 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cross Lingual Cross Corpus Speech Emotion Recognition
Mar 18, 2020

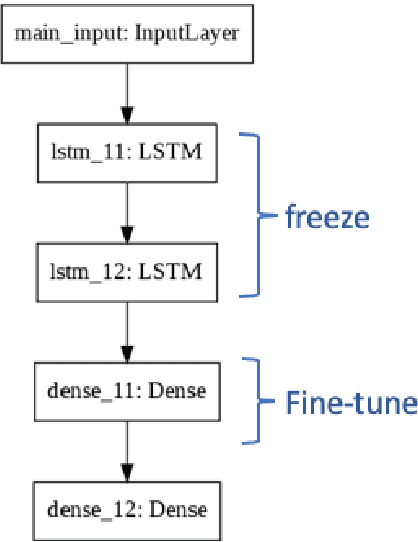
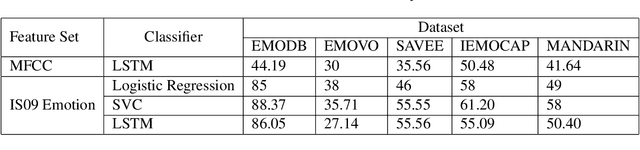
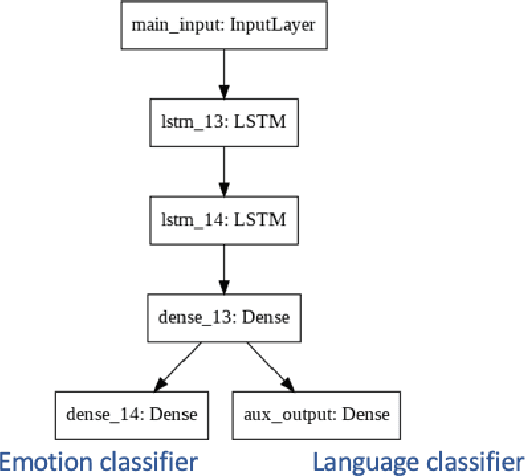
The majority of existing speech emotion recognition models are trained and evaluated on a single corpus and a single language setting. These systems do not perform as well when applied in a cross-corpus and cross-language scenario. This paper presents results for speech emotion recognition for 4 languages in both single corpus and cross corpus setting. Additionally, since multi-task learning (MTL) with gender, naturalness and arousal as auxiliary tasks has shown to enhance the generalisation capabilities of the emotion models, this paper introduces language ID as another auxiliary task in MTL framework to explore the role of spoken language on emotion recognition which has not been studied yet.
Hypergraph based semi-supervised learning algorithms applied to speech recognition problem: a novel approach
Oct 28, 2018
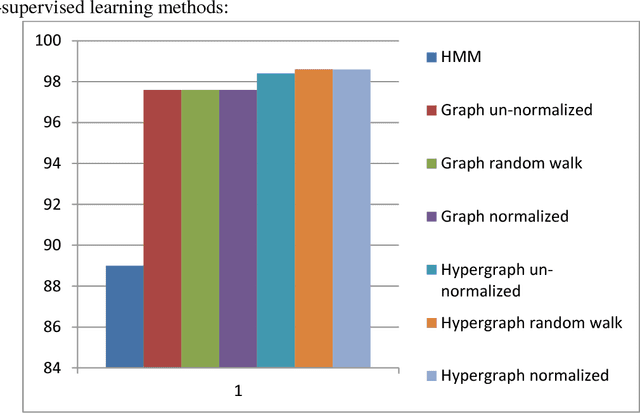
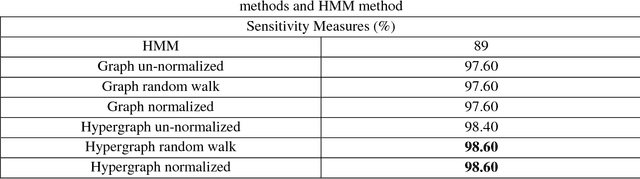
Most network-based speech recognition methods are based on the assumption that the labels of two adjacent speech samples in the network are likely to be the same. However, assuming the pairwise relationship between speech samples is not complete. The information a group of speech samples that show very similar patterns and tend to have similar labels is missed. The natural way overcoming the information loss of the above assumption is to represent the feature data of speech samples as the hypergraph. Thus, in this paper, the three un-normalized, random walk, and symmetric normalized hypergraph Laplacian based semi-supervised learning methods applied to hypergraph constructed from the feature data of speech samples in order to predict the labels of speech samples are introduced. Experiment results show that the sensitivity performance measures of these three hypergraph Laplacian based semi-supervised learning methods are greater than the sensitivity performance measures of the Hidden Markov Model method (the current state of the art method applied to speech recognition problem) and graph based semi-supervised learning methods (i.e. the current state of the art network-based method for classification problems) applied to network created from the feature data of speech samples.
NNTrainer: Light-Weight On-Device Training Framework
Jun 09, 2022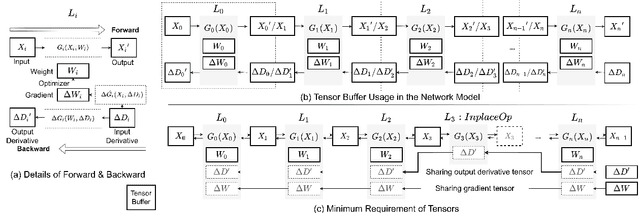

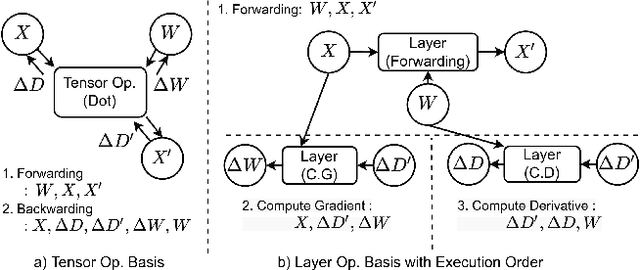

Modern consumer electronic devices have adopted deep learning-based intelligence services for their key features. Vendors have recently started to execute intelligence services on devices to preserve personal data in devices, reduce network and cloud costs. We find such a trend as the opportunity to personalize intelligence services by updating neural networks with user data without exposing the data out of devices: on-device training. For example, we may add a new class, my dog, Alpha, for robotic vacuums, adapt speech recognition for the users accent, let text-to-speech speak as if the user speaks. However, the resource limitations of target devices incur significant difficulties. We propose NNTrainer, a light-weight on-device training framework. We describe optimization techniques for neural networks implemented by NNTrainer, which are evaluated along with the conventional. The evaluations show that NNTrainer can reduce memory consumption down to 1/28 without deteriorating accuracy or training time and effectively personalizes applications on devices. NNTrainer is cross-platform and practical open source software, which is being deployed to millions of devices in the authors affiliation.
Unsupervised pre-traing for sequence to sequence speech recognition
Oct 28, 2019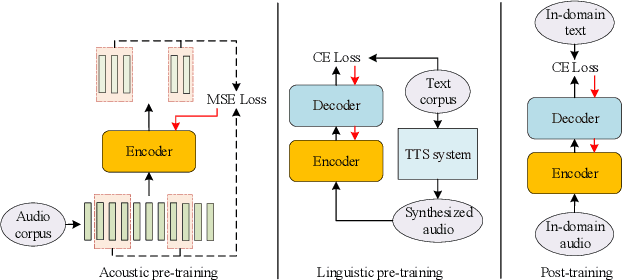

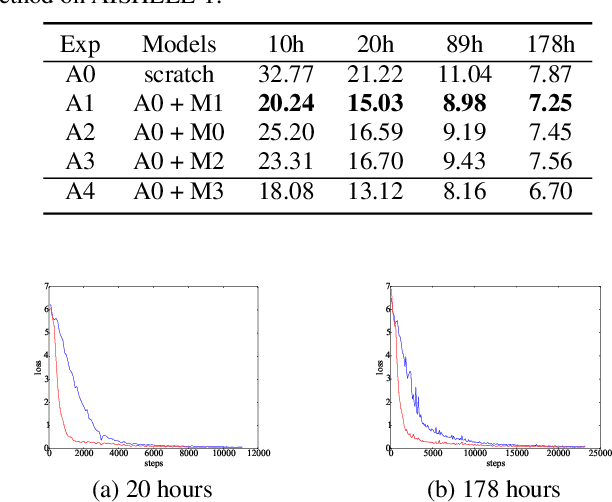
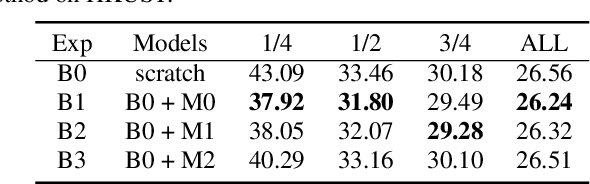
This paper proposes a novel approach to pre-train encoder-decoder sequence-to-sequence (seq2seq) model with unpaired speech and transcripts respectively. Our pre-training method is divided into two stages, named acoustic pre-trianing and linguistic pre-training. In the acoustic pre-training stage, we use a large amount of speech to pre-train the encoder by predicting masked speech feature chunks with its context. In the linguistic pre-training stage, we generate synthesized speech from a large number of transcripts using a single-speaker text to speech (TTS) system, and use the synthesized paired data to pre-train decoder. This two-stage pre-training method integrates rich acoustic and linguistic knowledge into seq2seq model, which will benefit downstream automatic speech recognition (ASR) tasks. The unsupervised pre-training is finished on AISHELL-2 dataset and we apply the pre-trained model to multiple paired data ratios of AISHELL-1 and HKUST. We obtain relative character error rate reduction (CERR) from 38.24% to 7.88% on AISHELL-1 and from 12.00% to 1.20% on HKUST. Besides, we apply our pretrained model to a cross-lingual case with CALLHOME dataset. For all six languages in CALLHOME dataset, our pre-training method makes model outperform baseline consistently.
Training Augmentation with Adversarial Examples for Robust Speech Recognition
Jun 17, 2018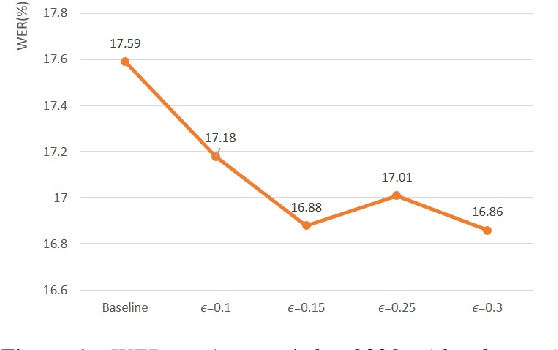
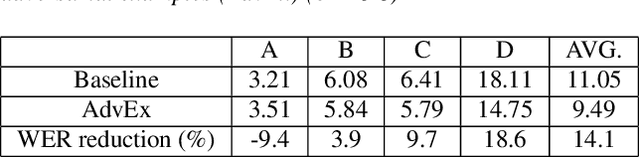
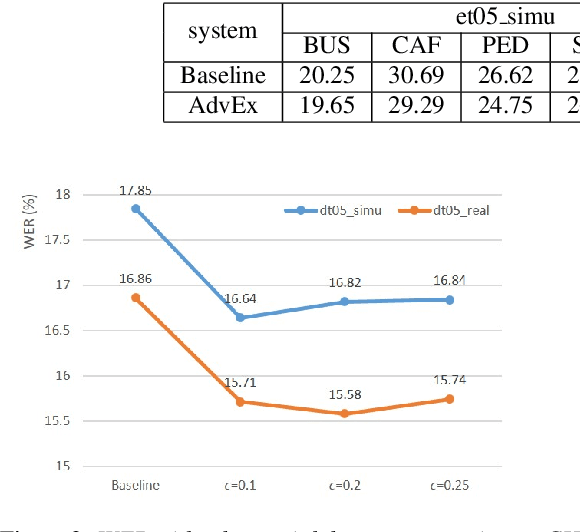
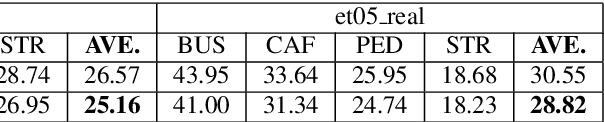
This paper explores the use of adversarial examples in training speech recognition systems to increase robustness of deep neural network acoustic models. During training, the fast gradient sign method is used to generate adversarial examples augmenting the original training data. Different from conventional data augmentation based on data transformations, the examples are dynamically generated based on current acoustic model parameters. We assess the impact of adversarial data augmentation in experiments on the Aurora-4 and CHiME-4 single-channel tasks, showing improved robustness against noise and channel variation. Further improvement is obtained when combining adversarial examples with teacher/student training, leading to a 23% relative word error rate reduction on Aurora-4.
Attribute Inference Attack of Speech Emotion Recognition in Federated Learning Settings
Dec 26, 2021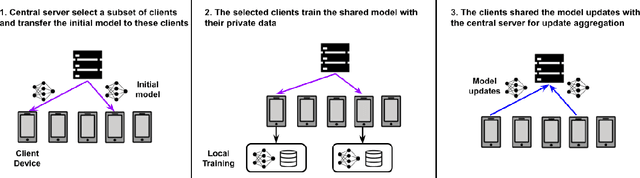
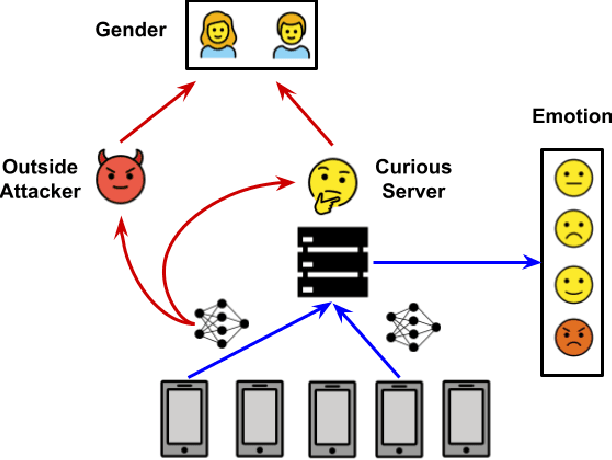
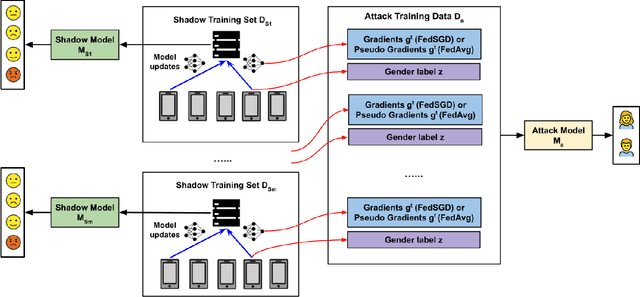
Speech emotion recognition (SER) processes speech signals to detect and characterize expressed perceived emotions. Many SER application systems often acquire and transmit speech data collected at the client-side to remote cloud platforms for inference and decision making. However, speech data carry rich information not only about emotions conveyed in vocal expressions, but also other sensitive demographic traits such as gender, age and language background. Consequently, it is desirable for SER systems to have the ability to classify emotion constructs while preventing unintended/improper inferences of sensitive and demographic information. Federated learning (FL) is a distributed machine learning paradigm that coordinates clients to train a model collaboratively without sharing their local data. This training approach appears secure and can improve privacy for SER. However, recent works have demonstrated that FL approaches are still vulnerable to various privacy attacks like reconstruction attacks and membership inference attacks. Although most of these have focused on computer vision applications, such information leakages exist in the SER systems trained using the FL technique. To assess the information leakage of SER systems trained using FL, we propose an attribute inference attack framework that infers sensitive attribute information of the clients from shared gradients or model parameters, corresponding to the FedSGD and the FedAvg training algorithms, respectively. As a use case, we empirically evaluate our approach for predicting the client's gender information using three SER benchmark datasets: IEMOCAP, CREMA-D, and MSP-Improv. We show that the attribute inference attack is achievable for SER systems trained using FL. We further identify that most information leakage possibly comes from the first layer in the SER model.
Online Model Compression for Federated Learning with Large Models
May 06, 2022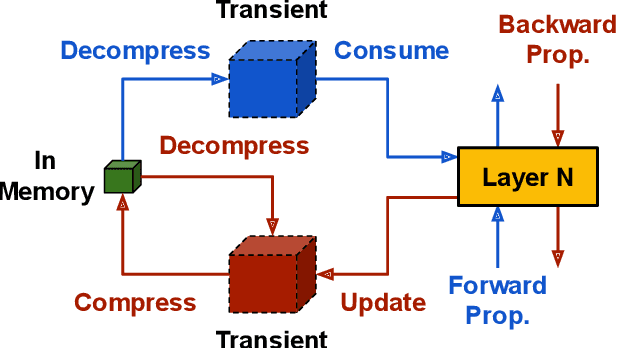
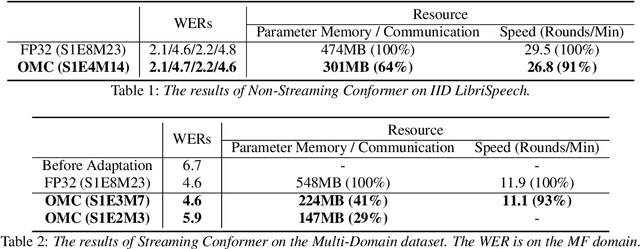
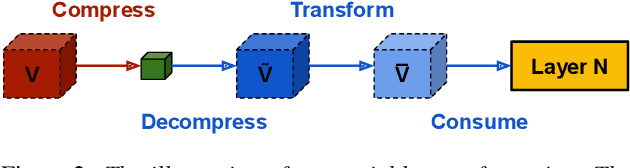
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
AccentDB: A Database of Non-Native English Accents to Assist Neural Speech Recognition
May 16, 2020
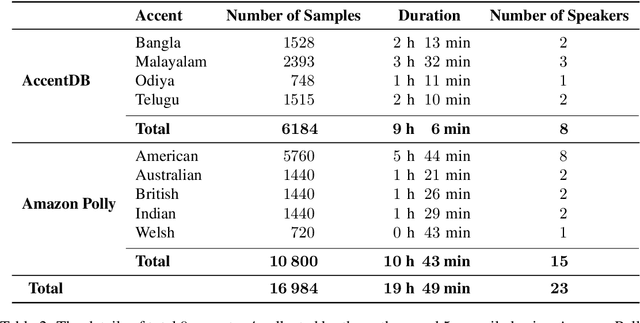
Modern Automatic Speech Recognition (ASR) technology has evolved to identify the speech spoken by native speakers of a language very well. However, identification of the speech spoken by non-native speakers continues to be a major challenge for it. In this work, we first spell out the key requirements for creating a well-curated database of speech samples in non-native accents for training and testing robust ASR systems. We then introduce AccentDB, one such database that contains samples of 4 Indian-English accents collected by us, and a compilation of samples from 4 native-English, and a metropolitan Indian-English accent. We also present an analysis on separability of the collected accent data. Further, we present several accent classification models and evaluate them thoroughly against human-labelled accent classes. We test the generalization of our classifier models in a variety of setups of seen and unseen data. Finally, we introduce the task of accent neutralization of non-native accents to native accents using autoencoder models with task-specific architectures. Thus, our work aims to aid ASR systems at every stage of development with a database for training, classification models for feature augmentation, and neutralization systems for acoustic transformations of non-native accents of English.
Automatic recognition of suprasegmentals in speech
Aug 04, 2021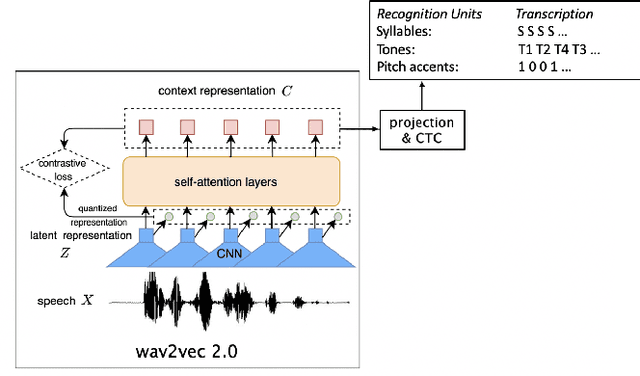
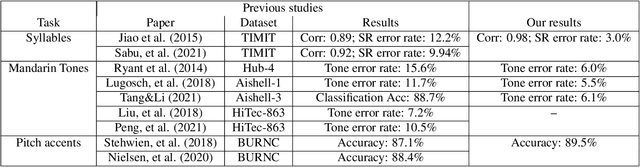
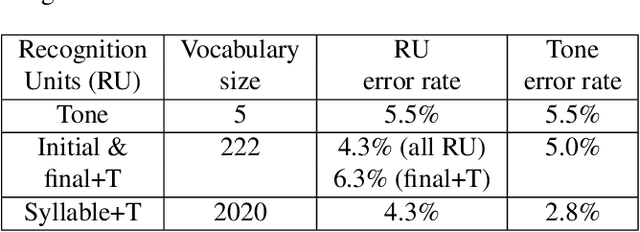
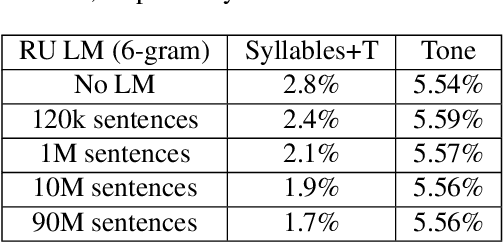
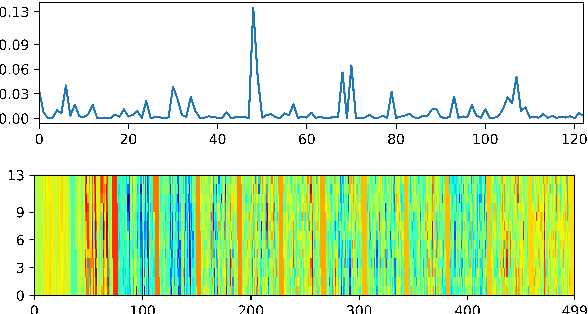
This study reports our efforts to improve automatic recognition of suprasegmentals by fine-tuning wav2vec 2.0 with CTC, a method that has been successful in automatic speech recognition. We demonstrate that the method can improve the state-of-the-art on automatic recognition of syllables, tones, and pitch accents. Utilizing segmental information, by employing tonal finals or tonal syllables as recognition units, can significantly improve Mandarin tone recognition. Language models are helpful when tonal syllables are used as recognition units, but not helpful when tones are recognition units. Finally, Mandarin tone recognition can benefit from English phoneme recognition by combining the two tasks in fine-tuning wav2vec 2.0.
Streaming Noise Context Aware Enhancement For Automatic Speech Recognition in Multi-Talker Environments
May 17, 2022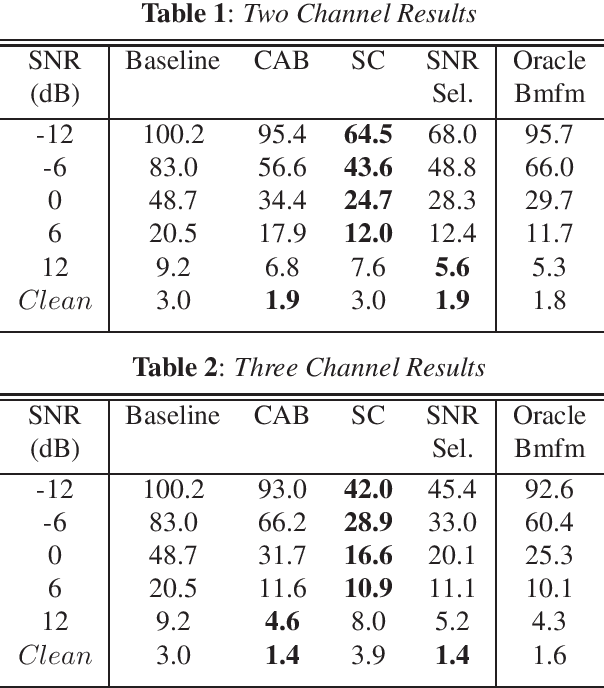
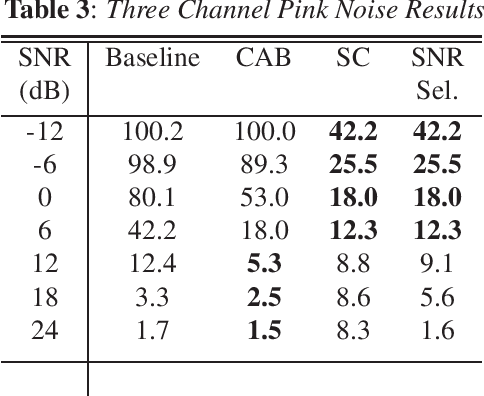
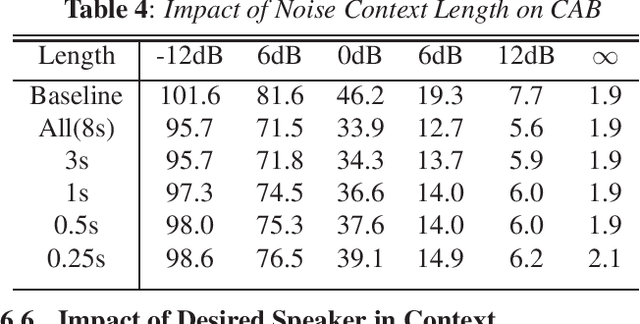
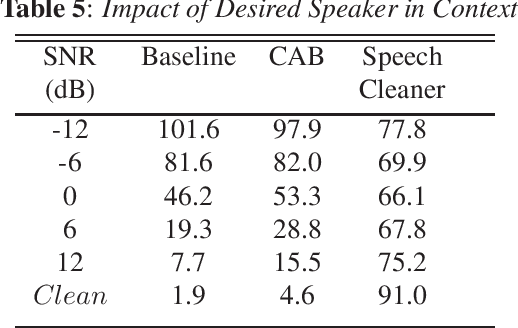
One of the most challenging scenarios for smart speakers is multi-talker, when target speech from the desired speaker is mixed with interfering speech from one or more speakers. A smart assistant needs to determine which voice to recognize and which to ignore and it needs to do so in a streaming, low-latency manner. This work presents two multi-microphone speech enhancement algorithms targeted at this scenario. Targeting on-device use-cases, we assume that the algorithm has access to the signal before the hotword, which is referred to as the noise context. First is the Context Aware Beamformer which uses the noise context and detected hotword to determine how to target the desired speaker. The second is an adaptive noise cancellation algorithm called Speech Cleaner which trains a filter using the noise context. It is demonstrated that the two algorithms are complementary in the signal-to-noise ratio conditions under which they work well. We also propose an algorithm to select which one to use based on estimated SNR. When using 3 microphone channels, the final system achieves a relative word error rate reduction of 55% at -12dB, and 43\% at 12dB.