 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition
Apr 04, 2022
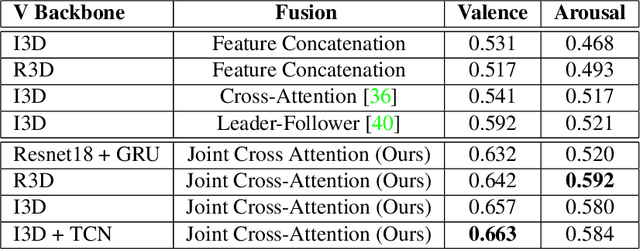
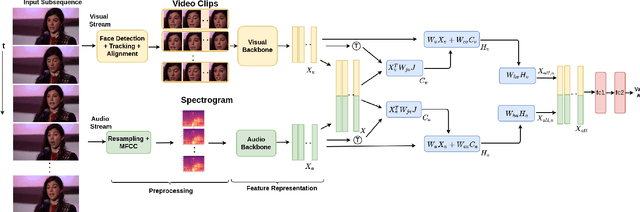
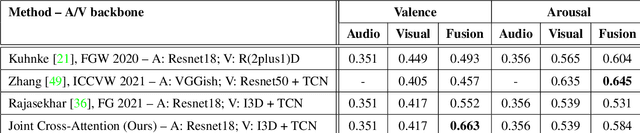
Multimodal emotion recognition has recently gained much attention since it can leverage diverse and complementary relationships over multiple modalities (e.g., audio, visual, biosignals, etc.), and can provide some robustness to noisy modalities. Most state-of-the-art methods for audio-visual (A-V) fusion rely on recurrent networks or conventional attention mechanisms that do not effectively leverage the complementary nature of A-V modalities. In this paper, we focus on dimensional emotion recognition based on the fusion of facial and vocal modalities extracted from videos. Specifically, we propose a joint cross-attention model that relies on the complementary relationships to extract the salient features across A-V modalities, allowing for accurate prediction of continuous values of valence and arousal. The proposed fusion model efficiently leverages the inter-modal relationships, while reducing the heterogeneity between the features. In particular, it computes the cross-attention weights based on correlation between the combined feature representation and individual modalities. By deploying the combined A-V feature representation into the cross-attention module, the performance of our fusion module improves significantly over the vanilla cross-attention module. Experimental results on validation-set videos from the AffWild2 dataset indicate that our proposed A-V fusion model provides a cost-effective solution that can outperform state-of-the-art approaches. The code is available on GitHub: https://github.com/praveena2j/JointCrossAttentional-AV-Fusion.
Knowing When to Quit: Selective Cascaded Regression with Patch Attention for Real-Time Face Alignment
Aug 03, 2021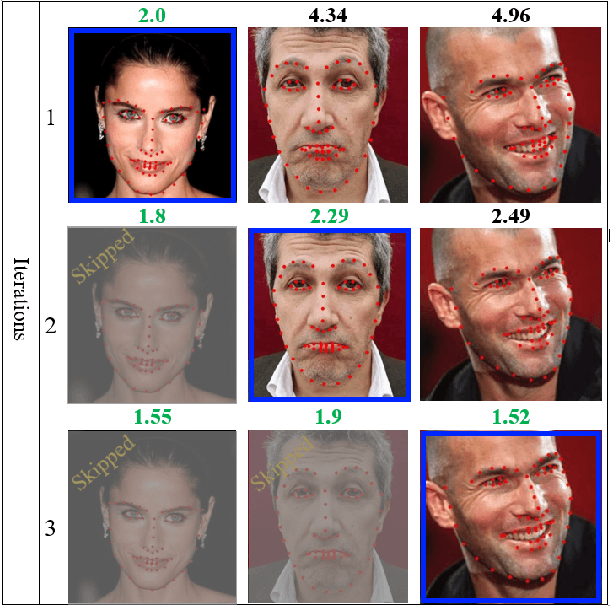
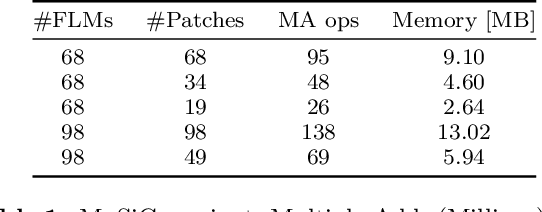
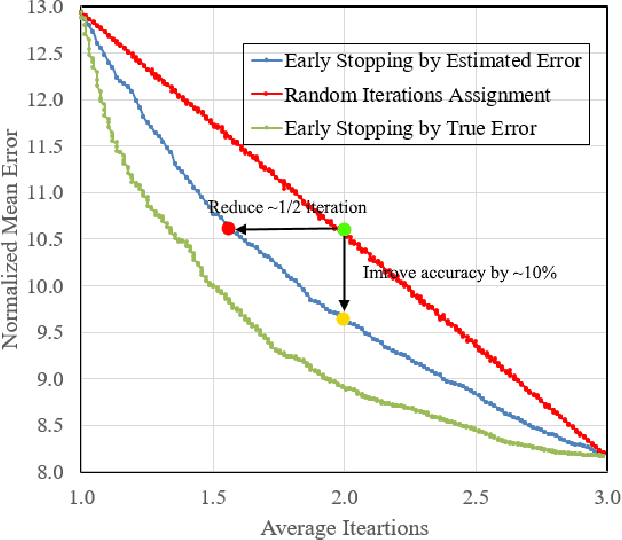
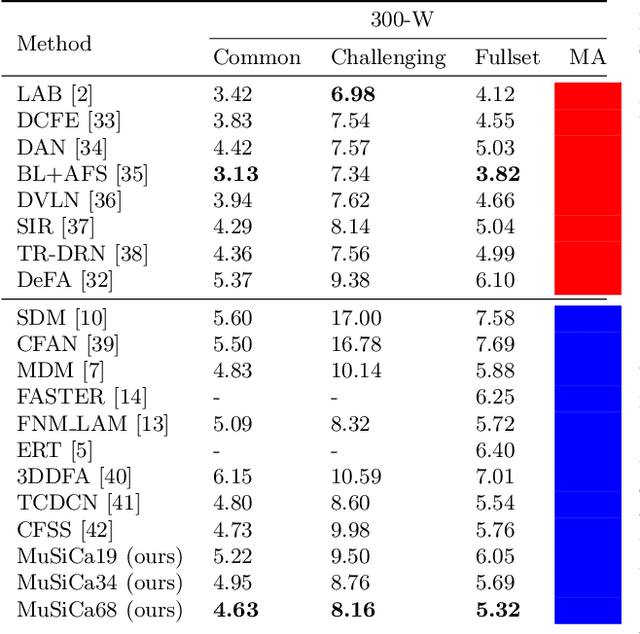
Facial landmarks (FLM) estimation is a critical component in many face-related applications. In this work, we aim to optimize for both accuracy and speed and explore the trade-off between them. Our key observation is that not all faces are created equal. Frontal faces with neutral expressions converge faster than faces with extreme poses or expressions. To differentiate among samples, we train our model to predict the regression error after each iteration. If the current iteration is accurate enough, we stop iterating, saving redundant iterations while keeping the accuracy in check. We also observe that as neighboring patches overlap, we can infer all facial landmarks (FLMs) with only a small number of patches without a major accuracy sacrifice. Architecturally, we offer a multi-scale, patch-based, lightweight feature extractor with a fine-grained local patch attention module, which computes a patch weighting according to the information in the patch itself and enhances the expressive power of the patch features. We analyze the patch attention data to infer where the model is attending when regressing facial landmarks and compare it to face attention in humans. Our model runs in real-time on a mobile device GPU, with 95 Mega Multiply-Add (MMA) operations, outperforming all state-of-the-art methods under 1000 MMA, with a normalized mean error of 8.16 on the 300W challenging dataset.
Face Age Progression With Attribute Manipulation
Jun 14, 2021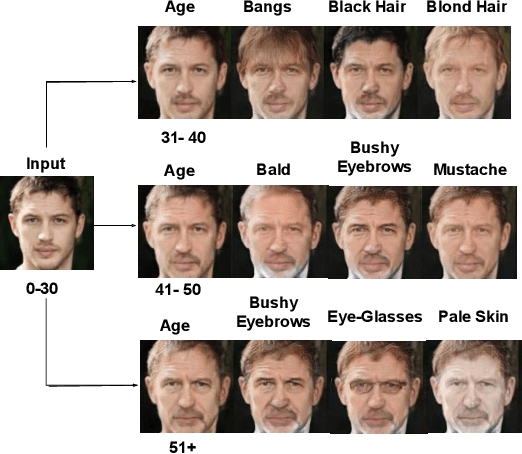
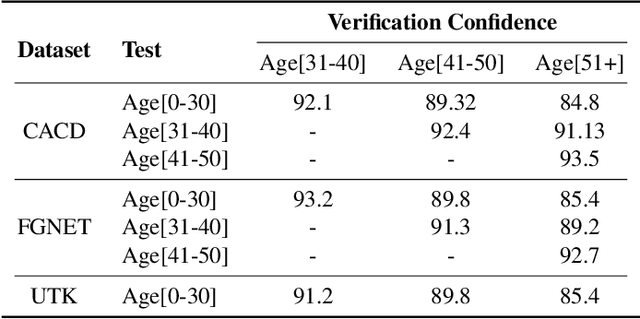
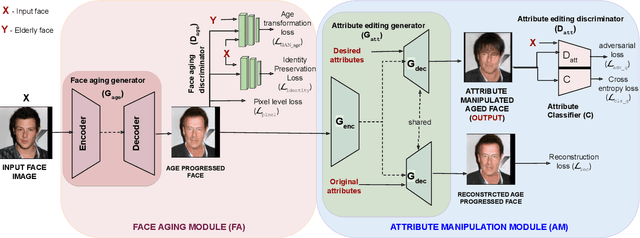
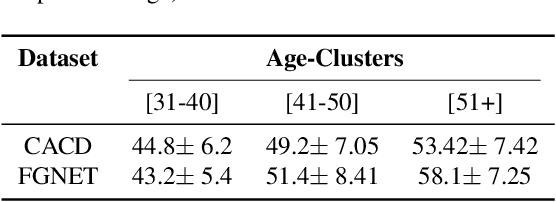
Face is one of the predominant means of person recognition. In the process of ageing, human face is prone to many factors such as time, attributes, weather and other subject specific variations. The impact of these factors were not well studied in the literature of face aging. In this paper, we propose a novel holistic model in this regard viz., ``Face Age progression With Attribute Manipulation (FAWAM)", i.e. generating face images at different ages while simultaneously varying attributes and other subject specific characteristics. We address the task in a bottom-up manner, as two submodules i.e. face age progression and face attribute manipulation. For face aging, we use an attribute-conscious face aging model with a pyramidal generative adversarial network that can model age-specific facial changes while maintaining intrinsic subject specific characteristics. For facial attribute manipulation, the age processed facial image is manipulated with desired attributes while preserving other details unchanged, leveraging an attribute generative adversarial network architecture. We conduct extensive analysis in standard large scale datasets and our model achieves significant performance both quantitatively and qualitatively.
Facial Landmark Detection with Tweaked Convolutional Neural Networks
Mar 21, 2016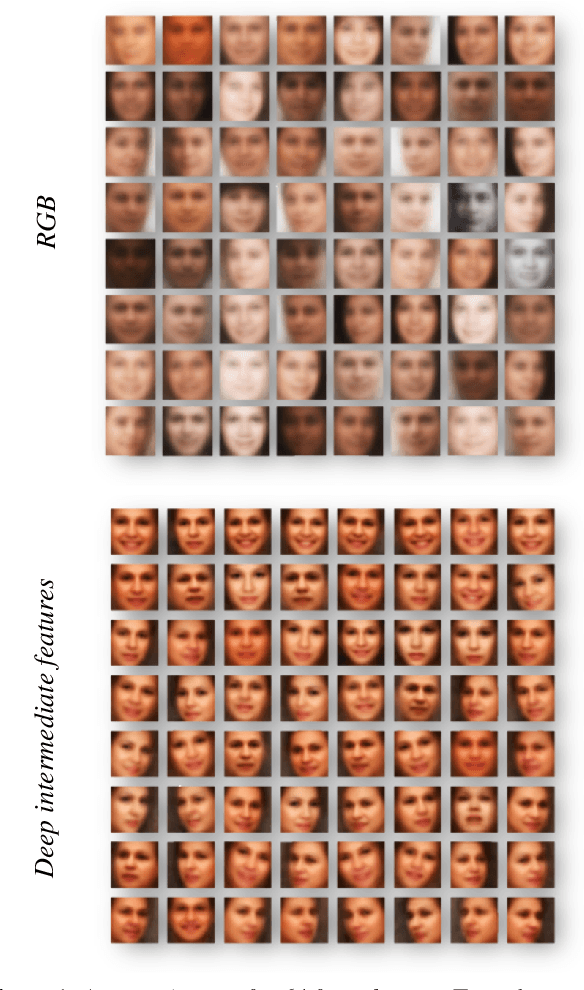


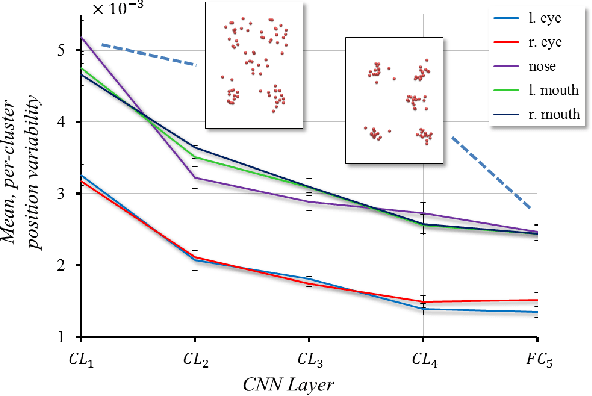
We present a novel convolutional neural network (CNN) design for facial landmark coordinate regression. We examine the intermediate features of a standard CNN trained for landmark detection and show that features extracted from later, more specialized layers capture rough landmark locations. This provides a natural means of applying differential treatment midway through the network, tweaking processing based on facial alignment. The resulting Tweaked CNN model (TCNN) harnesses the robustness of CNNs for landmark detection, in an appearance-sensitive manner without training multi-part or multi-scale models. Our results on standard face landmark detection and face verification benchmarks show TCNN to surpasses previously published performances by wide margins.
GMFIM: A Generative Mask-guided Facial Image Manipulation Model for Privacy Preservation
Jan 10, 2022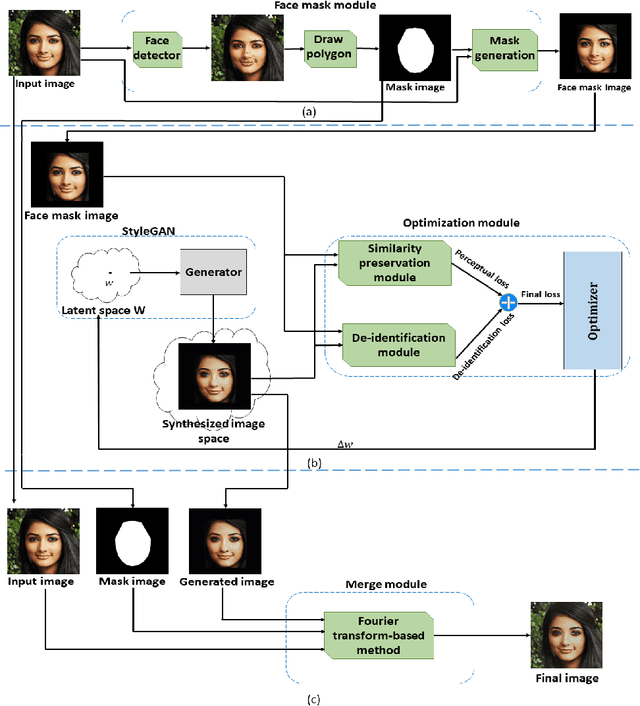



The use of social media websites and applications has become very popular and people share their photos on these networks. Automatic recognition and tagging of people's photos on these networks has raised privacy preservation issues and users seek methods for hiding their identities from these algorithms. Generative adversarial networks (GANs) are shown to be very powerful in generating face images in high diversity and also in editing face images. In this paper, we propose a Generative Mask-guided Face Image Manipulation (GMFIM) model based on GANs to apply imperceptible editing to the input face image to preserve the privacy of the person in the image. Our model consists of three main components: a) the face mask module to cut the face area out of the input image and omit the background, b) the GAN-based optimization module for manipulating the face image and hiding the identity and, c) the merge module for combining the background of the input image and the manipulated de-identified face image. Different criteria are considered in the loss function of the optimization step to produce high-quality images that are as similar as possible to the input image while they cannot be recognized by AFR systems. The results of the experiments on different datasets show that our model can achieve better performance against automated face recognition systems in comparison to the state-of-the-art methods and it catches a higher attack success rate in most experiments from a total of 18. Moreover, the generated images of our proposed model have the highest quality and are more pleasing to human eyes.
Improved Search Strategies for Determining Facial Expression
Dec 07, 2018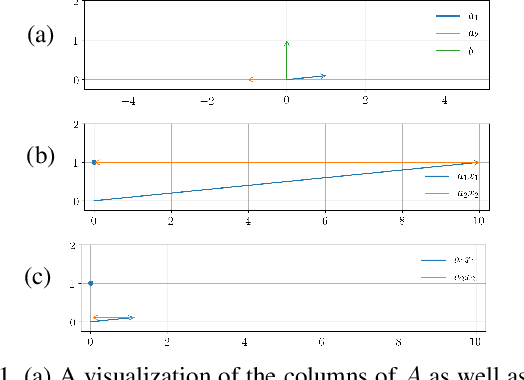
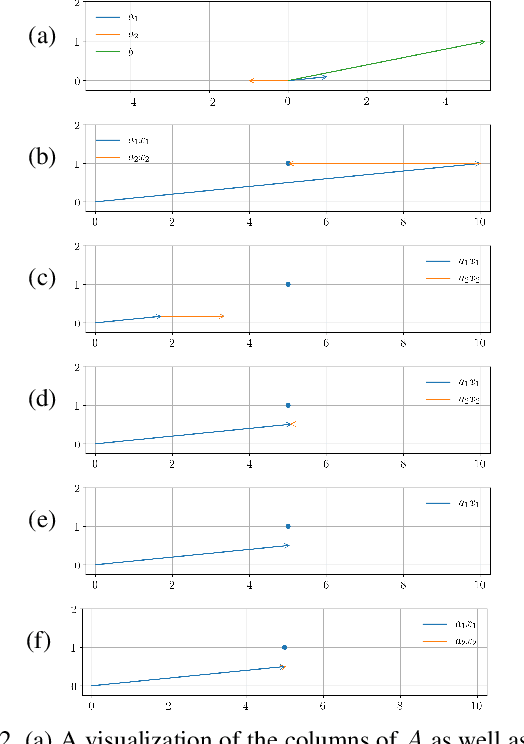
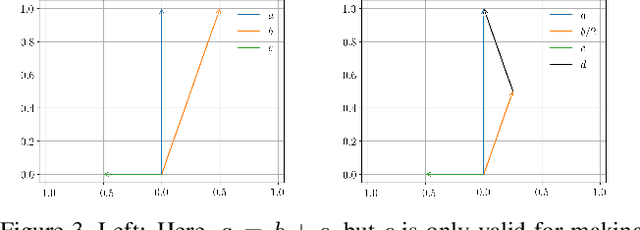
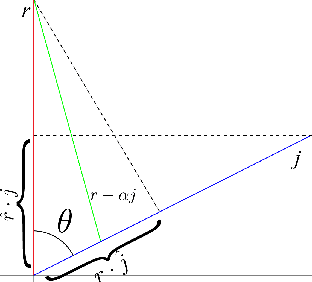
It is well known that popular optimization techniques can lead to overfitting or even a lack of convergence altogether; thus, practitioners often utilize ad hoc regularization terms added to the energy functional. When carefully crafted, these regularizations can produce compelling results. However, regularization changes both the energy landscape and the solution to the optimization problem, which can result in underfitting. Surprisingly, many practitioners both add regularization and claim that their model lacks the expressivity to fit the data. Motivated by a geometric interpretation of the linearized search space, we propose an approach that ameliorates overfitting without the need for regularization terms that restrict the expressiveness of the underlying model. We illustrate the efficacy of our approach on minimization problems related to three-dimensional facial expression estimation where overfitting clouds semantic understanding and regularization may lead to underfitting that misses or misinterprets subtle expressions.
Improving Makeup Face Verification by Exploring Part-Based Representations
Jan 18, 2021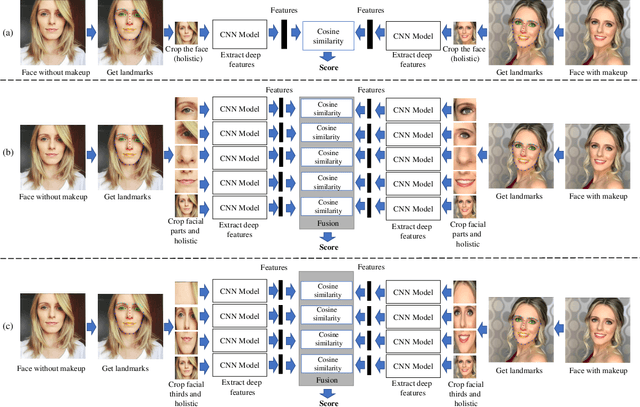

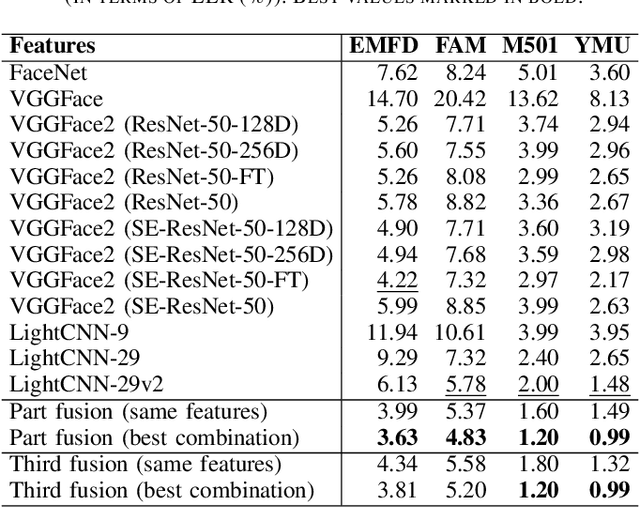
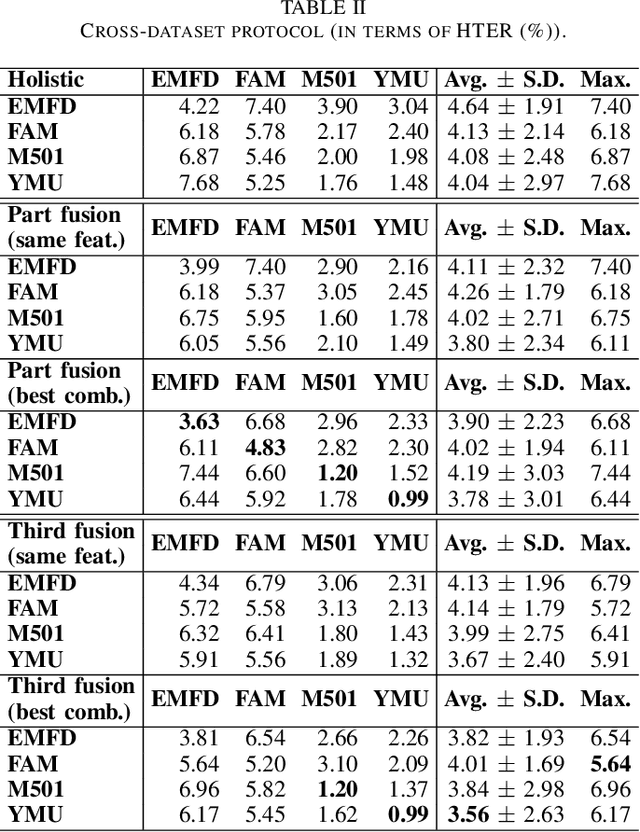
Recently, we have seen an increase in the global facial recognition market size. Despite significant advances in face recognition technology with the adoption of convolutional neural networks, there are still open challenges, as when there is makeup in the face. To address this challenge, we propose and evaluate the adoption of facial parts to fuse with current holistic representations. We propose two strategies of facial parts: one with four regions (left periocular, right periocular, nose and mouth) and another with three facial thirds (upper, middle and lower). Experimental results obtained in four public makeup face datasets and in a challenging cross-dataset protocol show that the fusion of deep features extracted of facial parts with holistic representation increases the accuracy of face verification systems and decreases the error rates, even without any retraining of the CNN models. Our proposed pipeline achieved state-of-the-art performance for the YMU dataset and competitive results for other three datasets (EMFD, FAM and M501).
Multi-Modal Learning for AU Detection Based on Multi-Head Fused Transformers
Mar 22, 2022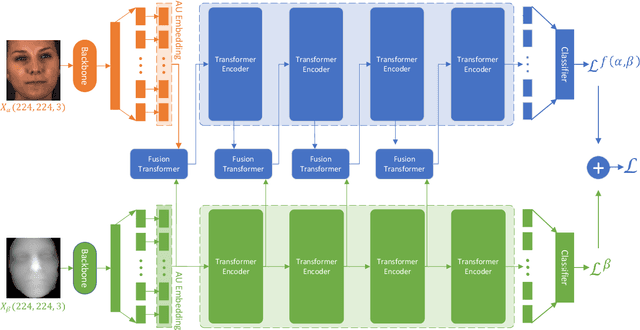
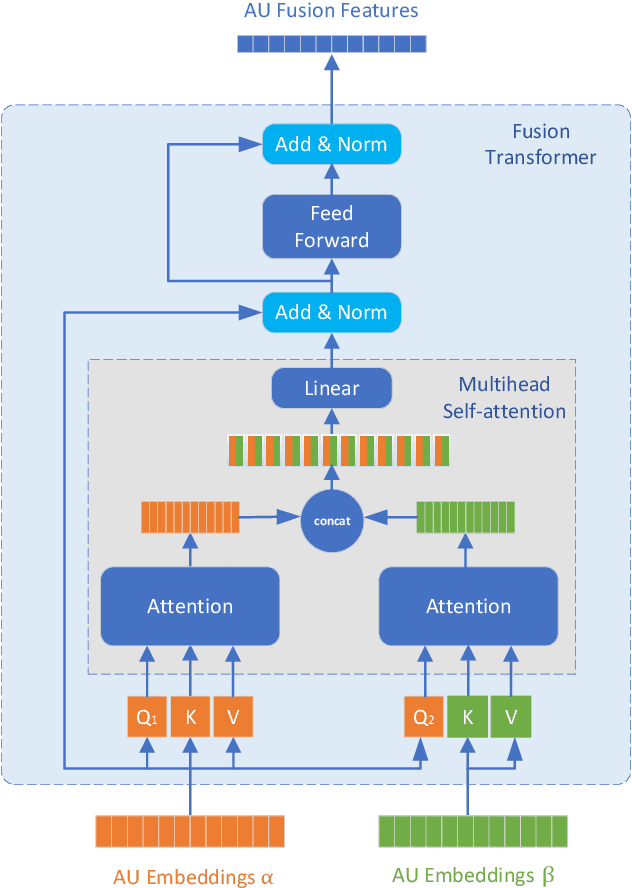
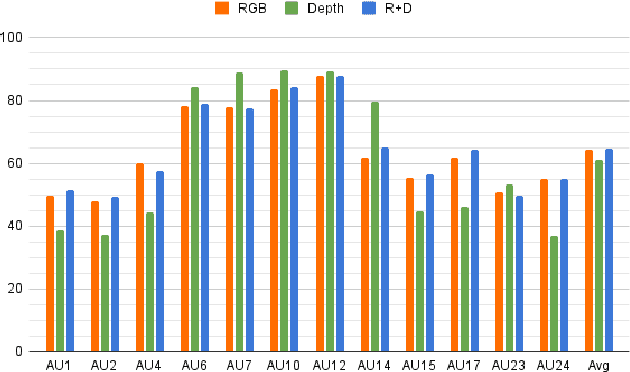
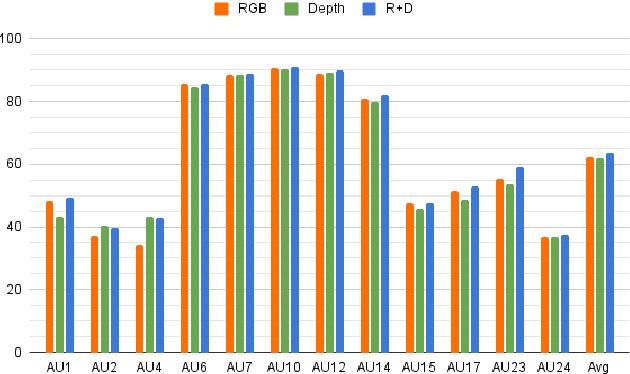
Multi-modal learning has been intensified in recent years, especially for applications in facial analysis and action unit detection whilst there still exist two main challenges in terms of 1) relevant feature learning for representation and 2) efficient fusion for multi-modalities. Recently, there are a number of works have shown the effectiveness in utilizing the attention mechanism for AU detection, however, most of them are binding the region of interest (ROI) with features but rarely apply attention between features of each AU. On the other hand, the transformer, which utilizes a more efficient self-attention mechanism, has been widely used in natural language processing and computer vision tasks but is not fully explored in AU detection tasks. In this paper, we propose a novel end-to-end Multi-Head Fused Transformer (MFT) method for AU detection, which learns AU encoding features representation from different modalities by transformer encoder and fuses modalities by another fusion transformer module. Multi-head fusion attention is designed in the fusion transformer module for the effective fusion of multiple modalities. Our approach is evaluated on two public multi-modal AU databases, BP4D, and BP4D+, and the results are superior to the state-of-the-art algorithms and baseline models. We further analyze the performance of AU detection from different modalities.
Semi-Latent GAN: Learning to generate and modify facial images from attributes
Apr 07, 2017
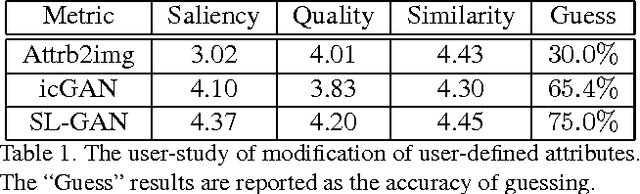
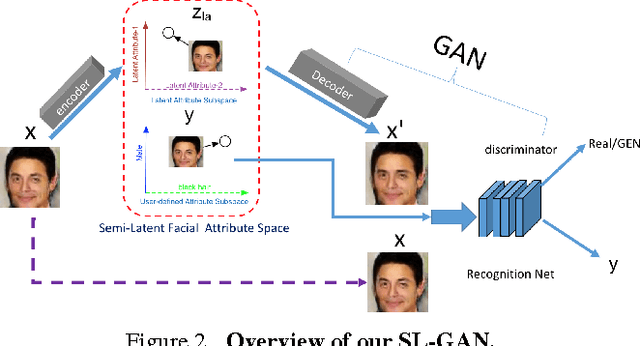
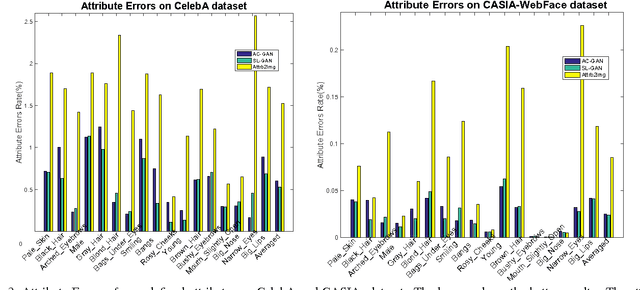
Generating and manipulating human facial images using high-level attributal controls are important and interesting problems. The models proposed in previous work can solve one of these two problems (generation or manipulation), but not both coherently. This paper proposes a novel model that learns how to both generate and modify the facial image from high-level semantic attributes. Our key idea is to formulate a Semi-Latent Facial Attribute Space (SL-FAS) to systematically learn relationship between user-defined and latent attributes, as well as between those attributes and RGB imagery. As part of this newly formulated space, we propose a new model --- SL-GAN which is a specific form of Generative Adversarial Network. Finally, we present an iterative training algorithm for SL-GAN. The experiments on recent CelebA and CASIA-WebFace datasets validate the effectiveness of our proposed framework. We will also make data, pre-trained models and code available.
LandmarkGAN: Synthesizing Faces from Landmarks
Oct 31, 2020
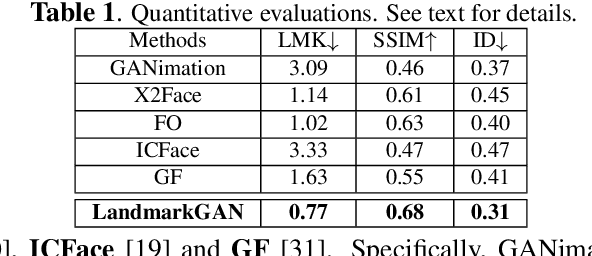
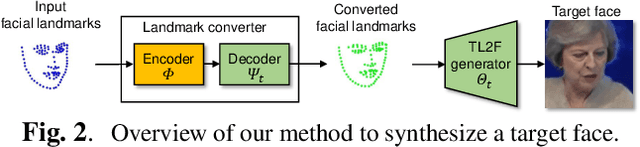
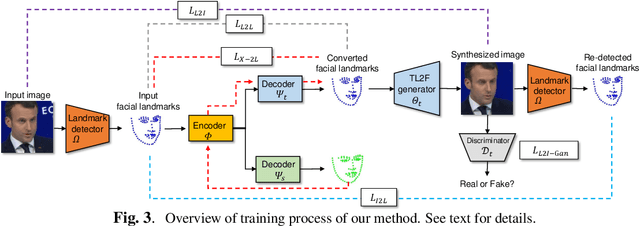
Face synthesis is an important problem in computer vision with many applications. In this work, we describe a new method, namely LandmarkGAN, to synthesize faces based on facial landmarks as input. Facial landmarks are a natural, intuitive, and effective representation for facial expressions and orientations, which are independent from the target's texture or color and background scene. Our method is able to transform a set of facial landmarks into new faces of different subjects, while retains the same facial expression and orientation. Experimental results on face synthesis and reenactments demonstrate the effectiveness of our method.