 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023
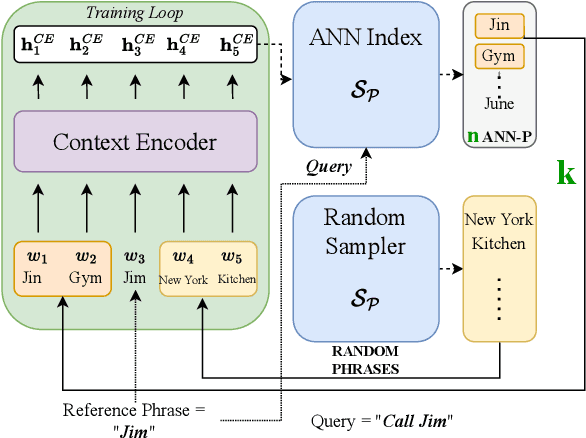
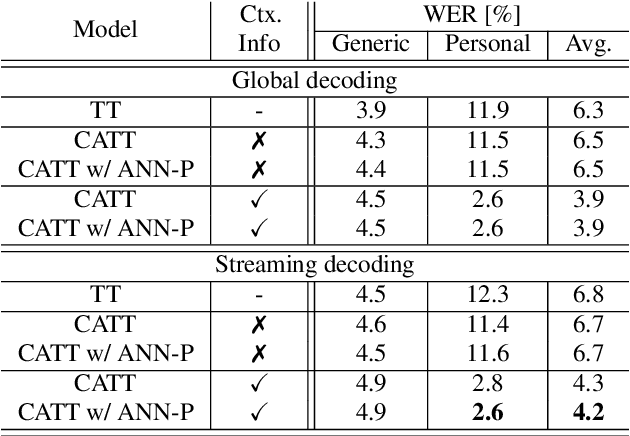
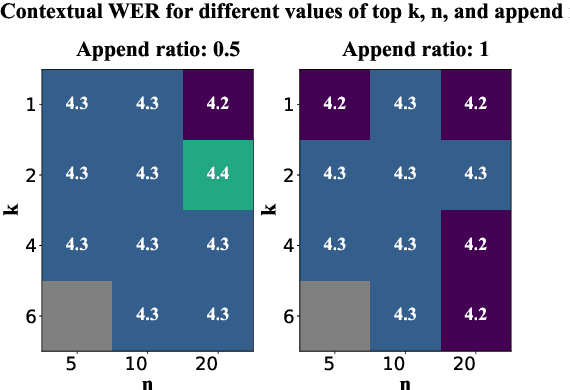

This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
NBC2: Multichannel Speech Separation with Revised Narrow-band Conformer
Dec 05, 2022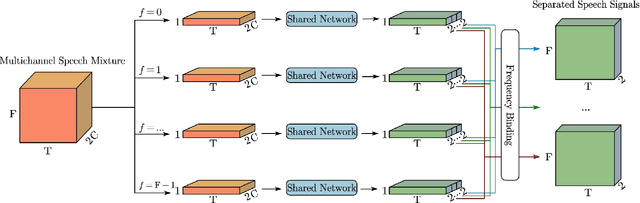
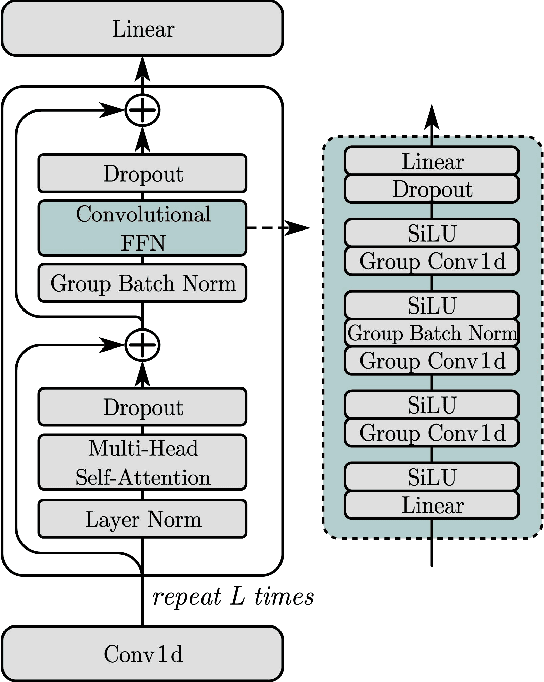
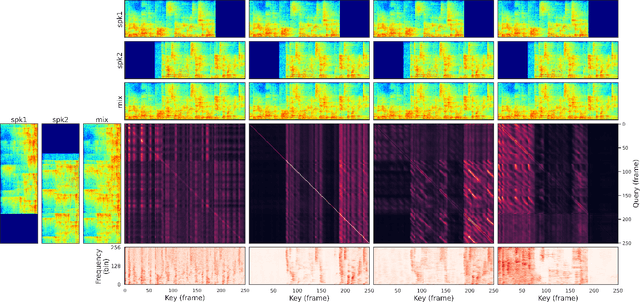
This work proposes a multichannel narrow-band speech separation network. In the short-time Fourier transform (STFT) domain, the proposed network processes each frequency independently, and all frequencies use a shared network. For each frequency, the network performs end-to-end speech separation, namely taking as input the STFT coefficients of microphone signals, and predicting the separated STFT coefficients of multiple speakers. The proposed network learns to cluster the frame-wise spatial/steering vectors that belong to different speakers. It is mainly composed of three components. First, a self-attention network. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Second, a convolutional feed-forward network. The convolutional layers are employed for signal smoothing and reverberation processing. Third, a novel hidden-layer normalization method, i.e. group batch normalization (GBN), is especially designed for the proposed narrow-band network to maintain the distribution of hidden units over frequencies. Overall, the proposed network is named NBC2, as it is a revised version of our previous NBC (narrow-band conformer) network. Experiments show that 1) the proposed network outperforms other state-of-the-art methods by a large margin, 2) the proposed GBN improves the signal-to-distortion ratio by 3 dB, relative to other normalization methods, such as batch/layer/group normalization, 3) the proposed narrow-band network is spectrum-agnostic, as it does not learn spectral patterns, and 4) the proposed network is indeed performing frame clustering (demonstrated by the attention maps).
Learning to Compute the Articulatory Representations of Speech with the MIRRORNET
Oct 29, 2022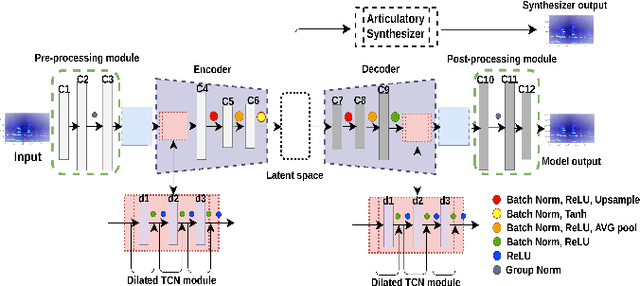
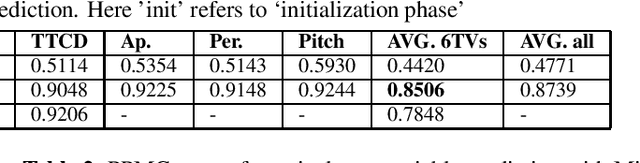
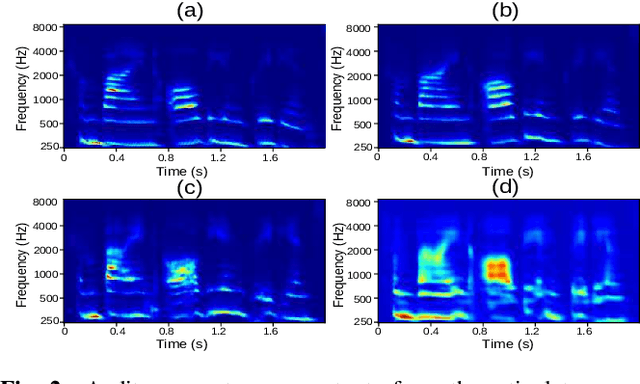
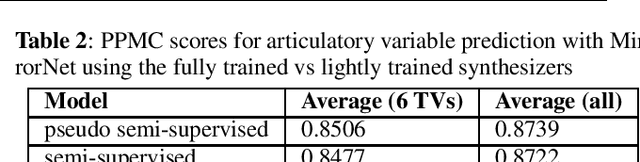
Most organisms including humans function by coordinating and integrating sensory signals with motor actions to survive and accomplish desired tasks. Learning these complex sensorimotor mappings proceeds simultaneously and often in an unsupervised or semi-supervised fashion. An autoencoder architecture (MirrorNet) inspired by this sensorimotor learning paradigm is explored in this work to learn how to control an articulatory synthesizer. The synthesizer takes as input control signals consisting of six vocal Tract Variables (TVs) and source features (voicing indicators and pitch), and generates the corresponding auditory spectrograms. Due to the non-linear structure of the synthesizer, the control parameters that produce a target speech signal are not readily computable nor are they always unique. Here we demonstrate how to initialize the MirrorNet learning so as to produce a meaningful range of articulatory values. Once trained, the MirrorNet successfully estimates the TVs and source features needed to synthesize any arbitrary speech utterance. This approach outperforms the best previously designed `speech inversion' systems on the Wisconsin X-ray microbeam (XRMB) dataset.
CHAPTER: Exploiting Convolutional Neural Network Adapters for Self-supervised Speech Models
Dec 01, 2022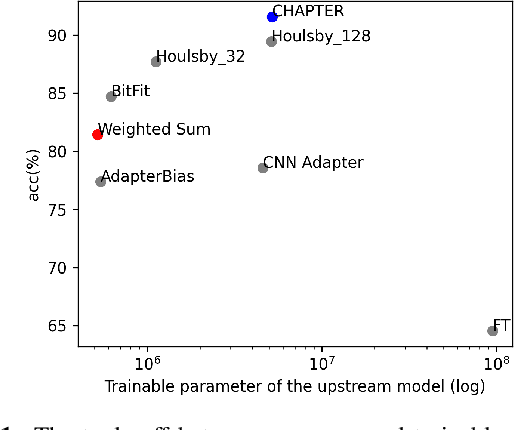
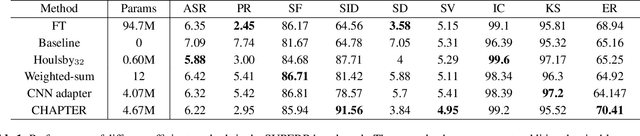
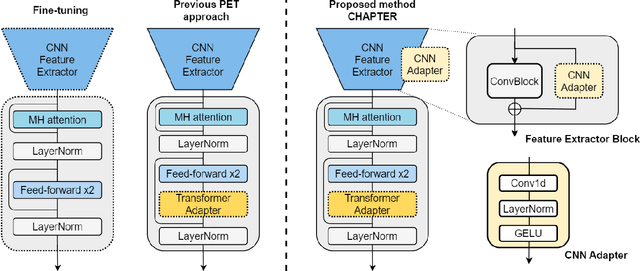
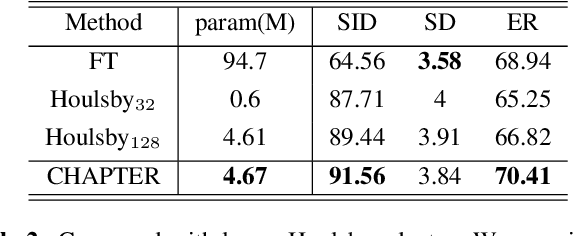
Self-supervised learning (SSL) is a powerful technique for learning representations from unlabeled data. Transformer based models such as HuBERT, which consist a feature extractor and transformer layers, are leading the field in the speech domain. SSL models are fine-tuned on a wide range of downstream tasks, which involves re-training the majority of the model for each task. Previous studies have introduced applying adapters, which are small lightweight modules commonly used in Natural Language Processing (NLP) to adapt pre-trained models to new tasks. However, such efficient tuning techniques only provide adaptation at the transformer layer, but failed to perform adaptation at the feature extractor. In this paper, we propose CHAPTER, an efficient tuning method specifically designed for SSL speech model, by applying CNN adapters at the feature extractor. Using this method, we can only fine-tune fewer than 5% of parameters per task compared to fully fine-tuning and achieve better and more stable performance. We empirically found that adding CNN adapters to the feature extractor can help the adaptation on emotion and speaker tasks. For instance, the accuracy of SID is improved from 87.71 to 91.56, and the accuracy of ER is improved by 5%.
"My Unconditional Homework Buddy:'' Exploring Children's Preferences for a Homework Companion Robot
May 04, 2023



We aim to design robotic educational support systems that can promote socially and intellectually meaningful learning experiences for students while they complete school work outside of class. To pursue this goal, we conducted participatory design studies with 10 children (aged 10--12) to explore their design needs for robot-assisted homework. We investigated children's current ways of doing homework, the type of support they receive while doing homework, and co-designed the speech and expressiveness of a homework companion robot. Children and parents attending our design sessions explained that an emotionally expressive social robot as a homework aid can support students' motivation and engagement, as well as their affective state. Children primarily perceived the robot as a dedicated assistant at home, capable of forming meaningful friendships, or a shared classroom learning resource. We present key design recommendations to support students' homework experiences with a learning companion robot.
Who Needs Decoders? Efficient Estimation of Sequence-level Attributes
May 09, 2023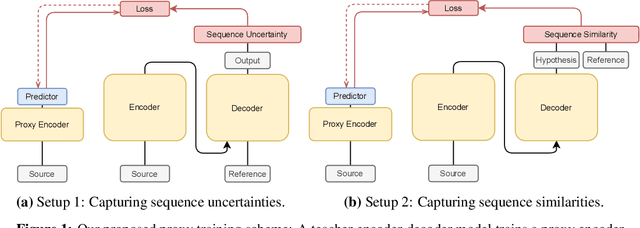

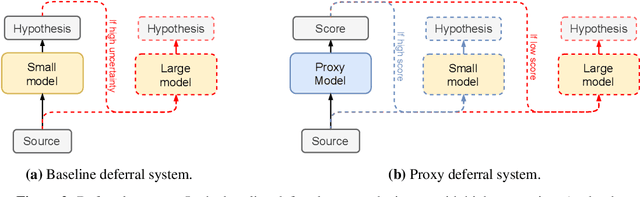
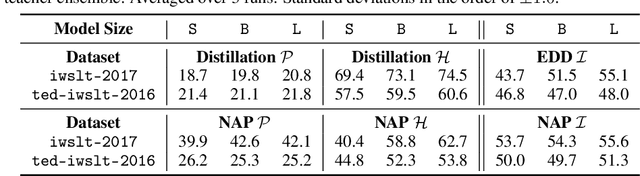
State-of-the-art sequence-to-sequence models often require autoregressive decoding, which can be highly expensive. However, for some downstream tasks such as out-of-distribution (OOD) detection and resource allocation, the actual decoding output is not needed just a scalar attribute of this sequence. In these scenarios, where for example knowing the quality of a system's output to predict poor performance prevails over knowing the output itself, is it possible to bypass the autoregressive decoding? We propose Non-Autoregressive Proxy (NAP) models that can efficiently predict general scalar-valued sequence-level attributes. Importantly, NAPs predict these metrics directly from the encodings, avoiding the expensive autoregressive decoding stage. We consider two sequence-to-sequence task: Machine Translation (MT); and Automatic Speech Recognition (ASR). In OOD for MT, NAPs outperform a deep ensemble while being significantly faster. NAPs are also shown to be able to predict performance metrics such as BERTScore (MT) or word error rate (ASR). For downstream tasks, such as data filtering and resource optimization, NAPs generate performance predictions that outperform predictive uncertainty while being highly inference efficient.
Down the Rabbit Hole: Detecting Online Extremism, Radicalisation, and Politicised Hate Speech
Jan 27, 2023
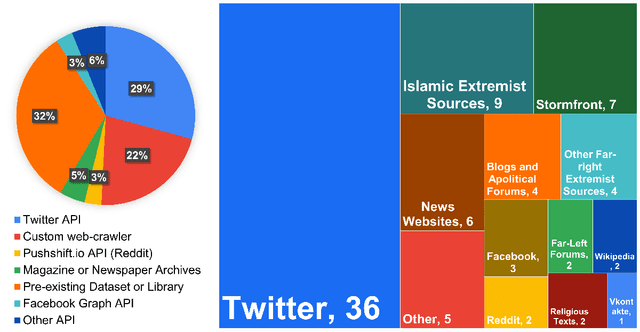


Social media is a modern person's digital voice to project and engage with new ideas and mobilise communities $\unicode{x2013}$ a power shared with extremists. Given the societal risks of unvetted content-moderating algorithms for Extremism, Radicalisation, and Hate speech (ERH) detection, responsible software engineering must understand the who, what, when, where, and why such models are necessary to protect user safety and free expression. Hence, we propose and examine the unique research field of ERH context mining to unify disjoint studies. Specifically, we evaluate the start-to-finish design process from socio-technical definition-building and dataset collection strategies to technical algorithm design and performance. Our 2015-2021 51-study Systematic Literature Review (SLR) provides the first cross-examination of textual, network, and visual approaches to detecting extremist affiliation, hateful content, and radicalisation towards groups and movements. We identify consensus-driven ERH definitions and propose solutions to existing ideological and geographic biases, particularly due to the lack of research in Oceania/Australasia. Our hybridised investigation on Natural Language Processing, Community Detection, and visual-text models demonstrates the dominating performance of textual transformer-based algorithms. We conclude with vital recommendations for ERH context mining researchers and propose an uptake roadmap with guidelines for researchers, industries, and governments to enable a safer cyberspace.
Improving Perceptual Quality, Intelligibility, and Acoustics on VoIP Platforms
Mar 16, 2023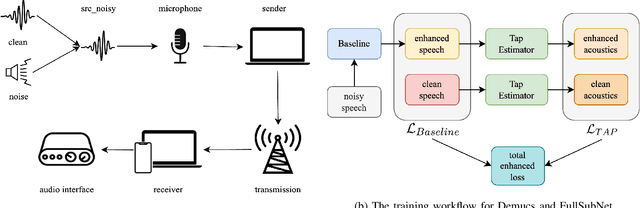
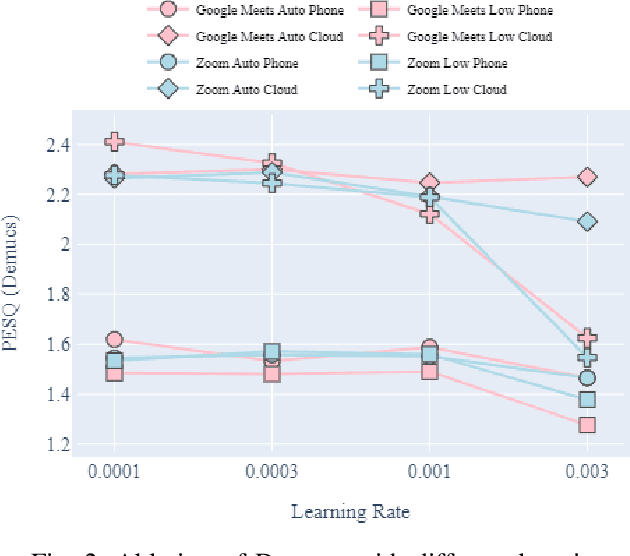
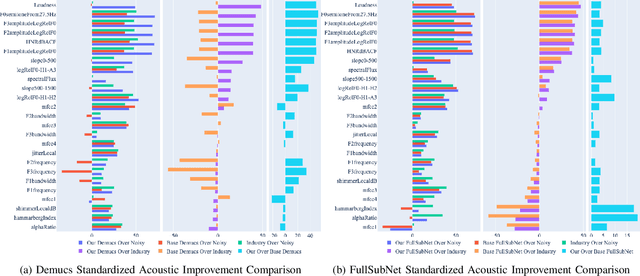

In this paper, we present a method for fine-tuning models trained on the Deep Noise Suppression (DNS) 2020 Challenge to improve their performance on Voice over Internet Protocol (VoIP) applications. Our approach involves adapting the DNS 2020 models to the specific acoustic characteristics of VoIP communications, which includes distortion and artifacts caused by compression, transmission, and platform-specific processing. To this end, we propose a multi-task learning framework for VoIP-DNS that jointly optimizes noise suppression and VoIP-specific acoustics for speech enhancement. We evaluate our approach on a diverse VoIP scenarios and show that it outperforms both industry performance and state-of-the-art methods for speech enhancement on VoIP applications. Our results demonstrate the potential of models trained on DNS-2020 to be improved and tailored to different VoIP platforms using VoIP-DNS, whose findings have important applications in areas such as speech recognition, voice assistants, and telecommunication.
A Persian ASR-based SER: Modification of Sharif Emotional Speech Database and Investigation of Persian Text Corpora
Nov 18, 2022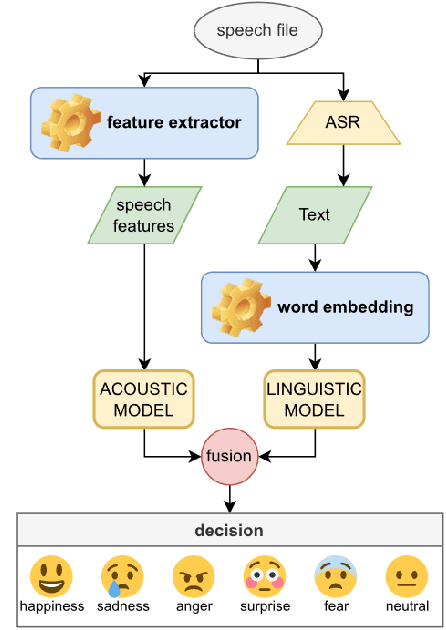
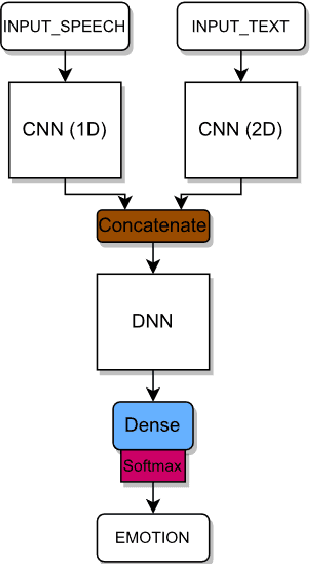

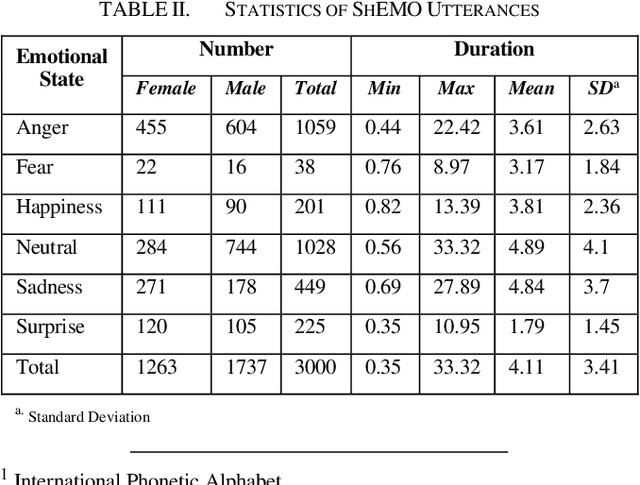
Speech Emotion Recognition (SER) is one of the essential perceptual methods of humans in understanding the situation and how to interact with others, therefore, in recent years, it has been tried to add the ability to recognize emotions to human-machine communication systems. Since the SER process relies on labeled data, databases are essential for it. Incomplete, low-quality or defective data may lead to inaccurate predictions. In this paper, we fixed the inconsistencies in Sharif Emotional Speech Database (ShEMO), as a Persian database, by using an Automatic Speech Recognition (ASR) system and investigating the effect of Farsi language models obtained from accessible Persian text corpora. We also introduced a Persian/Farsi ASR-based SER system that uses linguistic features of the ASR outputs and Deep Learning-based models.
Multilingual Auxiliary Tasks Training: Bridging the Gap between Languages for Zero-Shot Transfer of Hate Speech Detection Models
Oct 25, 2022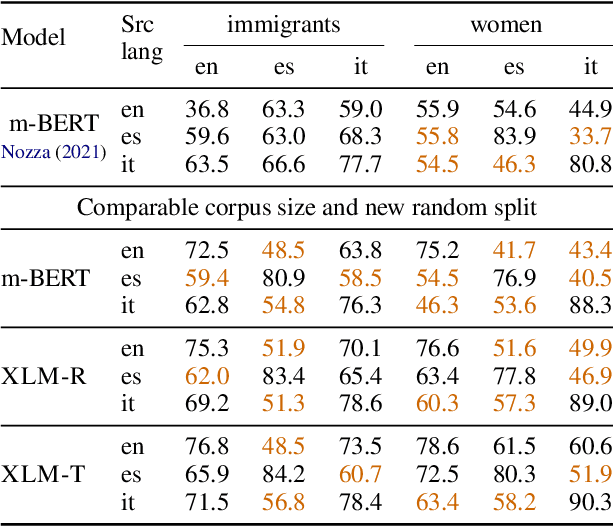
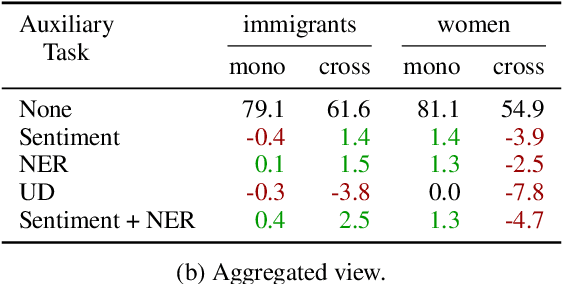
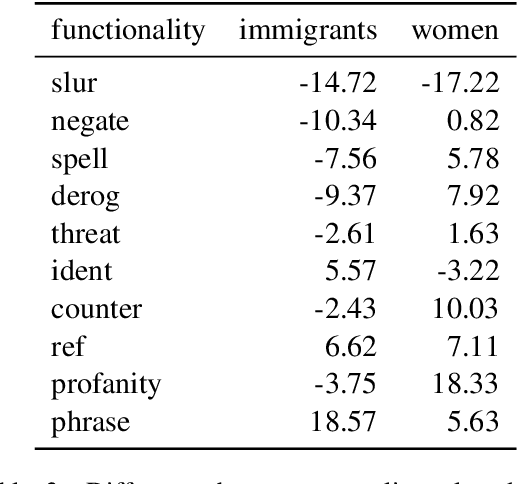
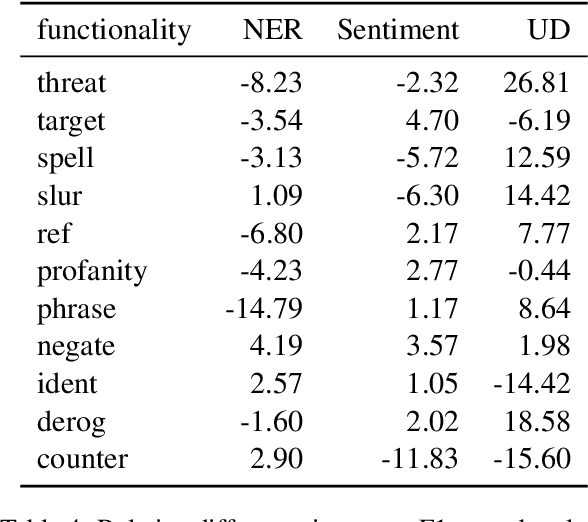
Zero-shot cross-lingual transfer learning has been shown to be highly challenging for tasks involving a lot of linguistic specificities or when a cultural gap is present between languages, such as in hate speech detection. In this paper, we highlight this limitation for hate speech detection in several domains and languages using strict experimental settings. Then, we propose to train on multilingual auxiliary tasks -- sentiment analysis, named entity recognition, and tasks relying on syntactic information -- to improve zero-shot transfer of hate speech detection models across languages. We show how hate speech detection models benefit from a cross-lingual knowledge proxy brought by auxiliary tasks fine-tuning and highlight these tasks' positive impact on bridging the hate speech linguistic and cultural gap between languages.