 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding competitive direct acoustics-to-word models for English conversational speech recognition
Paper and Code
Dec 08, 2017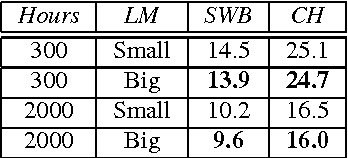
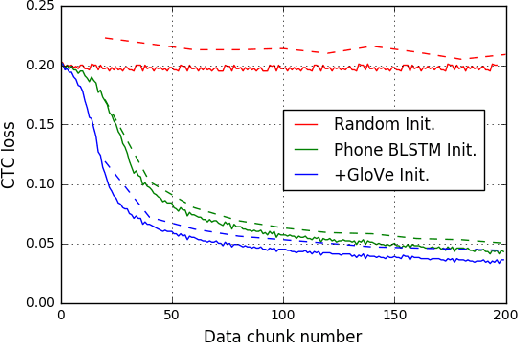
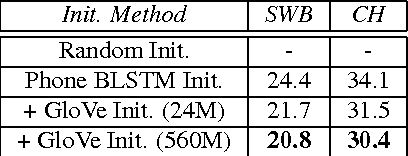
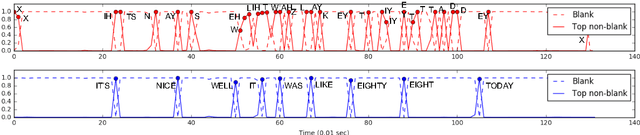
Direct acoustics-to-word (A2W) models in the end-to-end paradigm have received increasing attention compared to conventional sub-word based automatic speech recognition models using phones, characters, or context-dependent hidden Markov model states. This is because A2W models recognize words from speech without any decoder, pronunciation lexicon, or externally-trained language model, making training and decoding with such models simple. Prior work has shown that A2W models require orders of magnitude more training data in order to perform comparably to conventional models. Our work also showed this accuracy gap when using the English Switchboard-Fisher data set. This paper describes a recipe to train an A2W model that closes this gap and is at-par with state-of-the-art sub-word based models. We achieve a word error rate of 8.8%/13.9% on the Hub5-2000 Switchboard/CallHome test sets without any decoder or language model. We find that model initialization, training data order, and regularization have the most impact on the A2W model performance. Next, we present a joint word-character A2W model that learns to first spell the word and then recognize it. This model provides a rich output to the user instead of simple word hypotheses, making it especially useful in the case of words unseen or rarely-seen during training.