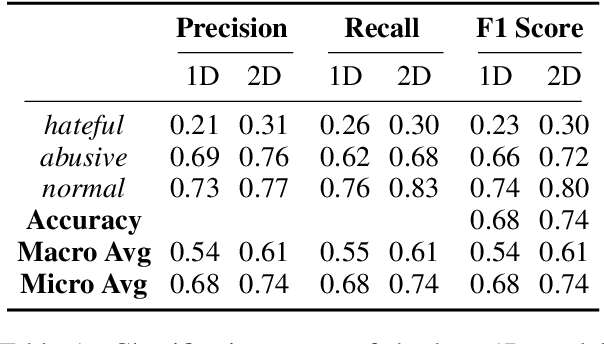

Hate speech on social media is a growing concern, and automated methods have so far been sub-par at reliably detecting it. A major challenge lies in the potentially evasive nature of hate speech due to the ambiguity and fast evolution of natural language. To tackle this, we introduce a vectorisation based on a crowd-sourced and continuously updated dictionary of hate words and propose fusing this approach with standard word embedding in order to improve the classification performance of a CNN model. To train and test our model we use a merge of two established datasets (110,748 tweets in total). By adding the dictionary-enhanced input, we are able to increase the CNN model's predictive power and increase the F1 macro score by seven percentage points.
A General Multi-Task Learning Framework to Leverage Text Data for Speech to Text Tasks
Oct 21, 2020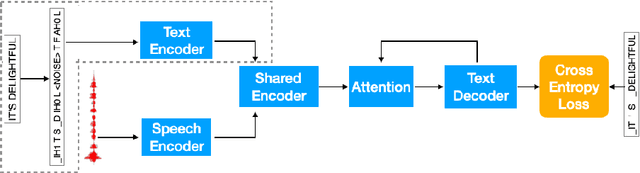
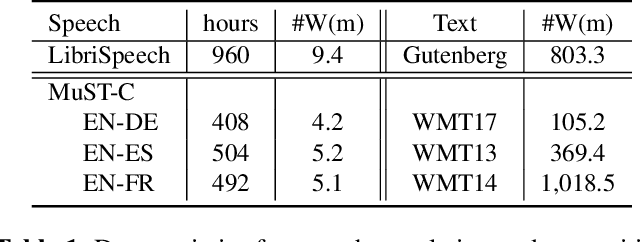
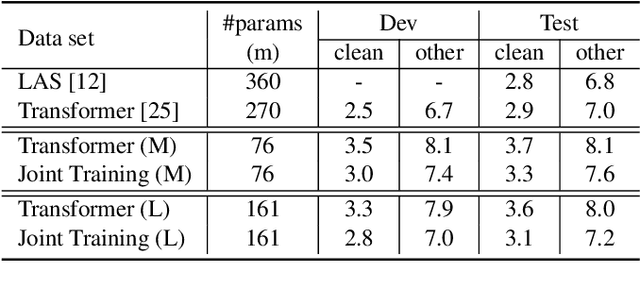
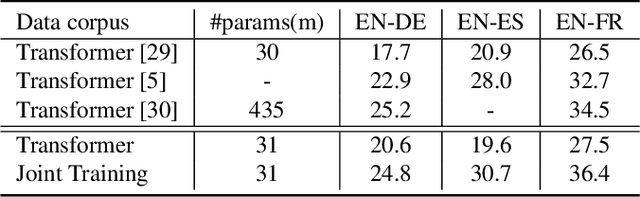
Attention-based sequence-to-sequence modeling provides a powerful and elegant solution for applications that need to map one sequence to a different sequence. Its success heavily relies on the availability of large amounts of training data. This presents a challenge for speech applications where labelled speech data is very expensive to obtain, such as automatic speech recognition (ASR) and speech translation (ST). In this study, we propose a general multi-task learning framework to leverage text data for ASR and ST tasks. Two auxiliary tasks, a denoising autoencoder task and machine translation task, are proposed to be co-trained with ASR and ST tasks respectively. We demonstrate that representing text input as phoneme sequences can reduce the difference between speech and text inputs, and enhance the knowledge transfer from text corpora to the speech to text tasks. Our experiments show that the proposed method achieves a relative 10~15% word error rate reduction on the English Librispeech task, and improves the speech translation quality on the MuST-C tasks by 4.2~11.1 BLEU.
Compute Cost Amortized Transformer for Streaming ASR
Jul 05, 2022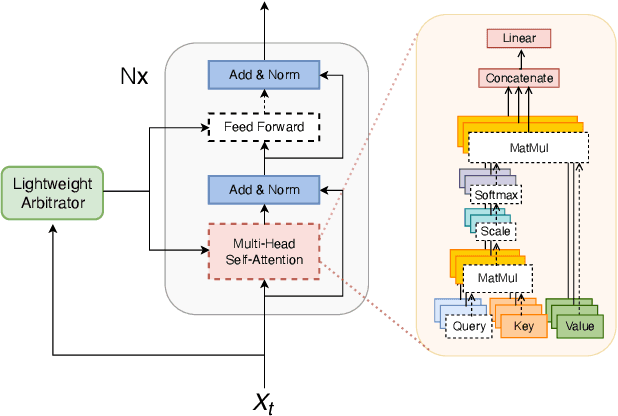
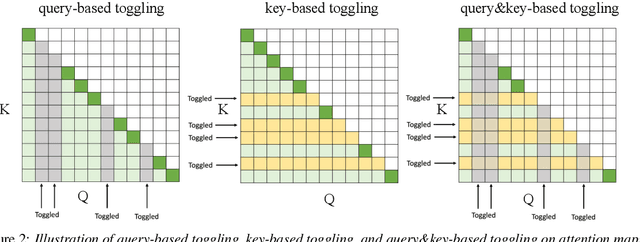
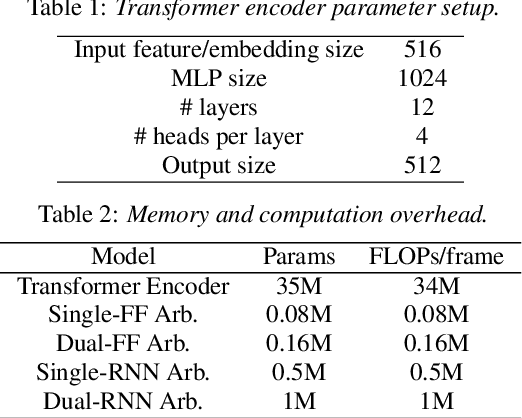
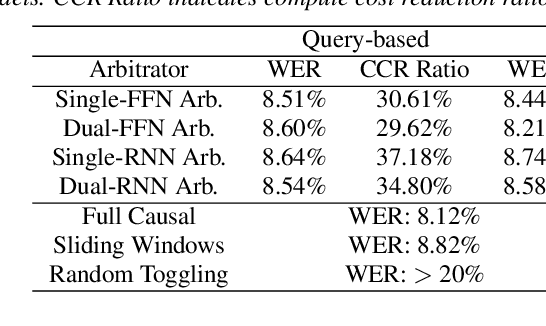
We present a streaming, Transformer-based end-to-end automatic speech recognition (ASR) architecture which achieves efficient neural inference through compute cost amortization. Our architecture creates sparse computation pathways dynamically at inference time, resulting in selective use of compute resources throughout decoding, enabling significant reductions in compute with minimal impact on accuracy. The fully differentiable architecture is trained end-to-end with an accompanying lightweight arbitrator mechanism operating at the frame-level to make dynamic decisions on each input while a tunable loss function is used to regularize the overall level of compute against predictive performance. We report empirical results from experiments using the compute amortized Transformer-Transducer (T-T) model conducted on LibriSpeech data. Our best model can achieve a 60% compute cost reduction with only a 3% relative word error rate (WER) increase.
SLNSpeech: solving extended speech separation problem by the help of sign language
Jul 21, 2020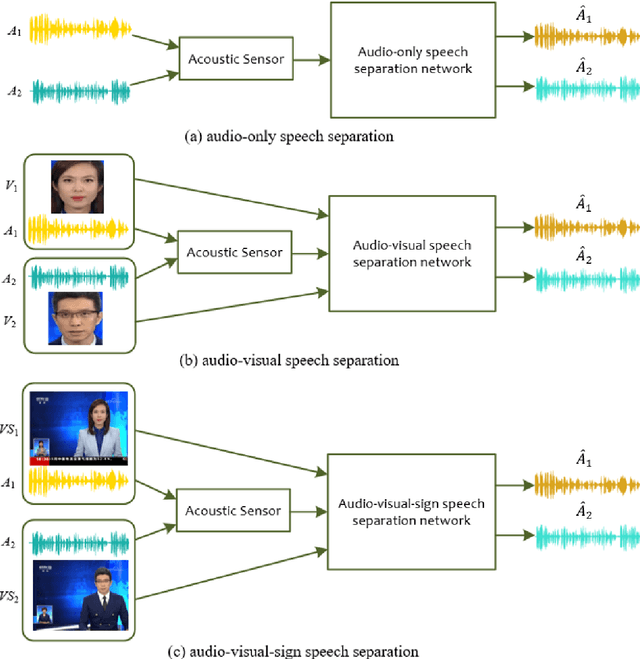


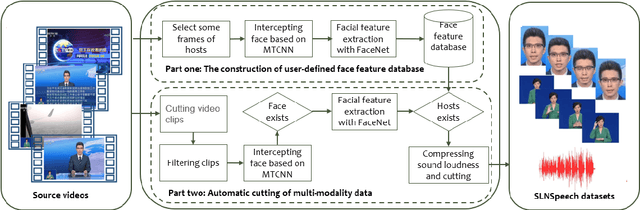
A speech separation task can be roughly divided into audio-only separation and audio-visual separation. In order to make speech separation technology applied in the real scenario of the disabled, this paper presents an extended speech separation problem which refers in particular to sign language assisted speech separation. However, most existing datasets for speech separation are audios and videos which contain audio and/or visual modalities. To address the extended speech separation problem, we introduce a large-scale dataset named Sign Language News Speech (SLNSpeech) dataset in which three modalities of audio, visual, and sign language are coexisted. Then, we design a general deep learning network for the self-supervised learning of three modalities, particularly, using sign language embeddings together with audio or audio-visual information for better solving the speech separation task. Specifically, we use 3D residual convolutional network to extract sign language features and use pretrained VGGNet model to exact visual features. After that, an improved U-Net with skip connections in feature extraction stage is applied for learning the embeddings among the mixed spectrogram transformed from source audios, the sign language features and visual features. Experiments results show that, besides visual modality, sign language modality can also be used alone to supervise speech separation task. Moreover, we also show the effectiveness of sign language assisted speech separation when the visual modality is disturbed. Source code will be released in http://cheertt.top/homepage/