 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
LRWR: Large-Scale Benchmark for Lip Reading in Russian language
Sep 14, 2021
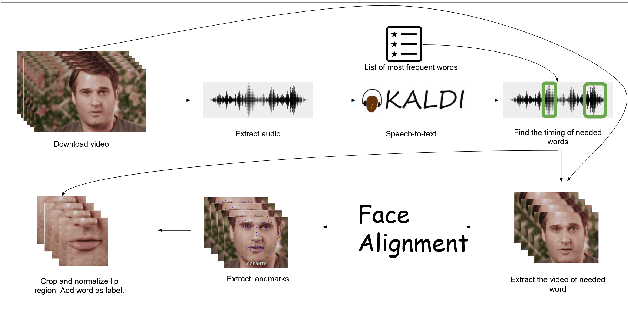

Lipreading, also known as visual speech recognition, aims to identify the speech content from videos by analyzing the visual deformations of lips and nearby areas. One of the significant obstacles for research in this field is the lack of proper datasets for a wide variety of languages: so far, these methods have been focused only on English or Chinese. In this paper, we introduce a naturally distributed large-scale benchmark for lipreading in Russian language, named LRWR, which contains 235 classes and 135 speakers. We provide a detailed description of the dataset collection pipeline and dataset statistics. We also present a comprehensive comparison of the current popular lipreading methods on LRWR and conduct a detailed analysis of their performance. The results demonstrate the differences between the benchmarked languages and provide several promising directions for lipreading models finetuning. Thanks to our findings, we also achieved new state-of-the-art results on the LRW benchmark.
The DIRHA-English corpus and related tasks for distant-speech recognition in domestic environments
Oct 06, 2017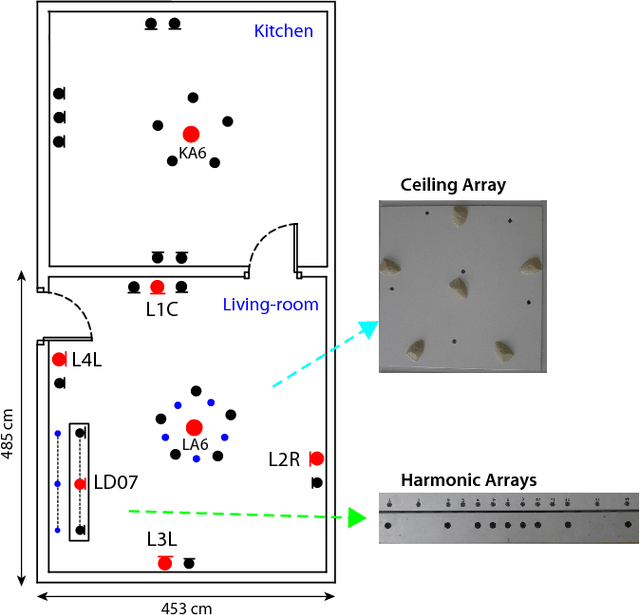
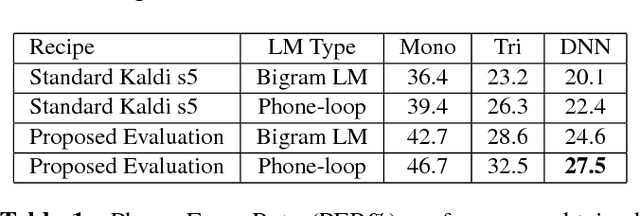
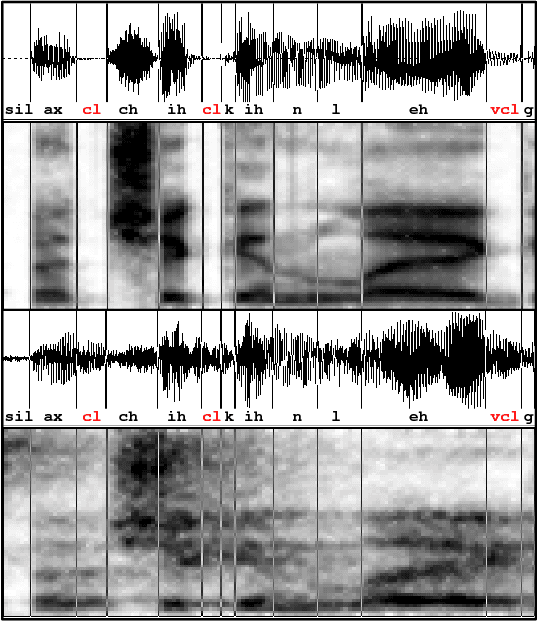
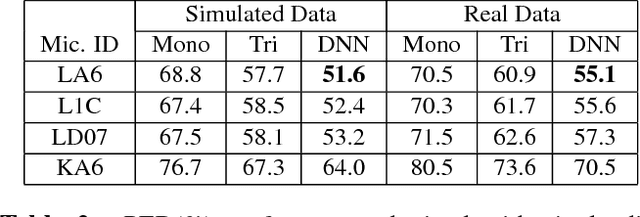
This paper introduces the contents and the possible usage of the DIRHA-ENGLISH multi-microphone corpus, recently realized under the EC DIRHA project. The reference scenario is a domestic environment equipped with a large number of microphones and microphone arrays distributed in space. The corpus is composed of both real and simulated material, and it includes 12 US and 12 UK English native speakers. Each speaker uttered different sets of phonetically-rich sentences, newspaper articles, conversational speech, keywords, and commands. From this material, a large set of 1-minute sequences was generated, which also includes typical domestic background noise as well as inter/intra-room reverberation effects. Dev and test sets were derived, which represent a very precious material for different studies on multi-microphone speech processing and distant-speech recognition. Various tasks and corresponding Kaldi recipes have already been developed. The paper reports a first set of baseline results obtained using different techniques, including Deep Neural Networks (DNN), aligned with the state-of-the-art at international level.
An Improved Single Step Non-autoregressive Transformer for Automatic Speech Recognition
Jul 22, 2021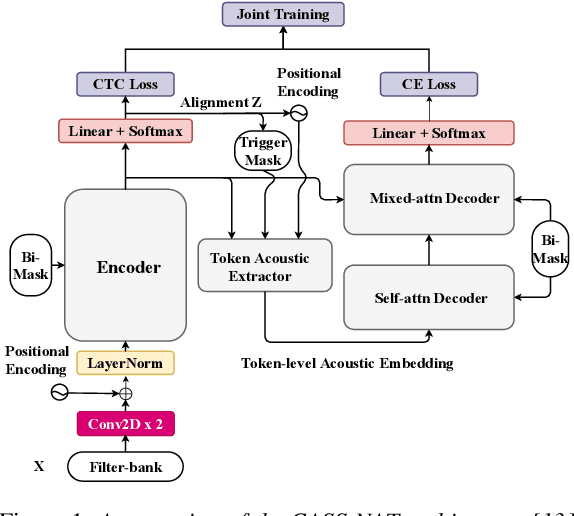
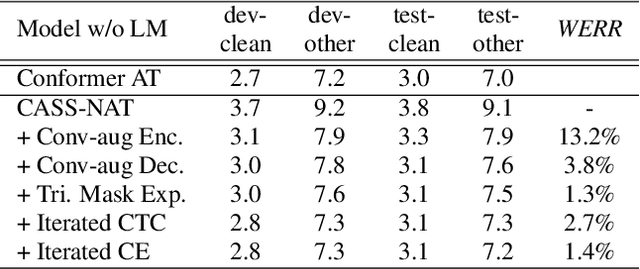
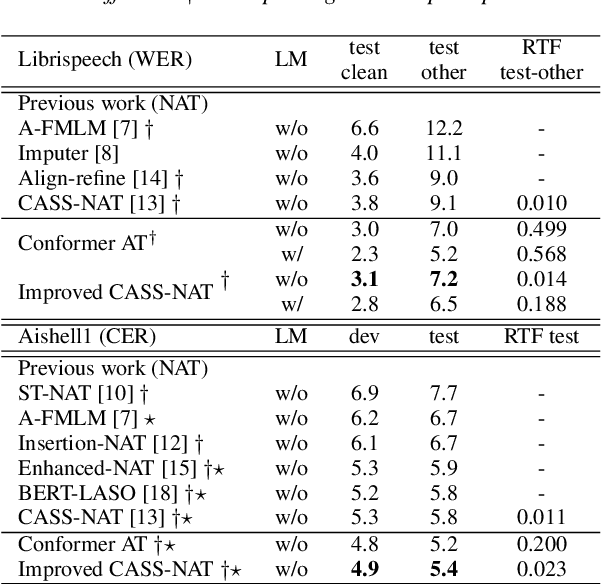
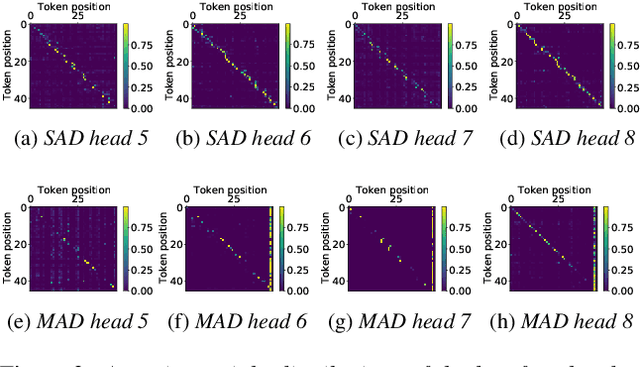
Non-autoregressive mechanisms can significantly decrease inference time for speech transformers, especially when the single step variant is applied. Previous work on CTC alignment-based single step non-autoregressive transformer (CASS-NAT) has shown a large real time factor (RTF) improvement over autoregressive transformers (AT). In this work, we propose several methods to improve the accuracy of the end-to-end CASS-NAT, followed by performance analyses. First, convolution augmented self-attention blocks are applied to both the encoder and decoder modules. Second, we propose to expand the trigger mask (acoustic boundary) for each token to increase the robustness of CTC alignments. In addition, iterated loss functions are used to enhance the gradient update of low-layer parameters. Without using an external language model, the WERs of the improved CASS-NAT, when using the three methods, are 3.1%/7.2% on Librispeech test clean/other sets and the CER is 5.4% on the Aishell1 test set, achieving a 7%~21% relative WER/CER improvement. For the analyses, we plot attention weight distributions in the decoders to visualize the relationships between token-level acoustic embeddings. When the acoustic embeddings are visualized, we find that they have a similar behavior to word embeddings, which explains why the improved CASS-NAT performs similarly to AT.
Beyond $L_p$ clipping: Equalization-based Psychoacoustic Attacks against ASRs
Oct 25, 2021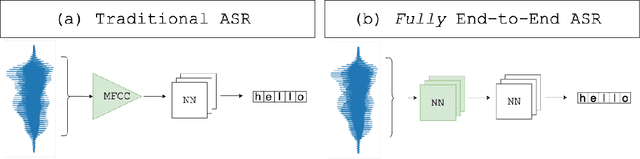

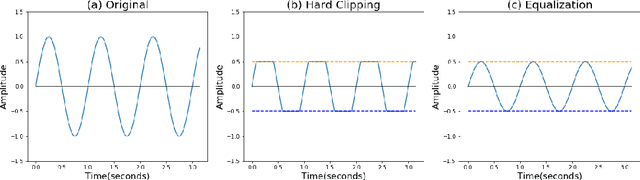
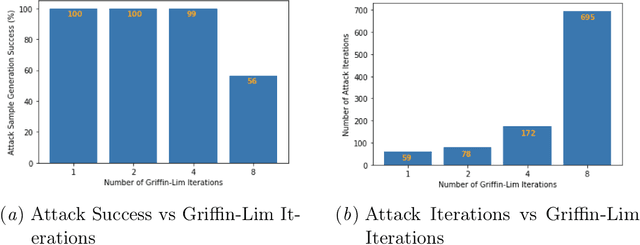
Automatic Speech Recognition (ASR) systems convert speech into text and can be placed into two broad categories: traditional and fully end-to-end. Both types have been shown to be vulnerable to adversarial audio examples that sound benign to the human ear but force the ASR to produce malicious transcriptions. Of these attacks, only the "psychoacoustic" attacks can create examples with relatively imperceptible perturbations, as they leverage the knowledge of the human auditory system. Unfortunately, existing psychoacoustic attacks can only be applied against traditional models, and are obsolete against the newer, fully end-to-end ASRs. In this paper, we propose an equalization-based psychoacoustic attack that can exploit both traditional and fully end-to-end ASRs. We successfully demonstrate our attack against real-world ASRs that include DeepSpeech and Wav2Letter. Moreover, we employ a user study to verify that our method creates low audible distortion. Specifically, 80 of the 100 participants voted in favor of all our attack audio samples as less noisier than the existing state-of-the-art attack. Through this, we demonstrate both types of existing ASR pipelines can be exploited with minimum degradation to attack audio quality.
Speech Technology for Everyone: Automatic Speech Recognition for Non-Native English with Transfer Learning
Oct 15, 2021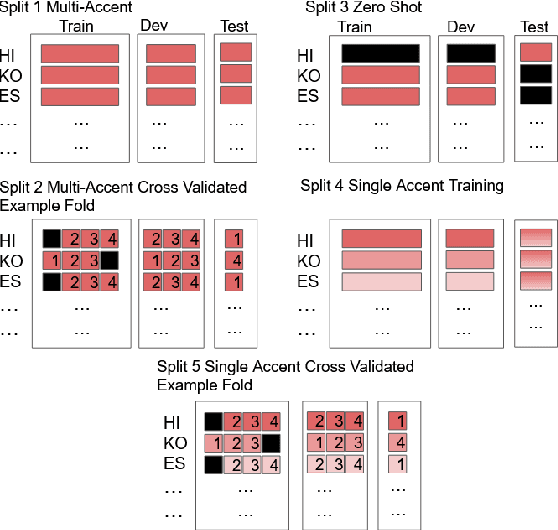


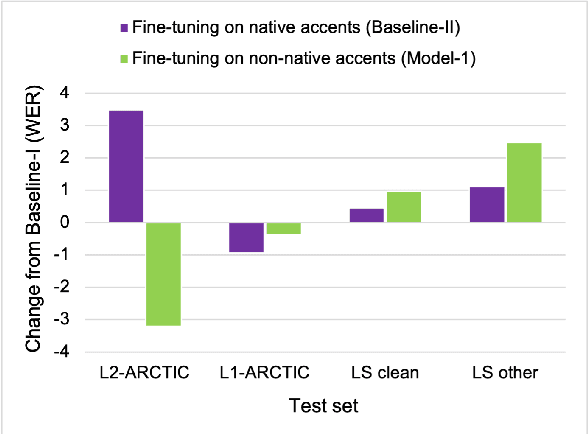
To address the performance gap of English ASR models on L2 English speakers, we evaluate fine-tuning of pretrained wav2vec 2.0 models (Baevski et al., 2020; Xu et al., 2021) on L2-ARCTIC, a non-native English speech corpus (Zhao et al., 2018) under different training settings. We compare \textbf{(a)} models trained with a combination of diverse accents to ones trained with only specific accents and \textbf{(b)} results from different single-accent models. Our experiments demonstrate the promise of developing ASR models for non-native English speakers, even with small amounts of L2 training data and even without a language model. Our models also excel in the zero-shot setting where we train on multiple L2 datasets and test on a blind L2 test set.
Complementing Handcrafted Features with Raw Waveform Using a Light-weight Auxiliary Model
Sep 06, 2021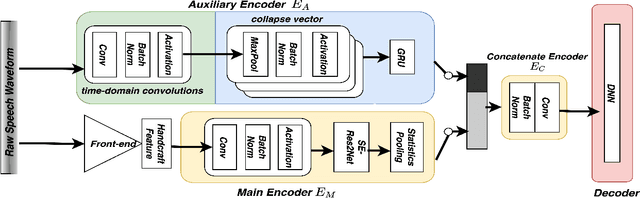
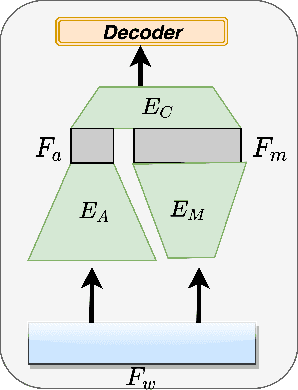

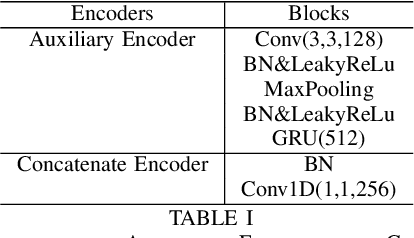
An emerging trend in audio processing is capturing low-level speech representations from raw waveforms. These representations have shown promising results on a variety of tasks, such as speech recognition and speech separation. Compared to handcrafted features, learning speech features via backpropagation provides the model greater flexibility in how it represents data for different tasks theoretically. However, results from empirical study shows that, in some tasks, such as voice spoof detection, handcrafted features are more competitive than learned features. Instead of evaluating handcrafted features and raw waveforms independently, this paper proposes an Auxiliary Rawnet model to complement handcrafted features with features learned from raw waveforms. A key benefit of the approach is that it can improve accuracy at a relatively low computational cost. The proposed Auxiliary Rawnet model is tested using the ASVspoof 2019 dataset and the results from this dataset indicate that a light-weight waveform encoder can potentially boost the performance of handcrafted-features-based encoders in exchange for a small amount of additional computational work.
Deep Residual Local Feature Learning for Speech Emotion Recognition
Nov 19, 2020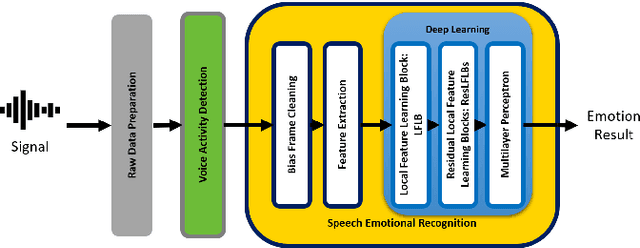
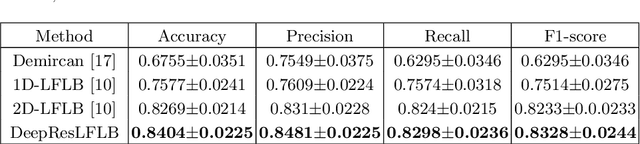
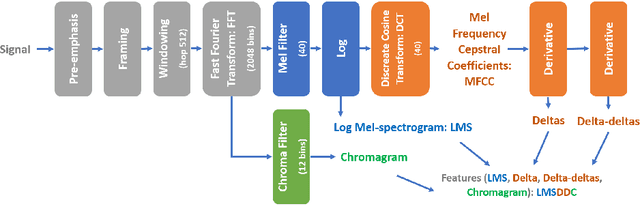

Speech Emotion Recognition (SER) is becoming a key role in global business today to improve service efficiency, like call center services. Recent SERs were based on a deep learning approach. However, the efficiency of deep learning depends on the number of layers, i.e., the deeper layers, the higher efficiency. On the other hand, the deeper layers are causes of a vanishing gradient problem, a low learning rate, and high time-consuming. Therefore, this paper proposed a redesign of existing local feature learning block (LFLB). The new design is called a deep residual local feature learning block (DeepResLFLB). DeepResLFLB consists of three cascade blocks: LFLB, residual local feature learning block (ResLFLB), and multilayer perceptron (MLP). LFLB is built for learning local correlations along with extracting hierarchical correlations; DeepResLFLB can take advantage of repeatedly learning to explain more detail in deeper layers using residual learning for solving vanishing gradient and reducing overfitting; and MLP is adopted to find the relationship of learning and discover probability for predicted speech emotions and gender types. Based on two available published datasets: EMODB and RAVDESS, the proposed DeepResLFLB can significantly improve performance when evaluated by standard metrics: accuracy, precision, recall, and F1-score.
Building competitive direct acoustics-to-word models for English conversational speech recognition
Dec 08, 2017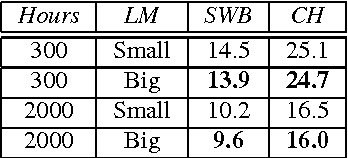
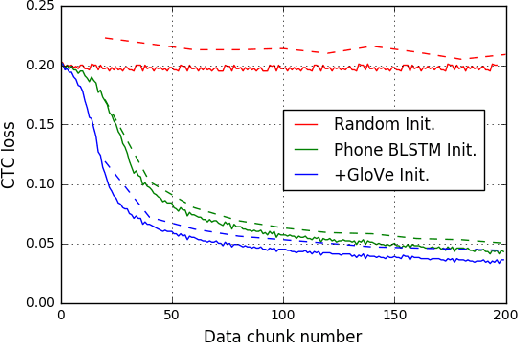
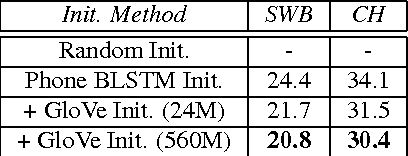
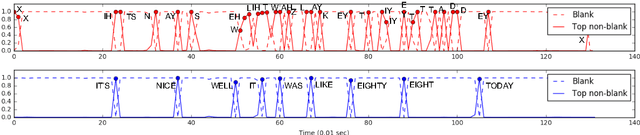
Direct acoustics-to-word (A2W) models in the end-to-end paradigm have received increasing attention compared to conventional sub-word based automatic speech recognition models using phones, characters, or context-dependent hidden Markov model states. This is because A2W models recognize words from speech without any decoder, pronunciation lexicon, or externally-trained language model, making training and decoding with such models simple. Prior work has shown that A2W models require orders of magnitude more training data in order to perform comparably to conventional models. Our work also showed this accuracy gap when using the English Switchboard-Fisher data set. This paper describes a recipe to train an A2W model that closes this gap and is at-par with state-of-the-art sub-word based models. We achieve a word error rate of 8.8%/13.9% on the Hub5-2000 Switchboard/CallHome test sets without any decoder or language model. We find that model initialization, training data order, and regularization have the most impact on the A2W model performance. Next, we present a joint word-character A2W model that learns to first spell the word and then recognize it. This model provides a rich output to the user instead of simple word hypotheses, making it especially useful in the case of words unseen or rarely-seen during training.
Deep Recurrent Convolutional Neural Network: Improving Performance For Speech Recognition
Dec 27, 2016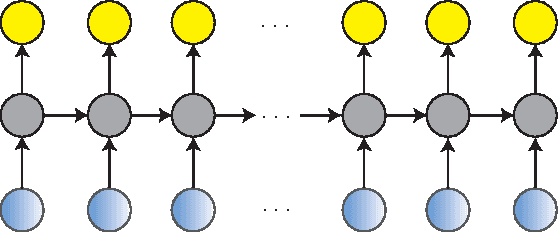
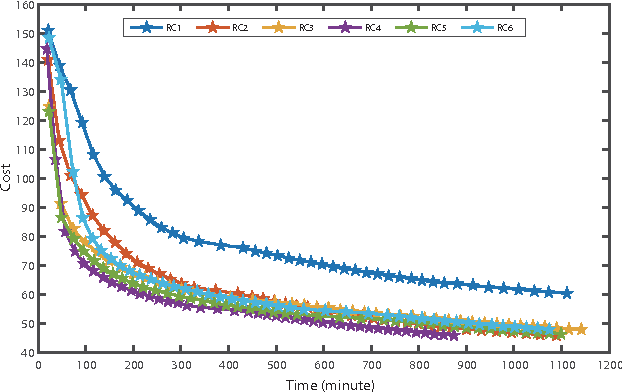
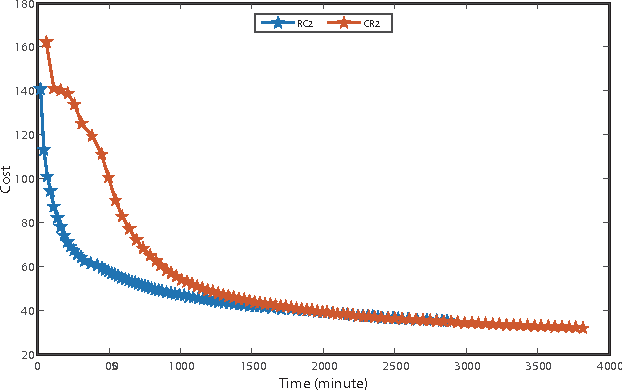
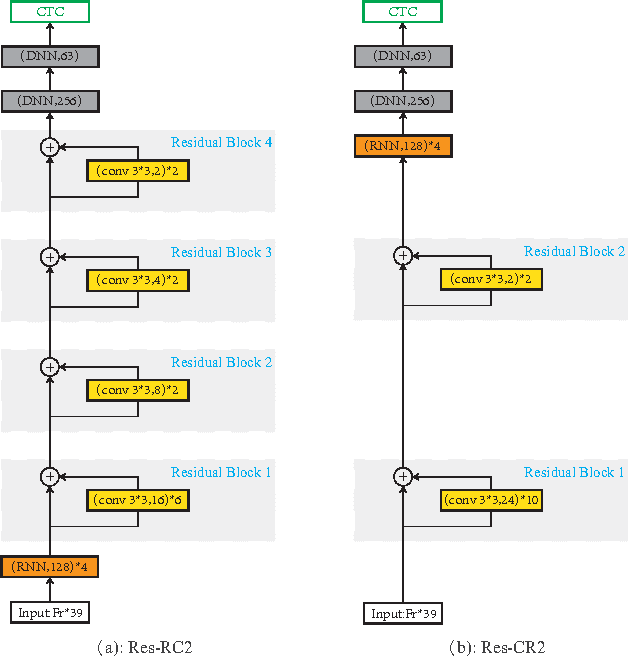
A deep learning approach has been widely applied in sequence modeling problems. In terms of automatic speech recognition (ASR), its performance has significantly been improved by increasing large speech corpus and deeper neural network. Especially, recurrent neural network and deep convolutional neural network have been applied in ASR successfully. Given the arising problem of training speed, we build a novel deep recurrent convolutional network for acoustic modeling and then apply deep residual learning to it. Our experiments show that it has not only faster convergence speed but better recognition accuracy over traditional deep convolutional recurrent network. In the experiments, we compare the convergence speed of our novel deep recurrent convolutional networks and traditional deep convolutional recurrent networks. With faster convergence speed, our novel deep recurrent convolutional networks can reach the comparable performance. We further show that applying deep residual learning can boost the convergence speed of our novel deep recurret convolutional networks. Finally, we evaluate all our experimental networks by phoneme error rate (PER) with our proposed bidirectional statistical n-gram language model. Our evaluation results show that our newly proposed deep recurrent convolutional network applied with deep residual learning can reach the best PER of 17.33\% with the fastest convergence speed on TIMIT database. The outstanding performance of our novel deep recurrent convolutional neural network with deep residual learning indicates that it can be potentially adopted in other sequential problems.