 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Phase Repair for Time-Domain Convolutional Neural Networks in Music Super-Resolution
Jun 20, 2023
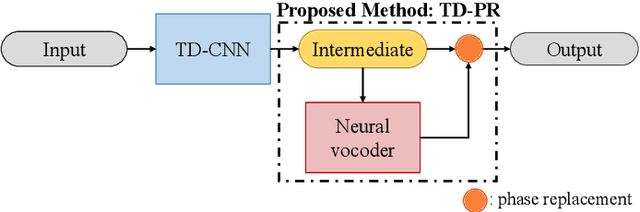
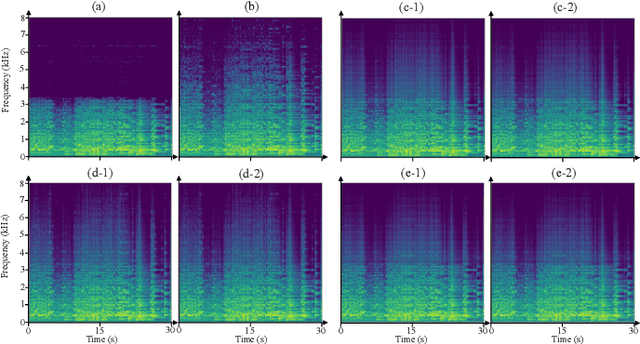
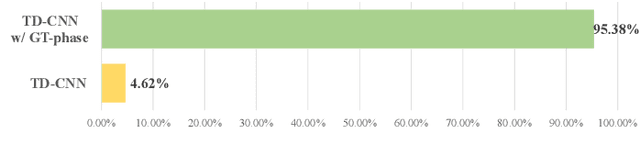
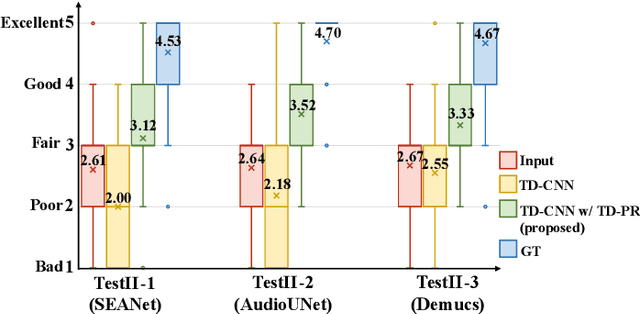
Audio Super-Resolution (SR) is an important topic in the field of audio processing. Many models are designed in time domain due to the advantage of waveform processing, such as being able to avoid the phase problem. However, in prior works it is shown that Time-Domain Convolutional Neural Network (TD-CNN) approaches tend to produce annoying artifacts in their output. In order to confirm the source of the artifact, we conduct an AB listening test and found phase to be the cause. We further propose Time-Domain Phase Repair (TD-PR) to improve TD-CNNs' performance by repairing the phase of the TD-CNNs' output. In this paper, we focus on the music SR task, which is challenging due to the wide frequency response and dynamic range of music. Our proposed method can handle various narrow-bandwidth from 2.5kHz to 4kHz with a target bandwidth of 8kHz. We conduct both objective and subjective evaluation to assess the proposed method. The objective evaluation result indicates the proposed method achieves the SR task effectively. Moreover, the proposed TD-PR obtains the much higher mean opinion scores than all TD-CNN baselines, which indicates that the proposed TD-PR significantly improves perceptual quality. Samples are available on the demo page.
VMCML: Video and Music Matching via Cross-Modality Lifting
Mar 22, 2023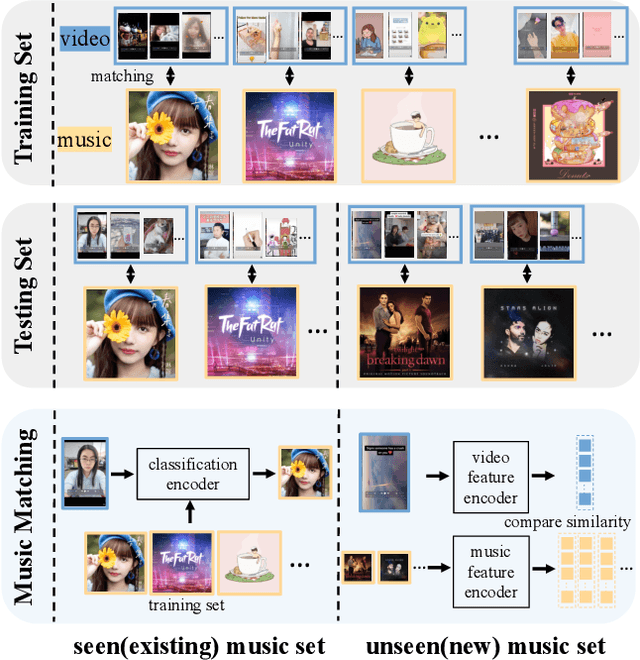

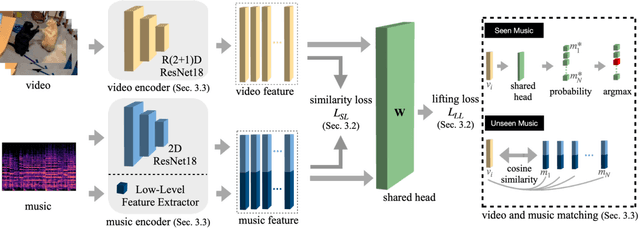

We propose a content-based system for matching video and background music. The system aims to address the challenges in music recommendation for new users or new music give short-form videos. To this end, we propose a cross-modal framework VMCML that finds a shared embedding space between video and music representations. To ensure the embedding space can be effectively shared by both representations, we leverage CosFace loss based on margin-based cosine similarity loss. Furthermore, we establish a large-scale dataset called MSVD, in which we provide 390 individual music and the corresponding matched 150,000 videos. We conduct extensive experiments on Youtube-8M and our MSVD datasets. Our quantitative and qualitative results demonstrate the effectiveness of our proposed framework and achieve state-of-the-art video and music matching performance.
AudioSR: Versatile Audio Super-resolution at Scale
Sep 13, 2023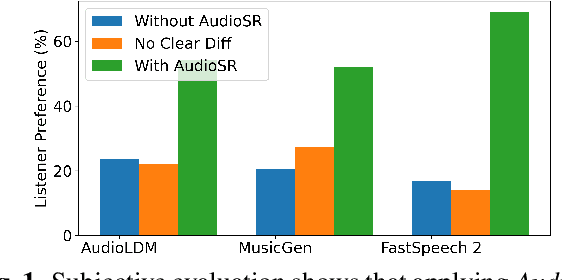

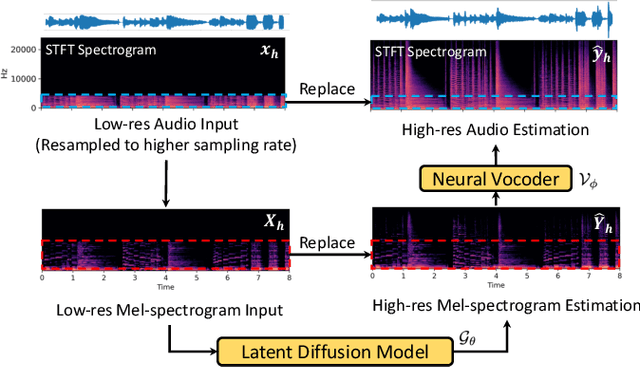

Audio super-resolution is a fundamental task that predicts high-frequency components for low-resolution audio, enhancing audio quality in digital applications. Previous methods have limitations such as the limited scope of audio types (e.g., music, speech) and specific bandwidth settings they can handle (e.g., 4kHz to 8kHz). In this paper, we introduce a diffusion-based generative model, AudioSR, that is capable of performing robust audio super-resolution on versatile audio types, including sound effects, music, and speech. Specifically, AudioSR can upsample any input audio signal within the bandwidth range of 2kHz to 16kHz to a high-resolution audio signal at 24kHz bandwidth with a sampling rate of 48kHz. Extensive objective evaluation on various audio super-resolution benchmarks demonstrates the strong result achieved by the proposed model. In addition, our subjective evaluation shows that AudioSR can acts as a plug-and-play module to enhance the generation quality of a wide range of audio generative models, including AudioLDM, Fastspeech2, and MusicGen. Our code and demo are available at https://audioldm.github.io/audiosr.
Adapting Meter Tracking Models to Latin American Music
Apr 14, 2023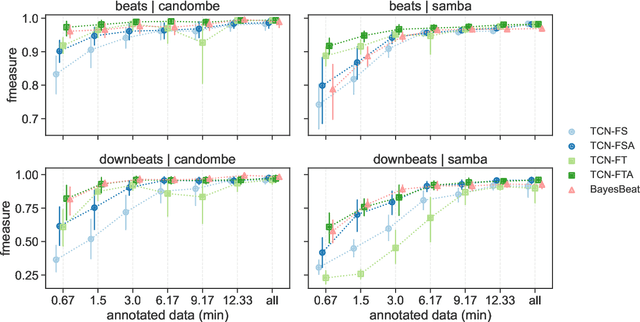

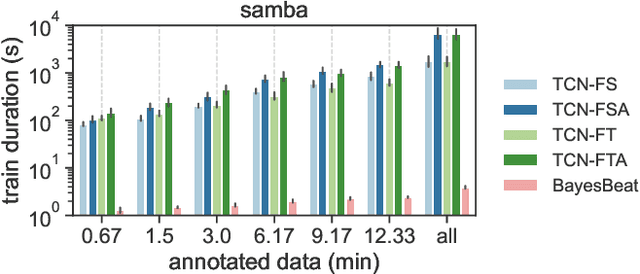
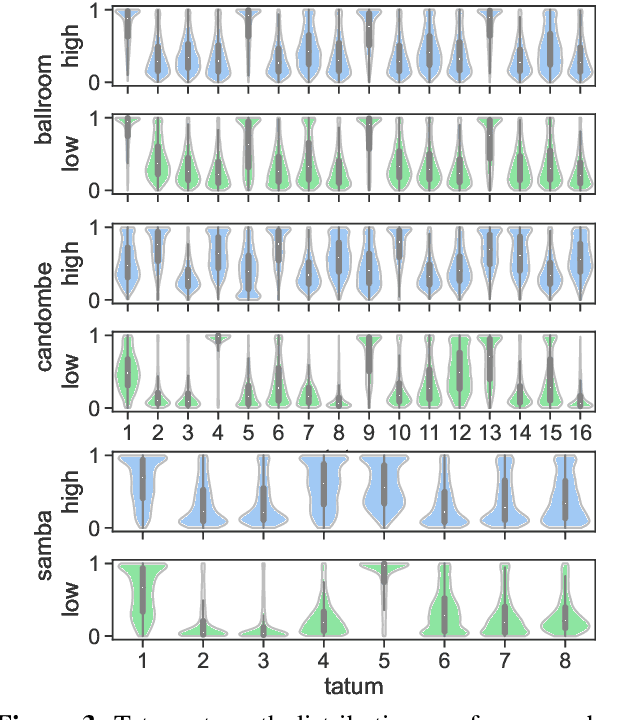
Beat and downbeat tracking models have improved significantly in recent years with the introduction of deep learning methods. However, despite these improvements, several challenges remain. Particularly, the adaptation of available models to underrepresented music traditions in MIR is usually synonymous with collecting and annotating large amounts of data, which is impractical and time-consuming. Transfer learning, data augmentation, and fine-tuning techniques have been used quite successfully in related tasks and are known to alleviate this bottleneck. Furthermore, when studying these music traditions, models are not required to generalize to multiple mainstream music genres but to perform well in more constrained, homogeneous conditions. In this work, we investigate simple yet effective strategies to adapt beat and downbeat tracking models to two different Latin American music traditions and analyze the feasibility of these adaptations in real-world applications concerning the data and computational requirements. Contrary to common belief, our findings show it is possible to achieve good performance by spending just a few minutes annotating a portion of the data and training a model in a standard CPU machine, with the precise amount of resources needed depending on the task and the complexity of the dataset.
Pre-Training Strategies Using Contrastive Learning and Playlist Information for Music Classification and Similarity
Apr 24, 2023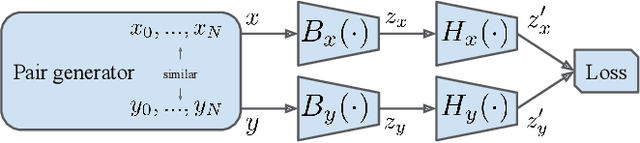
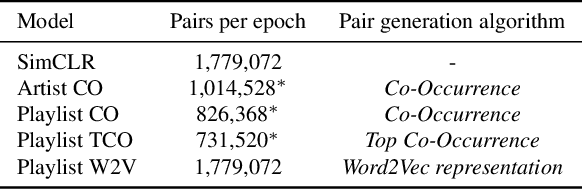
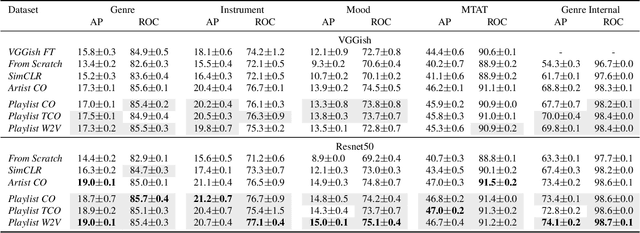
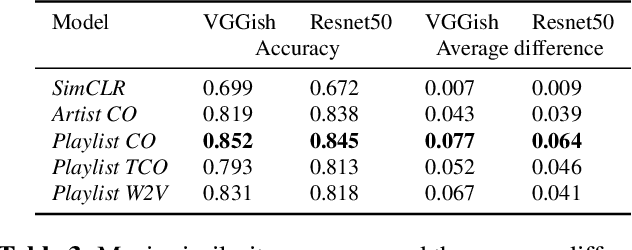
In this work, we investigate an approach that relies on contrastive learning and music metadata as a weak source of supervision to train music representation models. Recent studies show that contrastive learning can be used with editorial metadata (e.g., artist or album name) to learn audio representations that are useful for different classification tasks. In this paper, we extend this idea to using playlist data as a source of music similarity information and investigate three approaches to generate anchor and positive track pairs. We evaluate these approaches by fine-tuning the pre-trained models for music multi-label classification tasks (genre, mood, and instrument tagging) and music similarity. We find that creating anchor and positive track pairs by relying on co-occurrences in playlists provides better music similarity and competitive classification results compared to choosing tracks from the same artist as in previous works. Additionally, our best pre-training approach based on playlists provides superior classification performance for most datasets.
Textless Speech-to-Music Retrieval Using Emotion Similarity
Mar 19, 2023
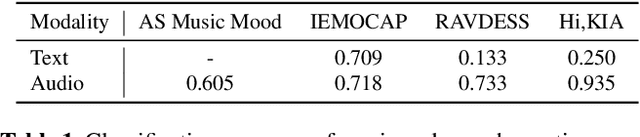
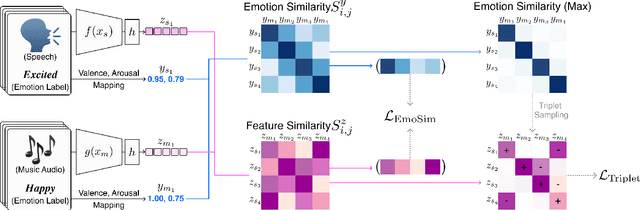

We introduce a framework that recommends music based on the emotions of speech. In content creation and daily life, speech contains information about human emotions, which can be enhanced by music. Our framework focuses on a cross-domain retrieval system to bridge the gap between speech and music via emotion labels. We explore different speech representations and report their impact on different speech types, including acting voice and wake-up words. We also propose an emotion similarity regularization term in cross-domain retrieval tasks. By incorporating the regularization term into training, similar speech-and-music pairs in the emotion space are closer in the joint embedding space. Our comprehensive experimental results show that the proposed model is effective in textless speech-to-music retrieval.
ISAC 4D Imaging System Based on 5G Downlink Millimeter Wave Signal
Oct 10, 2023Integrated Sensing and Communication(ISAC) has become a key technology for the 5th generation (5G) and 6th generation (6G) wireless communications due to its high spectrum utilization efficiency. Utilizing infrastructure such as 5G Base Stations (BS) to realize environmental imaging and reconstruction is important for promoting the construction of smart cities. Current 4D imaging methods utilizing Frequency Modulated Continuous Wave (FMCW) based Fast Fourier Transform (FFT) are not suitable for ISAC scenarios due to the higher bandwidth occupation and lower resolution. We propose a 4D (3D-Coordinates, Velocity) imaging method with higher sensing accuracy based on 2D-FFT with 2D-MUSIC utilizing standard 5G Downlink (DL) millimeter wave (mmWave) signals. To improve the sensing precision we also design a transceiver antenna array element arrangement scheme based on MIMO virtual aperture technique. We further propose a target detection algorithm based on multi-dimensional Constant False Alarm (CFAR) detection, which optimizes the ISAC imaging signal processing flow and reduces the computational pressure of signal processing. Simulation results show that our proposed method has better imaging results. The code is publicly available at https://github.com/MrHaobolu/ISAC\_4D\_IMaging.git.
LongDanceDiff: Long-term Dance Generation with Conditional Diffusion Model
Aug 23, 2023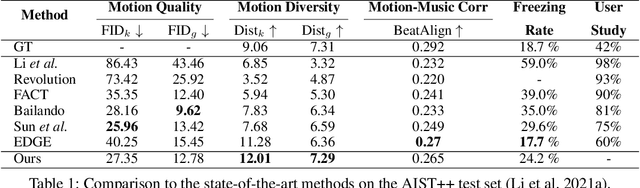
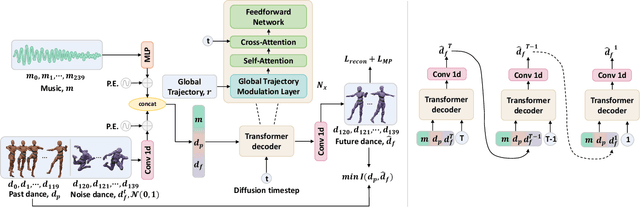
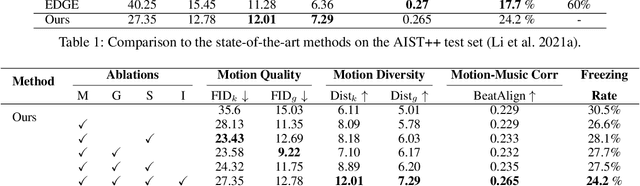
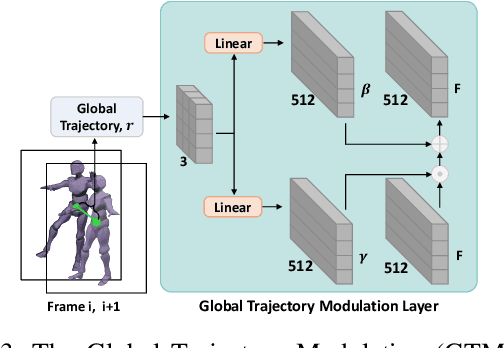
Dancing with music is always an essential human art form to express emotion. Due to the high temporal-spacial complexity, long-term 3D realist dance generation synchronized with music is challenging. Existing methods suffer from the freezing problem when generating long-term dances due to error accumulation and training-inference discrepancy. To address this, we design a conditional diffusion model, LongDanceDiff, for this sequence-to-sequence long-term dance generation, addressing the challenges of temporal coherency and spatial constraint. LongDanceDiff contains a transformer-based diffusion model, where the input is a concatenation of music, past motions, and noised future motions. This partial noising strategy leverages the full-attention mechanism and learns the dependencies among music and past motions. To enhance the diversity of generated dance motions and mitigate the freezing problem, we introduce a mutual information minimization objective that regularizes the dependency between past and future motions. We also address common visual quality issues in dance generation, such as foot sliding and unsmooth motion, by incorporating spatial constraints through a Global-Trajectory Modulation (GTM) layer and motion perceptual losses, thereby improving the smoothness and naturalness of motion generation. Extensive experiments demonstrate a significant improvement in our approach over the existing state-of-the-art methods. We plan to release our codes and models soon.
Pitchclass2vec: Symbolic Music Structure Segmentation with Chord Embeddings
Mar 24, 2023

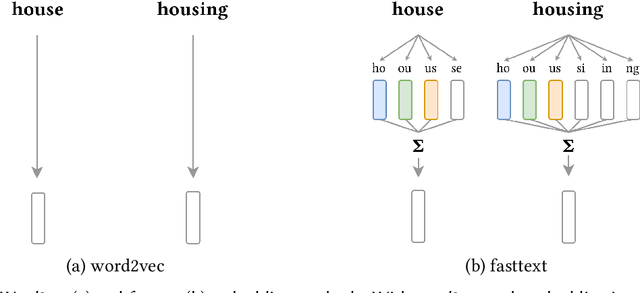
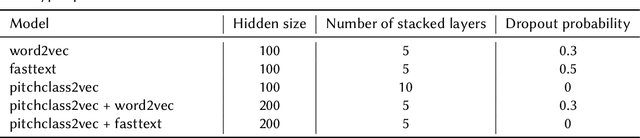
Structure perception is a fundamental aspect of music cognition in humans. Historically, the hierarchical organization of music into structures served as a narrative device for conveying meaning, creating expectancy, and evoking emotions in the listener. Thereby, musical structures play an essential role in music composition, as they shape the musical discourse through which the composer organises his ideas. In this paper, we present a novel music segmentation method, pitchclass2vec, based on symbolic chord annotations, which are embedded into continuous vector representations using both natural language processing techniques and custom-made encodings. Our algorithm is based on long-short term memory (LSTM) neural network and outperforms the state-of-the-art techniques based on symbolic chord annotations in the field.
Terahertz-Band Direction Finding With Beam-Split and Mutual Coupling Calibration
Sep 07, 2023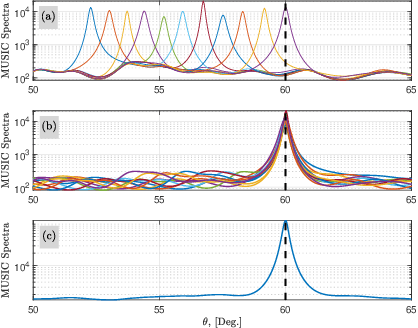
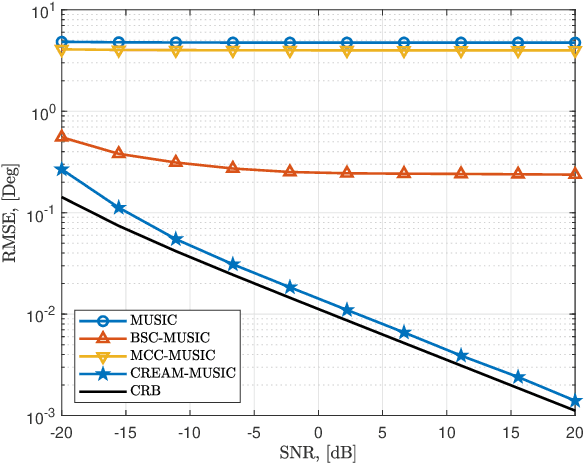
Terahertz (THz) band is currently envisioned as the key building block to achieving the future sixth generation (6G) wireless systems. The ultra-wide bandwidth and very narrow beamwidth of THz systems offer the next order of magnitude in user densities and multi-functional behavior. However, wide bandwidth results in a frequency-dependent beampattern causing the beams generated at different subcarriers split and point to different directions. Furthermore, mutual coupling degrades the system's performance. This paper studies the compensation of both beam-split and mutual coupling for direction-of-arrival (DoA) estimation by modeling the beam-split and mutual coupling as an array imperfection. We propose a subspace-based approach using multiple signal classification with CalibRated for bEAam-split and Mutual coupling (CREAM-MUSIC) algorithm for this purpose. Via numerical simulations, we show the proposed CREAM-MUSIC approach accurately estimates the DoAs in the presence of beam-split and mutual coupling.