 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
End-to-End Speech Emotion Recognition: Challenges of Real-Life Emergency Call Centers Data Recordings
Oct 28, 2021
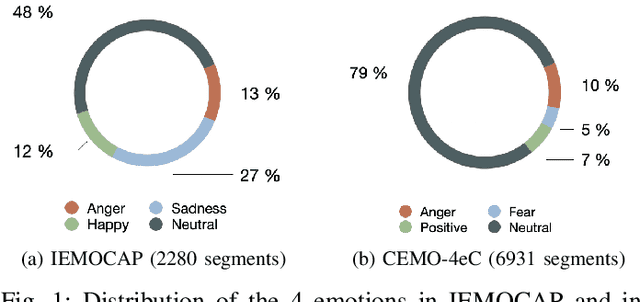
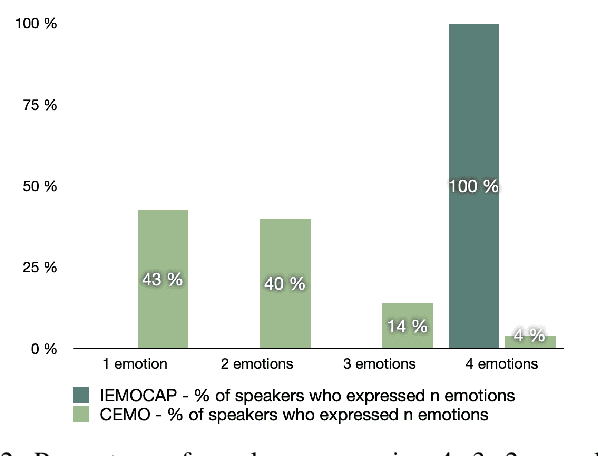
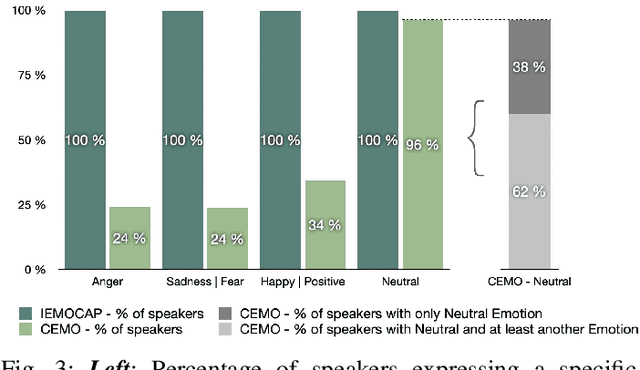
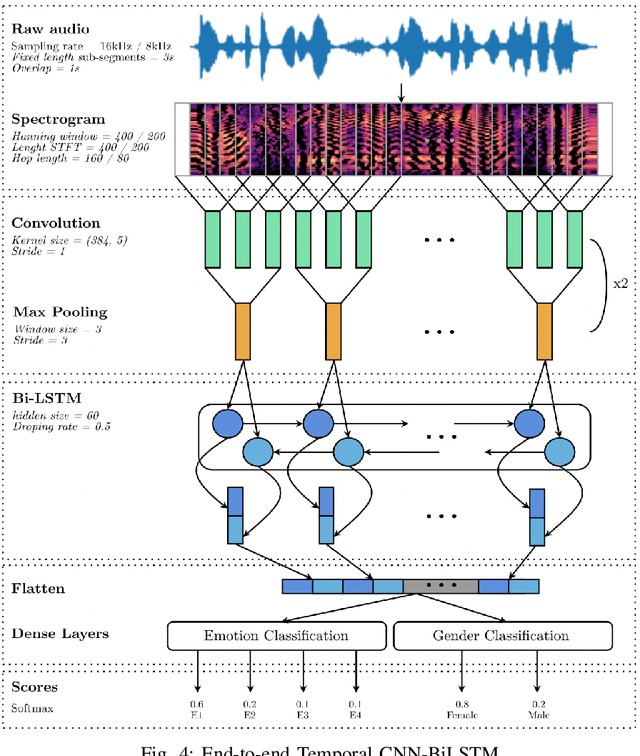
Recognizing a speaker's emotion from their speech can be a key element in emergency call centers. End-to-end deep learning systems for speech emotion recognition now achieve equivalent or even better results than conventional machine learning approaches. In this paper, in order to validate the performance of our neural network architecture for emotion recognition from speech, we first trained and tested it on the widely used corpus accessible by the community, IEMOCAP. We then used the same architecture as the real life corpus, CEMO, composed of 440 dialogs (2h16m) from 485 speakers. The most frequent emotions expressed by callers in these real life emergency dialogues are fear, anger and positive emotions such as relief. In the IEMOCAP general topic conversations, the most frequent emotions are sadness, anger and happiness. Using the same end-to-end deep learning architecture, an Unweighted Accuracy Recall (UA) of 63% is obtained on IEMOCAP and a UA of 45.6% on CEMO, each with 4 classes. Using only 2 classes (Anger, Neutral), the results for CEMO are 76.9% UA compared to 81.1% UA for IEMOCAP. We expect that these encouraging results with CEMO can be improved by combining the audio channel with the linguistic channel. Real-life emotions are clearly more complex than acted ones, mainly due to the large diversity of emotional expressions of speakers. Index Terms-emotion detection, end-to-end deep learning architecture, call center, real-life database, complex emotions.
Long Short-Term Memory based Convolutional Recurrent Neural Networks for Large Vocabulary Speech Recognition
Oct 11, 2016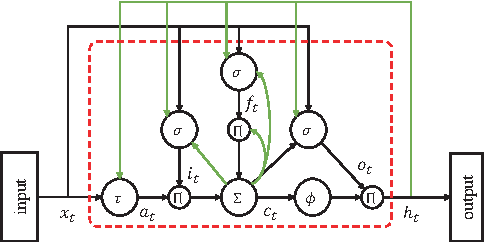

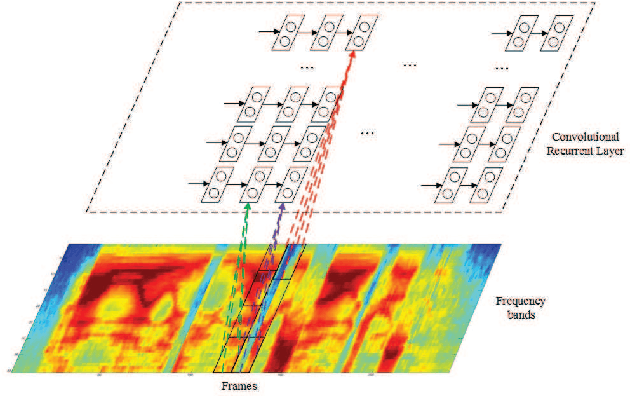
Long short-term memory (LSTM) recurrent neural networks (RNNs) have been shown to give state-of-the-art performance on many speech recognition tasks, as they are able to provide the learned dynamically changing contextual window of all sequence history. On the other hand, the convolutional neural networks (CNNs) have brought significant improvements to deep feed-forward neural networks (FFNNs), as they are able to better reduce spectral variation in the input signal. In this paper, a network architecture called as convolutional recurrent neural network (CRNN) is proposed by combining the CNN and LSTM RNN. In the proposed CRNNs, each speech frame, without adjacent context frames, is organized as a number of local feature patches along the frequency axis, and then a LSTM network is performed on each feature patch along the time axis. We train and compare FFNNs, LSTM RNNs and the proposed LSTM CRNNs at various number of configurations. Experimental results show that the LSTM CRNNs can exceed state-of-the-art speech recognition performance.
Pretraining Approaches for Spoken Language Recognition: TalTech Submission to the OLR 2021 Challenge
May 14, 2022
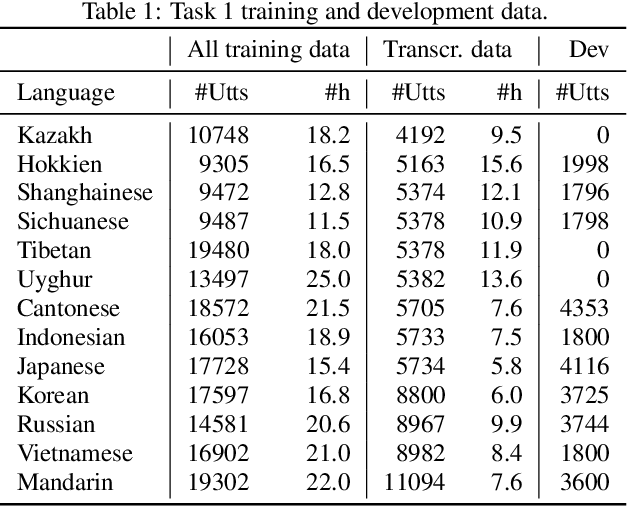
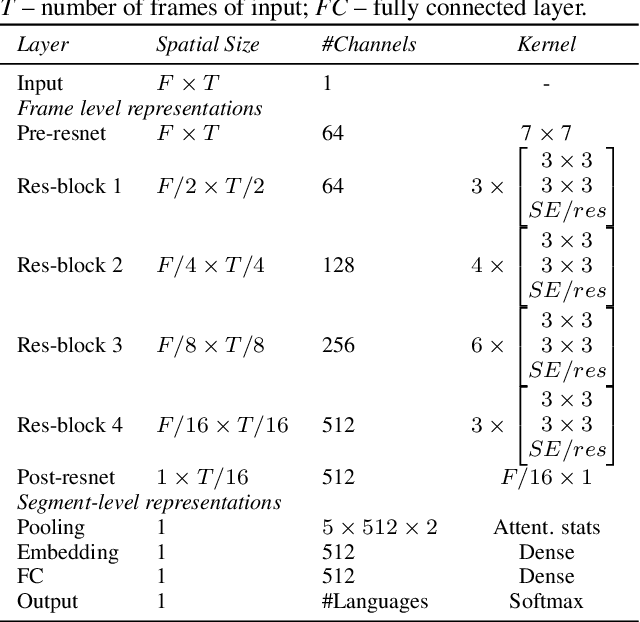
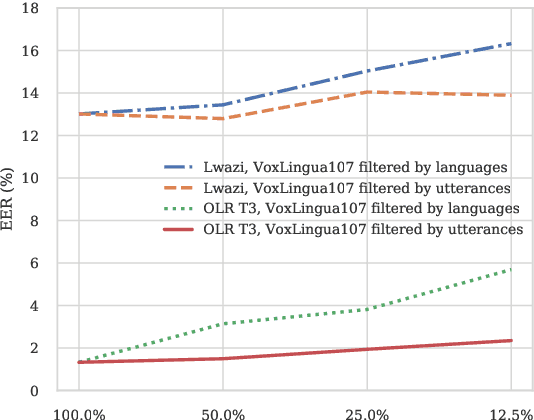
This paper investigates different pretraining approaches to spoken language identification. The paper is based on our submission to the Oriental Language Recognition 2021 Challenge. We participated in two tracks of the challenge: constrained and unconstrained language recognition. For the constrained track, we first trained a Conformer-based encoder-decoder model for multilingual automatic speech recognition (ASR), using the provided training data that had transcripts available. The shared encoder of the multilingual ASR model was then finetuned for the language identification task. For the unconstrained task, we relied on both externally available pretrained models as well as external data: the multilingual XLSR-53 wav2vec2.0 model was finetuned on the VoxLingua107 corpus for the language recognition task, and finally finetuned on the provided target language training data, augmented with CommonVoice data. Our primary metric $C_{\rm avg}$ values on the Test set are 0.0079 for the constrained task and 0.0119 for the unconstrained task which resulted in the second place in both rankings. In post-evaluation experiments, we study the amount of target language data needed for training an accurate backend model, the importance of multilingual pretraining data, and compare different models as finetuning starting points.
Speaker adaptation for Wav2vec2 based dysarthric ASR
Apr 02, 2022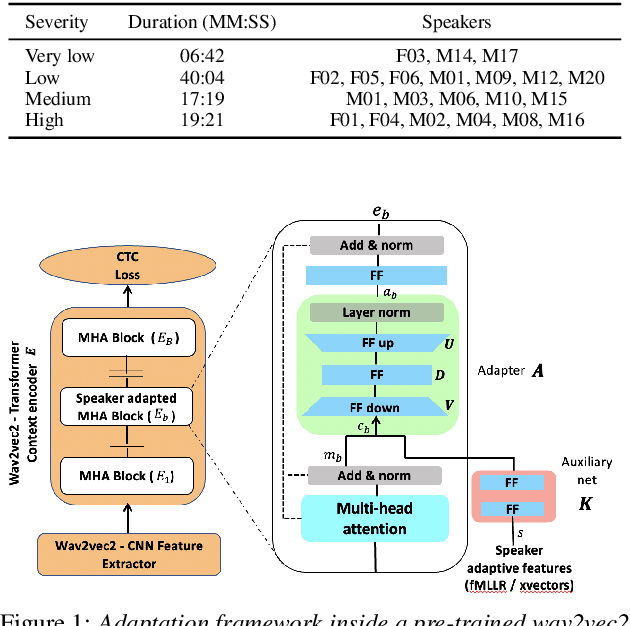
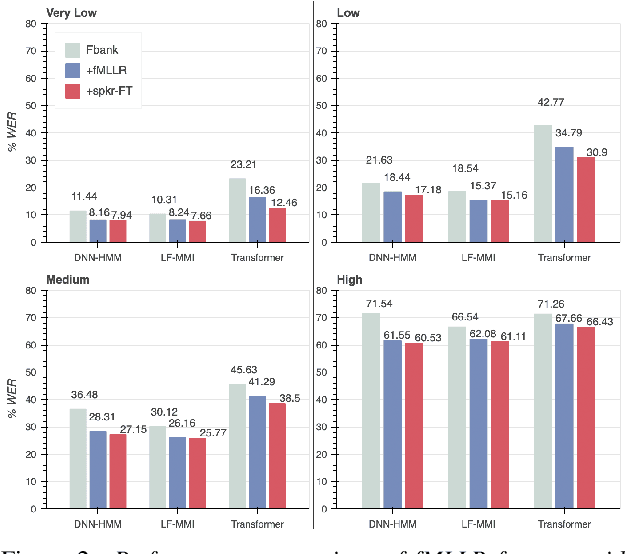
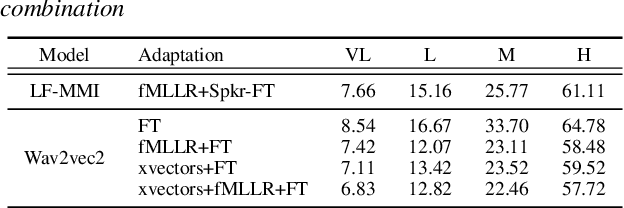
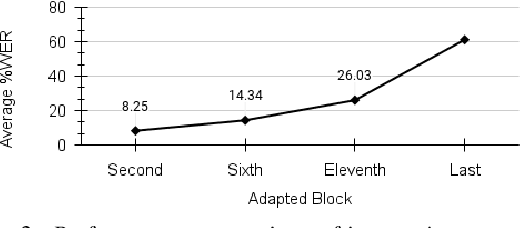
Dysarthric speech recognition has posed major challenges due to lack of training data and heavy mismatch in speaker characteristics. Recent ASR systems have benefited from readily available pretrained models such as wav2vec2 to improve the recognition performance. Speaker adaptation using fMLLR and xvectors have provided major gains for dysarthric speech with very little adaptation data. However, integration of wav2vec2 with fMLLR features or xvectors during wav2vec2 finetuning is yet to be explored. In this work, we propose a simple adaptation network for fine-tuning wav2vec2 using fMLLR features. The adaptation network is also flexible to handle other speaker adaptive features such as xvectors. Experimental analysis show steady improvements using our proposed approach across all impairment severity levels and attains 57.72\% WER for high severity in UASpeech dataset. We also performed experiments on German dataset to substantiate the consistency of our proposed approach across diverse domains.
Building an ASR Error Robust Spoken Virtual Patient System in a Highly Class-Imbalanced Scenario Without Speech Data
Apr 11, 2022
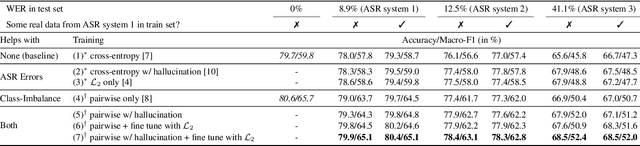
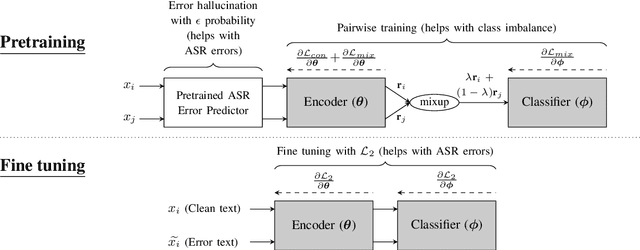

A Virtual Patient (VP) is a powerful tool for training medical students to take patient histories, where responding to a diverse set of spoken questions is essential to simulate natural conversations with a student. The performance of such a Spoken Language Understanding system (SLU) can be adversely affected by both the presence of Automatic Speech Recognition (ASR) errors in the test data and a high degree of class imbalance in the SLU training data. While these two issues have been addressed separately in prior work, we develop a novel two-step training methodology that tackles both these issues effectively in a single dialog agent. As it is difficult to collect spoken data from users without a functioning SLU system, our method does not rely on spoken data for training, rather we use an ASR error predictor to "speechify" the text data. Our method shows significant improvements over strong baselines on the VP intent classification task at various word error rate settings.
Revisiting End-to-End Speech-to-Text Translation From Scratch
Jun 09, 2022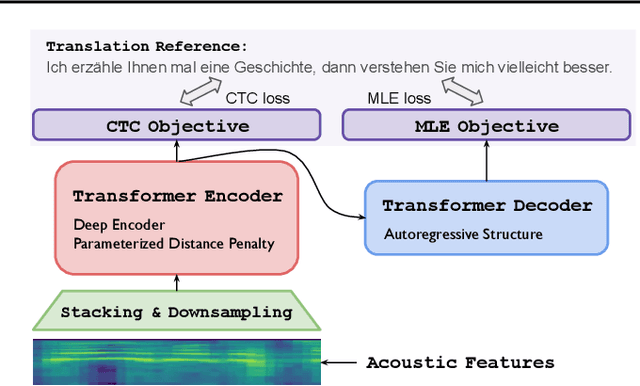
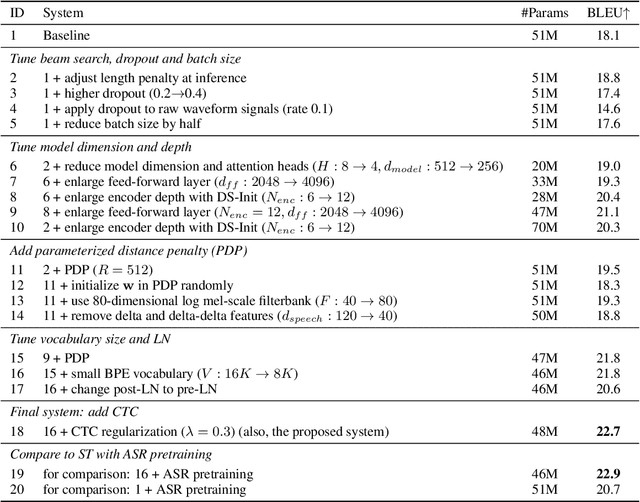
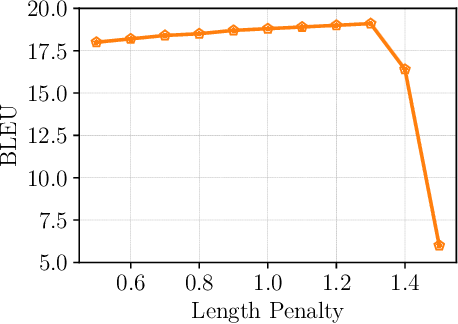
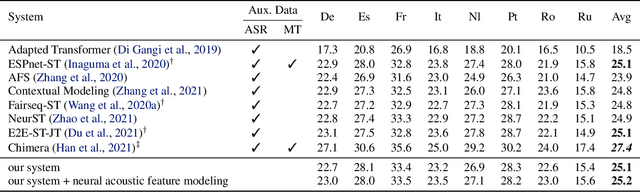
End-to-end (E2E) speech-to-text translation (ST) often depends on pretraining its encoder and/or decoder using source transcripts via speech recognition or text translation tasks, without which translation performance drops substantially. However, transcripts are not always available, and how significant such pretraining is for E2E ST has rarely been studied in the literature. In this paper, we revisit this question and explore the extent to which the quality of E2E ST trained on speech-translation pairs alone can be improved. We reexamine several techniques proven beneficial to ST previously, and offer a set of best practices that biases a Transformer-based E2E ST system toward training from scratch. Besides, we propose parameterized distance penalty to facilitate the modeling of locality in the self-attention model for speech. On four benchmarks covering 23 languages, our experiments show that, without using any transcripts or pretraining, the proposed system reaches and even outperforms previous studies adopting pretraining, although the gap remains in (extremely) low-resource settings. Finally, we discuss neural acoustic feature modeling, where a neural model is designed to extract acoustic features from raw speech signals directly, with the goal to simplify inductive biases and add freedom to the model in describing speech. For the first time, we demonstrate its feasibility and show encouraging results on ST tasks.
Improving Language Identification of Accented Speech
Apr 01, 2022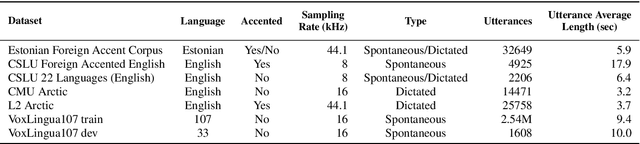
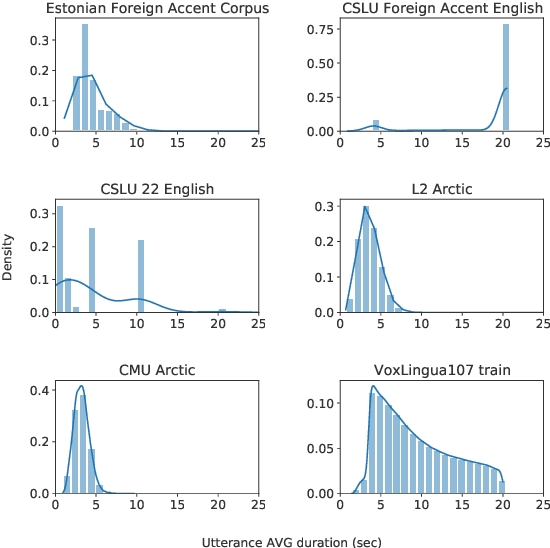
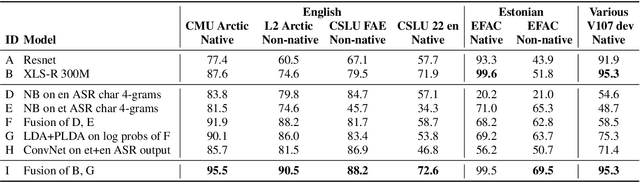
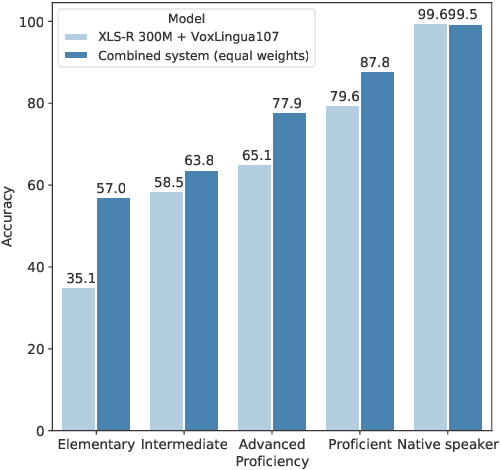
Language identification from speech is a common preprocessing step in many spoken language processing systems. In recent years, this field has seen a fast progress, mostly due to the use of self-supervised models pretrained on multilingual data and the use of large training corpora. This paper shows that for speech with a non-native or regional accent, the accuracy of spoken language identification systems drops dramatically, and that the accuracy of identifying the language is inversely correlated with the strength of the accent. We also show that using the output of a lexicon-free speech recognition system of the particular language helps to improve language identification performance on accented speech by a large margin, without sacrificing accuracy on native speech. We obtain relative error rate reductions ranging from to 35 to 63% over the state-of-the-art model across several non-native speech datasets.
Unsupervised Speech Recognition via Segmental Empirical Output Distribution Matching
Dec 23, 2018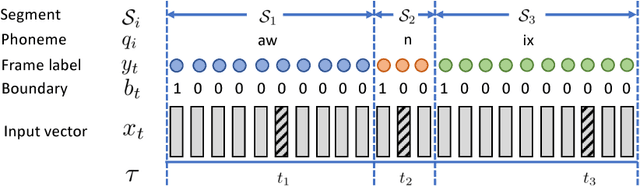
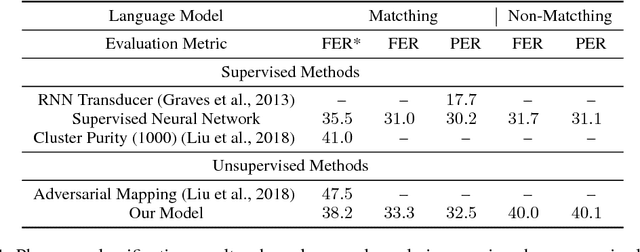
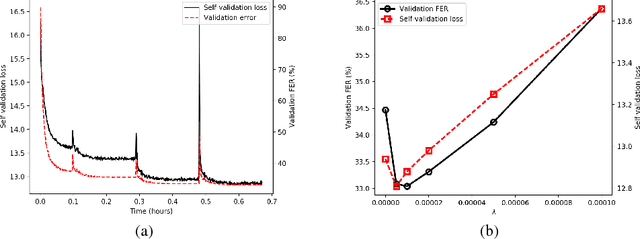
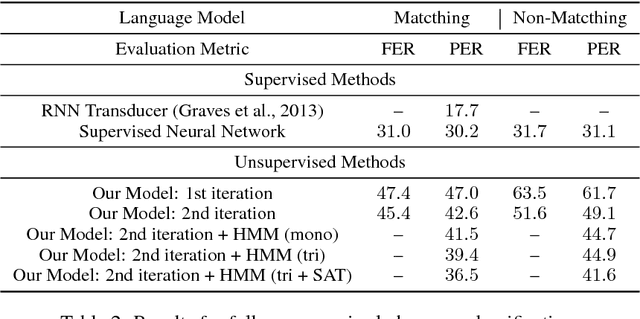
We consider the problem of training speech recognition systems without using any labeled data, under the assumption that the learner can only access to the input utterances and a phoneme language model estimated from a non-overlapping corpus. We propose a fully unsupervised learning algorithm that alternates between solving two sub-problems: (i) learn a phoneme classifier for a given set of phoneme segmentation boundaries, and (ii) refining the phoneme boundaries based on a given classifier. To solve the first sub-problem, we introduce a novel unsupervised cost function named Segmental Empirical Output Distribution Matching, which generalizes the work in (Liu et al., 2017) to segmental structures. For the second sub-problem, we develop an approximate MAP approach to refining the boundaries obtained from Wang et al. (2017). Experimental results on TIMIT dataset demonstrate the success of this fully unsupervised phoneme recognition system, which achieves a phone error rate (PER) of 41.6%. Although it is still far away from the state-of-the-art supervised systems, we show that with oracle boundaries and matching language model, the PER could be improved to 32.5%.This performance approaches the supervised system of the same model architecture, demonstrating the great potential of the proposed method.
Fast and Accurate Capitalization and Punctuation for Automatic Speech Recognition Using Transformer and Chunk Merging
Aug 07, 2019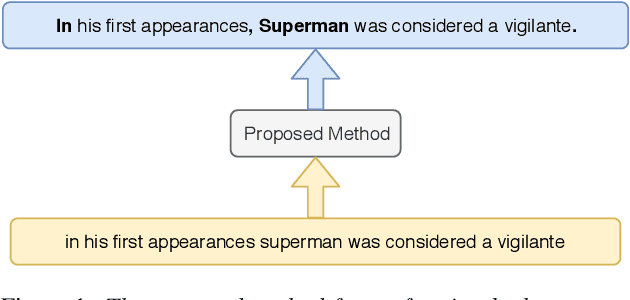
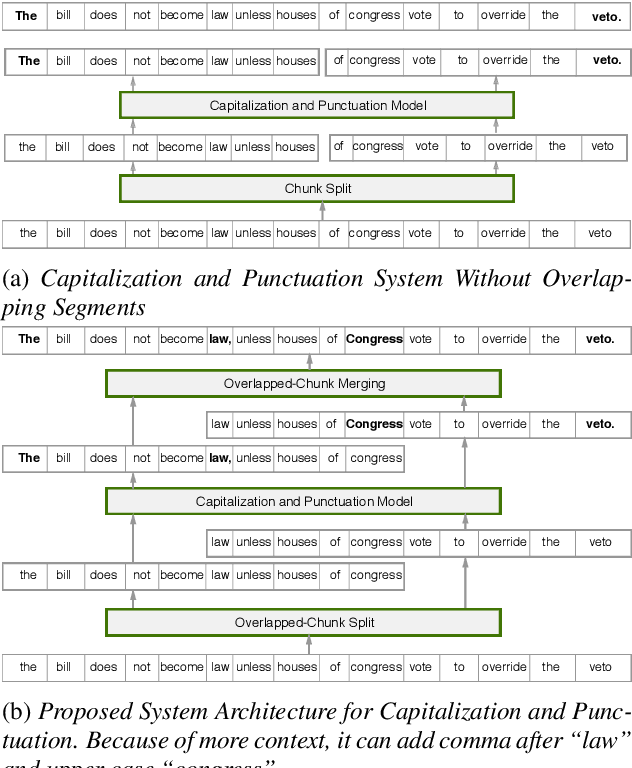
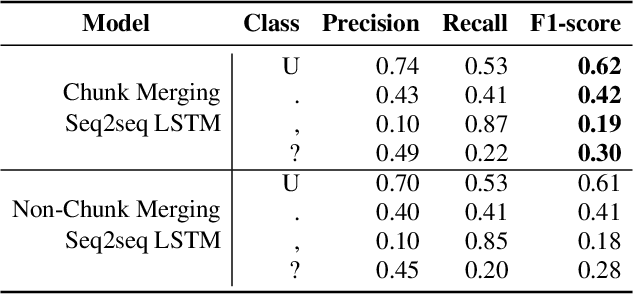
In recent years, studies on automatic speech recognition (ASR) have shown outstanding results that reach human parity on short speech segments. However, there are still difficulties in standardizing the output of ASR such as capitalization and punctuation restoration for long-speech transcription. The problems obstruct readers to understand the ASR output semantically and also cause difficulties for natural language processing models such as NER, POS and semantic parsing. In this paper, we propose a method to restore the punctuation and capitalization for long-speech ASR transcription. The method is based on Transformer models and chunk merging that allows us to (1), build a single model that performs punctuation and capitalization in one go, and (2), perform decoding in parallel while improving the prediction accuracy. Experiments on British National Corpus showed that the proposed approach outperforms existing methods in both accuracy and decoding speed.
Sequence-Level Knowledge Distillation for Model Compression of Attention-based Sequence-to-Sequence Speech Recognition
Nov 12, 2018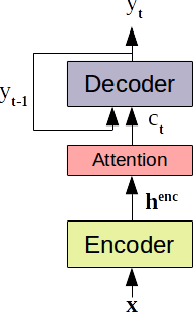

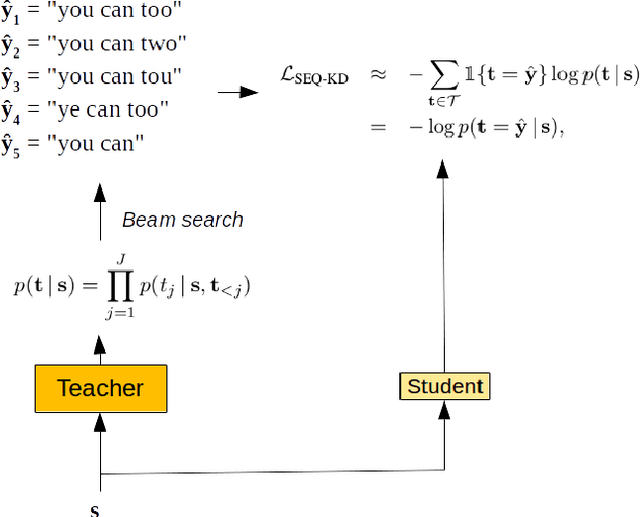
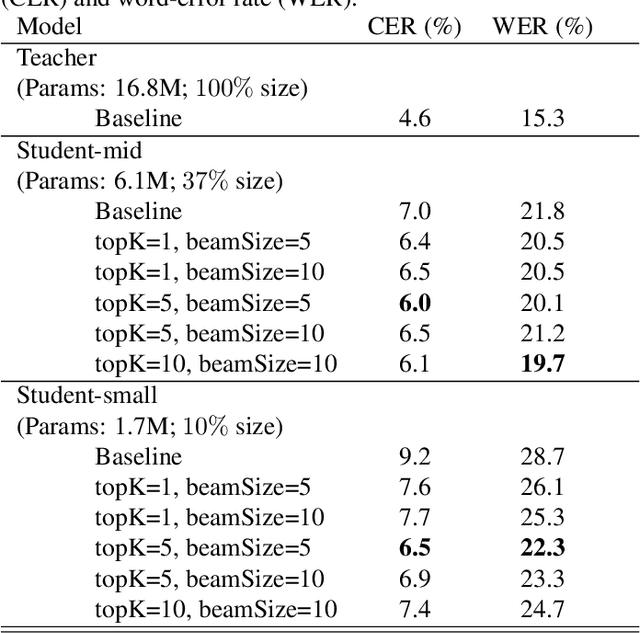
We investigate the feasibility of sequence-level knowledge distillation of Sequence-to-Sequence (Seq2Seq) models for Large Vocabulary Continuous Speech Recognition (LVSCR). We first use a pre-trained larger teacher model to generate multiple hypotheses per utterance with beam search. With the same input, we then train the student model using these hypotheses generated from the teacher as pseudo labels in place of the original ground truth labels. We evaluate our proposed method using Wall Street Journal (WSJ) corpus. It achieved up to $ 9.8 \times$ parameter reduction with accuracy loss of up to 7.0\% word-error rate (WER) increase