 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Adaptive Knowledge Distillation between Text and Speech Pre-trained Models
Mar 07, 2023
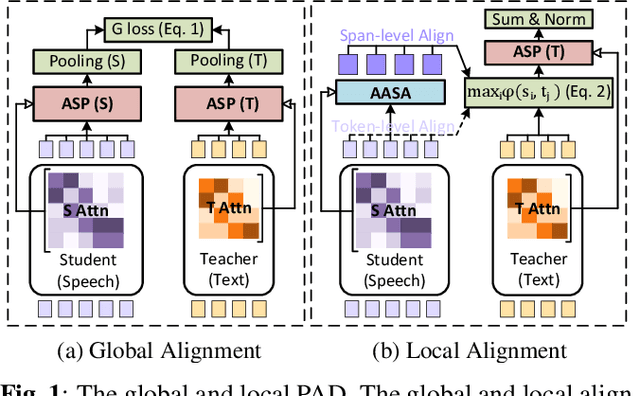
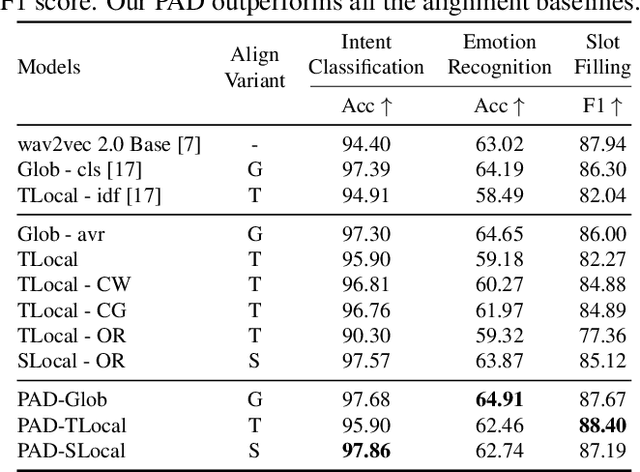
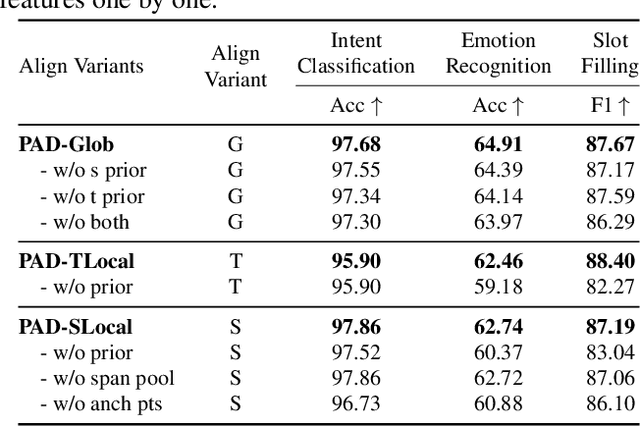
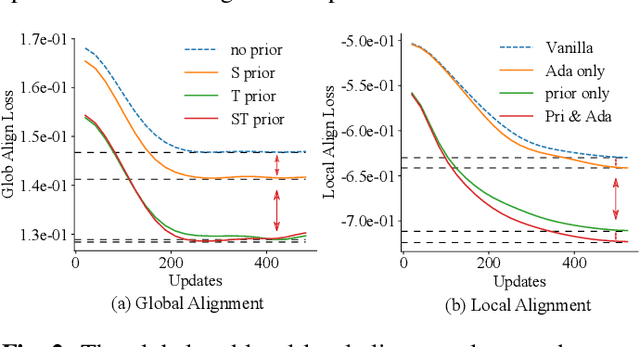
Learning on a massive amount of speech corpus leads to the recent success of many self-supervised speech models. With knowledge distillation, these models may also benefit from the knowledge encoded by language models that are pre-trained on rich sources of texts. The distillation process, however, is challenging due to the modal disparity between textual and speech embedding spaces. This paper studies metric-based distillation to align the embedding space of text and speech with only a small amount of data without modifying the model structure. Since the semantic and granularity gap between text and speech has been omitted in literature, which impairs the distillation, we propose the Prior-informed Adaptive knowledge Distillation (PAD) that adaptively leverages text/speech units of variable granularity and prior distributions to achieve better global and local alignments between text and speech pre-trained models. We evaluate on three spoken language understanding benchmarks to show that PAD is more effective in transferring linguistic knowledge than other metric-based distillation approaches.
Flexible Keyword Spotting based on Homogeneous Audio-Text Embedding
Aug 12, 2023
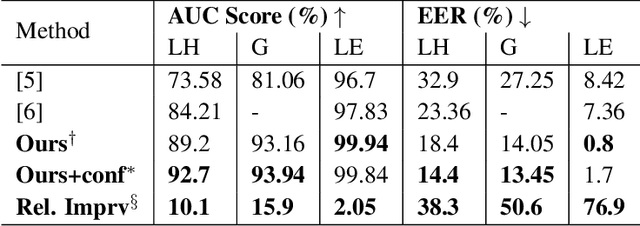
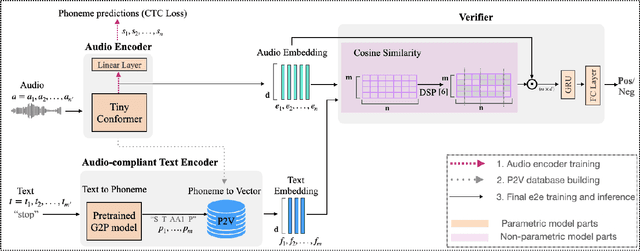

Spotting user-defined/flexible keywords represented in text frequently uses an expensive text encoder for joint analysis with an audio encoder in an embedding space, which can suffer from heterogeneous modality representation (i.e., large mismatch) and increased complexity. In this work, we propose a novel architecture to efficiently detect arbitrary keywords based on an audio-compliant text encoder which inherently has homogeneous representation with audio embedding, and it is also much smaller than a compatible text encoder. Our text encoder converts the text to phonemes using a grapheme-to-phoneme (G2P) model, and then to an embedding using representative phoneme vectors, extracted from the paired audio encoder on rich speech datasets. We further augment our method with confusable keyword generation to develop an audio-text embedding verifier with strong discriminative power. Experimental results show that our scheme outperforms the state-of-the-art results on Libriphrase hard dataset, increasing Area Under the ROC Curve (AUC) metric from 84.21% to 92.7% and reducing Equal-Error-Rate (EER) metric from 23.36% to 14.4%.
Text-to-Video: a Two-stage Framework for Zero-shot Identity-agnostic Talking-head Generation
Aug 12, 2023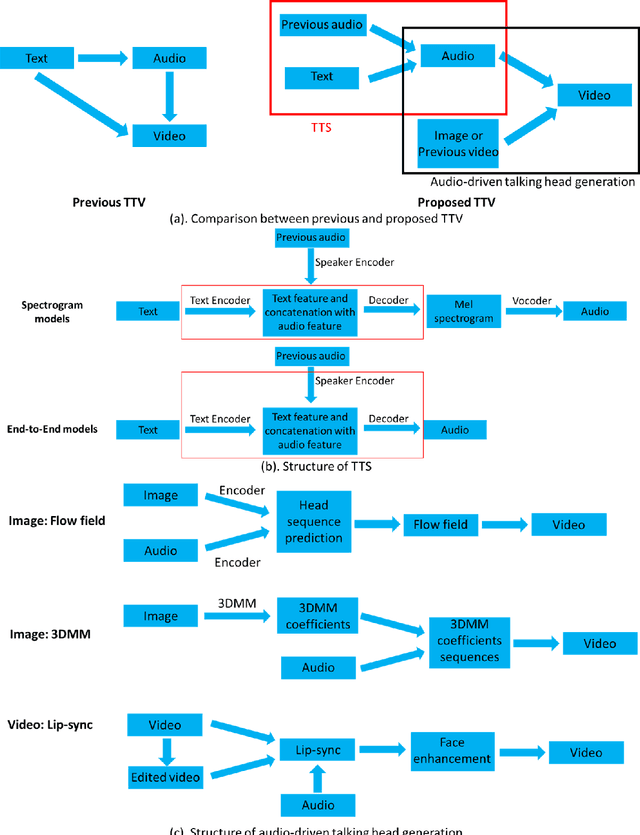

The advent of ChatGPT has introduced innovative methods for information gathering and analysis. However, the information provided by ChatGPT is limited to text, and the visualization of this information remains constrained. Previous research has explored zero-shot text-to-video (TTV) approaches to transform text into videos. However, these methods lacked control over the identity of the generated audio, i.e., not identity-agnostic, hindering their effectiveness. To address this limitation, we propose a novel two-stage framework for person-agnostic video cloning, specifically focusing on TTV generation. In the first stage, we leverage pretrained zero-shot models to achieve text-to-speech (TTS) conversion. In the second stage, an audio-driven talking head generation method is employed to produce compelling videos privided the audio generated in the first stage. This paper presents a comparative analysis of different TTS and audio-driven talking head generation methods, identifying the most promising approach for future research and development. Some audio and videos samples can be found in the following link: https://github.com/ZhichaoWang970201/Text-to-Video/tree/main.
On Data Sampling Strategies for Training Neural Network Speech Separation Models
Apr 14, 2023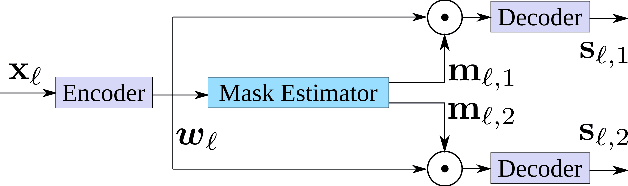
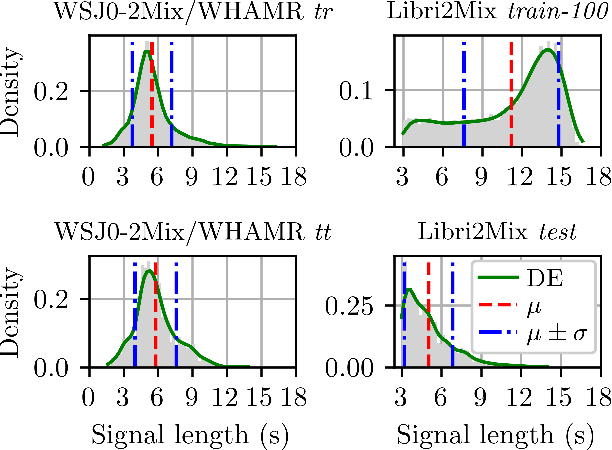
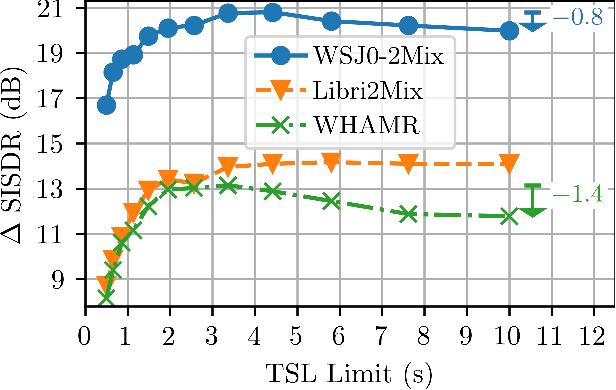
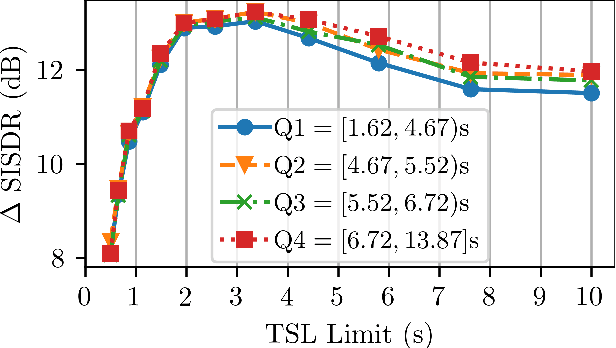
Speech separation remains an important area of multi-speaker signal processing. Deep neural network (DNN) models have attained the best performance on many speech separation benchmarks. Some of these models can take significant time to train and have high memory requirements. Previous work has proposed shortening training examples to address these issues but the impact of this on model performance is not yet well understood. In this work, the impact of applying these training signal length (TSL) limits is analysed for two speech separation models: SepFormer, a transformer model, and Conv-TasNet, a convolutional model. The WJS0-2Mix, WHAMR and Libri2Mix datasets are analysed in terms of signal length distribution and its impact on training efficiency. It is demonstrated that, for specific distributions, applying specific TSL limits results in better performance. This is shown to be mainly due to randomly sampling the start index of the waveforms resulting in more unique examples for training. A SepFormer model trained using a TSL limit of 4.42s and dynamic mixing (DM) is shown to match the best-performing SepFormer model trained with DM and unlimited signal lengths. Furthermore, the 4.42s TSL limit results in a 44% reduction in training time with WHAMR.
Multi-task learning of speech and speaker recognition
Feb 24, 2023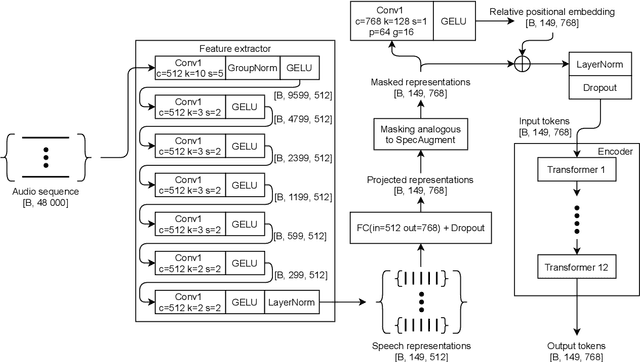
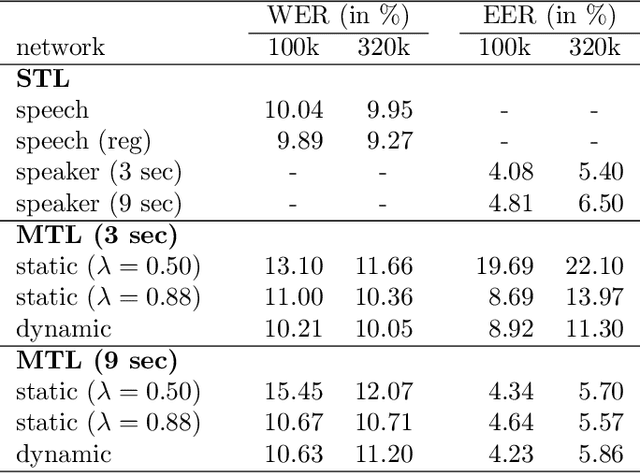
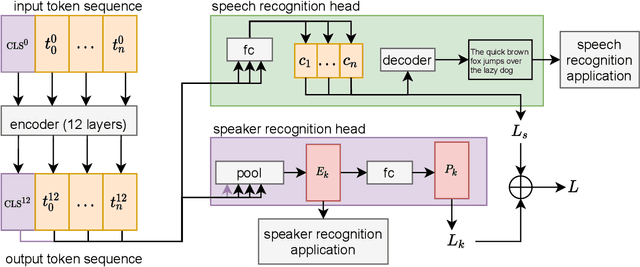
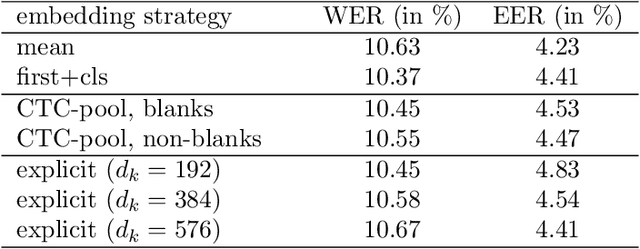
We study multi-task learning for two orthogonal speech technology tasks: speech and speaker recognition. We use wav2vec2 as a base architecture with two task-specific output heads. We experiment with different methods to mix speaker and speech information in the output embedding sequence, and propose a simple dynamic approach to balance the speech and speaker recognition loss functions. Our multi-task learning networks can produce a shared speaker and speech embedding, which are evaluated on the LibriSpeech and VoxCeleb test sets, and achieve a performance comparable to separate single-task models. Code is available at https://github.com/nikvaessen/2022-repo-mt-w2v2.
Dialogue Systems Can Generate Appropriate Responses without the Use of Question Marks? -- Investigation of the Effects of Question Marks on Dialogue Systems
Aug 07, 2023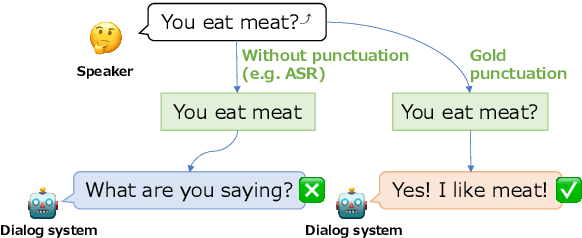



When individuals engage in spoken discourse, various phenomena can be observed that differ from those that are apparent in text-based conversation. While written communication commonly uses a question mark to denote a query, in spoken discourse, queries are frequently indicated by a rising intonation at the end of a sentence. However, numerous speech recognition engines do not append a question mark to recognized queries, presenting a challenge when creating a spoken dialogue system. Specifically, the absence of a question mark at the end of a sentence can impede the generation of appropriate responses to queries in spoken dialogue systems. Hence, we investigate the impact of question marks on dialogue systems, with the results showing that they have a significant impact. Moreover, we analyze specific examples in an effort to determine which types of utterances have the impact on dialogue systems.
Towards Real-Time Single-Channel Speech Separation in Noisy and Reverberant Environments
Mar 14, 2023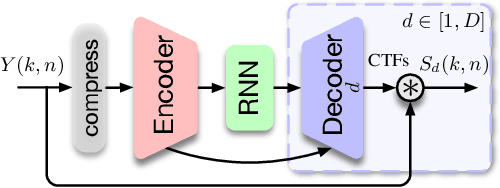
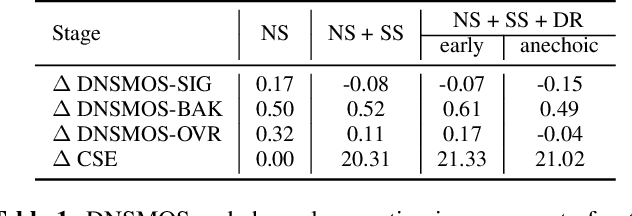
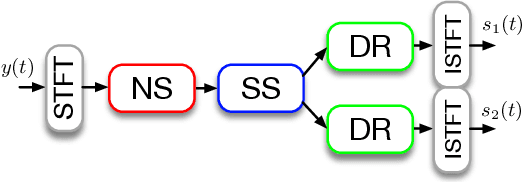
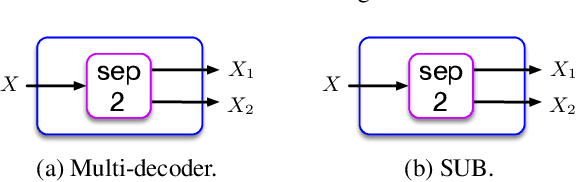
Real-time single-channel speech separation aims to unmix an audio stream captured from a single microphone that contains multiple people talking at once, environmental noise, and reverberation into multiple de-reverberated and noise-free speech tracks, each track containing only one talker. While large state-of-the-art DNNs can achieve excellent separation from anechoic mixtures of speech, the main challenge is to create compact and causal models that can separate reverberant mixtures at inference time. In this paper, we explore low-complexity, resource-efficient, causal DNN architectures for real-time separation of two or more simultaneous speakers. A cascade of three neural network modules are trained to sequentially perform noise-suppression, separation, and de-reverberation. For comparison, a larger end-to-end model is trained to output two anechoic speech signals directly from noisy reverberant speech mixtures. We propose an efficient single-decoder architecture with subtractive separation for real-time recursive speech separation for two or more speakers. Evaluation on real monophonic recordings of speech mixtures, according to speech separation measures like SI-SDR, perceptual measures like DNS-MOS, and a novel proposed channel separation metric, show that these compact causal models can separate speech mixtures with low latency, and perform on par with large offline state-of-the-art models like SepFormer.
SpeechFormer++: A Hierarchical Efficient Framework for Paralinguistic Speech Processing
Feb 27, 2023
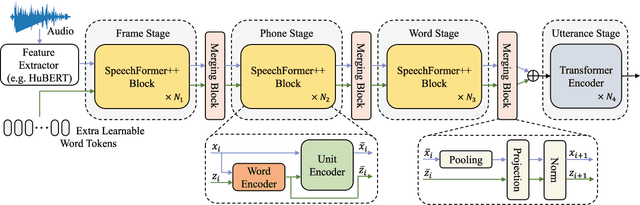
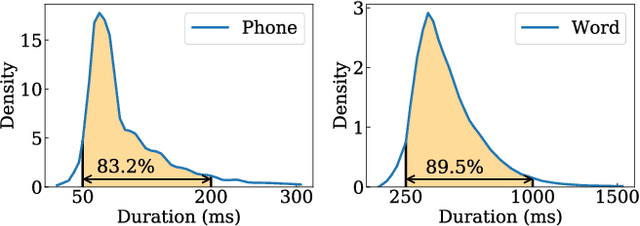
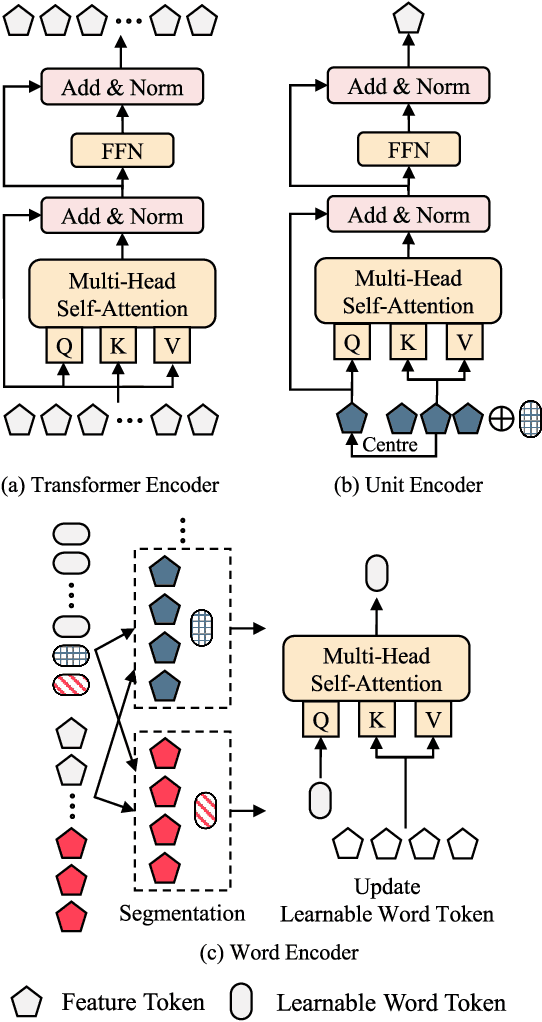
Paralinguistic speech processing is important in addressing many issues, such as sentiment and neurocognitive disorder analyses. Recently, Transformer has achieved remarkable success in the natural language processing field and has demonstrated its adaptation to speech. However, previous works on Transformer in the speech field have not incorporated the properties of speech, leaving the full potential of Transformer unexplored. In this paper, we consider the characteristics of speech and propose a general structure-based framework, called SpeechFormer++, for paralinguistic speech processing. More concretely, following the component relationship in the speech signal, we design a unit encoder to model the intra- and inter-unit information (i.e., frames, phones, and words) efficiently. According to the hierarchical relationship, we utilize merging blocks to generate features at different granularities, which is consistent with the structural pattern in the speech signal. Moreover, a word encoder is introduced to integrate word-grained features into each unit encoder, which effectively balances fine-grained and coarse-grained information. SpeechFormer++ is evaluated on the speech emotion recognition (IEMOCAP & MELD), depression classification (DAIC-WOZ) and Alzheimer's disease detection (Pitt) tasks. The results show that SpeechFormer++ outperforms the standard Transformer while greatly reducing the computational cost. Furthermore, it delivers superior results compared to the state-of-the-art approaches.
Source-Filter-Based Generative Adversarial Neural Vocoder for High Fidelity Speech Synthesis
Apr 26, 2023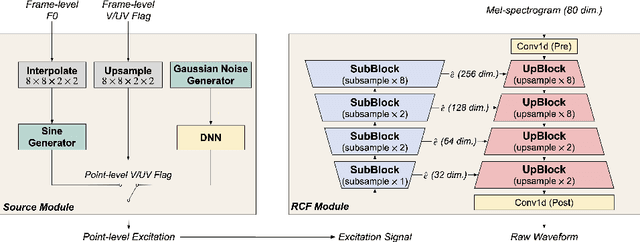
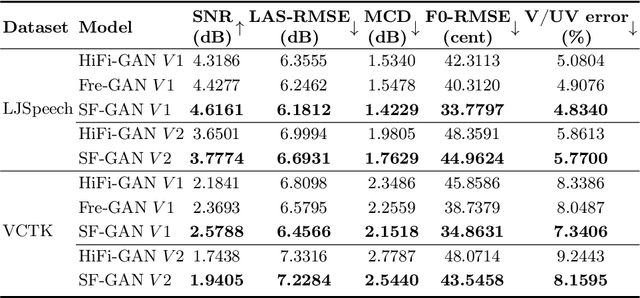
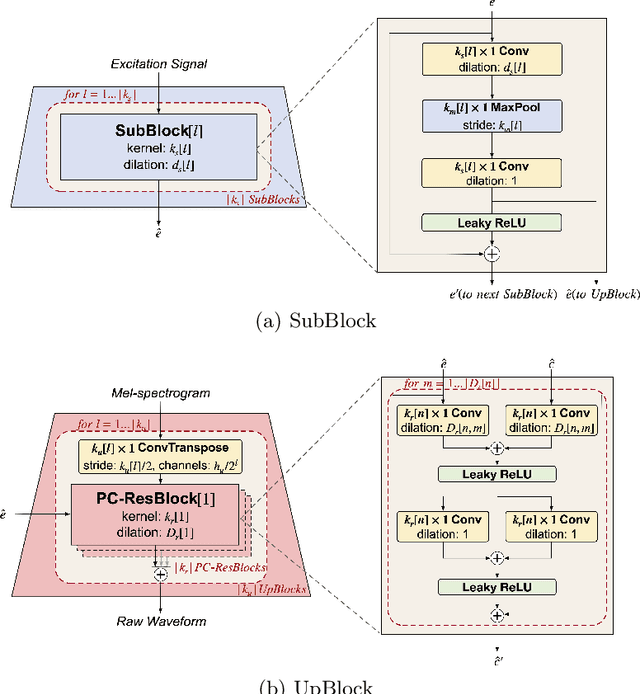
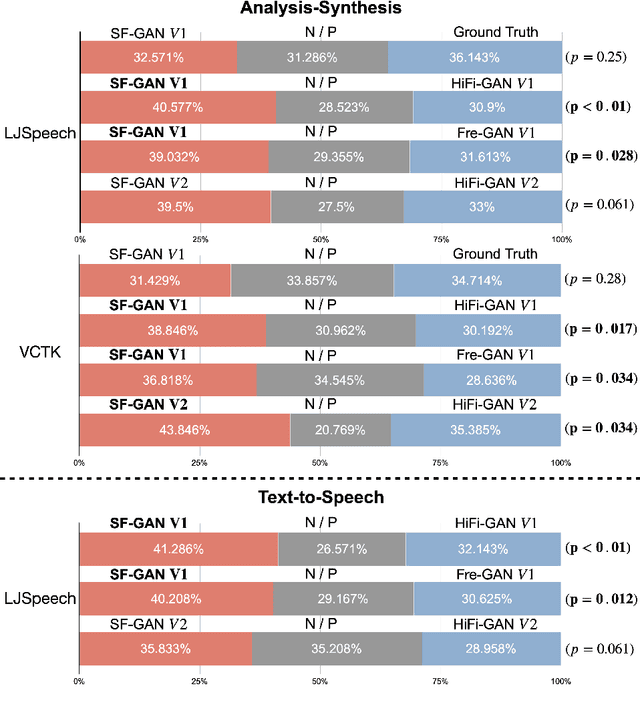
This paper proposes a source-filter-based generative adversarial neural vocoder named SF-GAN, which achieves high-fidelity waveform generation from input acoustic features by introducing F0-based source excitation signals to a neural filter framework. The SF-GAN vocoder is composed of a source module and a resolution-wise conditional filter module and is trained based on generative adversarial strategies. The source module produces an excitation signal from the F0 information, then the resolution-wise convolutional filter module combines the excitation signal with processed acoustic features at various temporal resolutions and finally reconstructs the raw waveform. The experimental results show that our proposed SF-GAN vocoder outperforms the state-of-the-art HiFi-GAN and Fre-GAN in both analysis-synthesis (AS) and text-to-speech (TTS) tasks, and the synthesized speech quality of SF-GAN is comparable to the ground-truth audio.
Learning Landmarks Motion from Speech for Speaker-Agnostic 3D Talking Heads Generation
Jun 02, 2023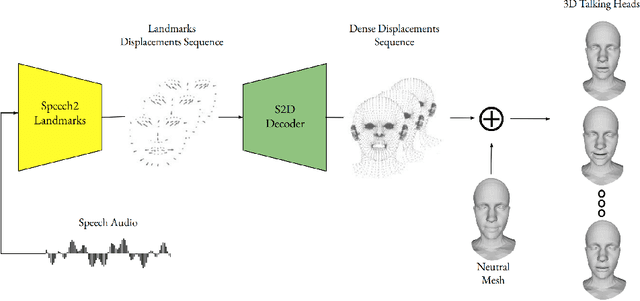



This paper presents a novel approach for generating 3D talking heads from raw audio inputs. Our method grounds on the idea that speech related movements can be comprehensively and efficiently described by the motion of a few control points located on the movable parts of the face, i.e., landmarks. The underlying musculoskeletal structure then allows us to learn how their motion influences the geometrical deformations of the whole face. The proposed method employs two distinct models to this aim: the first one learns to generate the motion of a sparse set of landmarks from the given audio. The second model expands such landmarks motion to a dense motion field, which is utilized to animate a given 3D mesh in neutral state. Additionally, we introduce a novel loss function, named Cosine Loss, which minimizes the angle between the generated motion vectors and the ground truth ones. Using landmarks in 3D talking head generation offers various advantages such as consistency, reliability, and obviating the need for manual-annotation. Our approach is designed to be identity-agnostic, enabling high-quality facial animations for any users without additional data or training.