 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Painterly Image Harmonization via Adversarial Residual Learning
Nov 15, 2023
Image compositing plays a vital role in photo editing. After inserting a foreground object into another background image, the composite image may look unnatural and inharmonious. When the foreground is photorealistic and the background is an artistic painting, painterly image harmonization aims to transfer the style of background painting to the foreground object, which is a challenging task due to the large domain gap between foreground and background. In this work, we employ adversarial learning to bridge the domain gap between foreground feature map and background feature map. Specifically, we design a dual-encoder generator, in which the residual encoder produces the residual features added to the foreground feature map from main encoder. Then, a pixel-wise discriminator plays against the generator, encouraging the refined foreground feature map to be indistinguishable from background feature map. Extensive experiments demonstrate that our method could achieve more harmonious and visually appealing results than previous methods.
Training Robust Deep Physiological Measurement Models with Synthetic Video-based Data
Nov 15, 2023Recent advances in supervised deep learning techniques have demonstrated the possibility to remotely measure human physiological vital signs (e.g., photoplethysmograph, heart rate) just from facial videos. However, the performance of these methods heavily relies on the availability and diversity of real labeled data. Yet, collecting large-scale real-world data with high-quality labels is typically challenging and resource intensive, which also raises privacy concerns when storing personal bio-metric data. Synthetic video-based datasets (e.g., SCAMPS \cite{mcduff2022scamps}) with photo-realistic synthesized avatars are introduced to alleviate the issues while providing high-quality synthetic data. However, there exists a significant gap between synthetic and real-world data, which hinders the generalization of neural models trained on these synthetic datasets. In this paper, we proposed several measures to add real-world noise to synthetic physiological signals and corresponding facial videos. We experimented with individual and combined augmentation methods and evaluated our framework on three public real-world datasets. Our results show that we were able to reduce the average MAE from 6.9 to 2.0.
Data Augmentation: a Combined Inductive-Deductive Approach featuring Answer Set Programming
Oct 22, 2023Although the availability of a large amount of data is usually given for granted, there are relevant scenarios where this is not the case; for instance, in the biomedical/healthcare domain, some applications require to build huge datasets of proper images, but the acquisition of such images is often hard for different reasons (e.g., accessibility, costs, pathology-related variability), thus causing limited and usually imbalanced datasets. Hence, the need for synthesizing photo-realistic images via advanced Data Augmentation techniques is crucial. In this paper we propose a hybrid inductive-deductive approach to the problem; in particular, starting from a limited set of real labeled images, the proposed framework makes use of logic programs for declaratively specifying the structure of new images, that is guaranteed to comply with both a set of constraints coming from the domain knowledge and some specific desiderata. The resulting labeled images undergo a dedicated process based on Deep Learning in charge of creating photo-realistic images that comply with the generated label.
Protecting Voice-Controlled Devices against LASER Injection Attacks
Oct 13, 2023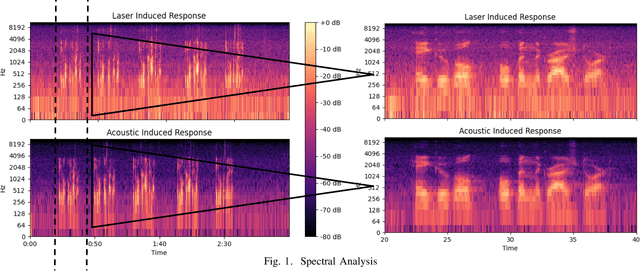
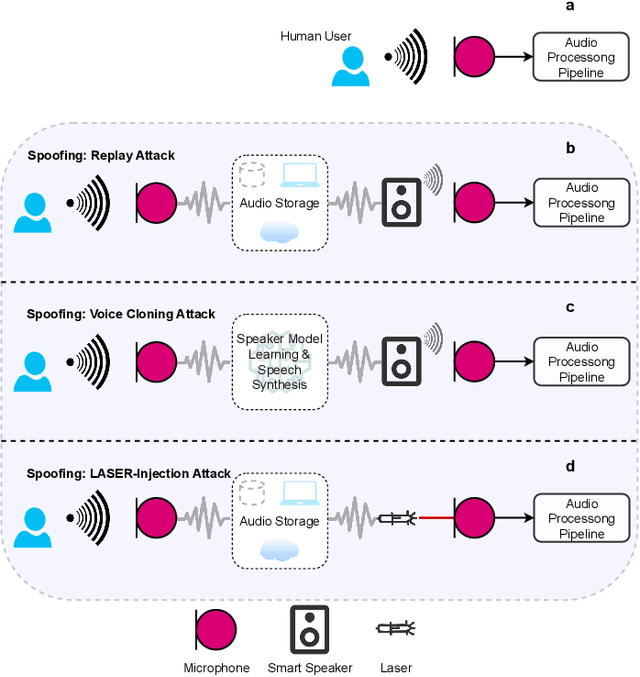
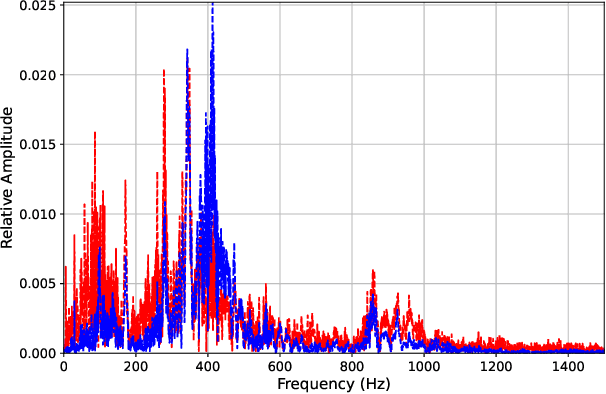
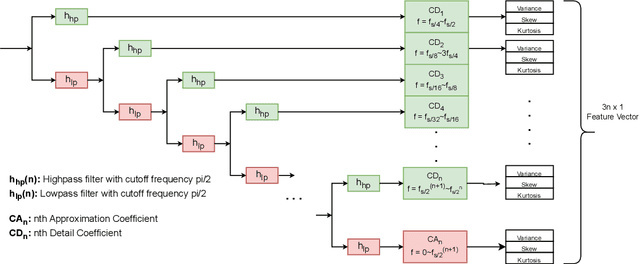
Voice-Controllable Devices (VCDs) have seen an increasing trend towards their adoption due to the small form factor of the MEMS microphones and their easy integration into modern gadgets. Recent studies have revealed that MEMS microphones are vulnerable to audio-modulated laser injection attacks. This paper aims to develop countermeasures to detect and prevent laser injection attacks on MEMS microphones. A time-frequency decomposition based on discrete wavelet transform (DWT) is employed to decompose microphone output audio signal into n + 1 frequency subbands to capture photo-acoustic related artifacts. Higher-order statistical features consisting of the first four moments of subband audio signals, e.g., variance, skew, and kurtosis are used to distinguish between acoustic and photo-acoustic responses. An SVM classifier is used to learn the underlying model that differentiates between an acoustic- and laser-induced (photo-acoustic) response in the MEMS microphone. The proposed framework is evaluated on a data set of 190 audios, consisting of 19 speakers. The experimental results indicate that the proposed framework is able to correctly classify $98\%$ of the acoustic- and laser-induced audio in a random data partition setting and $100\%$ of the audio in speaker-independent and text-independent data partition settings.
ADFactory: An Effective Framework for Generalizing Optical Flow with Nerf
Nov 14, 2023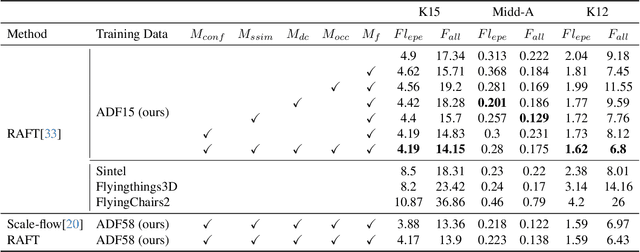
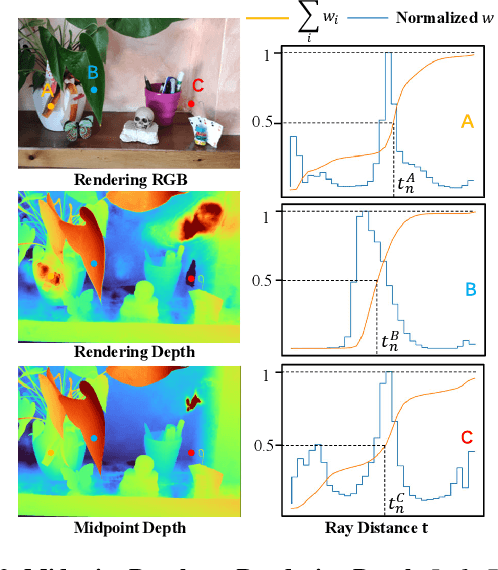
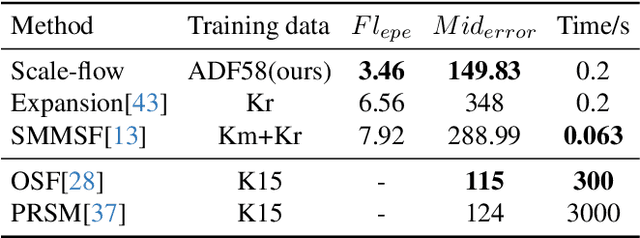
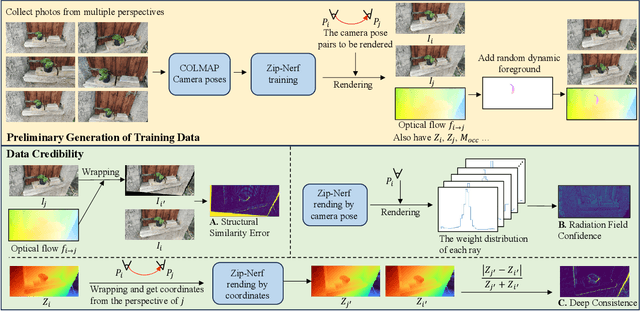
A significant challenge facing current optical flow methods is the difficulty in generalizing them well to the real world. This is mainly due to the high cost of hand-crafted datasets, and existing self-supervised methods are limited by indirect loss and occlusions, resulting in fuzzy outcomes. To address this challenge, we introduce a novel optical flow training framework: automatic data factory (ADF). ADF only requires RGB images as input to effectively train the optical flow network on the target data domain. Specifically, we use advanced Nerf technology to reconstruct scenes from photo groups collected by a monocular camera, and then calculate optical flow labels between camera pose pairs based on the rendering results. To eliminate erroneous labels caused by defects in the scene reconstructed by Nerf, we screened the generated labels from multiple aspects, such as optical flow matching accuracy, radiation field confidence, and depth consistency. The filtered labels can be directly used for network supervision. Experimentally, the generalization ability of ADF on KITTI surpasses existing self-supervised optical flow and monocular scene flow algorithms. In addition, ADF achieves impressive results in real-world zero-point generalization evaluations and surpasses most supervised methods.
RaceLens: A Machine Intelligence-Based Application for Racing Photo Analysis
Oct 20, 2023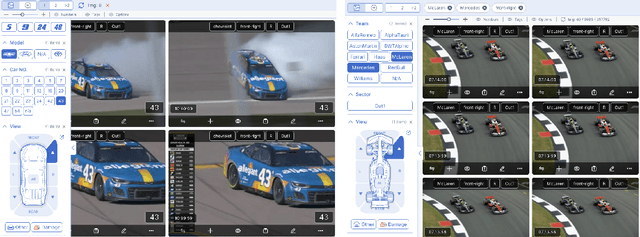
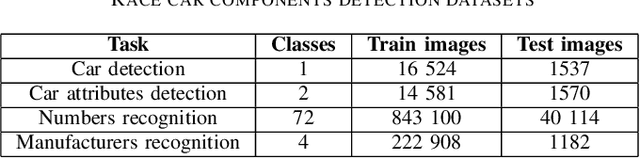
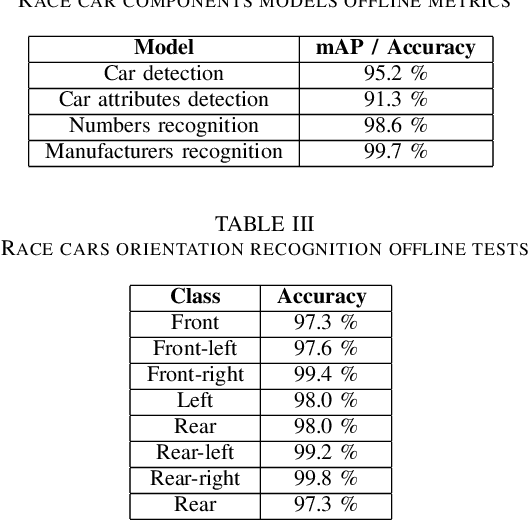
This paper presents RaceLens, a novel application utilizing advanced deep learning and computer vision models for comprehensive analysis of racing photos. The developed models have demonstrated their efficiency in a wide array of tasks, including detecting racing cars, recognizing car numbers, detecting and quantifying car details, and recognizing car orientations. We discuss the process of collecting a robust dataset necessary for training our models, and describe an approach we have designed to augment and improve this dataset continually. Our method leverages a feedback loop for continuous model improvement, thus enhancing the performance and accuracy of RaceLens over time. A significant part of our study is dedicated to illustrating the practical application of RaceLens, focusing on its successful deployment by NASCAR teams over four seasons. We provide a comprehensive evaluation of our system's performance and its direct impact on the team's strategic decisions and performance metrics. The results underscore the transformative potential of machine intelligence in the competitive and dynamic world of car racing, setting a precedent for future applications.
Optimal Image Transport on Sparse Dictionaries
Nov 03, 2023

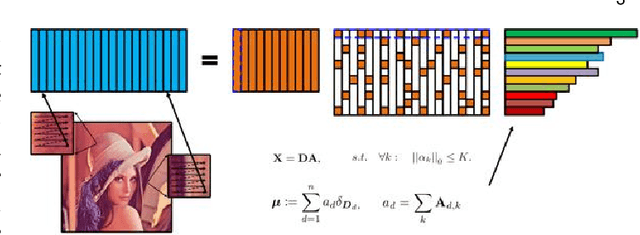
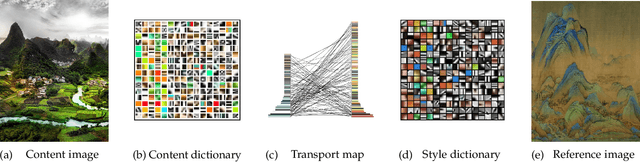
In this paper, we derive a novel optimal image transport algorithm over sparse dictionaries by taking advantage of Sparse Representation (SR) and Optimal Transport (OT). Concisely, we design a unified optimization framework in which the individual image features (color, textures, styles, etc.) are encoded using sparse representation compactly, and an optimal transport plan is then inferred between two learned dictionaries in accordance with the encoding process. This paradigm gives rise to a simple but effective way for simultaneous image representation and transformation, which is also empirically solvable because of the moderate size of sparse coding and optimal transport sub-problems. We demonstrate its versatility and many benefits to different image-to-image translation tasks, in particular image color transform and artistic style transfer, and show the plausible results for photo-realistic transferred effects.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
Automatic Photo Orientation Detection with Convolutional Neural Networks
May 17, 2023

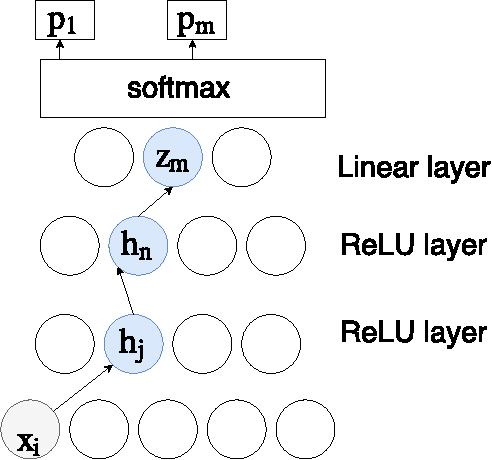

We apply convolutional neural networks (CNN) to the problem of image orientation detection in the context of determining the correct orientation (from 0, 90, 180, and 270 degrees) of a consumer photo. The problem is especially important for digitazing analog photographs. We substantially improve on the published state of the art in terms of the performance on one of the standard datasets, and test our system on a more difficult large dataset of consumer photos. We use Guided Backpropagation to obtain insights into how our CNN detects photo orientation, and to explain its mistakes.