 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Human Reaction Intensity Estimation with Ensemble of Multi-task Networks
Mar 16, 2023
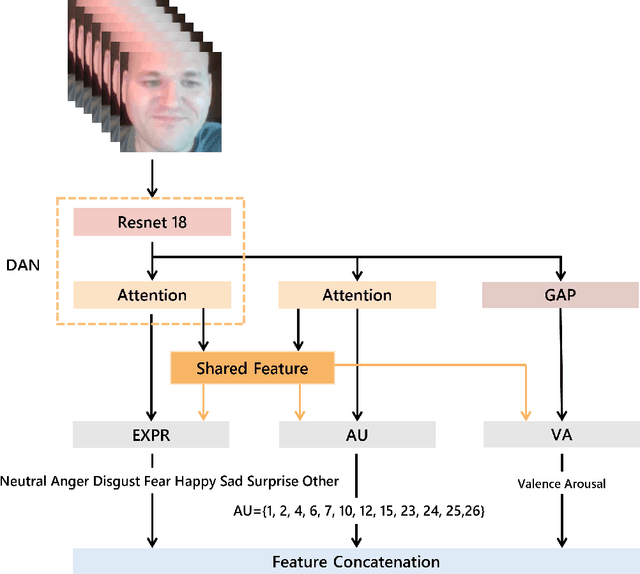
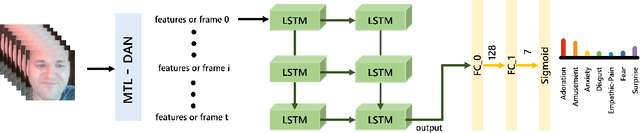


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Emotional Reaction Intensity" (ERI) is an important topic in the facial expression recognition task. In this paper, we propose a multi-emotional task learning-based approach and present preliminary results for the ERI challenge introduced in the 5th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean PCC score of 0.3254.
Automated Speaker Independent Visual Speech Recognition: A Comprehensive Survey
Jun 14, 2023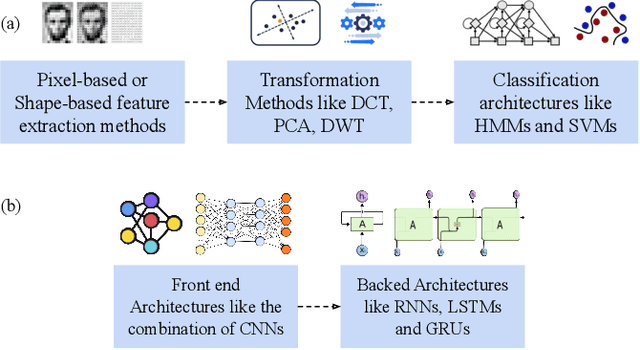
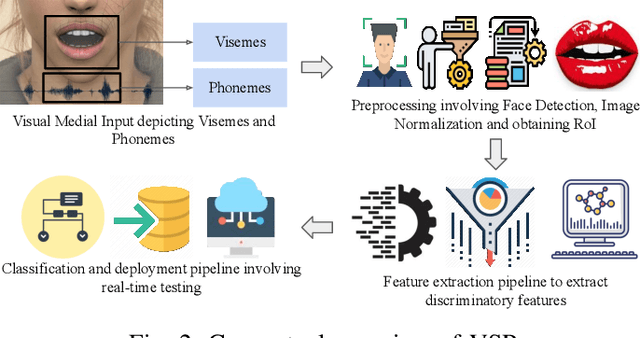
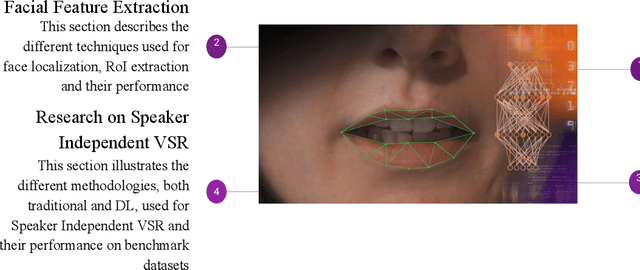
Speaker-independent VSR is a complex task that involves identifying spoken words or phrases from video recordings of a speaker's facial movements. Over the years, there has been a considerable amount of research in the field of VSR involving different algorithms and datasets to evaluate system performance. These efforts have resulted in significant progress in developing effective VSR models, creating new opportunities for further research in this area. This survey provides a detailed examination of the progression of VSR over the past three decades, with a particular emphasis on the transition from speaker-dependent to speaker-independent systems. We also provide a comprehensive overview of the various datasets used in VSR research and the preprocessing techniques employed to achieve speaker independence. The survey covers the works published from 1990 to 2023, thoroughly analyzing each work and comparing them on various parameters. This survey provides an in-depth analysis of speaker-independent VSR systems evolution from 1990 to 2023. It outlines the development of VSR systems over time and highlights the need to develop end-to-end pipelines for speaker-independent VSR. The pictorial representation offers a clear and concise overview of the techniques used in speaker-independent VSR, thereby aiding in the comprehension and analysis of the various methodologies. The survey also highlights the strengths and limitations of each technique and provides insights into developing novel approaches for analyzing visual speech cues. Overall, This comprehensive review provides insights into the current state-of-the-art speaker-independent VSR and highlights potential areas for future research.
Analysis of Adversarial Image Manipulations
May 10, 2023
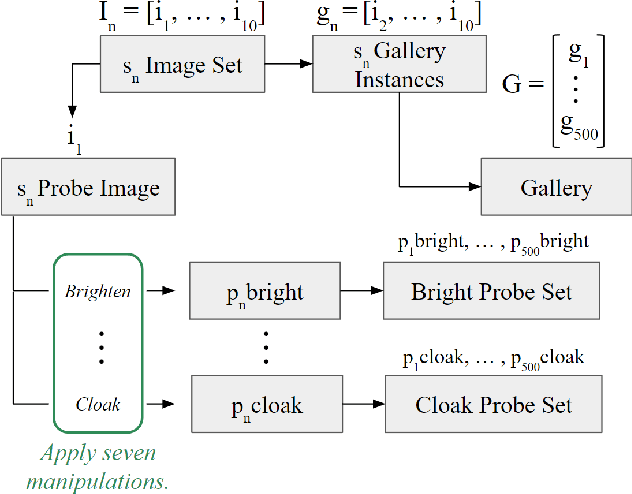
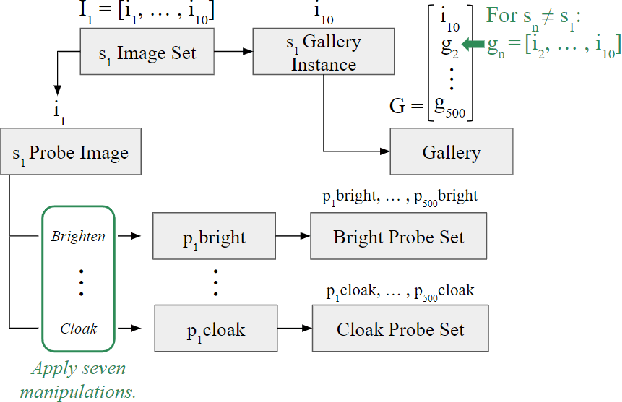
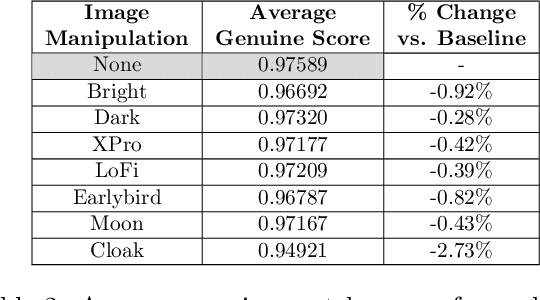
As virtual and physical identity grow increasingly intertwined, the importance of privacy and security in the online sphere becomes paramount. In recent years, multiple news stories have emerged of private companies scraping web content and doing research with or selling the data. Images uploaded online can be scraped without users' consent or knowledge. Users of social media platforms whose images are scraped may be at risk of being identified in other uploaded images or in real-world identification situations. This paper investigates how simple, accessible image manipulation techniques affect the accuracy of facial recognition software in identifying an individual's various face images based on one unique image.
Facial Action Unit Detection and Intensity Estimation from Self-supervised Representation
Oct 28, 2022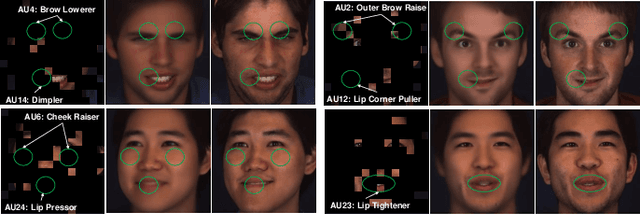
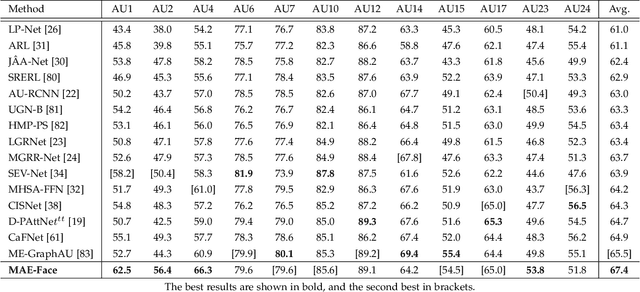
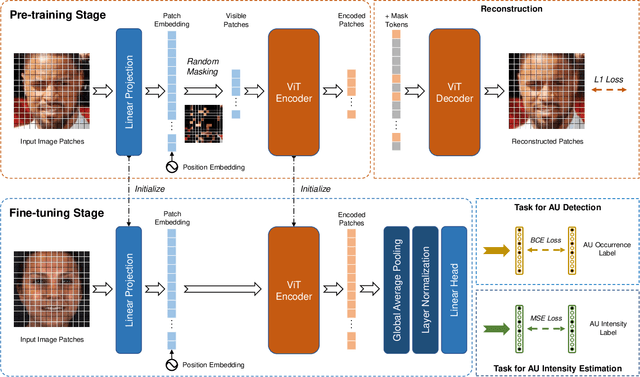

As a fine-grained and local expression behavior measurement, facial action unit (FAU) analysis (e.g., detection and intensity estimation) has been documented for its time-consuming, labor-intensive, and error-prone annotation. Thus a long-standing challenge of FAU analysis arises from the data scarcity of manual annotations, limiting the generalization ability of trained models to a large extent. Amounts of previous works have made efforts to alleviate this issue via semi/weakly supervised methods and extra auxiliary information. However, these methods still require domain knowledge and have not yet avoided the high dependency on data annotation. This paper introduces a robust facial representation model MAE-Face for AU analysis. Using masked autoencoding as the self-supervised pre-training approach, MAE-Face first learns a high-capacity model from a feasible collection of face images without additional data annotations. Then after being fine-tuned on AU datasets, MAE-Face exhibits convincing performance for both AU detection and AU intensity estimation, achieving a new state-of-the-art on nearly all the evaluation results. Further investigation shows that MAE-Face achieves decent performance even when fine-tuned on only 1\% of the AU training set, strongly proving its robustness and generalization performance.
End-to-end Face-swapping via Adaptive Latent Representation Learning
Mar 07, 2023


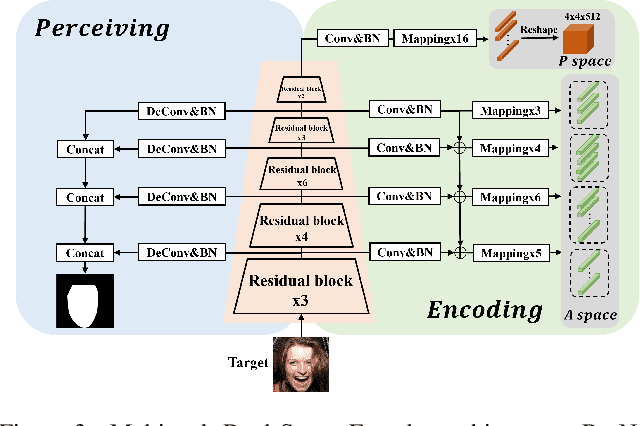
Taking full advantage of the excellent performance of StyleGAN, style transfer-based face swapping methods have been extensively investigated recently. However, these studies require separate face segmentation and blending modules for successful face swapping, and the fixed selection of the manipulated latent code in these works is reckless, thus degrading face swapping quality, generalizability, and practicability. This paper proposes a novel and end-to-end integrated framework for high resolution and attribute preservation face swapping via Adaptive Latent Representation Learning. Specifically, we first design a multi-task dual-space face encoder by sharing the underlying feature extraction network to simultaneously complete the facial region perception and face encoding. This encoder enables us to control the face pose and attribute individually, thus enhancing the face swapping quality. Next, we propose an adaptive latent codes swapping module to adaptively learn the mapping between the facial attributes and the latent codes and select effective latent codes for improved retention of facial attributes. Finally, the initial face swapping image generated by StyleGAN2 is blended with the facial region mask generated by our encoder to address the background blur problem. Our framework integrating facial perceiving and blending into the end-to-end training and testing process can achieve high realistic face-swapping on wild faces without segmentation masks. Experimental results demonstrate the superior performance of our approach over state-of-the-art methods.
Non-Contact Heart Rate Measurement from Deteriorated Videos
Apr 28, 2023
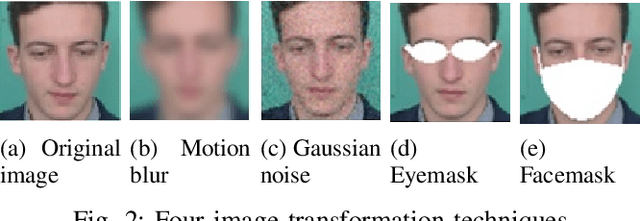


Remote photoplethysmography (rPPG) offers a state-of-the-art, non-contact methodology for estimating human pulse by analyzing facial videos. Despite its potential, rPPG methods can be susceptible to various artifacts, such as noise, occlusions, and other obstructions caused by sunglasses, masks, or even involuntary facial contact, such as individuals inadvertently touching their faces. In this study, we apply image processing transformations to intentionally degrade video quality, mimicking these challenging conditions, and subsequently evaluate the performance of both non-learning and learning-based rPPG methods on the deteriorated data. Our results reveal a significant decrease in accuracy in the presence of these artifacts, prompting us to propose the application of restoration techniques, such as denoising and inpainting, to improve heart-rate estimation outcomes. By addressing these challenging conditions and occlusion artifacts, our approach aims to make rPPG methods more robust and adaptable to real-world situations. To assess the effectiveness of our proposed methods, we undertake comprehensive experiments on three publicly available datasets, encompassing a wide range of scenarios and artifact types. Our findings underscore the potential to construct a robust rPPG system by employing an optimal combination of restoration algorithms and rPPG techniques. Moreover, our study contributes to the advancement of privacy-conscious rPPG methodologies, thereby bolstering the overall utility and impact of this innovative technology in the field of remote heart-rate estimation under realistic and diverse conditions.
Gender Stereotyping Impact in Facial Expression Recognition
Oct 11, 2022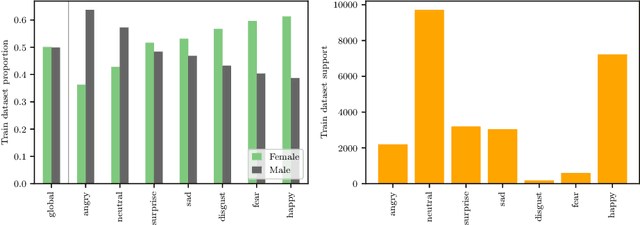
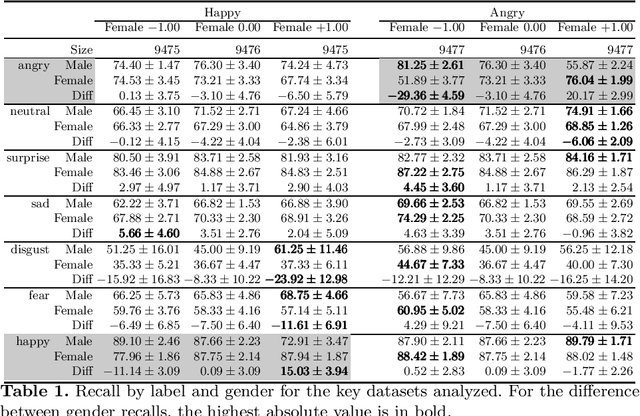
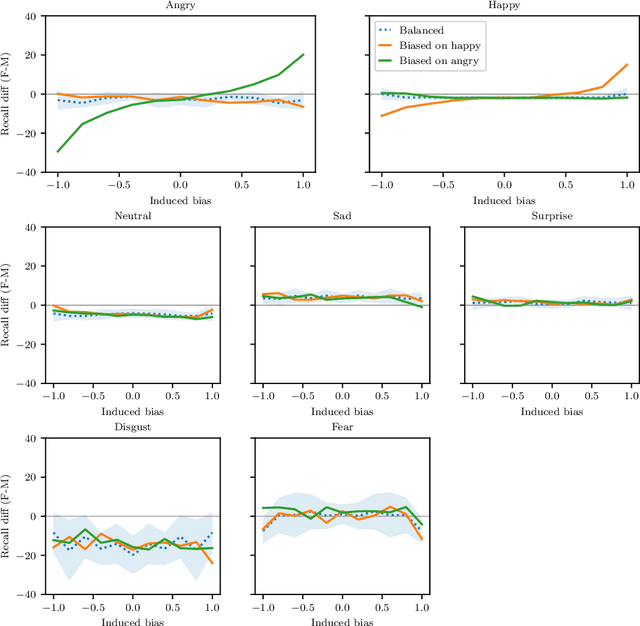
Facial Expression Recognition (FER) uses images of faces to identify the emotional state of users, allowing for a closer interaction between humans and autonomous systems. Unfortunately, as the images naturally integrate some demographic information, such as apparent age, gender, and race of the subject, these systems are prone to demographic bias issues. In recent years, machine learning-based models have become the most popular approach to FER. These models require training on large datasets of facial expression images, and their generalization capabilities are strongly related to the characteristics of the dataset. In publicly available FER datasets, apparent gender representation is usually mostly balanced, but their representation in the individual label is not, embedding social stereotypes into the datasets and generating a potential for harm. Although this type of bias has been overlooked so far, it is important to understand the impact it may have in the context of FER. To do so, we use a popular FER dataset, FER+, to generate derivative datasets with different amounts of stereotypical bias by altering the gender proportions of certain labels. We then proceed to measure the discrepancy between the performance of the models trained on these datasets for the apparent gender groups. We observe a discrepancy in the recognition of certain emotions between genders of up to $29 \%$ under the worst bias conditions. Our results also suggest a safety range for stereotypical bias in a dataset that does not appear to produce stereotypical bias in the resulting model. Our findings support the need for a thorough bias analysis of public datasets in problems like FER, where a global balance of demographic representation can still hide other types of bias that harm certain demographic groups.
Instant Multi-View Head Capture through Learnable Registration
Jun 12, 2023
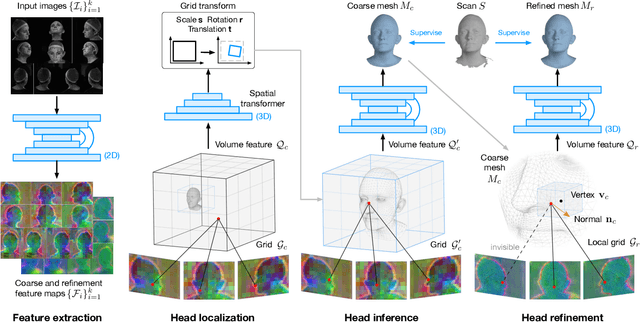
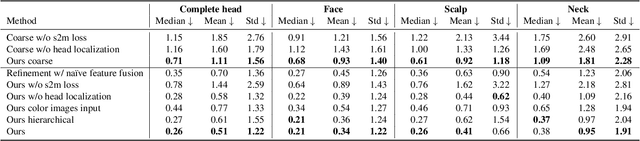
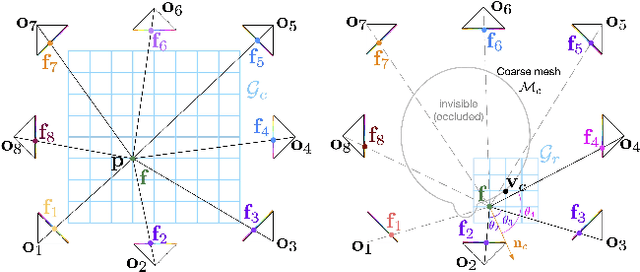
Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available at https://tempeh.is.tue.mpg.de.
EMERSK -- Explainable Multimodal Emotion Recognition with Situational Knowledge
Jun 14, 2023
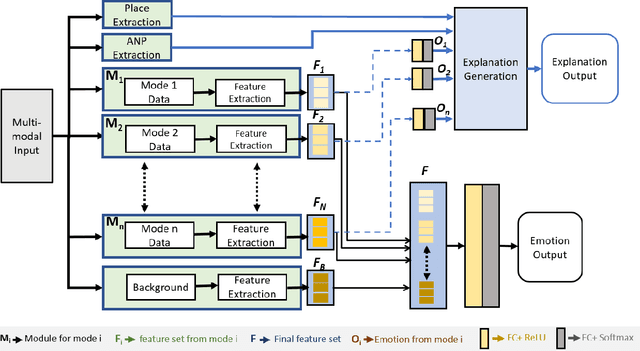
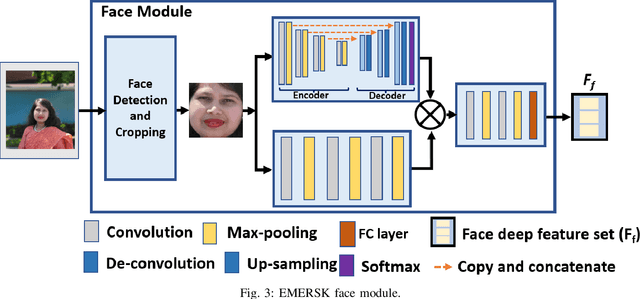
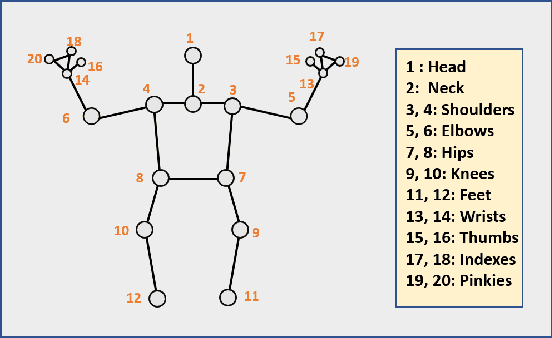
Automatic emotion recognition has recently gained significant attention due to the growing popularity of deep learning algorithms. One of the primary challenges in emotion recognition is effectively utilizing the various cues (modalities) available in the data. Another challenge is providing a proper explanation of the outcome of the learning.To address these challenges, we present Explainable Multimodal Emotion Recognition with Situational Knowledge (EMERSK), a generalized and modular system for human emotion recognition and explanation using visual information. Our system can handle multiple modalities, including facial expressions, posture, and gait, in a flexible and modular manner. The network consists of different modules that can be added or removed depending on the available data. We utilize a two-stream network architecture with convolutional neural networks (CNNs) and encoder-decoder style attention mechanisms to extract deep features from face images. Similarly, CNNs and recurrent neural networks (RNNs) with Long Short-term Memory (LSTM) are employed to extract features from posture and gait data. We also incorporate deep features from the background as contextual information for the learning process. The deep features from each module are fused using an early fusion network. Furthermore, we leverage situational knowledge derived from the location type and adjective-noun pair (ANP) extracted from the scene, as well as the spatio-temporal average distribution of emotions, to generate explanations. Ablation studies demonstrate that each sub-network can independently perform emotion recognition, and combining them in a multimodal approach significantly improves overall recognition performance. Extensive experiments conducted on various benchmark datasets, including GroupWalk, validate the superior performance of our approach compared to other state-of-the-art methods.
AlteredAvatar: Stylizing Dynamic 3D Avatars with Fast Style Adaptation
May 30, 2023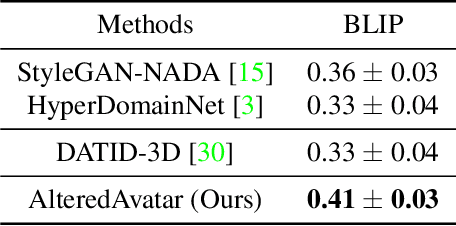
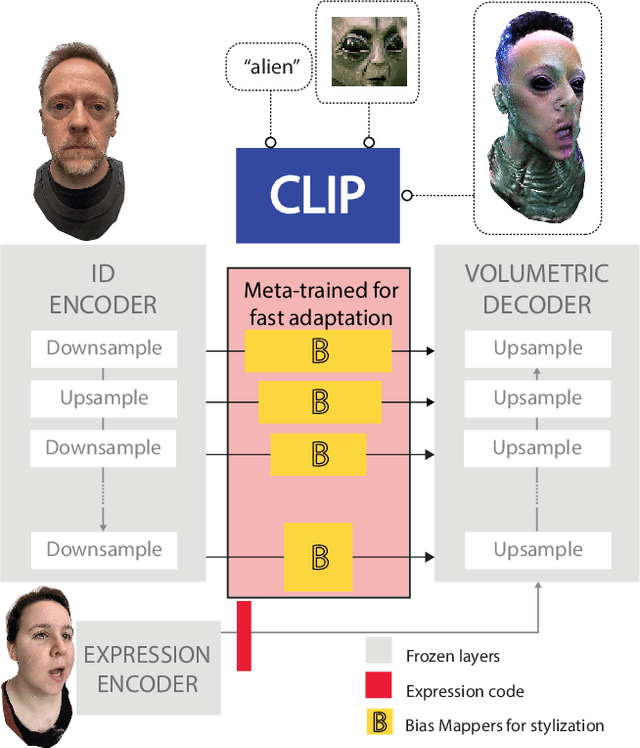


This paper presents a method that can quickly adapt dynamic 3D avatars to arbitrary text descriptions of novel styles. Among existing approaches for avatar stylization, direct optimization methods can produce excellent results for arbitrary styles but they are unpleasantly slow. Furthermore, they require redoing the optimization process from scratch for every new input. Fast approximation methods using feed-forward networks trained on a large dataset of style images can generate results for new inputs quickly, but tend not to generalize well to novel styles and fall short in quality. We therefore investigate a new approach, AlteredAvatar, that combines those two approaches using the meta-learning framework. In the inner loop, the model learns to optimize to match a single target style well; while in the outer loop, the model learns to stylize efficiently across many styles. After training, AlteredAvatar learns an initialization that can quickly adapt within a small number of update steps to a novel style, which can be given using texts, a reference image, or a combination of both. We show that AlteredAvatar can achieve a good balance between speed, flexibility and quality, while maintaining consistency across a wide range of novel views and facial expressions.