 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
FastPitch: Parallel Text-to-speech with Pitch Prediction
Jun 11, 2020
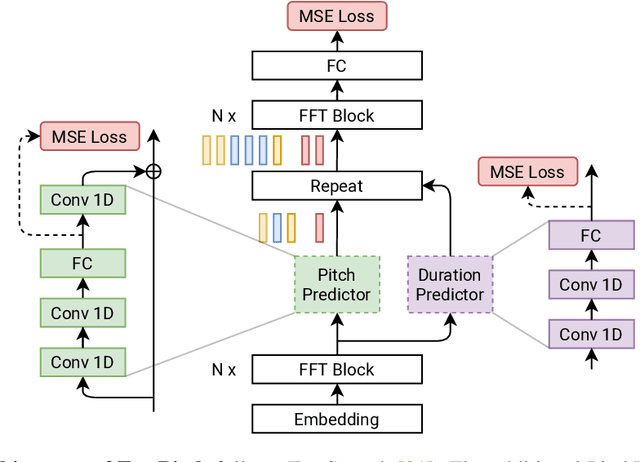
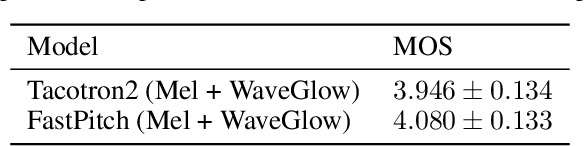
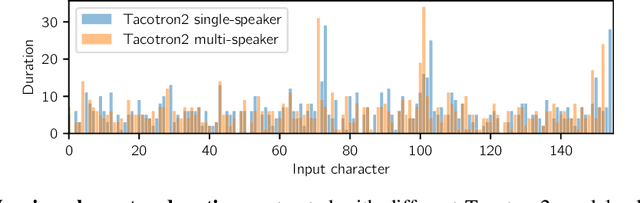

We present FastPitch, a fully-parallel text-to-speech model based on FastSpeech, conditioned on fundamental frequency contours. The model predicts pitch contours during inference, and generates speech that could be further controlled with predicted contours. FastPitch can thus change the perceived emotional state of the speaker or put emphasis on certain lexical units. We find that uniformly increasing or decreasing the pitch with FastPitch generates speech that resembles the voluntary modulation of voice. Conditioning on frequency contours improves the quality of synthesized speech, making it comparable to state-of-the-art. It does not introduce an overhead, and FastPitch retains the favorable, fully-parallel Transformer architecture of FastSpeech with a similar speed of mel-scale spectrogram synthesis, orders of magnitude faster than real-time.
A Spoken Drug Prescription Dataset in French for Spoken Language Understanding
Jul 17, 2022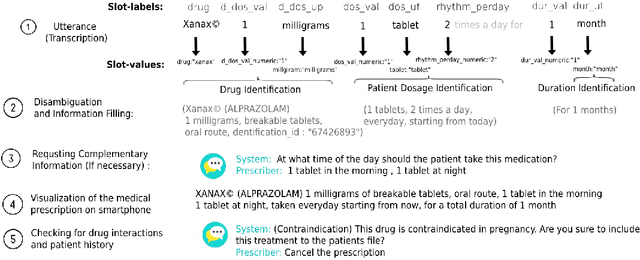
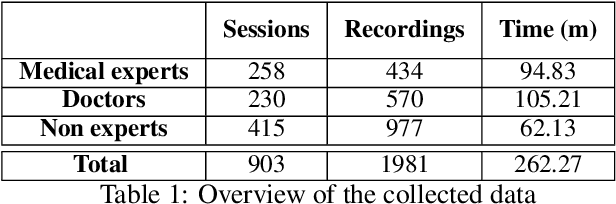


Spoken medical dialogue systems are increasingly attracting interest to enhance access to healthcare services and improve quality and traceability of patient care. In this paper, we focus on medical drug prescriptions acquired on smartphones through spoken dialogue. Such systems would facilitate the traceability of care and would free clinicians' time. However, there is a lack of speech corpora to develop such systems since most of the related corpora are in text form and in English. To facilitate the research and development of spoken medical dialogue systems, we present, to the best of our knowledge, the first spoken medical drug prescriptions corpus, named PxSLU. It contains 4 hours of transcribed and annotated dialogues of drug prescriptions in French acquired through an experiment with 55 participants experts and non-experts in prescriptions. We also present some experiments that demonstrate the interest of this corpus for the evaluation and development of medical dialogue systems.
Assessing clinical utility of Machine Learning and Artificial Intelligence approaches to analyze speech recordings in Multiple Sclerosis: A Pilot Study
Sep 27, 2021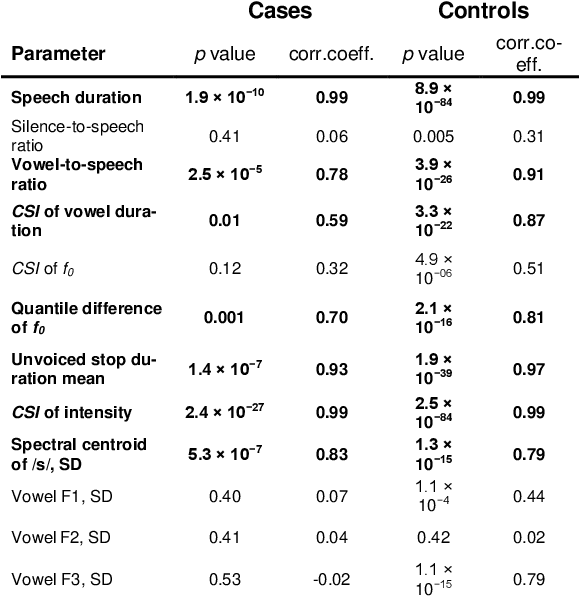
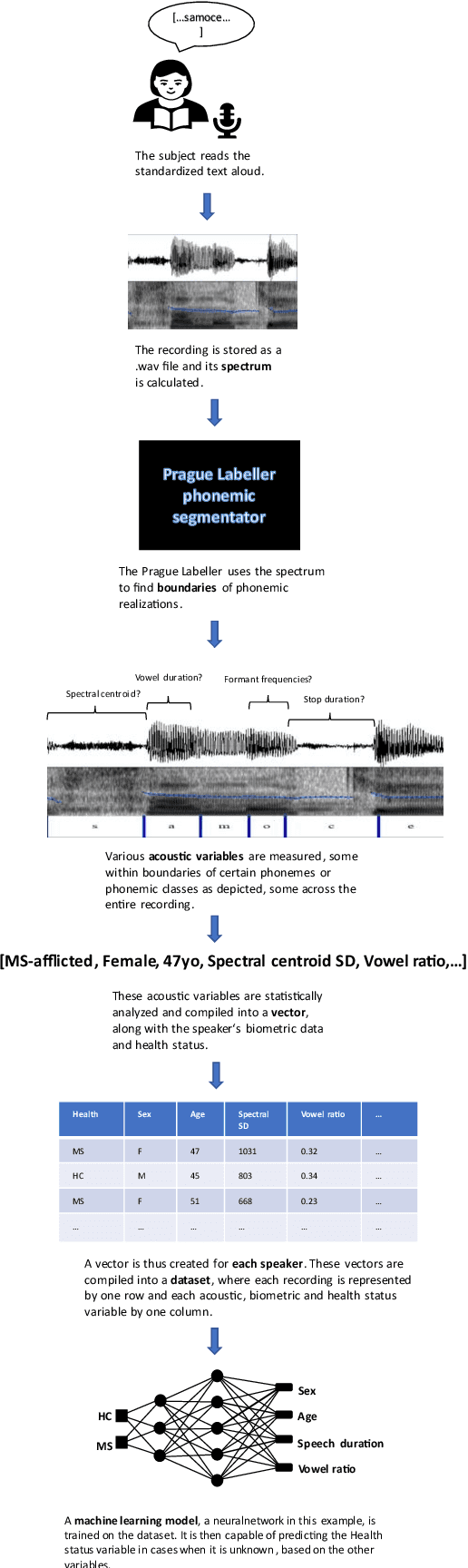
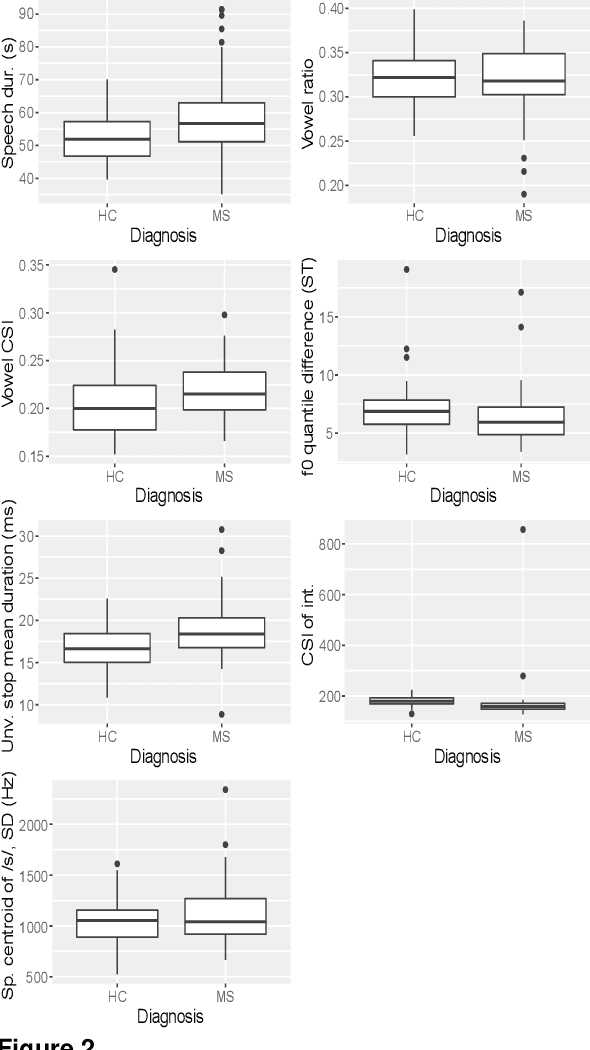
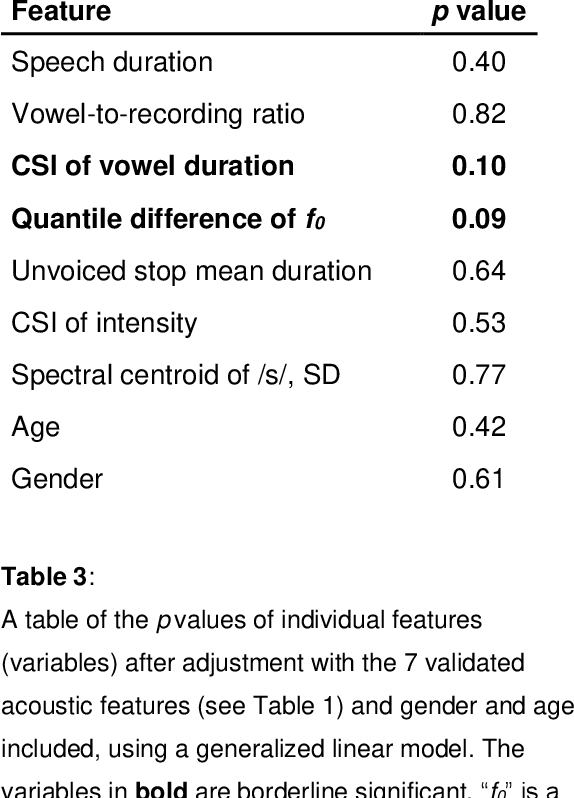
Background: An early diagnosis together with an accurate disease progression monitoring of multiple sclerosis is an important component of successful disease management. Prior studies have established that multiple sclerosis is correlated with speech discrepancies. Early research using objective acoustic measurements has discovered measurable dysarthria. Objective: To determine the potential clinical utility of machine learning and deep learning/AI approaches for the aiding of diagnosis, biomarker extraction and progression monitoring of multiple sclerosis using speech recordings. Methods: A corpus of 65 MS-positive and 66 healthy individuals reading the same text aloud was used for targeted acoustic feature extraction utilizing automatic phoneme segmentation. A series of binary classification models was trained, tuned, and evaluated regarding their Accuracy and area-under-curve. Results: The Random Forest model performed best, achieving an Accuracy of 0.82 on the validation dataset and an area-under-curve of 0.76 across 5 k-fold cycles on the training dataset. 5 out of 7 acoustic features were statistically significant. Conclusion: Machine learning and artificial intelligence in automatic analyses of voice recordings for aiding MS diagnosis and progression tracking seems promising. Further clinical validation of these methods and their mapping onto multiple sclerosis progression is needed, as well as a validating utility for English-speaking populations.
Towards Unconstrained Audio Splicing Detection and Localization with Neural Networks
Jul 29, 2022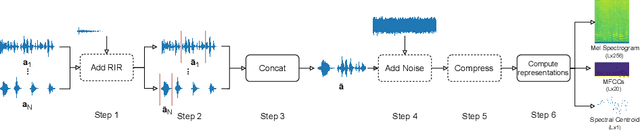
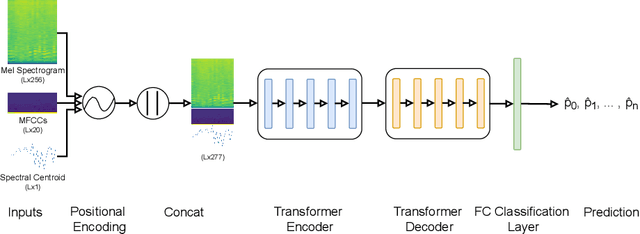
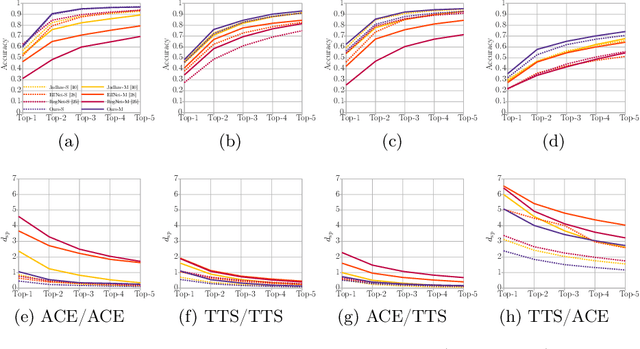
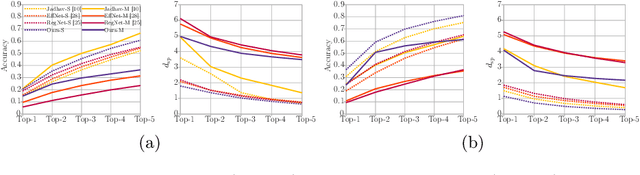
Freely available and easy-to-use audio editing tools make it straightforward to perform audio splicing. Convincing forgeries can be created by combining various speech samples from the same person. Detection of such splices is important both in the public sector when considering misinformation, and in a legal context to verify the integrity of evidence. Unfortunately, most existing detection algorithms for audio splicing use handcrafted features and make specific assumptions. However, criminal investigators are often faced with audio samples from unconstrained sources with unknown characteristics, which raises the need for more generally applicable methods. With this work, we aim to take a first step towards unconstrained audio splicing detection to address this need. We simulate various attack scenarios in the form of post-processing operations that may disguise splicing. We propose a Transformer sequence-to-sequence (seq2seq) network for splicing detection and localization. Our extensive evaluation shows that the proposed method outperforms existing dedicated approaches for splicing detection [3, 10] as well as the general-purpose networks EfficientNet [28] and RegNet [25].
S3PRL-VC: Open-source Voice Conversion Framework with Self-supervised Speech Representations
Oct 12, 2021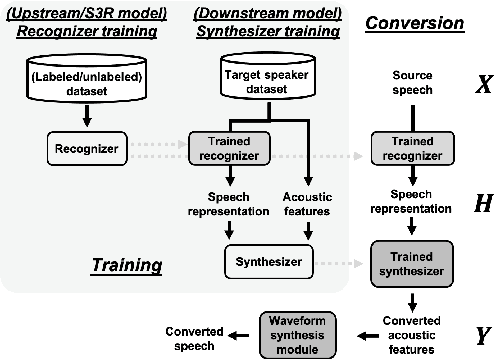
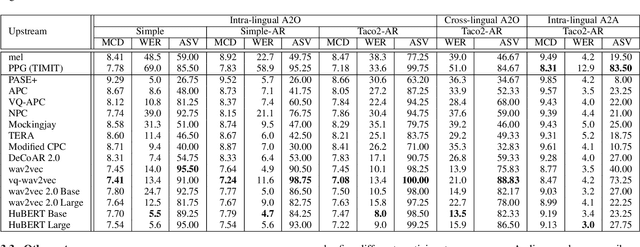
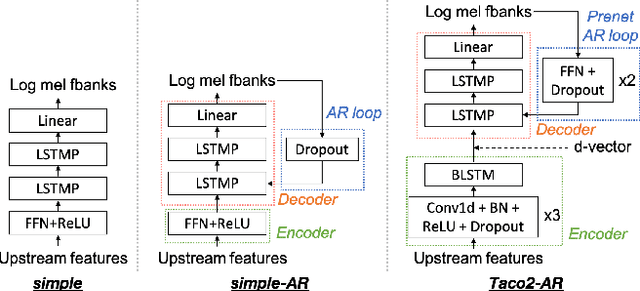
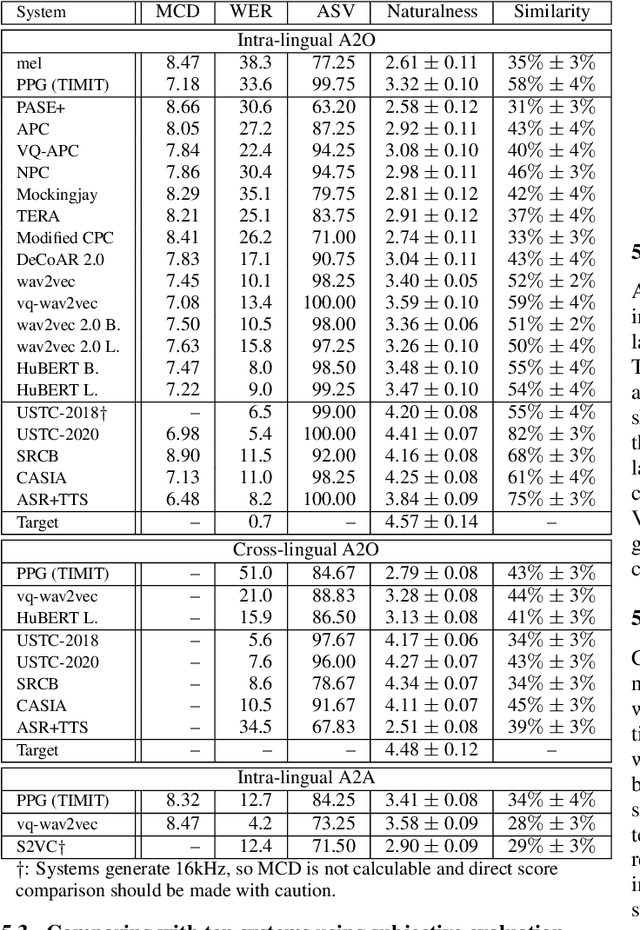
This paper introduces S3PRL-VC, an open-source voice conversion (VC) framework based on the S3PRL toolkit. In the context of recognition-synthesis VC, self-supervised speech representation (S3R) is valuable in its potential to replace the expensive supervised representation adopted by state-of-the-art VC systems. Moreover, we claim that VC is a good probing task for S3R analysis. In this work, we provide a series of in-depth analyses by benchmarking on the two tasks in VCC2020, namely intra-/cross-lingual any-to-one (A2O) VC, as well as an any-to-any (A2A) setting. We also provide comparisons between not only different S3Rs but also top systems in VCC2020 with supervised representations. Systematic objective and subjective evaluation were conducted, and we show that S3R is comparable with VCC2020 top systems in the A2O setting in terms of similarity, and achieves state-of-the-art in S3R-based A2A VC. We believe the extensive analysis, as well as the toolkit itself, contribute to not only the S3R community but also the VC community. The codebase is now open-sourced.
Neural Speech Separation Using Spatially Distributed Microphones
Apr 28, 2020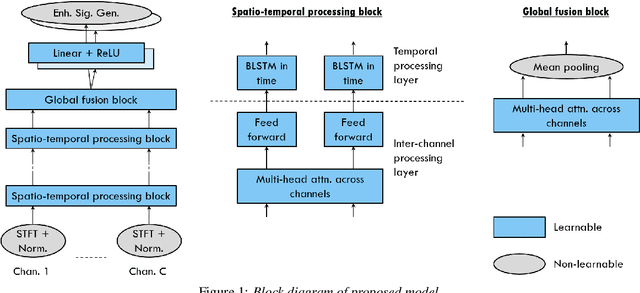
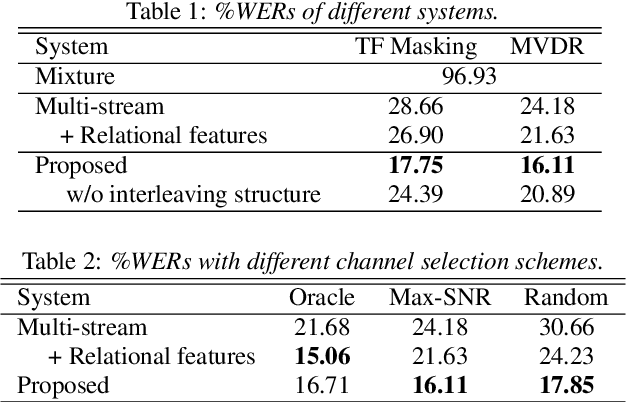
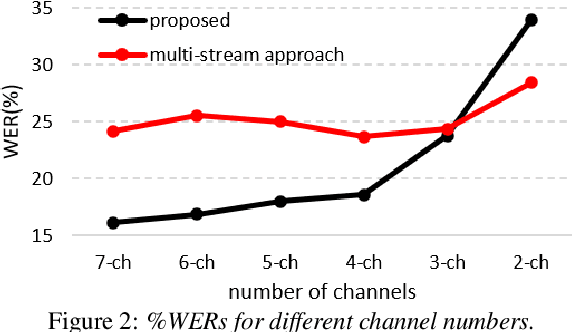
This paper proposes a neural network based speech separation method using spatially distributed microphones. Unlike with traditional microphone array settings, neither the number of microphones nor their spatial arrangement is known in advance, which hinders the use of conventional multi-channel speech separation neural networks based on fixed size input. To overcome this, a novel network architecture is proposed that interleaves inter-channel processing layers and temporal processing layers. The inter-channel processing layers apply a self-attention mechanism along the channel dimension to exploit the information obtained with a varying number of microphones. The temporal processing layers are based on a bidirectional long short term memory (BLSTM) model and applied to each channel independently. The proposed network leverages information across time and space by stacking these two kinds of layers alternately. Our network estimates time-frequency (TF) masks for each speaker, which are then used to generate enhanced speech signals either with TF masking or beamforming. Speech recognition experimental results show that the proposed method significantly outperforms baseline multi-channel speech separation systems.
Multi-channel Multi-frame ADL-MVDR for Target Speech Separation
Dec 24, 2020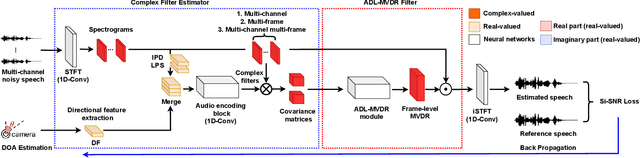
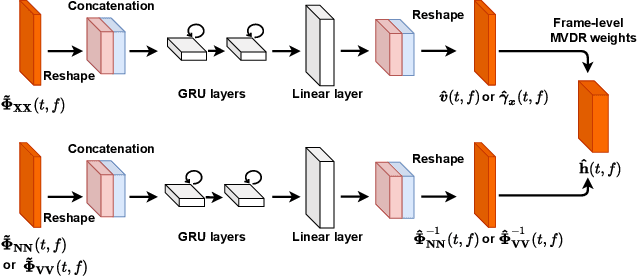
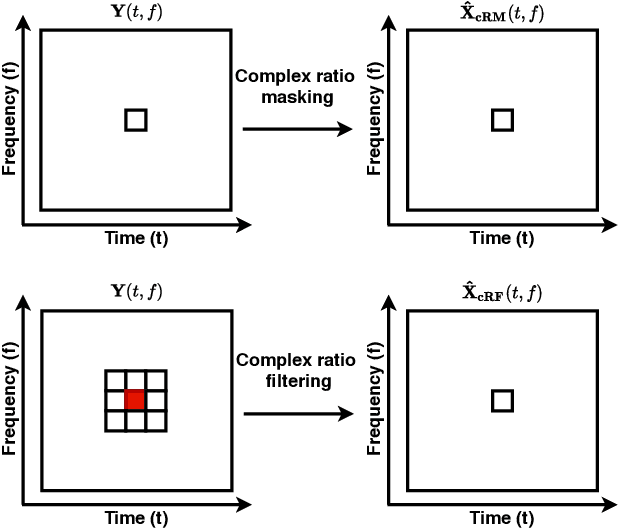
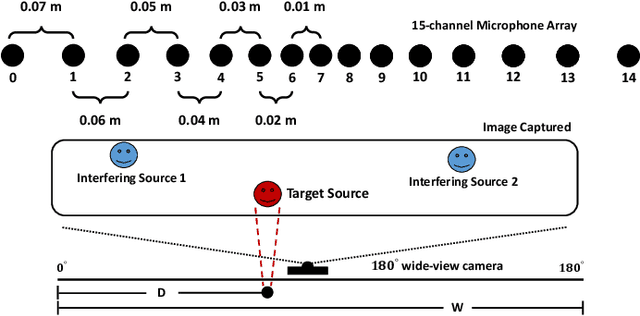
Many purely neural network based speech separation approaches have been proposed that greatly improve objective assessment scores, but they often introduce nonlinear distortions that are harmful to automatic speech recognition (ASR). Minimum variance distortionless response (MVDR) filters strive to remove nonlinear distortions, however, these approaches either are not optimal for removing residual (linear) noise, or they are unstable when used jointly with neural networks. In this study, we propose a multi-channel multi-frame (MCMF) all deep learning (ADL)-MVDR approach for target speech separation, which extends our preliminary multi-channel ADL-MVDR approach. The MCMF ADL-MVDR handles different numbers of microphone channels in one framework, where it addresses linear and nonlinear distortions. Spatio-temporal cross correlations are also fully utilized in the proposed approach. The proposed system is evaluated using a Mandarin audio-visual corpora and is compared with several state-of-the-art approaches. Experimental results demonstrate the superiority of our proposed framework under different scenarios and across several objective evaluation metrics, including ASR performance.
Nonlinear prediction with neural nets in ADPCM
Mar 22, 2022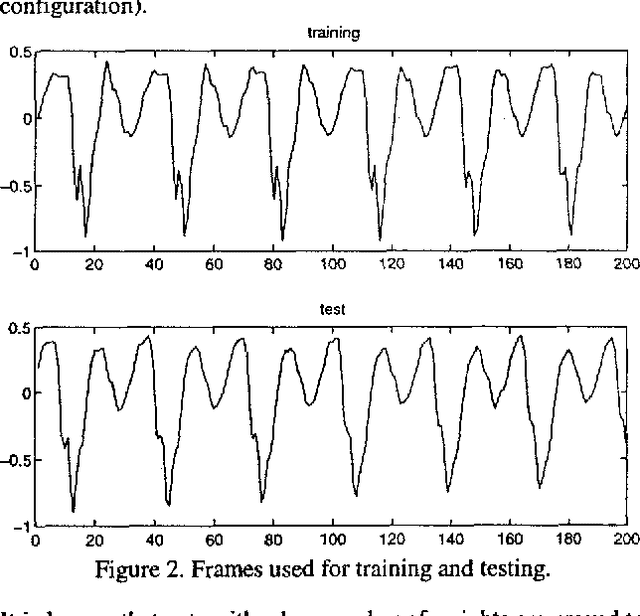
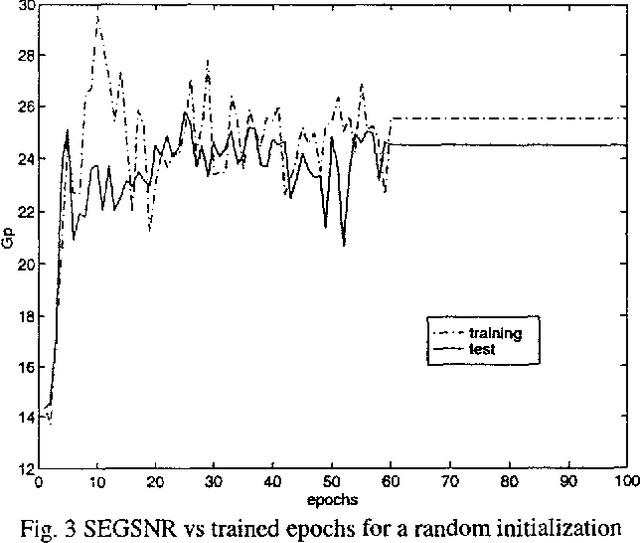
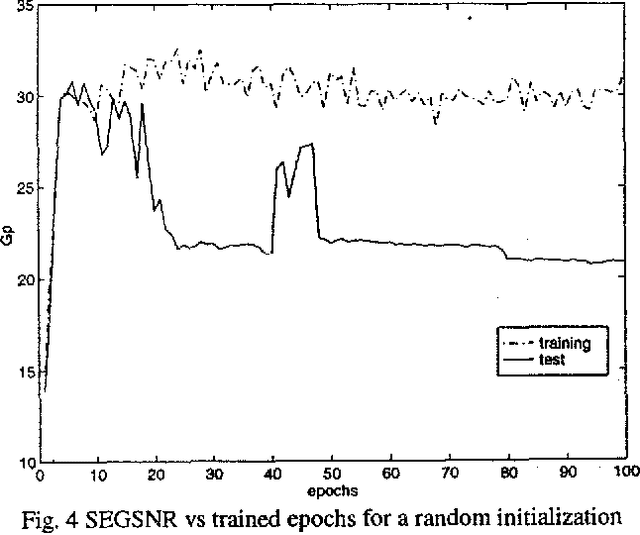
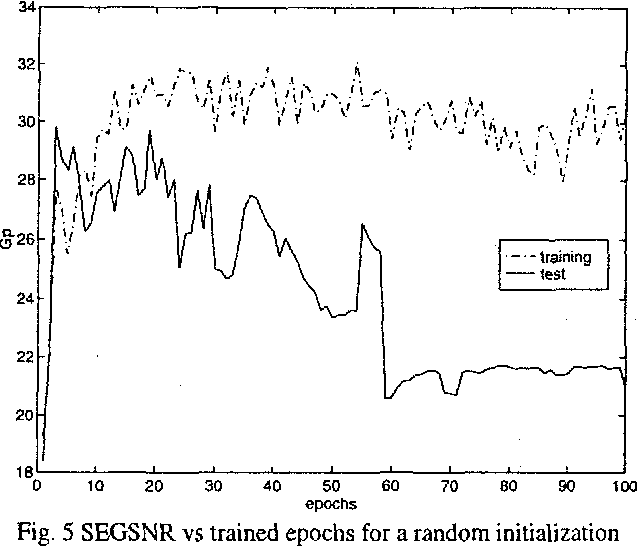
In the last years there has been a growing interest for nonlinear speech models. Several works have been published revealing the better performance of nonlinear techniques, but little attention has been dedicated to the implementation of the nonlinear model into real applications. This work is focused on the study of the behaviour of a nonlinear predictive model based on neural nets, in a speech waveform coder. Our novel scheme obtains an improvement in SEGSNR between 1 and 2 dB for an adaptive quantization ranging from 2 to 5 bits.
* 4 pages, published in Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP '98 (Cat. No.98CH36181) Seattle, WA, USA. arXiv admin note: text overlap with arXiv:2203.01818
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022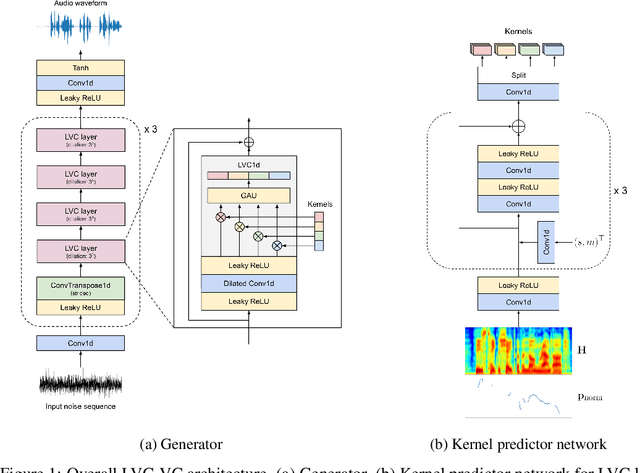
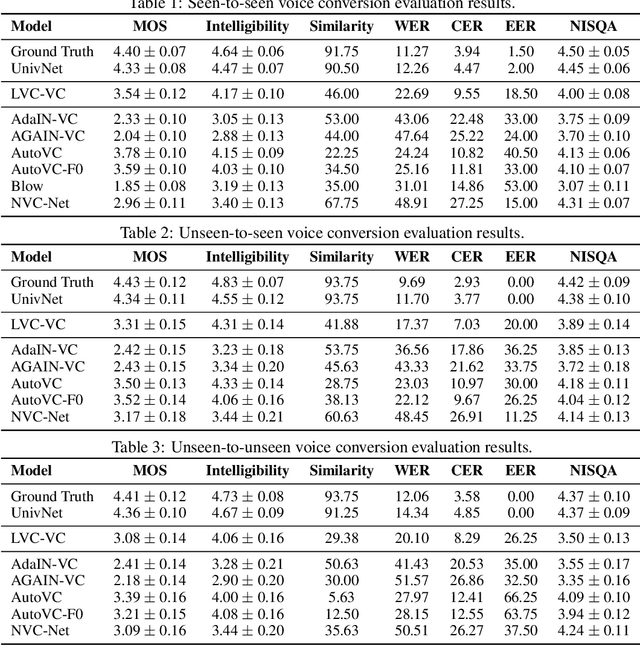

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.
Continuous Silent Speech Recognition using EEG
Feb 29, 2020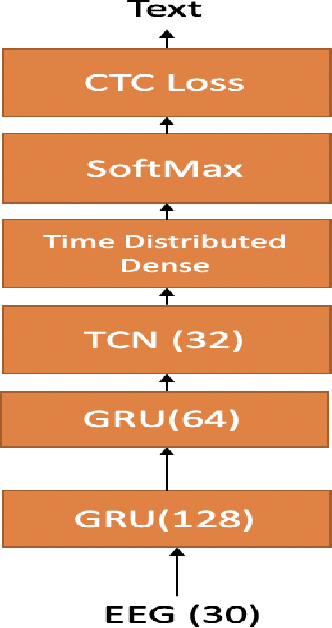
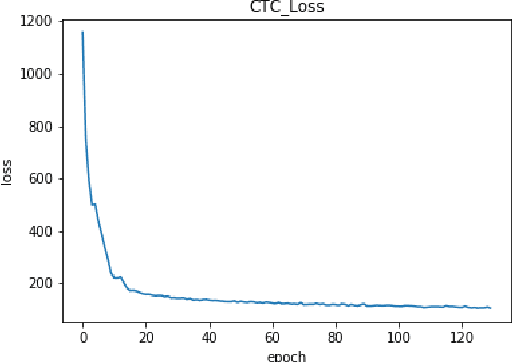
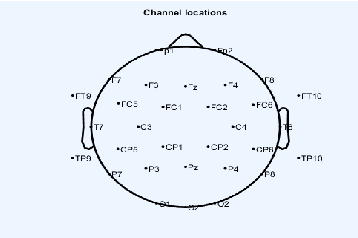
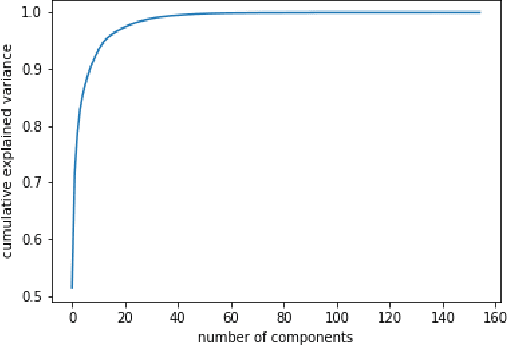
In this paper we explore continuous silent speech recognition using electroencephalography (EEG) signals. We implemented a connectionist temporal classification (CTC) automatic speech recognition (ASR) model to translate EEG signals recorded in parallel while subjects were reading English sentences in their mind without producing any voice to text. Our results demonstrate the feasibility of using EEG signals for performing continuous silent speech recognition. We demonstrate our results for a limited English vocabulary consisting of 30 unique sentences.