 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Detecting Generic Music Features with Single Layer Feedforward Network using Unsupervised Hebbian Computation
Aug 31, 2020

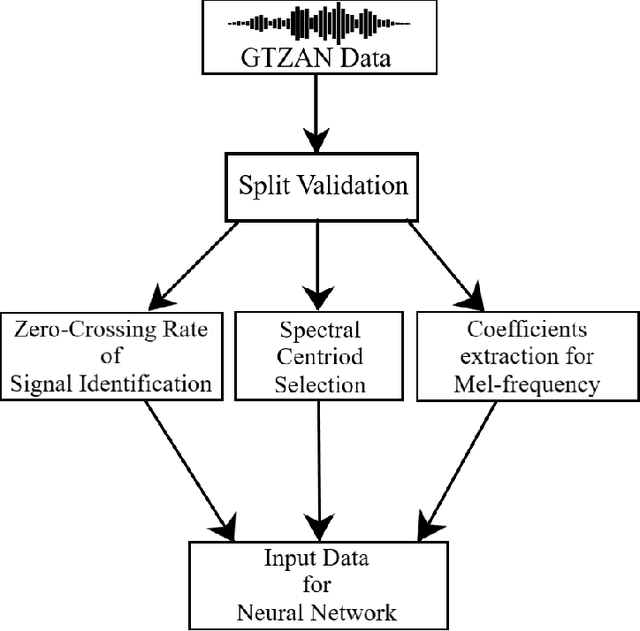
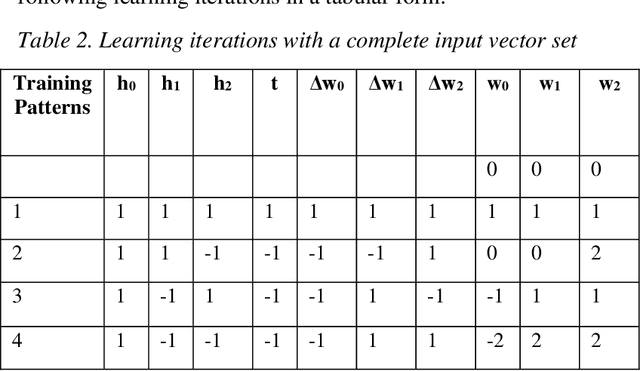
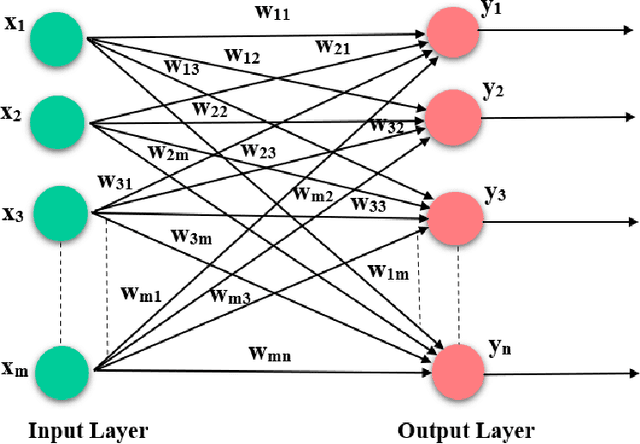
With the ever-increasing number of digital music and vast music track features through popular online music streaming software and apps, feature recognition using the neural network is being used for experimentation to produce a wide range of results across a variety of experiments recently. Through this work, the authors extract information on such features from a popular open-source music corpus and explored new recognition techniques, by applying unsupervised Hebbian learning techniques on their single-layer neural network using the same dataset. The authors show the detailed empirical findings to simulate how such an algorithm can help a single layer feedforward network in training for music feature learning as patterns. The unsupervised training algorithm enhances their proposed neural network to achieve an accuracy of 90.36% for successful music feature detection. For comparative analysis against similar tasks, authors put their results with the likes of several previous benchmark works. They further discuss the limitations and thorough error analysis of their work. The authors hope to discover and gather new information about this particular classification technique and its performance, and further understand future potential directions and prospects that could improve the art of computational music feature recognition.
Music Source Separation with Deep Equilibrium Models
Oct 13, 2021
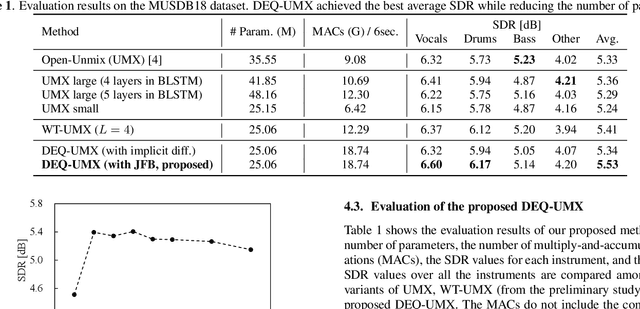

While deep neural network-based music source separation (MSS) is very effective and achieves high performance, its model size is often a problem for practical deployment. Deep implicit architectures such as deep equilibrium models (DEQ) were recently proposed, which can achieve higher performance than their explicit counterparts with limited depth while keeping the number of parameters small. This makes DEQ also attractive for MSS, especially as it was originally applied to sequential modeling tasks in natural language processing and thus should in principle be also suited for MSS. However, an investigation of a good architecture and training scheme for MSS with DEQ is needed as the characteristics of acoustic signals are different from those of natural language data. Hence, in this paper we propose an architecture and training scheme for MSS with DEQ. Starting with the architecture of Open-Unmix (UMX), we replace its sequence model with DEQ. We refer to our proposed method as DEQ-based UMX (DEQ-UMX). Experimental results show that DEQ-UMX performs better than the original UMX while reducing its number of parameters by 30%.
Score-based Continuous-time Discrete Diffusion Models
Nov 30, 2022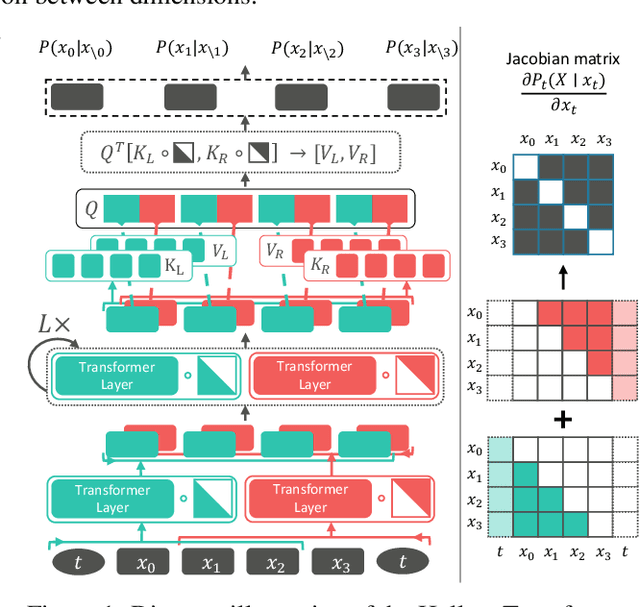



Score-based modeling through stochastic differential equations (SDEs) has provided a new perspective on diffusion models, and demonstrated superior performance on continuous data. However, the gradient of the log-likelihood function, i.e., the score function, is not properly defined for discrete spaces. This makes it non-trivial to adapt \textcolor{\cdiff}{the score-based modeling} to categorical data. In this paper, we extend diffusion models to discrete variables by introducing a stochastic jump process where the reverse process denoises via a continuous-time Markov chain. This formulation admits an analytical simulation during backward sampling. To learn the reverse process, we extend score matching to general categorical data and show that an unbiased estimator can be obtained via simple matching of the conditional marginal distributions. We demonstrate the effectiveness of the proposed method on a set of synthetic and real-world music and image benchmarks.
Multi-Modal Music Information Retrieval: Augmenting Audio-Analysis with Visual Computing for Improved Music Video Analysis
Feb 01, 2020



This thesis combines audio-analysis with computer vision to approach Music Information Retrieval (MIR) tasks from a multi-modal perspective. This thesis focuses on the information provided by the visual layer of music videos and how it can be harnessed to augment and improve tasks of the MIR research domain. The main hypothesis of this work is based on the observation that certain expressive categories such as genre or theme can be recognized on the basis of the visual content alone, without the sound being heard. This leads to the hypothesis that there exists a visual language that is used to express mood or genre. In a further consequence it can be concluded that this visual information is music related and thus should be beneficial for the corresponding MIR tasks such as music genre classification or mood recognition. A series of comprehensive experiments and evaluations are conducted which are focused on the extraction of visual information and its application in different MIR tasks. A custom dataset is created, suitable to develop and test visual features which are able to represent music related information. Evaluations range from low-level visual features to high-level concepts retrieved by means of Deep Convolutional Neural Networks. Additionally, new visual features are introduced capturing rhythmic visual patterns. In all of these experiments the audio-based results serve as benchmark for the visual and audio-visual approaches. The experiments are conducted for three MIR tasks Artist Identification, Music Genre Classification and Cross-Genre Classification. Experiments show that an audio-visual approach harnessing high-level semantic information gained from visual concept detection, outperforms audio-only genre-classification accuracy by 16.43%.
jaCappella Corpus: A Japanese a Cappella Vocal Ensemble Corpus
Nov 29, 2022


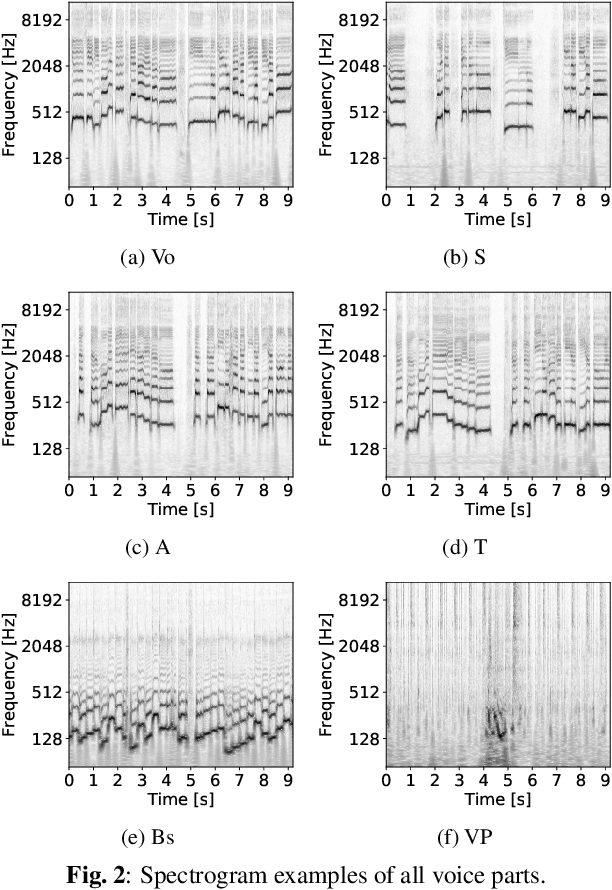
We construct a corpus of Japanese a cappella vocal ensembles (jaCappella corpus) for vocal ensemble separation and synthesis. It consists of 35 copyright-cleared vocal ensemble songs and their audio recordings of individual voice parts. These songs were arranged from out-of-copyright Japanese children's songs and have six voice parts (lead vocal, soprano, alto, tenor, bass, and vocal percussion). They are divided into seven subsets, each of which features typical characteristics of a music genre such as jazz and enka. The variety in genre and voice part match vocal ensembles recently widespread in social media services such as YouTube, although the main targets of conventional vocal ensemble datasets are choral singing made up of soprano, alto, tenor, and bass. Experimental evaluation demonstrates that our corpus is a challenging resource for vocal ensemble separation. Our corpus is available on our project page (https://tomohikonakamura.github.io/jaCappella_corpus/).
Residual Recurrent CRNN for End-to-End Optical Music Recognition on Monophonic Scores
Oct 26, 2020
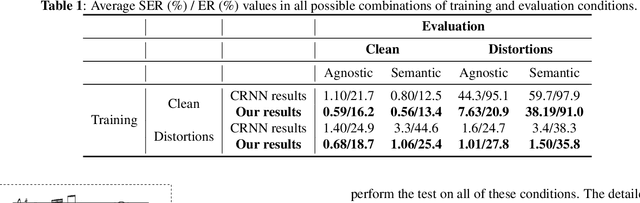

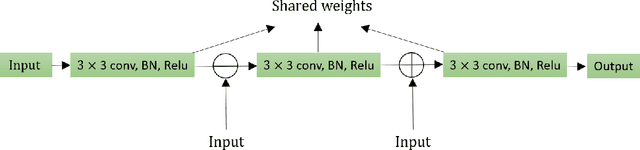
Optical Music Recognition is a field that attempts to extract digital information from images of either the printed music scores or the handwritten music scores. One of the challenges of the Optical Music Recognition task is to transcript the symbols of the camera-captured images into digital music notations. Previous end-to-end model, based on deep learning, was developed as a Convolutional Recurrent Neural Network. However, it does not explore sufficient contextual information from full scales and there is still a large room for improvement. In this paper, we propose an innovative end-to-end framework that combines a block of Residual Recurrent Convolutional Neural Network with a recurrent Encoder-Decoder network to map a sequence of monophonic music symbols corresponding to the notations present in the image. The Residual Recurrent Convolutional block can improve the ability of the model to enrich the context information while the number of parameter will not be increasing. The experiment results were benchmarked against a publicly available dataset called CAMERA-PRIMUS. We evaluate the performances of our model on both the images with ideal conditions and that with non-ideal conditions. The experiments show that our approach surpass the state-of-the-art end-to-end method using Convolutional Recurrent Neural Network.
Towards Context-Aware Neural Performance-Score Synchronisation
May 31, 2022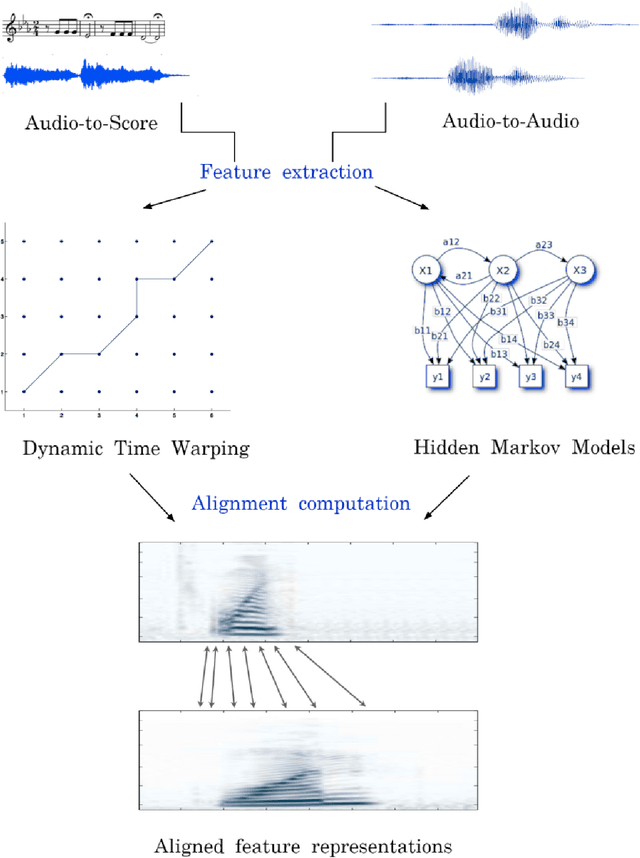
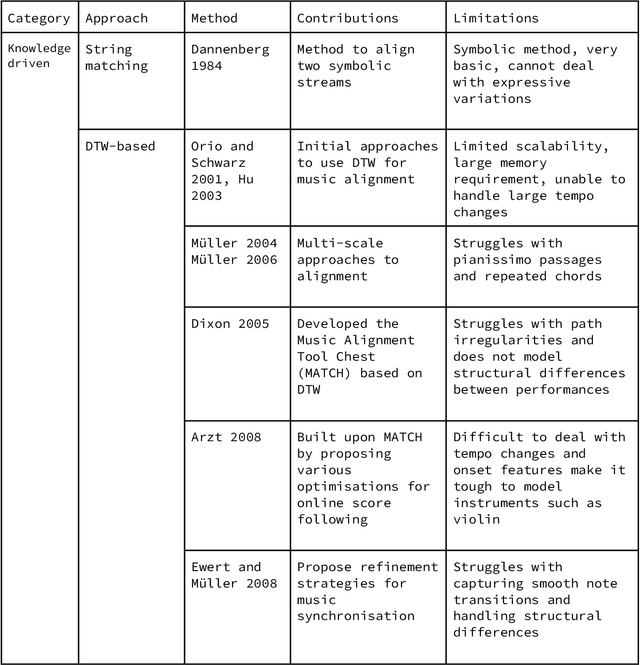
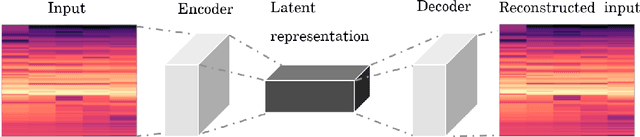

Music can be represented in multiple forms, such as in the audio form as a recording of a performance, in the symbolic form as a computer readable score, or in the image form as a scan of the sheet music. Music synchronisation provides a way to navigate among multiple representations of music in a unified manner by generating an accurate mapping between them, lending itself applicable to a myriad of domains like music education, performance analysis, automatic accompaniment and music editing. Traditional synchronisation methods compute alignment using knowledge-driven and stochastic approaches, typically employing handcrafted features. These methods are often unable to generalise well to different instruments, acoustic environments and recording conditions, and normally assume complete structural agreement between the performances and the scores. This PhD furthers the development of performance-score synchronisation research by proposing data-driven, context-aware alignment approaches, on three fronts: Firstly, I replace the handcrafted features by employing a metric learning based approach that is adaptable to different acoustic settings and performs well in data-scarce conditions. Secondly, I address the handling of structural differences between the performances and scores, which is a common limitation of standard alignment methods. Finally, I eschew the reliance on both feature engineering and dynamic programming, and propose a completely data-driven synchronisation method that computes alignments using a neural framework, whilst also being robust to structural differences between the performances and scores.
Mel Spectrogram Inversion with Stable Pitch
Aug 26, 2022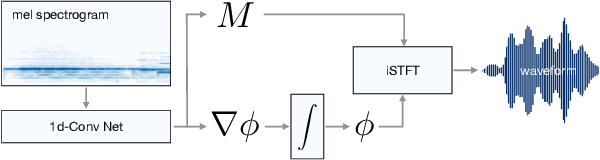
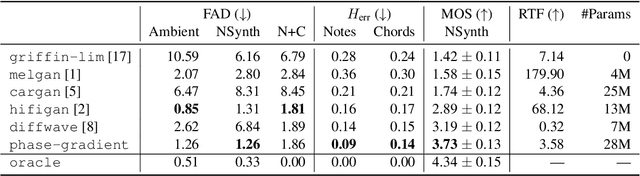
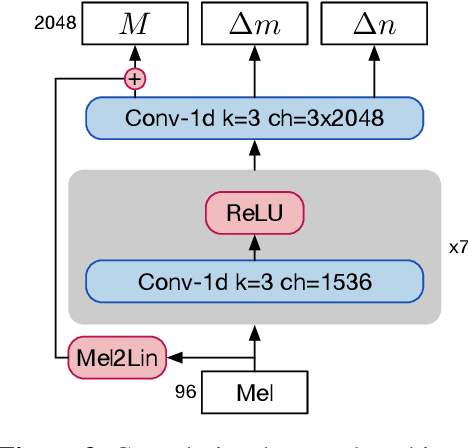
Vocoders are models capable of transforming a low-dimensional spectral representation of an audio signal, typically the mel spectrogram, to a waveform. Modern speech generation pipelines use a vocoder as their final component. Recent vocoder models developed for speech achieve a high degree of realism, such that it is natural to wonder how they would perform on music signals. Compared to speech, the heterogeneity and structure of the musical sound texture offers new challenges. In this work we focus on one specific artifact that some vocoder models designed for speech tend to exhibit when applied to music: the perceived instability of pitch when synthesizing sustained notes. We argue that the characteristic sound of this artifact is due to the lack of horizontal phase coherence, which is often the result of using a time-domain target space with a model that is invariant to time-shifts, such as a convolutional neural network. We propose a new vocoder model that is specifically designed for music. Key to improving the pitch stability is the choice of a shift-invariant target space that consists of the magnitude spectrum and the phase gradient. We discuss the reasons that inspired us to re-formulate the vocoder task, outline a working example, and evaluate it on musical signals. Our method results in 60% and 10% improved reconstruction of sustained notes and chords with respect to existing models, using a novel harmonic error metric.
Disentangled Multidimensional Metric Learning for Music Similarity
Aug 12, 2020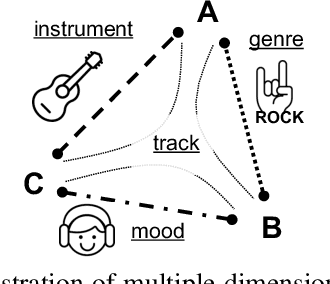
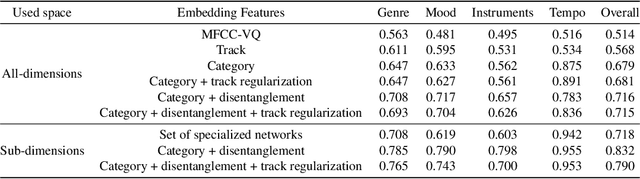
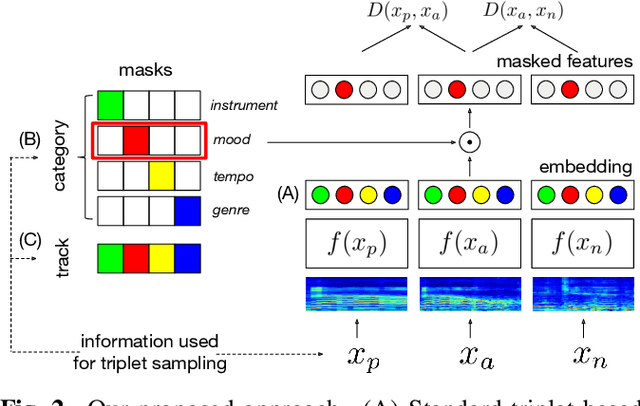

Music similarity search is useful for a variety of creative tasks such as replacing one music recording with another recording with a similar "feel", a common task in video editing. For this task, it is typically necessary to define a similarity metric to compare one recording to another. Music similarity, however, is hard to define and depends on multiple simultaneous notions of similarity (i.e. genre, mood, instrument, tempo). While prior work ignore this issue, we embrace this idea and introduce the concept of multidimensional similarity and unify both global and specialized similarity metrics into a single, semantically disentangled multidimensional similarity metric. To do so, we adapt a variant of deep metric learning called conditional similarity networks to the audio domain and extend it using track-based information to control the specificity of our model. We evaluate our method and show that our single, multidimensional model outperforms both specialized similarity spaces and alternative baselines. We also run a user-study and show that our approach is favored by human annotators as well.
GANkyoku: a Generative Adversarial Network for Shakuhachi Music
Nov 22, 2019
A common approach to generating symbolic music using neural networks involves repeated sampling of an autoregressive model until the full output sequence is obtained. While such approaches have shown some promise in generating short sequences of music, this typically has not extended to cases where the final target sequence is significantly longer, for example an entire piece of music. In this work we propose a network trained in an adversarial process to generate entire pieces of solo shakuhachi music, in the form of symbolic notation. The pieces are intended to refer clearly to traditional shakuhachi music, maintaining idiomaticity and key aesthetic qualities, while also adding novel features, ultimately creating worthy additions to the contemporary shakuhachi repertoire. A key subproblem is also addressed, namely the lack of relevant training data readily available, in two steps: firstly, we introduce the PH_Shaku dataset for symbolic traditional shakuhachi music; secondly, we build on previous work using conditioning in generative adversarial networks to introduce a technique for data augmentation.