 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Context-Based Music Recommendation Algorithm Evaluation
Dec 16, 2021
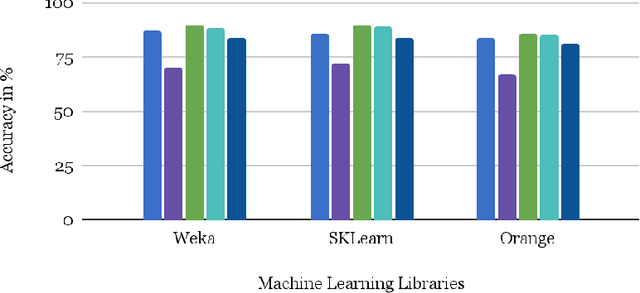
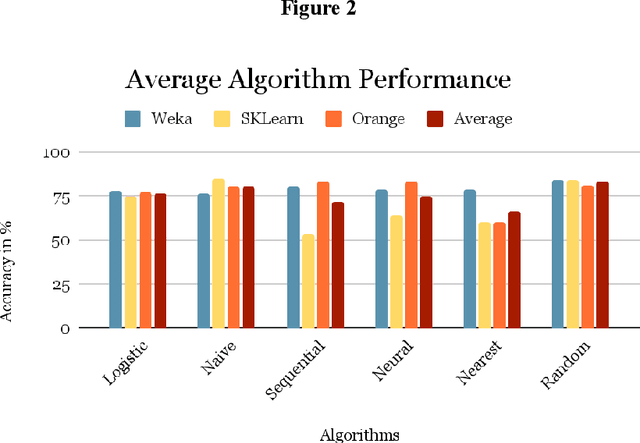
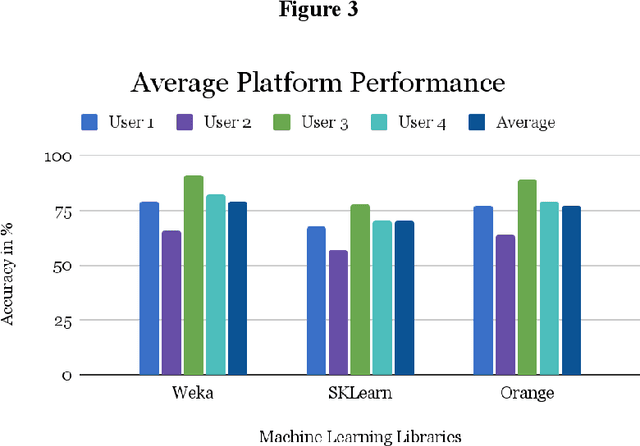
Artificial Intelligence (AI ) has been very successful in creating and predicting music playlists for online users based on their data; data received from users experience using the app such as searching the songs they like. There are lots of current technological advancements in AI due to the competition between music platform owners such as Spotify, Pandora, and more. In this paper, 6 machine learning algorithms and their individual accuracy for predicting whether a user will like a song are explored across 3 different platforms including Weka, SKLearn, and Orange. The algorithms explored include Logistic Regression, Naive Bayes, Sequential Minimal Optimization (SMO), Multilayer Perceptron (Neural Network), Nearest Neighbor, and Random Forest. With the analysis of the specific characteristics of each song provided by the Spotify API [1], Random Forest is the most successful algorithm for predicting whether a user will like a song with an accuracy of 84%. This is higher than the accuracy of 82.72% found by Mungekar using the Random Forest technique and slightly different characteristics of a song [2]. The characteristics in Mungekars Random Forest algorithm focus more on the artist and popularity rather than the sonic features of the songs. Removing the popularity aspect and focusing purely on the sonic qualities improve the accuracy of recommendations. Finally, this paper shows how song prediction can be accomplished without any monetary investments, and thus, inspires an idea of what amazing results can be accomplished with full financial research.
Region-based Layout Analysis of Music Score Images
Jan 11, 2022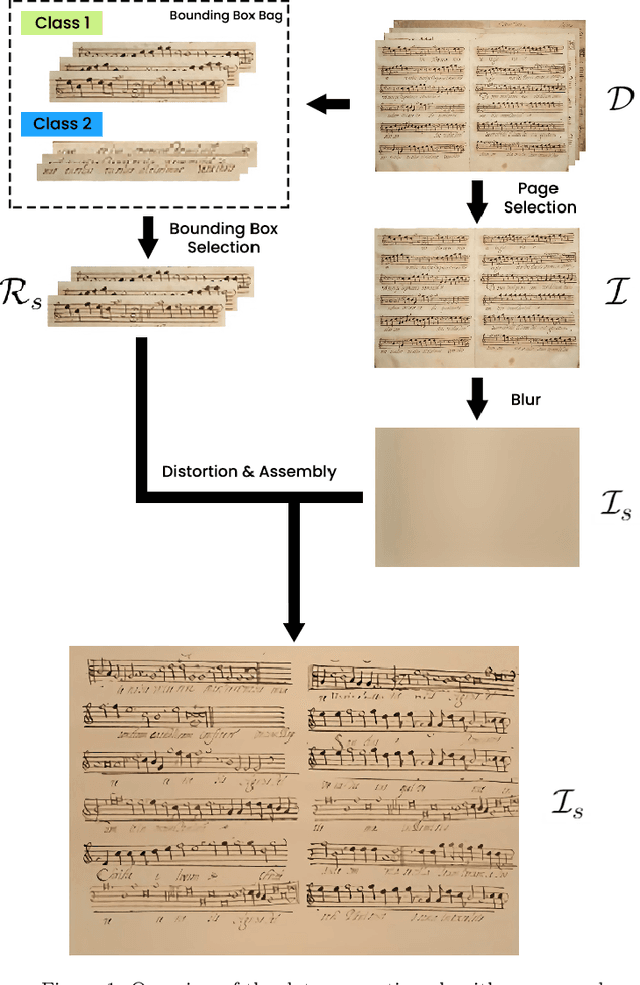
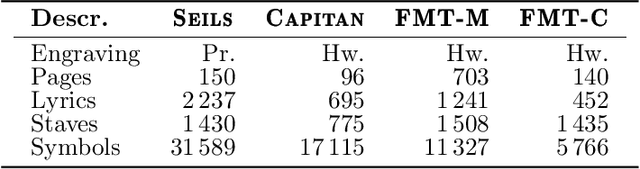

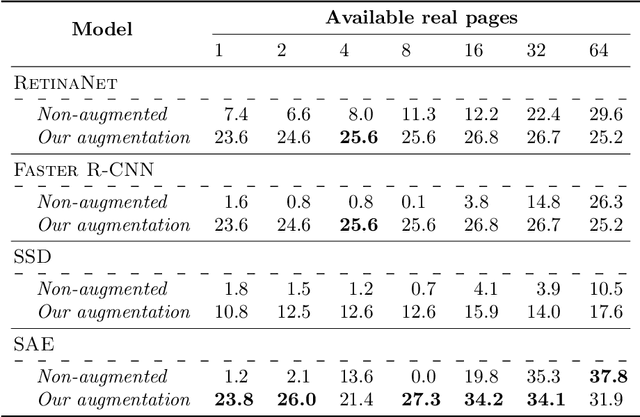
The Layout Analysis (LA) stage is of vital importance to the correct performance of an Optical Music Recognition (OMR) system. It identifies the regions of interest, such as staves or lyrics, which must then be processed in order to transcribe their content. Despite the existence of modern approaches based on deep learning, an exhaustive study of LA in OMR has not yet been carried out with regard to the precision of different models, their generalization to different domains or, more importantly, their impact on subsequent stages of the pipeline. This work focuses on filling this gap in literature by means of an experimental study of different neural architectures, music document types and evaluation scenarios. The need for training data has also led to a proposal for a new semi-synthetic data generation technique that enables the efficient applicability of LA approaches in real scenarios. Our results show that: (i) the choice of the model and its performance are crucial for the entire transcription process; (ii) the metrics commonly used to evaluate the LA stage do not always correlate with the final performance of the OMR system, and (iii) the proposed data-generation technique enables state-of-the-art results to be achieved with a limited set of labeled data.
Predicting emotion from music videos: exploring the relative contribution of visual and auditory information to affective responses
Feb 19, 2022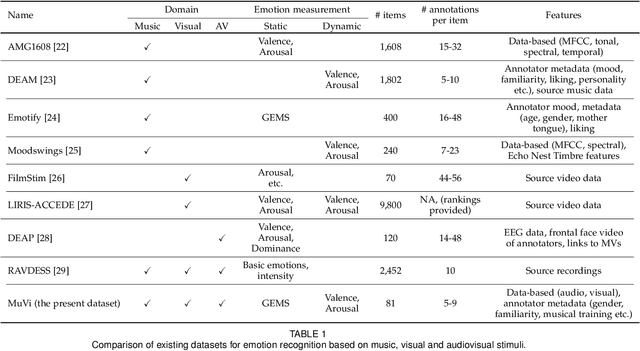

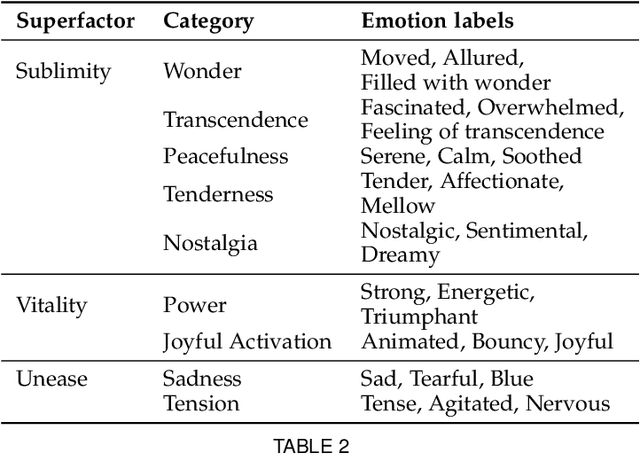
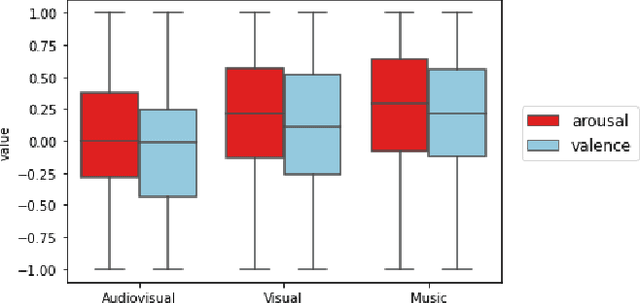
Although media content is increasingly produced, distributed, and consumed in multiple combinations of modalities, how individual modalities contribute to the perceived emotion of a media item remains poorly understood. In this paper we present MusicVideos (MuVi), a novel dataset for affective multimedia content analysis to study how the auditory and visual modalities contribute to the perceived emotion of media. The data were collected by presenting music videos to participants in three conditions: music, visual, and audiovisual. Participants annotated the music videos for valence and arousal over time, as well as the overall emotion conveyed. We present detailed descriptive statistics for key measures in the dataset and the results of feature importance analyses for each condition. Finally, we propose a novel transfer learning architecture to train Predictive models Augmented with Isolated modality Ratings (PAIR) and demonstrate the potential of isolated modality ratings for enhancing multimodal emotion recognition. Our results suggest that perceptions of arousal are influenced primarily by auditory information, while perceptions of valence are more subjective and can be influenced by both visual and auditory information. The dataset is made publicly available.
Efficiency 360: Efficient Vision Transformers
Feb 17, 2023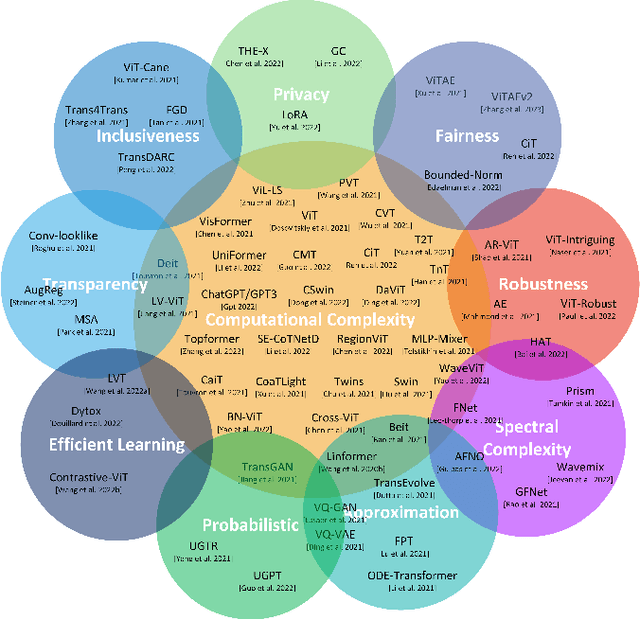
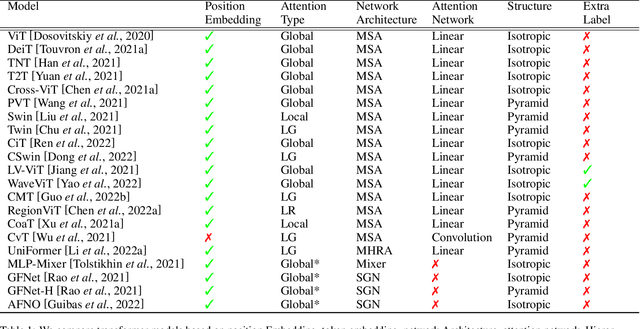
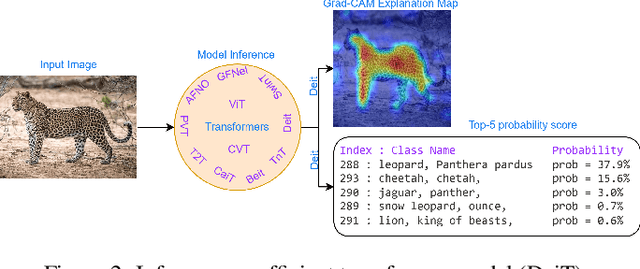
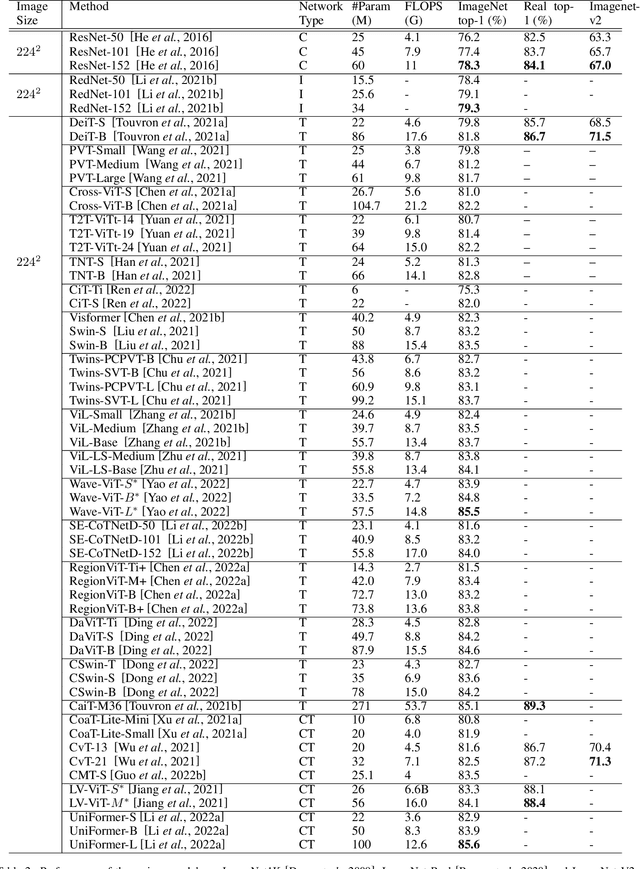
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
DanceIt: Music-inspired Dancing Video Synthesis
Sep 17, 2020
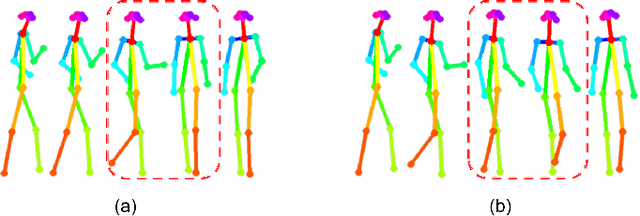
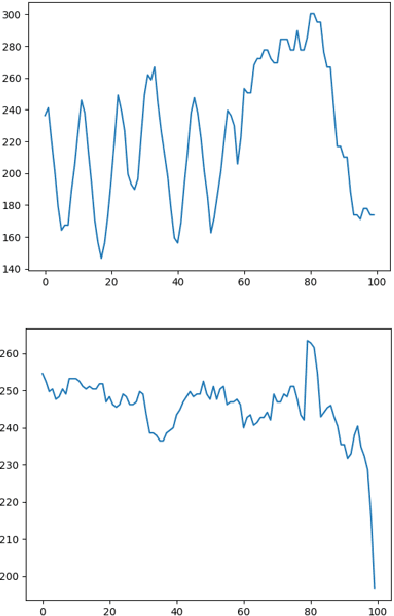
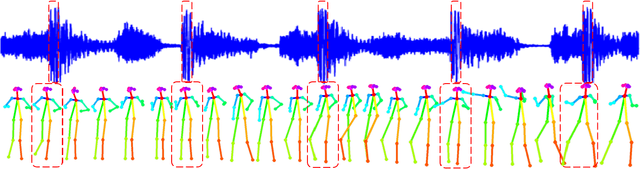
Close your eyes and listen to music, one can easily imagine an actor dancing rhythmically along with the music. These dance movements are usually made up of dance movements you have seen before. In this paper, we propose to reproduce such an inherent capability of the human-being within a computer vision system. The proposed system consists of three modules. To explore the relationship between music and dance movements, we propose a cross-modal alignment module that focuses on dancing video clips, accompanied on pre-designed music, to learn a system that can judge the consistency between the visual features of pose sequences and the acoustic features of music. The learned model is then used in the imagination module to select a pose sequence for the given music. Such pose sequence selected from the music, however, is usually discontinuous. To solve this problem, in the spatial-temporal alignment module we develop a spatial alignment algorithm based on the tendency and periodicity of dance movements to predict dance movements between discontinuous fragments. In addition, the selected pose sequence is often misaligned with the music beat. To solve this problem, we further develop a temporal alignment algorithm to align the rhythm of music and dance. Finally, the processed pose sequence is used to synthesize realistic dancing videos in the imagination module. The generated dancing videos match the content and rhythm of the music. Experimental results and subjective evaluations show that the proposed approach can perform the function of generating promising dancing videos by inputting music.
OK Computer Analysis: An Audio Corpus Study of Radiohead
Nov 29, 2022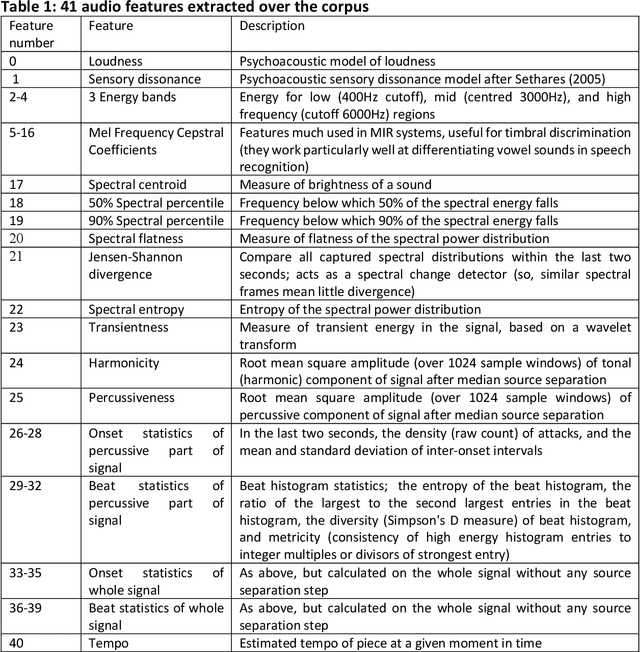
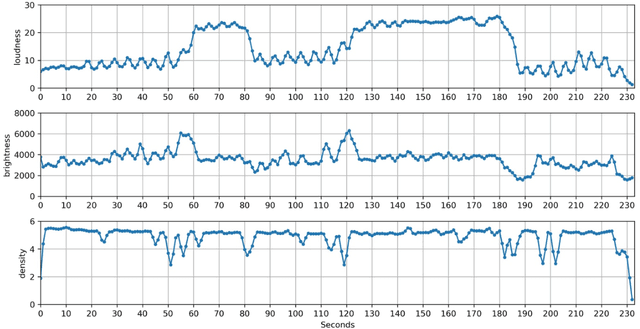
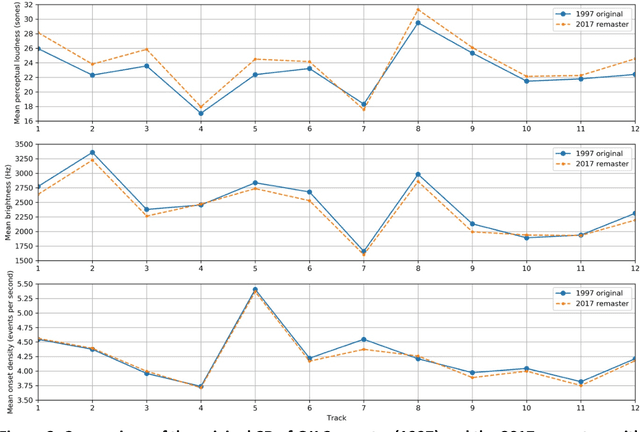
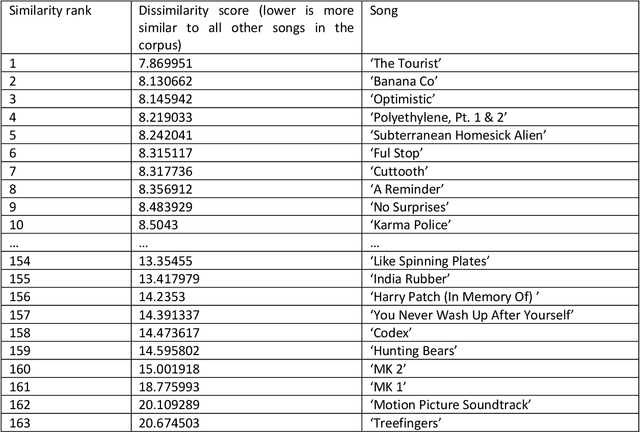
The application of music information retrieval techniques in popular music studies has great promise. In the present work, a corpus of Radiohead songs across their career from 1992 to 2017 are subjected to automated audio analysis. We examine findings from a number of granularities and perspectives, including within song and between song examination of both timbral-rhythmic and harmonic features. Chronological changes include possible career spanning effects for a band's releases such as slowing tempi and reduced brightness, and the timbral markers of Radiohead's expanding approach to instrumental resources most identified with the Kid A and Amnesiac era. We conclude with a discussion highlighting some challenges for this approach, and the potential for a field of audio file based career analysis.
Transformer-based approach towards music emotion recognition from lyrics
Jan 06, 2021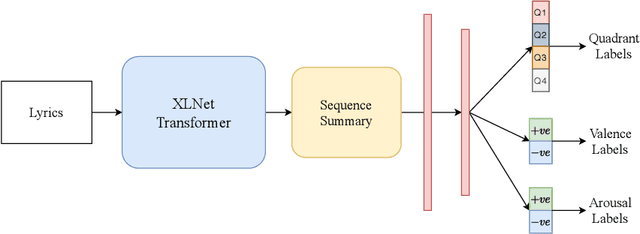

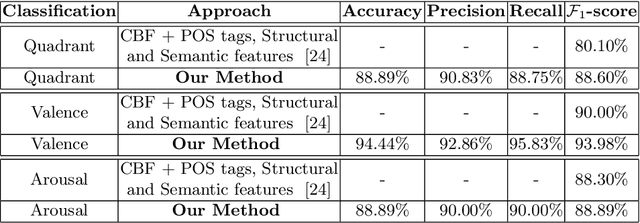
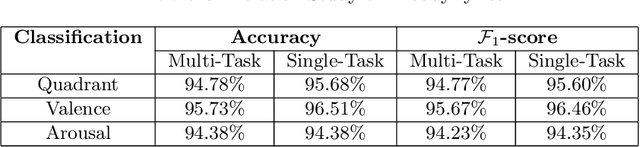
The task of identifying emotions from a given music track has been an active pursuit in the Music Information Retrieval (MIR) community for years. Music emotion recognition has typically relied on acoustic features, social tags, and other metadata to identify and classify music emotions. The role of lyrics in music emotion recognition remains under-appreciated in spite of several studies reporting superior performance of music emotion classifiers based on features extracted from lyrics. In this study, we use the transformer-based approach model using XLNet as the base architecture which, till date, has not been used to identify emotional connotations of music based on lyrics. Our proposed approach outperforms existing methods for multiple datasets. We used a robust methodology to enhance web-crawlers' accuracy for extracting lyrics. This study has important implications in improving applications involved in playlist generation of music based on emotions in addition to improving music recommendation systems.
Regeneration Learning: A Learning Paradigm for Data Generation
Jan 21, 2023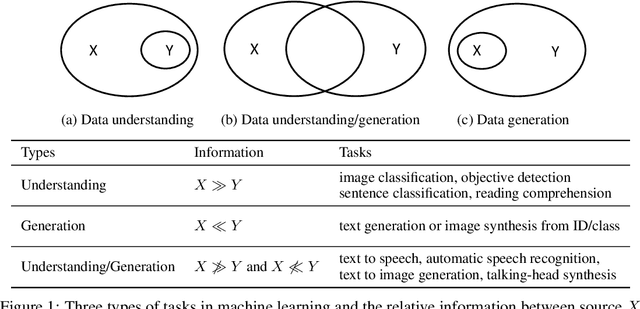
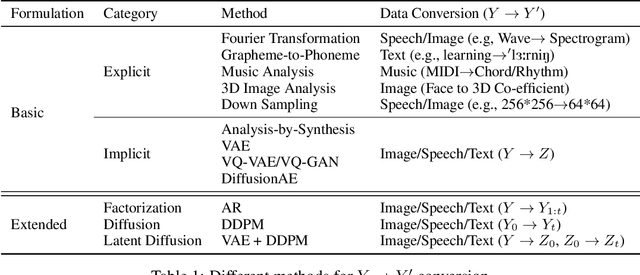


Machine learning methods for conditional data generation usually build a mapping from source conditional data X to target data Y. The target Y (e.g., text, speech, music, image, video) is usually high-dimensional and complex, and contains information that does not exist in source data, which hinders effective and efficient learning on the source-target mapping. In this paper, we present a learning paradigm called regeneration learning for data generation, which first generates Y' (an abstraction/representation of Y) from X and then generates Y from Y'. During training, Y' is obtained from Y through either handcrafted rules or self-supervised learning and is used to learn X-->Y' and Y'-->Y. Regeneration learning extends the concept of representation learning to data generation tasks, and can be regarded as a counterpart of traditional representation learning, since 1) regeneration learning handles the abstraction (Y') of the target data Y for data generation while traditional representation learning handles the abstraction (X') of source data X for data understanding; 2) both the processes of Y'-->Y in regeneration learning and X-->X' in representation learning can be learned in a self-supervised way (e.g., pre-training); 3) both the mappings from X to Y' in regeneration learning and from X' to Y in representation learning are simpler than the direct mapping from X to Y. We show that regeneration learning can be a widely-used paradigm for data generation (e.g., text generation, speech recognition, speech synthesis, music composition, image generation, and video generation) and can provide valuable insights into developing data generation methods.
Revealing Preference in Popular Music Through Familiarity and Brain Response
Jan 30, 2021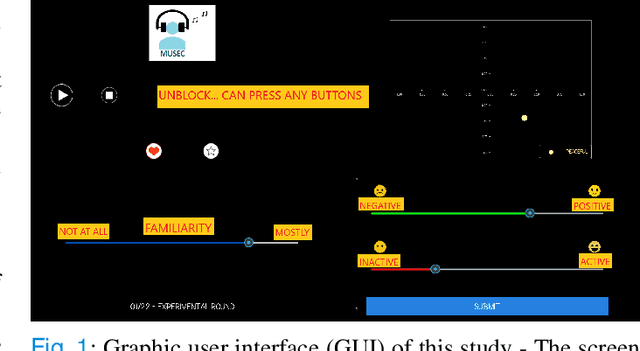
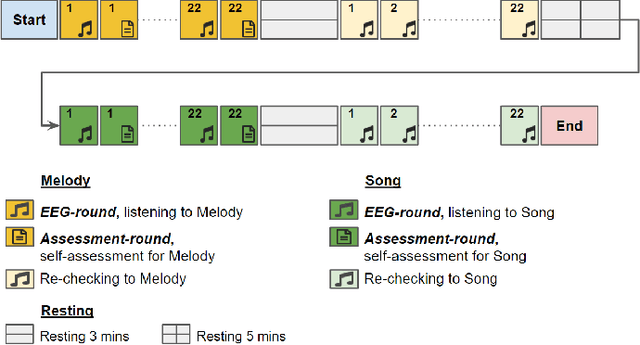
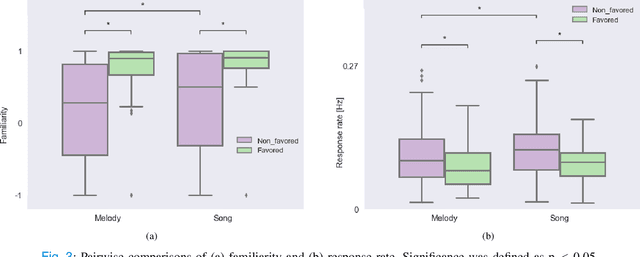
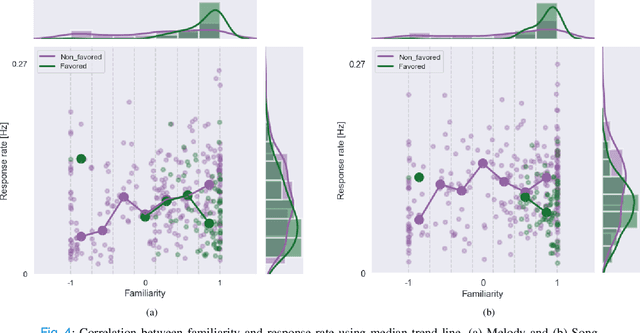
Music preference was reported as a factor, which could elicit innermost music emotion, entailing accurate ground-truth data and music therapy efficiency. This study executes statistical analysis to investigate the distinction of music preference through familiarity scores, response times (response rates), and brain response (EEG). Twenty participants did self-assessment after listening to two types of popular music's chorus section: music without lyrics (Melody) and music with lyrics (Song). We then conduct a music preference classification using a support vector machine (SVM) with the familiarity scores, the response rates, and EEG as the feature vectors. The statistical analysis and SVM's F1-score of EEG are congruent, which is the brain's right side outperformed its left side in classification performance. Finally, these behavioral and brain studies support that preference, familiarity, and response rates can contribute to the music emotion experiment's design to understand music, emotion, and listener. Not only to the music industry, the biomedical, and healthcare industry can also exploit this experiment to collect data from patients to improve the efficiency of healing by music.
Learning source-aware representations of music in a discrete latent space
Nov 26, 2021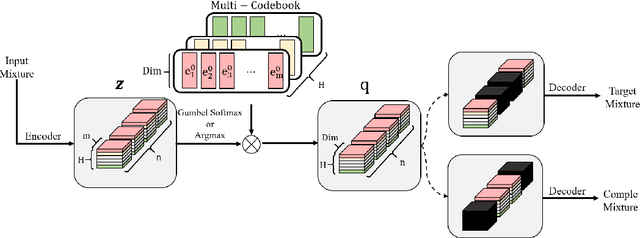
In recent years, neural network based methods have been proposed as a method that cangenerate representations from music, but they are not human readable and hardly analyzable oreditable by a human. To address this issue, we propose a novel method to learn source-awarelatent representations of music through Vector-Quantized Variational Auto-Encoder(VQ-VAE).We train our VQ-VAE to encode an input mixture into a tensor of integers in a discrete latentspace, and design them to have a decomposed structure which allows humans to manipulatethe latent vector in a source-aware manner. This paper also shows that we can generate basslines by estimating latent vectors in a discrete space.