 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Efficient Speech Translation with Dynamic Latent Perceivers
Oct 28, 2022
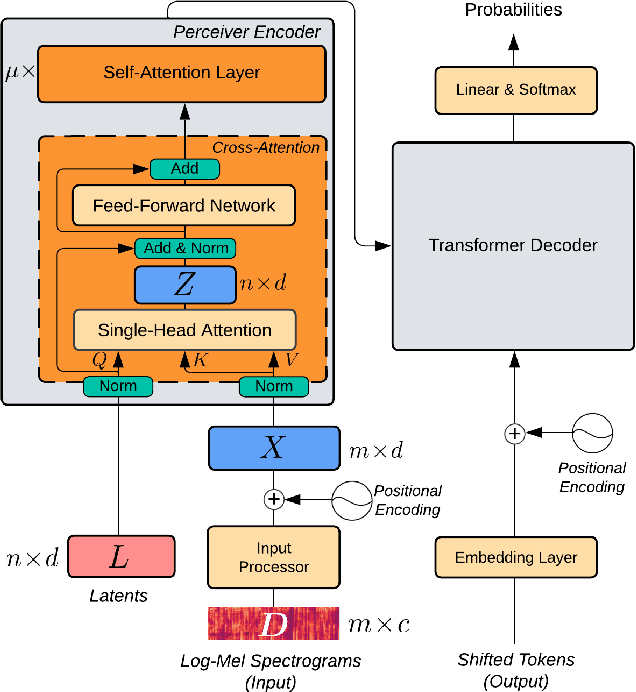
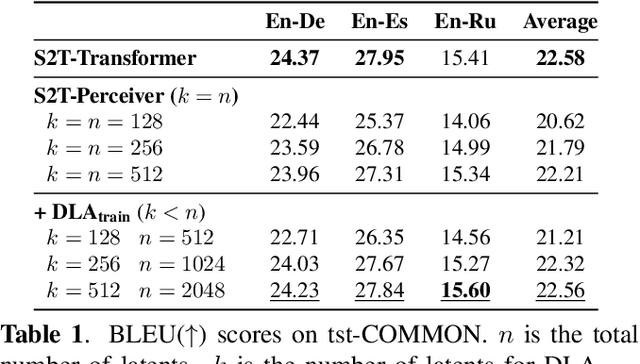
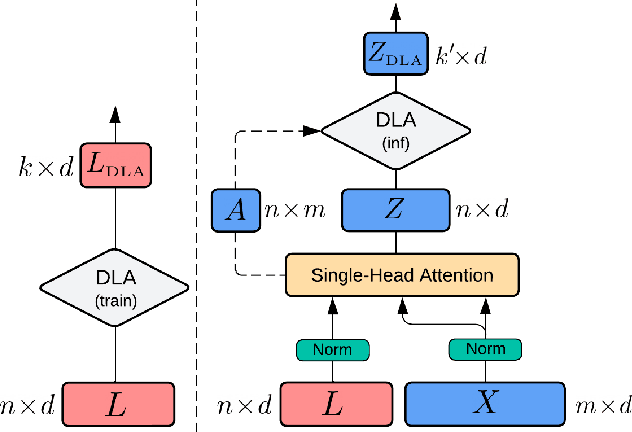
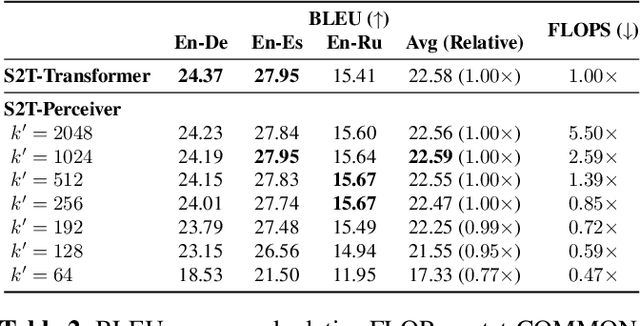
Transformers have been the dominant architecture for Speech Translation in recent years, achieving significant improvements in translation quality. Since speech signals are longer than their textual counterparts, and due to the quadratic complexity of the Transformer, a down-sampling step is essential for its adoption in Speech Translation. Instead, in this research, we propose to ease the complexity by using a Perceiver encoder to map the speech inputs to a fixed-length latent representation. Furthermore, we introduce a novel way of training Perceivers, with Dynamic Latent Access (DLA), unlocking larger latent spaces without any additional computational overhead. Speech-to-Text Perceivers with DLA can match the performance of a Transformer baseline across three language pairs in MuST-C. Finally, a DLA-trained model is easily adaptable to DLA at inference, and can be flexibly deployed with various computational budgets, without significant drops in translation quality.
End-to-End Automatic Speech Recognition model for the Sudanese Dialect
Dec 21, 2022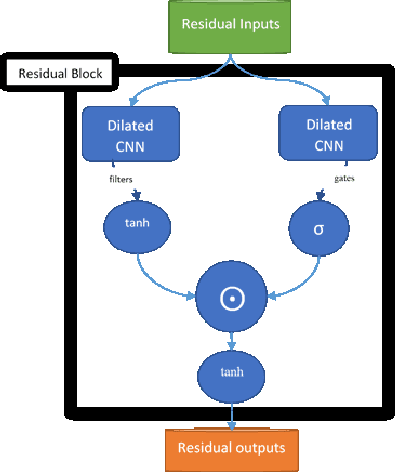

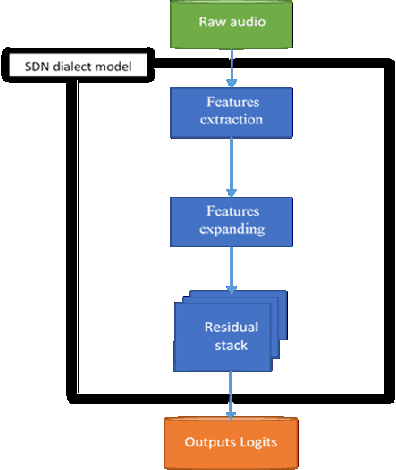

Designing a natural voice interface rely mostly on Speech recognition for interaction between human and their modern digital life equipment. In addition, speech recognition narrows the gap between monolingual individuals to better exchange communication. However, the field lacks wide support for several universal languages and their dialects, while most of the daily conversations are carried out using them. This paper comes to inspect the viability of designing an Automatic Speech Recognition model for the Sudanese dialect, which is one of the Arabic Language dialects, and its complexity is a product of historical and social conditions unique to its speakers. This condition is reflected in both the form and content of the dialect, so this paper gives an overview of the Sudanese dialect and the tasks of collecting represented resources and pre-processing performed to construct a modest dataset to overcome the lack of annotated data. Also proposed end- to-end speech recognition model, the design of the model was formed using Convolution Neural Networks. The Sudanese dialect dataset would be a stepping stone to enable future Natural Language Processing research targeting the dialect. The designed model provided some insights into the current recognition task and reached an average Label Error Rate of 73.67%.
AfroDigits: A Community-Driven Spoken Digit Dataset for African Languages
Apr 04, 2023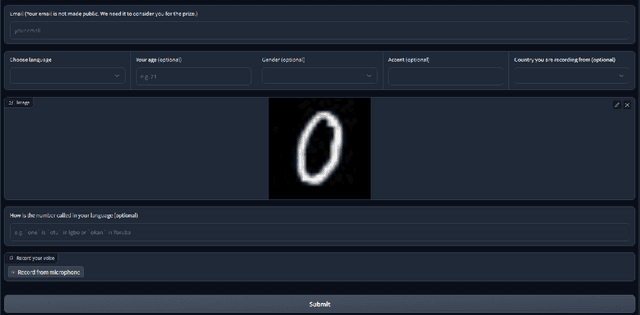
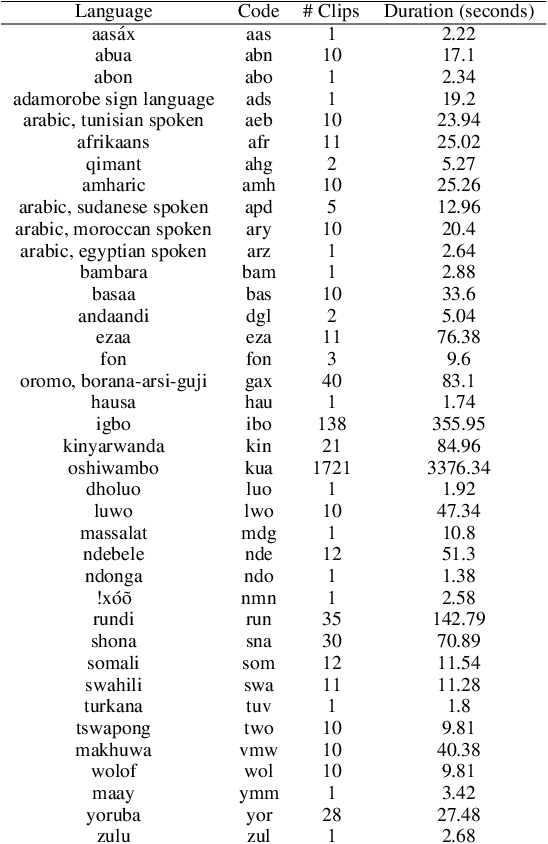
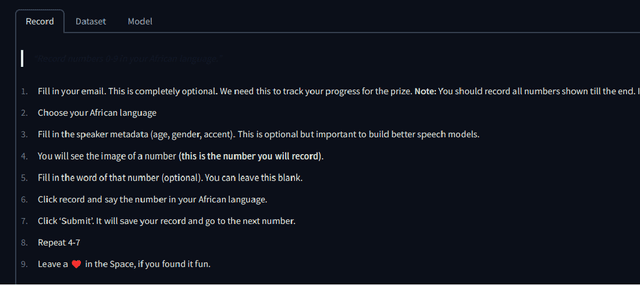
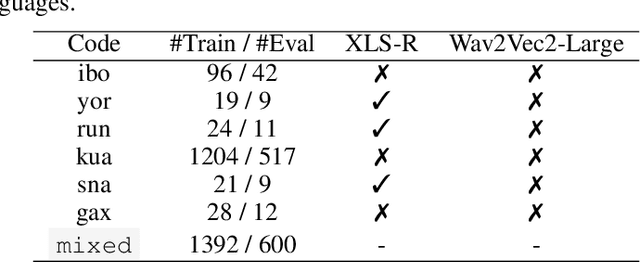
The advancement of speech technologies has been remarkable, yet its integration with African languages remains limited due to the scarcity of African speech corpora. To address this issue, we present AfroDigits, a minimalist, community-driven dataset of spoken digits for African languages, currently covering 38 African languages. As a demonstration of the practical applications of AfroDigits, we conduct audio digit classification experiments on six African languages [Igbo (ibo), Yoruba (yor), Rundi (run), Oshiwambo (kua), Shona (sna), and Oromo (gax)] using the Wav2Vec2.0-Large and XLS-R models. Our experiments reveal a useful insight on the effect of mixing African speech corpora during finetuning. AfroDigits is the first published audio digit dataset for African languages and we believe it will, among other things, pave the way for Afro-centric speech applications such as the recognition of telephone numbers, and street numbers. We release the dataset and platform publicly at https://huggingface.co/datasets/chrisjay/crowd-speech-africa and https://huggingface.co/spaces/chrisjay/afro-speech respectively.
Efficient Speech Quality Assessment using Self-supervised Framewise Embeddings
Nov 12, 2022
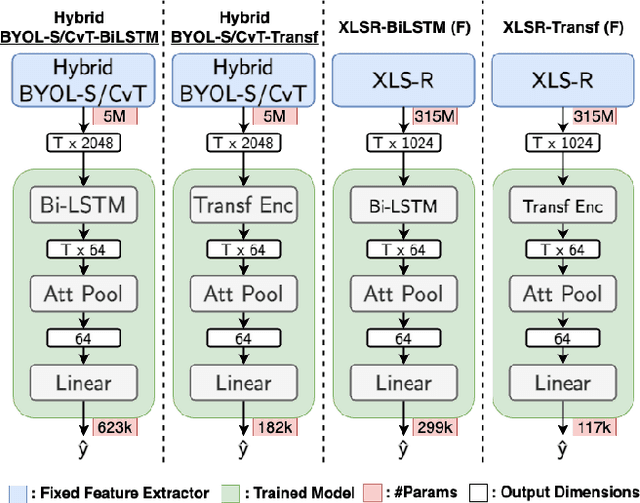
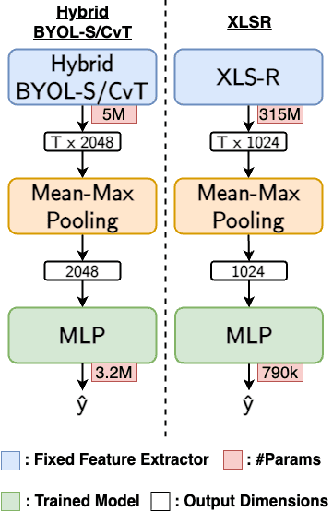
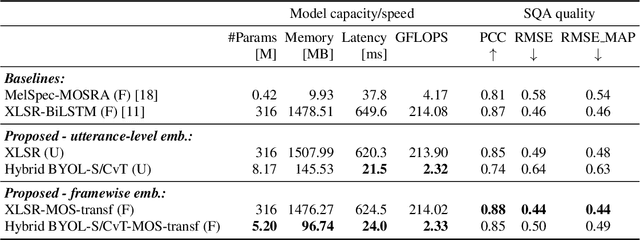
Automatic speech quality assessment is essential for audio researchers, developers, speech and language pathologists, and system quality engineers. The current state-of-the-art systems are based on framewise speech features (hand-engineered or learnable) combined with time dependency modeling. This paper proposes an efficient system with results comparable to the best performing model in the ConferencingSpeech 2022 challenge. Our proposed system is characterized by a smaller number of parameters (40-60x), fewer FLOPS (100x), lower memory consumption (10-15x), and lower latency (30x). Speech quality practitioners can therefore iterate much faster, deploy the system on resource-limited hardware, and, overall, the proposed system contributes to sustainable machine learning. The paper also concludes that framewise embeddings outperform utterance-level embeddings and that multi-task training with acoustic conditions modeling does not degrade speech quality prediction while providing better interpretation.
DDSupport: Language Learning Support System that Displays Differences and Distances from Model Speech
Dec 08, 2022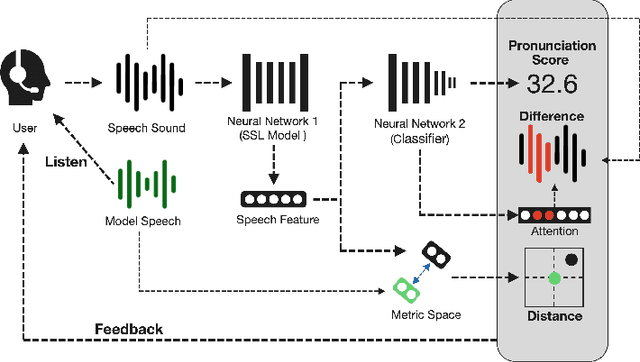
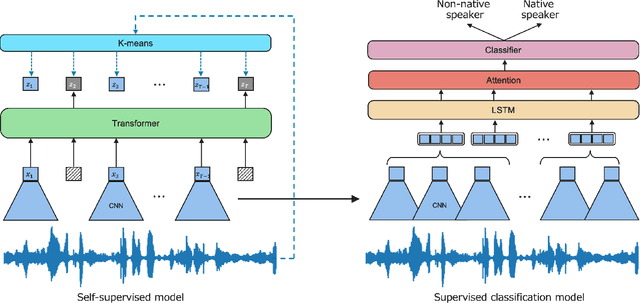
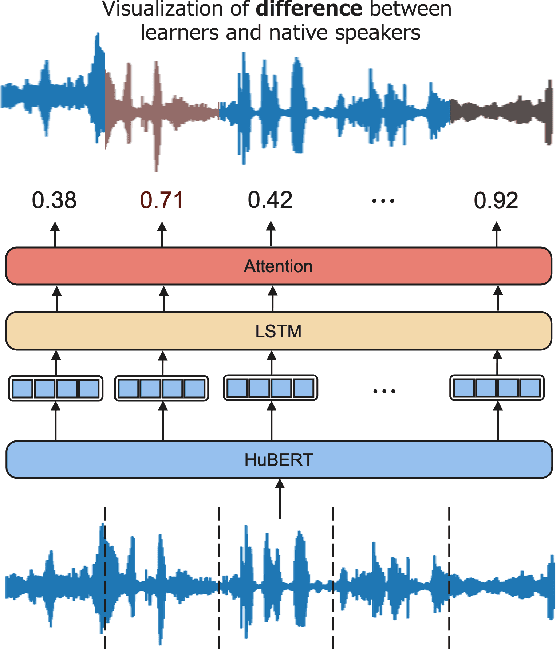
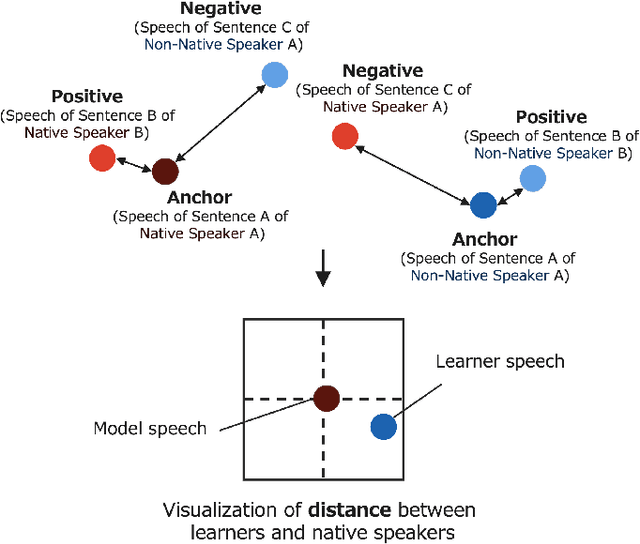
When beginners learn to speak a non-native language, it is difficult for them to judge for themselves whether they are speaking well. Therefore, computer-assisted pronunciation training systems are used to detect learner mispronunciations. These systems typically compare the user's speech with that of a specific native speaker as a model in units of rhythm, phonemes, or words and calculate the differences. However, they require extensive speech data with detailed annotations or can only compare with one specific native speaker. To overcome these problems, we propose a new language learning support system that calculates speech scores and detects mispronunciations by beginners based on a small amount of unannotated speech data without comparison to a specific person. The proposed system uses deep learning--based speech processing to display the pronunciation score of the learner's speech and the difference/distance between the learner's and a group of models' pronunciation in an intuitively visual manner. Learners can gradually improve their pronunciation by eliminating differences and shortening the distance from the model until they become sufficiently proficient. Furthermore, since the pronunciation score and difference/distance are not calculated compared to specific sentences of a particular model, users are free to study the sentences they wish to study. We also built an application to help non-native speakers learn English and confirmed that it can improve users' speech intelligibility.
Fine-tuning Strategies for Faster Inference using Speech Self-Supervised Models: A Comparative Study
Mar 12, 2023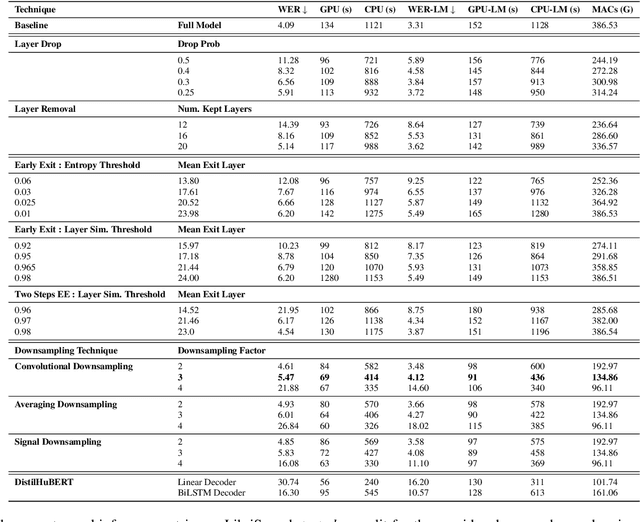
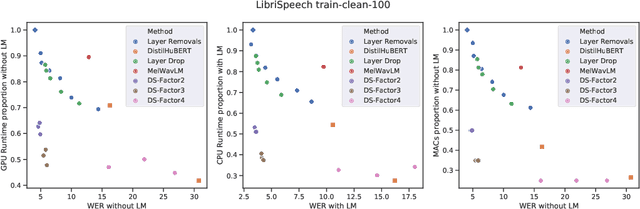
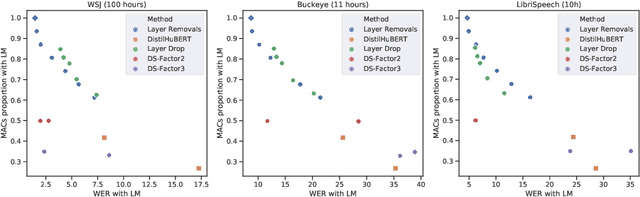
Self-supervised learning (SSL) has allowed substantial progress in Automatic Speech Recognition (ASR) performance in low-resource settings. In this context, it has been demonstrated that larger self-supervised feature extractors are crucial for achieving lower downstream ASR error rates. Thus, better performance might be sanctioned with longer inferences. This article explores different approaches that may be deployed during the fine-tuning to reduce the computations needed in the SSL encoder, leading to faster inferences. We adapt a number of existing techniques to common ASR settings and benchmark them, displaying performance drops and gains in inference times. Interestingly, we found that given enough downstream data, a simple downsampling of the input sequences outperforms the other methods with both low performance drops and high computational savings, reducing computations by 61.3% with an WER increase of only 0.81. Finally, we analyze the robustness of the comparison to changes in dataset conditions, revealing sensitivity to dataset size.
Meta-Gating Framework for Fast and Continuous Resource Optimization in Dynamic Wireless Environments
Jun 23, 2023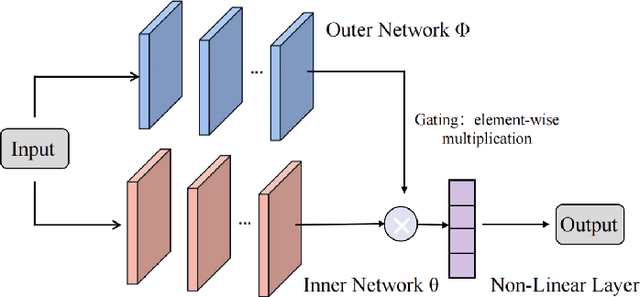
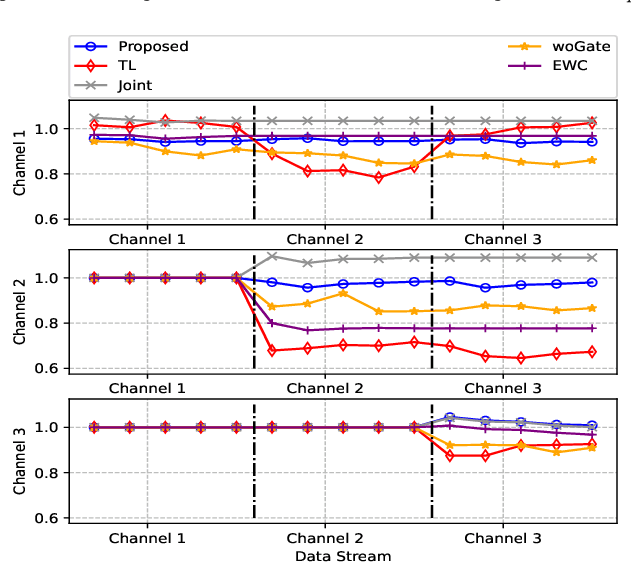
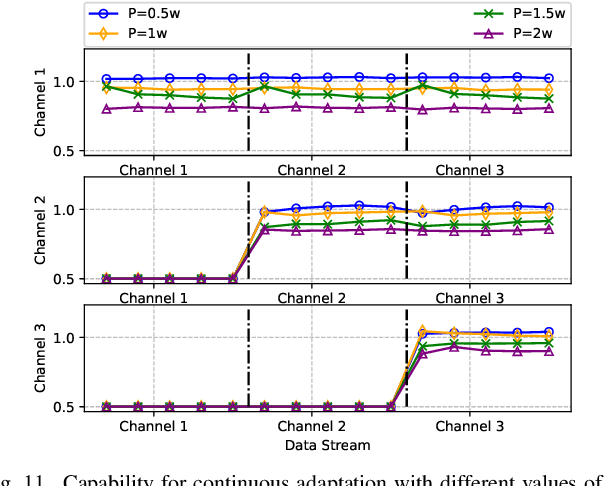
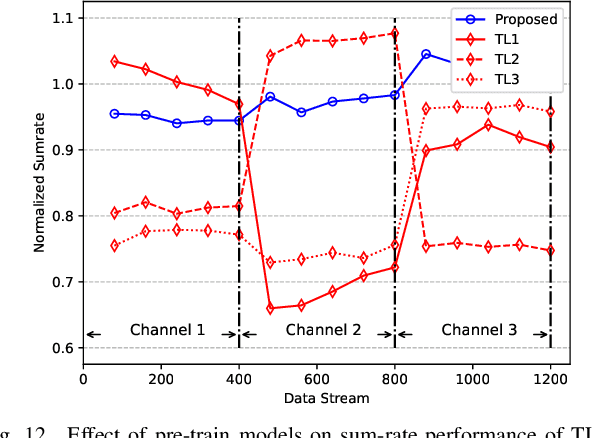
With the great success of deep learning (DL) in image classification, speech recognition, and other fields, more and more studies have applied various neural networks (NNs) to wireless resource allocation. Generally speaking, these artificial intelligent (AI) models are trained under some special learning hypotheses, especially that the statistics of the training data are static during the training stage. However, the distribution of channel state information (CSI) is constantly changing in the real-world wireless communication environment. Therefore, it is essential to study effective dynamic DL technologies to solve wireless resource allocation problems. In this paper, we propose a novel framework, named meta-gating, for solving resource allocation problems in an episodically dynamic wireless environment, where the CSI distribution changes over periods and remains constant within each period. The proposed framework, consisting of an inner network and an outer network, aims to adapt to the dynamic wireless environment by achieving three important goals, i.e., seamlessness, quickness and continuity. Specifically, for the former two goals, we propose a training method by combining a model-agnostic meta-learning (MAML) algorithm with an unsupervised learning mechanism. With this training method, the inner network is able to fast adapt to different channel distributions because of the good initialization. As for the goal of continuity, the outer network can learn to evaluate the importance of inner network's parameters under different CSI distributions, and then decide which subset of the inner network should be activated through the gating operation. Additionally, we theoretically analyze the performance of the proposed meta-gating framework.
Benchmarking Evaluation Metrics for Code-Switching Automatic Speech Recognition
Nov 22, 2022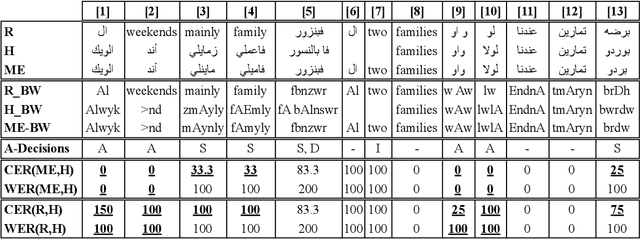

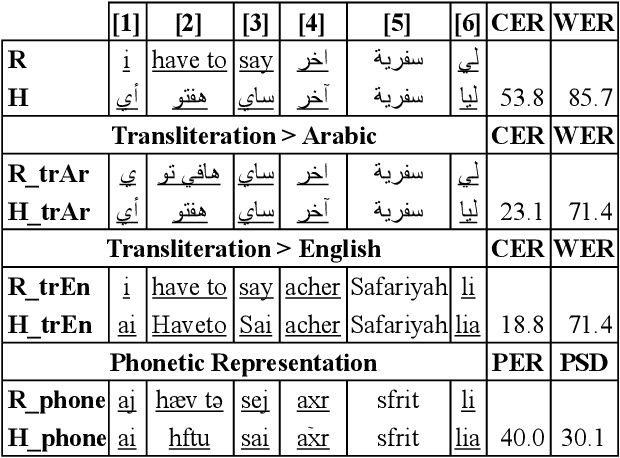

Code-switching poses a number of challenges and opportunities for multilingual automatic speech recognition. In this paper, we focus on the question of robust and fair evaluation metrics. To that end, we develop a reference benchmark data set of code-switching speech recognition hypotheses with human judgments. We define clear guidelines for minimal editing of automatic hypotheses. We validate the guidelines using 4-way inter-annotator agreement. We evaluate a large number of metrics in terms of correlation with human judgments. The metrics we consider vary in terms of representation (orthographic, phonological, semantic), directness (intrinsic vs extrinsic), granularity (e.g. word, character), and similarity computation method. The highest correlation to human judgment is achieved using transliteration followed by text normalization. We release the first corpus for human acceptance of code-switching speech recognition results in dialectal Arabic/English conversation speech.
Towards the Transferable Audio Adversarial Attack via Ensemble Methods
Apr 18, 2023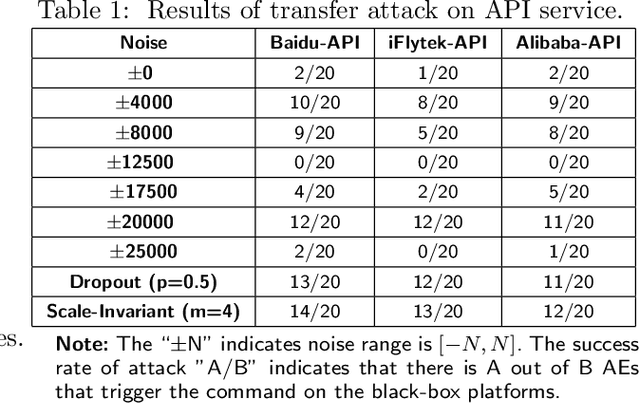
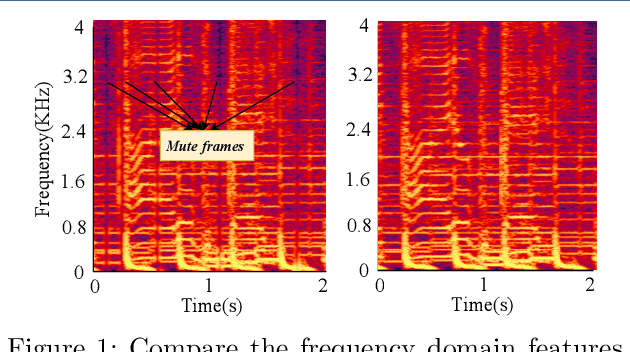
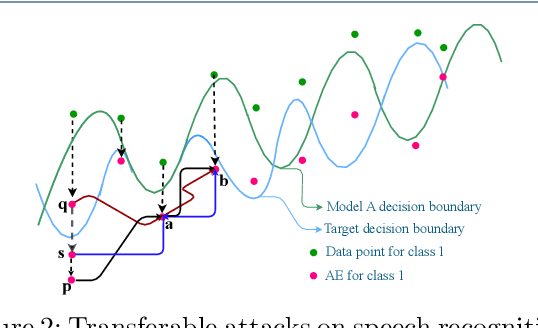
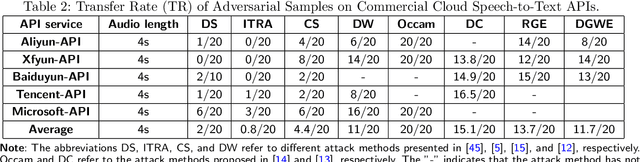
In recent years, deep learning (DL) models have achieved significant progress in many domains, such as autonomous driving, facial recognition, and speech recognition. However, the vulnerability of deep learning models to adversarial attacks has raised serious concerns in the community because of their insufficient robustness and generalization. Also, transferable attacks have become a prominent method for black-box attacks. In this work, we explore the potential factors that impact adversarial examples (AEs) transferability in DL-based speech recognition. We also discuss the vulnerability of different DL systems and the irregular nature of decision boundaries. Our results show a remarkable difference in the transferability of AEs between speech and images, with the data relevance being low in images but opposite in speech recognition. Motivated by dropout-based ensemble approaches, we propose random gradient ensembles and dynamic gradient-weighted ensembles, and we evaluate the impact of ensembles on the transferability of AEs. The results show that the AEs created by both approaches are valid for transfer to the black box API.
Exploring the Role of Audio in Video Captioning
Jun 21, 2023
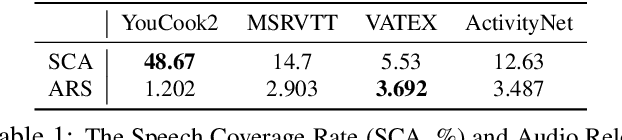


Recent focus in video captioning has been on designing architectures that can consume both video and text modalities, and using large-scale video datasets with text transcripts for pre-training, such as HowTo100M. Though these approaches have achieved significant improvement, the audio modality is often ignored in video captioning. In this work, we present an audio-visual framework, which aims to fully exploit the potential of the audio modality for captioning. Instead of relying on text transcripts extracted via automatic speech recognition (ASR), we argue that learning with raw audio signals can be more beneficial, as audio has additional information including acoustic events, speaker identity, etc. Our contributions are twofold. First, we observed that the model overspecializes to the audio modality when pre-training with both video and audio modality, since the ground truth (i.e., text transcripts) can be solely predicted using audio. We proposed a Modality Balanced Pre-training (MBP) loss to mitigate this issue and significantly improve the performance on downstream tasks. Second, we slice and dice different design choices of the cross-modal module, which may become an information bottleneck and generate inferior results. We proposed new local-global fusion mechanisms to improve information exchange across audio and video. We demonstrate significant improvements by leveraging the audio modality on four datasets, and even outperform the state of the art on some metrics without relying on the text modality as the input.