 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Discovery Dynamics: Leveraging Repeated Exposure for User and Music Characterization
Oct 28, 2022
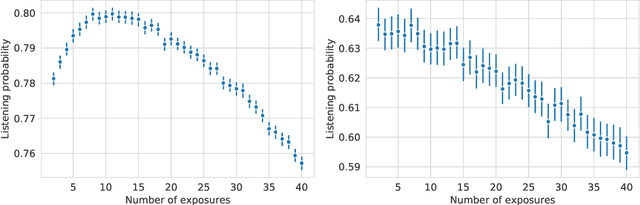
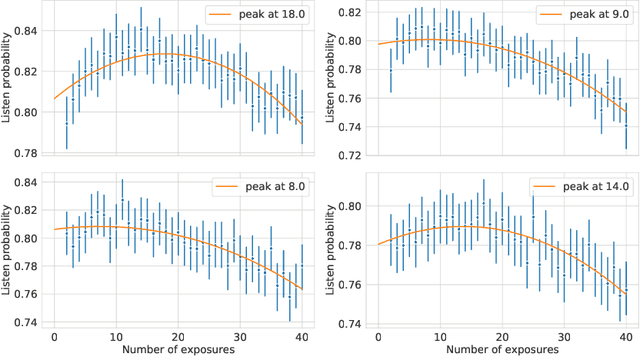
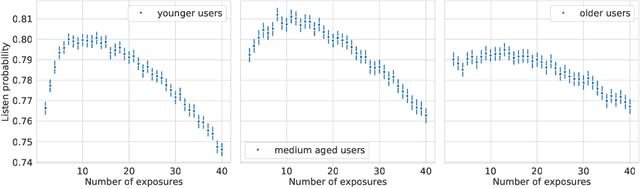
Repetition in music consumption is a common phenomenon. It is notably more frequent when compared to the consumption of other media, such as books and movies. In this paper, we show that one particularly interesting repetitive behavior arises when users are consuming new items. Users' interest tends to rise with the first repetitions and attains a peak after which interest will decrease with subsequent exposures, resulting in an inverted-U shape. This behavior, which has been extensively studied in psychology, is called the mere exposure effect. In this paper, we show how a number of factors, both content and user-based, well documented in the literature on the mere exposure effect, modulate the magnitude of the effect. Due to the vast availability of data of users discovering new songs everyday in music streaming platforms, these findings enable new ways to characterize both the music, users and their relationships. Ultimately, it opens up the possibility of developing new recommender systems paradigms based on these characterizations.
Combining piano performance dimensions for score difficulty classification
Jun 14, 2023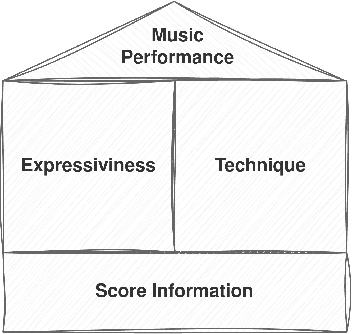

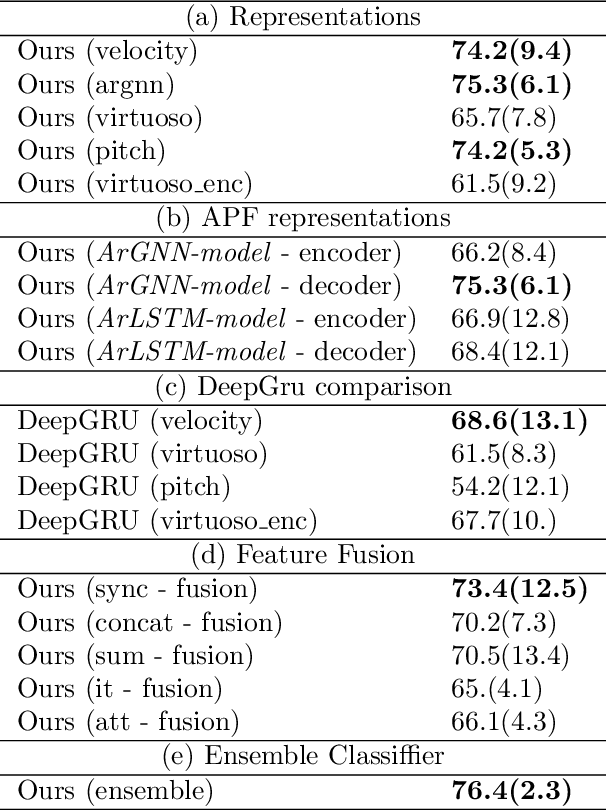
Predicting the difficulty of playing a musical score is essential for structuring and exploring score collections. Despite its importance for music education, the automatic difficulty classification of piano scores is not yet solved, mainly due to the lack of annotated data and the subjectiveness of the annotations. This paper aims to advance the state-of-the-art in score difficulty classification with two major contributions. To address the lack of data, we present Can I Play It? (CIPI) dataset, a machine-readable piano score dataset with difficulty annotations obtained from the renowned classical music publisher Henle Verlag. The dataset is created by matching public domain scores with difficulty labels from Henle Verlag, then reviewed and corrected by an expert pianist. As a second contribution, we explore various input representations from score information to pre-trained ML models for piano fingering and expressiveness inspired by the musicology definition of performance. We show that combining the outputs of multiple classifiers performs better than the classifiers on their own, pointing to the fact that the representations capture different aspects of difficulty. In addition, we conduct numerous experiments that lay a foundation for score difficulty classification and create a basis for future research. Our best-performing model reports a 39.47% balanced accuracy and 1.13 median square error across the nine difficulty levels proposed in this study. Code, dataset, and models are made available for reproducibility.
Multi-Source Diffusion Models for Simultaneous Music Generation and Separation
Feb 07, 2023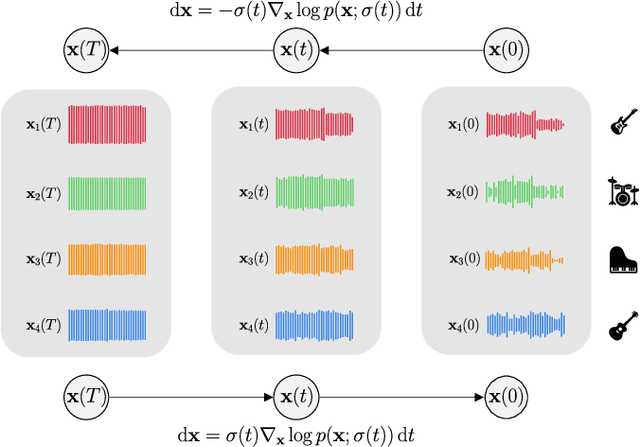

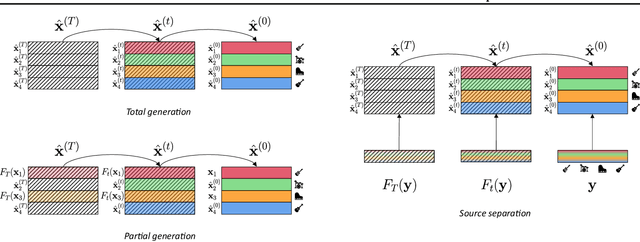
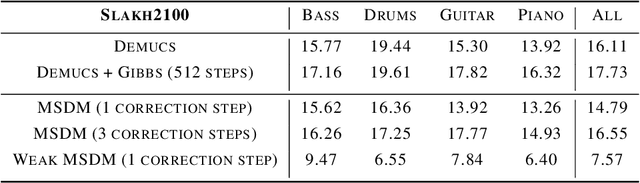
In this work, we define a diffusion-based generative model capable of both music synthesis and source separation by learning the score of the joint probability density of sources sharing a context. Alongside the classic total inference tasks (i.e. generating a mixture, separating the sources), we also introduce and experiment on the partial inference task of source imputation, where we generate a subset of the sources given the others (e.g., play a piano track that goes well with the drums). Additionally, we introduce a novel inference method for the separation task. We train our model on Slakh2100, a standard dataset for musical source separation, provide qualitative results in the generation settings, and showcase competitive quantitative results in the separation setting. Our method is the first example of a single model that can handle both generation and separation tasks, thus representing a step toward general audio models.
Music Source Separation with Band-split RNN
Sep 30, 2022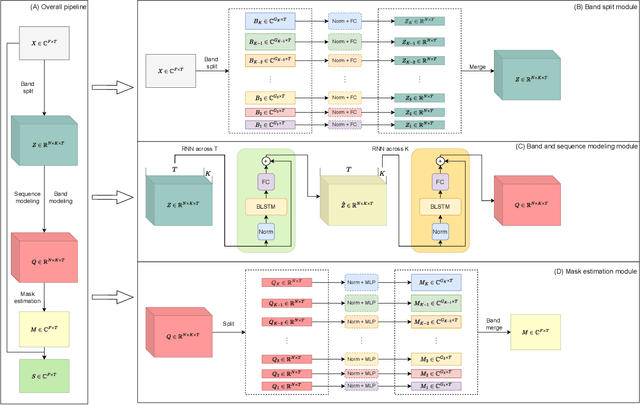
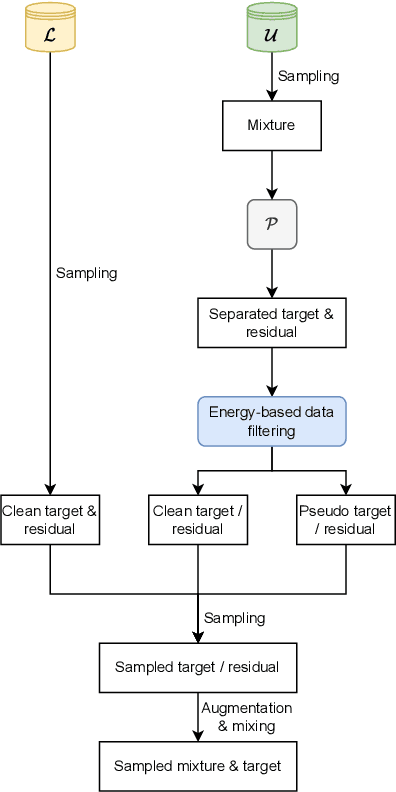

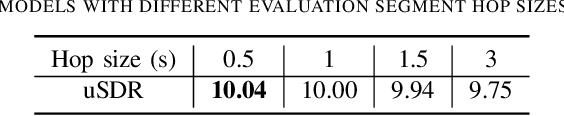
The performance of music source separation (MSS) models has been greatly improved in recent years thanks to the development of novel neural network architectures and training pipelines. However, recent model designs for MSS were mainly motivated by other audio processing tasks or other research fields, while the intrinsic characteristics and patterns of the music signals were not fully discovered. In this paper, we propose band-split RNN (BSRNN), a frequency-domain model that explictly splits the spectrogram of the mixture into subbands and perform interleaved band-level and sequence-level modeling. The choices of the bandwidths of the subbands can be determined by a priori knowledge or expert knowledge on the characteristics of the target source in order to optimize the performance on a certain type of target musical instrument. To better make use of unlabeled data, we also describe a semi-supervised model finetuning pipeline that can further improve the performance of the model. Experiment results show that BSRNN trained only on MUSDB18-HQ dataset significantly outperforms several top-ranking models in Music Demixing (MDX) Challenge 2021, and the semi-supervised finetuning stage further improves the performance on all four instrument tracks.
Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training
Feb 02, 2023
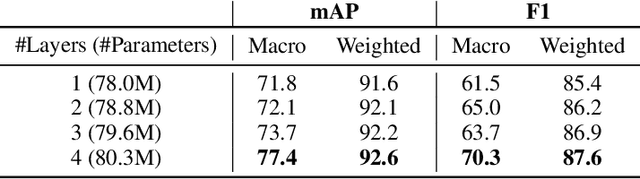
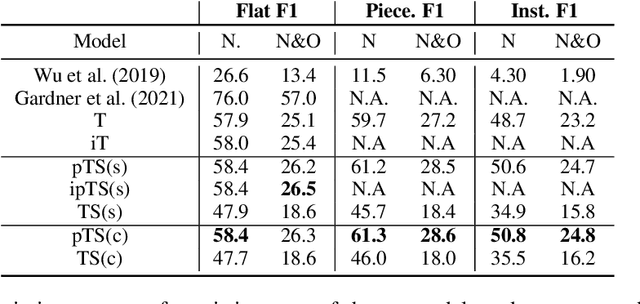
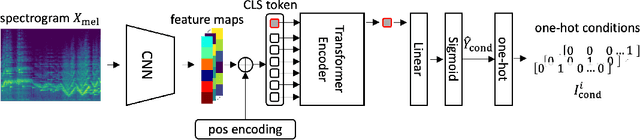
In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of an instrument recognition module that conditions the other two modules: a transcription module that outputs instrument-specific piano rolls, and a source separation module that utilizes instrument information and transcription results. The joint training of the transcription and source separation modules serves to improve the performance of both tasks. The instrument module is optional and can be directly controlled by human users. This makes Jointist a flexible user-controllable framework. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. Its novelty, however, necessitates a new perspective on how to evaluate such a model. In our experiments, we assess the proposed model from various aspects, providing a new evaluation perspective for multi-instrument transcription. Our subjective listening study shows that Jointist achieves state-of-the-art performance on popular music, outperforming existing multi-instrument transcription models such as MT3. We conducted experiments on several downstream tasks and found that the proposed method improved transcription by more than 1 percentage points (ppt.), source separation by 5 SDR, downbeat detection by 1.8 ppt., chord recognition by 1.4 ppt., and key estimation by 1.4 ppt., when utilizing transcription results obtained from Jointist. Demo available at \url{https://jointist.github.io/Demo}.
An Comparative Analysis of Different Pitch and Metrical Grid Encoding Methods in the Task of Sequential Music Generation
Jan 31, 2023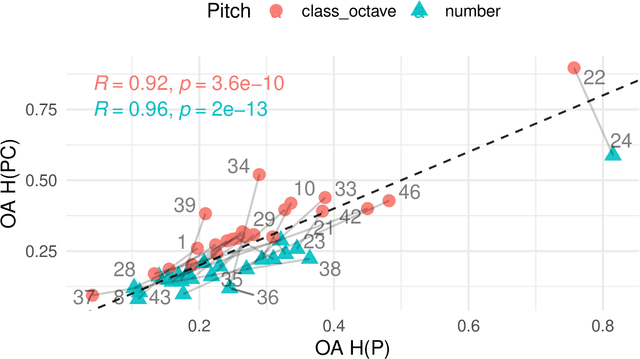
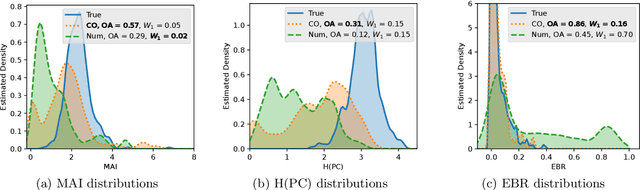

Pitch and meter are two fundamental music features for symbolic music generation tasks, where researchers usually choose different encoding methods depending on specific goals. However, the advantages and drawbacks of different encoding methods have not been frequently discussed. This paper presents a integrated analysis of the influence of two low-level feature, pitch and meter, on the performance of a token-based sequential music generation model. First, the commonly used MIDI number encoding and a less used class-octave encoding are compared. Second, an dense intra-bar metric grid is imposed to the encoded sequence as auxiliary features. Different complexity and resolutions of the metric grid are compared. For complexity, the single token approach and the multiple token approach are compared; for grid resolution, 0 (ablation), 1 (bar-level), 4 (downbeat-level) 12, (8th-triplet-level) up to 64 (64th-note-grid-level) are compared; for duration resolution, 4, 8, 12 and 16 subdivisions per beat are compared. All different encodings are tested on separately trained Transformer-XL models for a melody generation task. Regarding distribution similarity of several objective evaluation metrics to the test dataset, results suggest that the class-octave encoding significantly outperforms the taken-for-granted MIDI encoding on pitch-related metrics; finer grids and multiple-token grids improve the rhythmic quality, but also suffer from over-fitting at early training stage. Results display a general phenomenon of over-fitting from two aspects, the pitch embedding space and the test loss of the single-token grid encoding. From a practical perspective, we both demonstrate the feasibility and raise the concern of easy over-fitting problem of using smaller networks and lower embedding dimensions on the generation task. The findings can also contribute to futural models in terms of feature engineering.
Music Separation Enhancement with Generative Modeling
Aug 26, 2022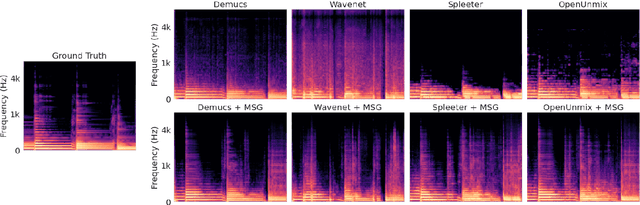
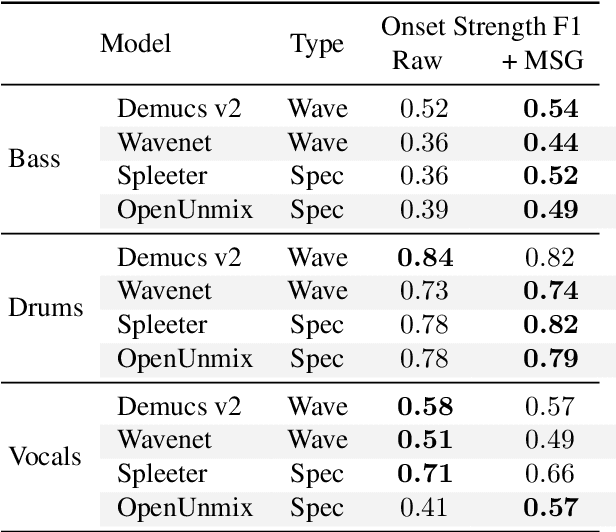
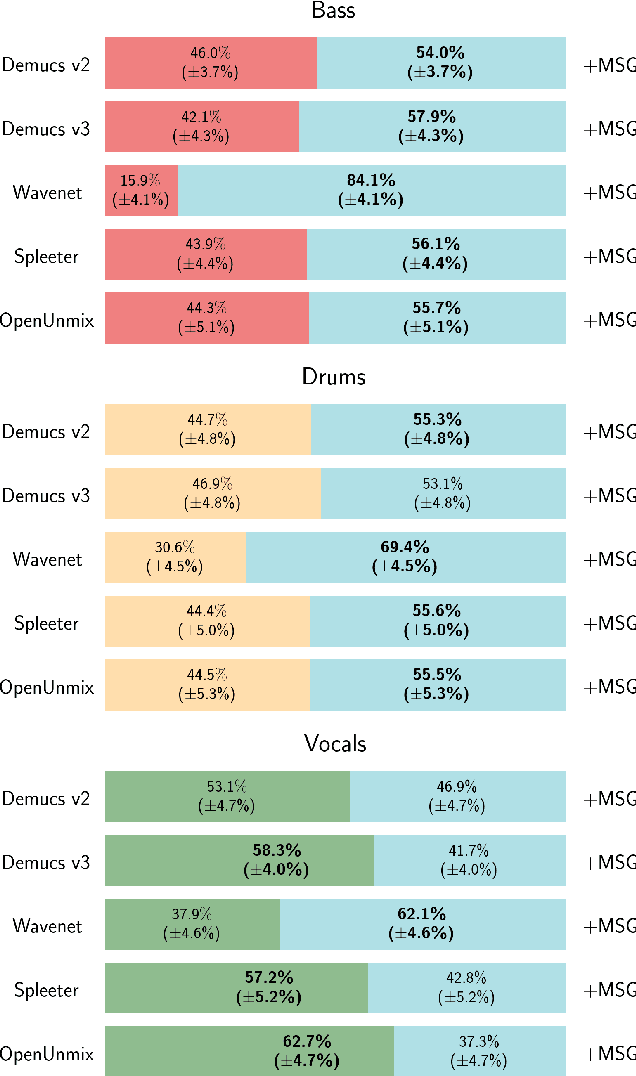
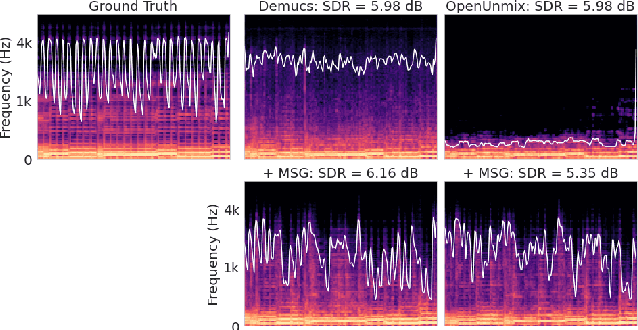
Despite phenomenal progress in recent years, state-of-the-art music separation systems produce source estimates with significant perceptual shortcomings, such as adding extraneous noise or removing harmonics. We propose a post-processing model (the Make it Sound Good (MSG) post-processor) to enhance the output of music source separation systems. We apply our post-processing model to state-of-the-art waveform-based and spectrogram-based music source separators, including a separator unseen by MSG during training. Our analysis of the errors produced by source separators shows that waveform models tend to introduce more high-frequency noise, while spectrogram models tend to lose transients and high frequency content. We introduce objective measures to quantify both kinds of errors and show MSG improves the source reconstruction of both kinds of errors. Crowdsourced subjective evaluations demonstrate that human listeners prefer source estimates of bass and drums that have been post-processed by MSG.
Automatic Piano Transcription with Hierarchical Frequency-Time Transformer
Jul 10, 2023

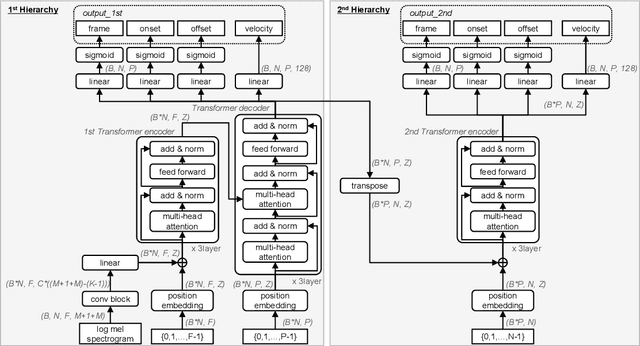
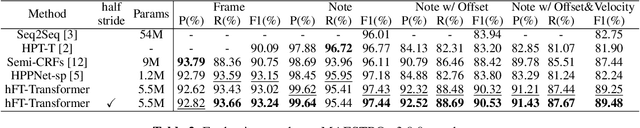
Taking long-term spectral and temporal dependencies into account is essential for automatic piano transcription. This is especially helpful when determining the precise onset and offset for each note in the polyphonic piano content. In this case, we may rely on the capability of self-attention mechanism in Transformers to capture these long-term dependencies in the frequency and time axes. In this work, we propose hFT-Transformer, which is an automatic music transcription method that uses a two-level hierarchical frequency-time Transformer architecture. The first hierarchy includes a convolutional block in the time axis, a Transformer encoder in the frequency axis, and a Transformer decoder that converts the dimension in the frequency axis. The output is then fed into the second hierarchy which consists of another Transformer encoder in the time axis. We evaluated our method with the widely used MAPS and MAESTRO v3.0.0 datasets, and it demonstrated state-of-the-art performance on all the F1-scores of the metrics among Frame, Note, Note with Offset, and Note with Offset and Velocity estimations.
Fitting Auditory Filterbanks with Multiresolution Neural Networks
Jul 25, 2023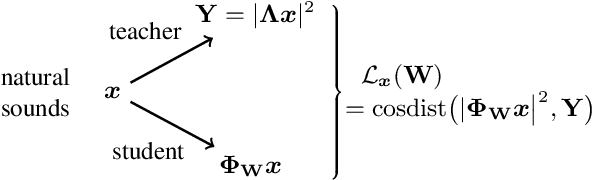


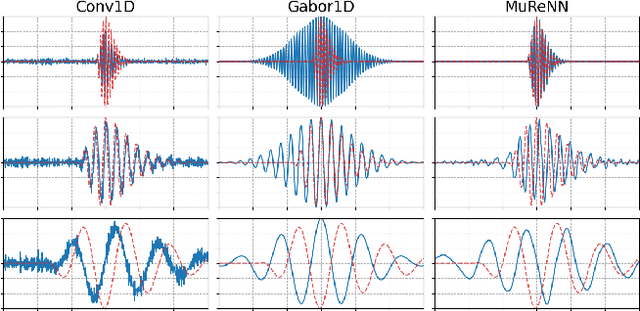
Waveform-based deep learning faces a dilemma between nonparametric and parametric approaches. On one hand, convolutional neural networks (convnets) may approximate any linear time-invariant system; yet, in practice, their frequency responses become more irregular as their receptive fields grow. On the other hand, a parametric model such as LEAF is guaranteed to yield Gabor filters, hence an optimal time-frequency localization; yet, this strong inductive bias comes at the detriment of representational capacity. In this paper, we aim to overcome this dilemma by introducing a neural audio model, named multiresolution neural network (MuReNN). The key idea behind MuReNN is to train separate convolutional operators over the octave subbands of a discrete wavelet transform (DWT). Since the scale of DWT atoms grows exponentially between octaves, the receptive fields of the subsequent learnable convolutions in MuReNN are dilated accordingly. For a given real-world dataset, we fit the magnitude response of MuReNN to that of a well-established auditory filterbank: Gammatone for speech, CQT for music, and third-octave for urban sounds, respectively. This is a form of knowledge distillation (KD), in which the filterbank ''teacher'' is engineered by domain knowledge while the neural network ''student'' is optimized from data. We compare MuReNN to the state of the art in terms of goodness of fit after KD on a hold-out set and in terms of Heisenberg time-frequency localization. Compared to convnets and Gabor convolutions, we find that MuReNN reaches state-of-the-art performance on all three optimization problems.