 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Multi-modal Affect Analysis using standardized data within subjects in the Wild
Jul 10, 2021
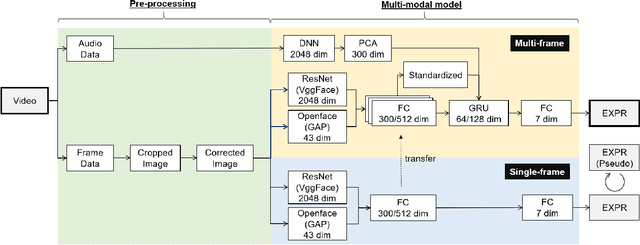


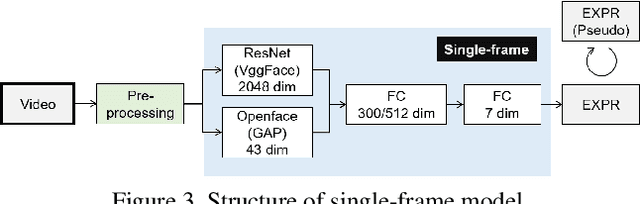
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on facial expression (EXP) and valence-arousal calculation that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest. When annotating facial expressions from a video, we thought that it would be judged not only from the features common to all people, but also from the relative changes in the time series of individuals. Therefore, after learning the common features for each frame, we constructed a facial expression estimation model and valence-arousal model using time-series data after combining the common features and the standardized features for each video. Furthermore, the above features were learned using multi-modal data such as image features, AU, Head pose, and Gaze. In the validation set, our model achieved a facial expression score of 0.546. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.
Objective Classes for Micro-Facial Expression Recognition
Dec 03, 2017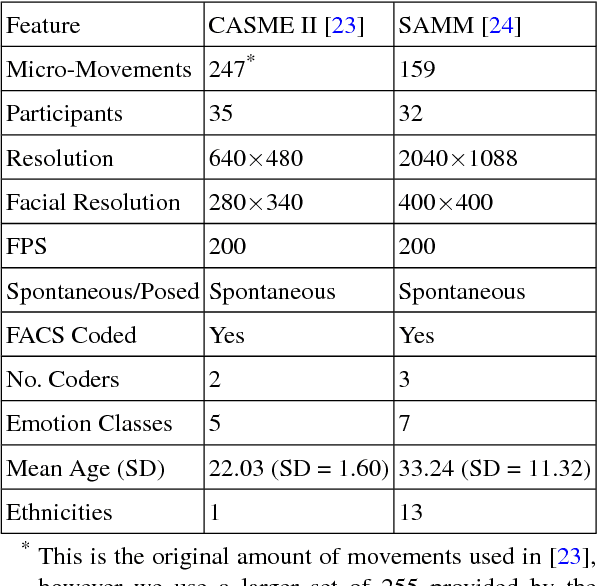



Micro-expressions are brief spontaneous facial expressions that appear on a face when a person conceals an emotion, making them different to normal facial expressions in subtlety and duration. Currently, emotion classes within the CASME II dataset are based on Action Units and self-reports, creating conflicts during machine learning training. We will show that classifying expressions using Action Units, instead of predicted emotion, removes the potential bias of human reporting. The proposed classes are tested using LBP-TOP, HOOF and HOG 3D feature descriptors. The experiments are evaluated on two benchmark FACS coded datasets: CASME II and SAMM. The best result achieves 86.35\% accuracy when classifying the proposed 5 classes on CASME II using HOG 3D, outperforming the result of the state-of-the-art 5-class emotional-based classification in CASME II. Results indicate that classification based on Action Units provides an objective method to improve micro-expression recognition.
Detecting facial landmarks in the video based on a hybrid framework
Sep 21, 2016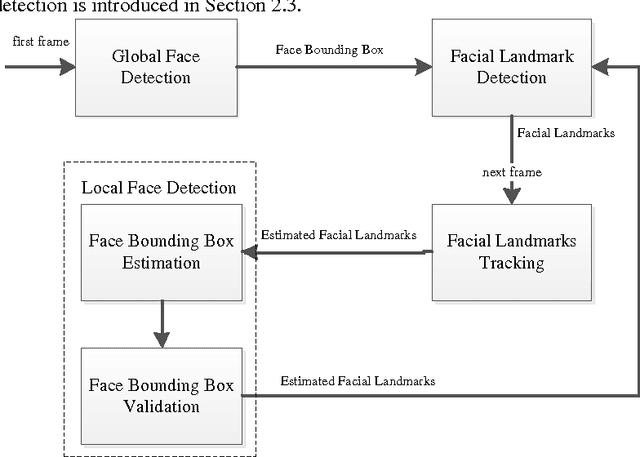



To dynamically detect the facial landmarks in the video, we propose a novel hybrid framework termed as detection-tracking-detection (DTD). First, the face bounding box is achieved from the first frame of the video sequence based on a traditional face detection method. Then, a landmark detector detects the facial landmarks, which is based on a cascaded deep convolution neural network (DCNN). Next, the face bounding box in the current frame is estimated and validated after the facial landmarks in the previous frame are tracked based on the median flow. Finally, the facial landmarks in the current frame are exactly detected from the validated face bounding box via the landmark detector. Experimental results indicate that the proposed framework can detect the facial landmarks in the video sequence more effectively and with lower consuming time compared to the frame-by-frame method via the DCNN.
Dynamic Bayesian Network Modelling of User Affect and Perceptions of a Teleoperated Robot Coach during Longitudinal Mindfulness Training
Dec 06, 2021
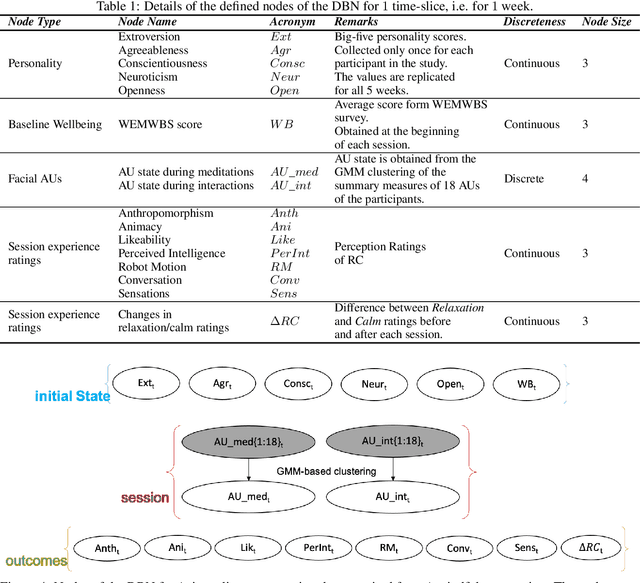

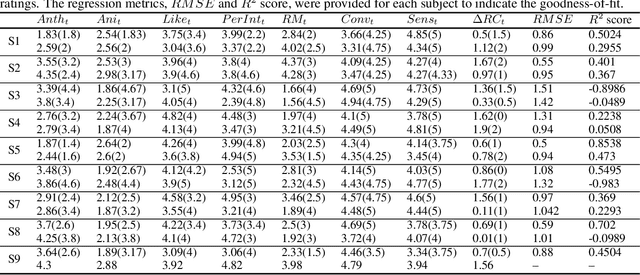
Longitudinal interaction studies with Socially Assistive Robots are crucial to ensure that the robot is relevant for long-term use and its perceptions are not prone to the novelty effect. In this paper, we present a dynamic Bayesian network (DBN) to capture the longitudinal interactions participants had with a teleoperated robot coach (RC) delivering mindfulness sessions. The DBN model is used to study complex, temporal interactions between the participants self-reported personality traits, weekly baseline wellbeing scores, session ratings, and facial AUs elicited during the sessions in a 5-week longitudinal study. DBN modelling involves learning a graphical representation that facilitates intuitive understanding of how multiple components contribute to the longitudinal changes in session ratings corresponding to the perceptions of the RC, and participants relaxation and calm levels. The learnt model captures the following within and between sessions aspects of the longitudinal interaction study: influence of the 5 personality dimensions on the facial AU states and the session ratings, influence of facial AU states on the session ratings, and the influences within the items of the session ratings. The DBN structure is learnt using first 3 time points and the obtained model is used to predict the session ratings of the last 2 time points of the 5-week longitudinal data. The predictions are quantified using subject-wise RMSE and R2 scores. We also demonstrate two applications of the model, namely, imputation of missing values in the dataset and estimation of longitudinal session ratings of a new participant with a given personality profile. The obtained DBN model thus facilitates learning of conditional dependency structure between variables in the longitudinal data and offers inferences and conceptual understanding which are not possible through other regression methodologies.
A Latent Transformer for Disentangled and Identity-Preserving Face Editing
Jun 22, 2021
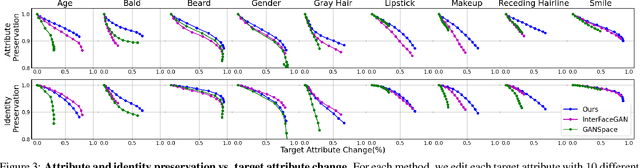


High quality facial image editing is a challenging problem in the movie post-production industry, requiring a high degree of control and identity preservation. Previous works that attempt to tackle this problem may suffer from the entanglement of facial attributes and the loss of the person's identity. Furthermore, many algorithms are limited to a certain task. To tackle these limitations, we propose to edit facial attributes via the latent space of a StyleGAN generator, by training a dedicated latent transformation network and incorporating explicit disentanglement and identity preservation terms in the loss function. We further introduce a pipeline to generalize our face editing to videos. Our model achieves a disentangled, controllable, and identity-preserving facial attribute editing, even in the challenging case of real (i.e., non-synthetic) images and videos. We conduct extensive experiments on image and video datasets and show that our model outperforms other state-of-the-art methods in visual quality and quantitative evaluation.
Where Is My Puppy? Retrieving Lost Dogs by Facial Features
Aug 01, 2016
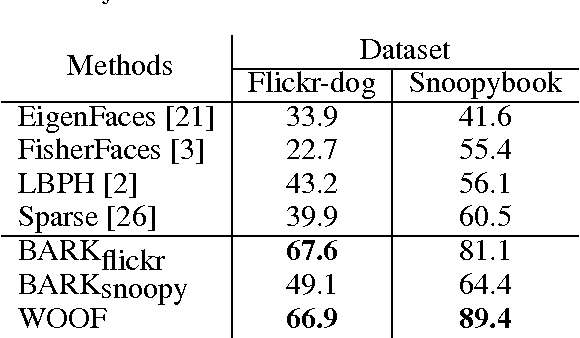

A pet that goes missing is among many people's worst fears: a moment of distraction is enough for a dog or a cat wandering off from home. Some measures help matching lost animals to their owners; but automated visual recognition is one that - although convenient, highly available, and low-cost - is surprisingly overlooked. In this paper, we inaugurate that promising avenue by pursuing face recognition for dogs. We contrast four ready-to-use human facial recognizers (EigenFaces, FisherFaces, LBPH, and a Sparse method) to two original solutions based upon convolutional neural networks: BARK (inspired in architecture-optimized networks employed for human facial recognition) and WOOF (based upon off-the-shelf OverFeat features). Human facial recognizers perform poorly for dogs (up to 60.5% accuracy), showing that dog facial recognition is not a trivial extension of human facial recognition. The convolutional network solutions work much better, with BARK attaining up to 81.1% accuracy, and WOOF, 89.4%. The tests were conducted in two datasets: Flickr-dog, with 42 dogs of two breeds (pugs and huskies); and Snoopybook, with 18 mongrel dogs.
Generator From Edges: Reconstruction of Facial Images
Feb 22, 2020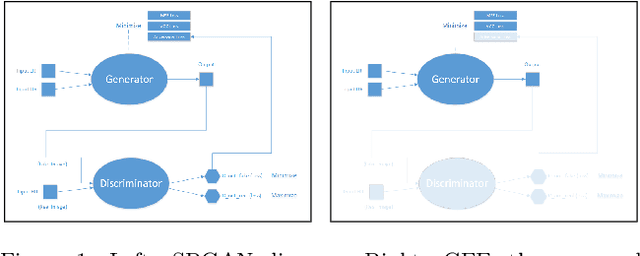


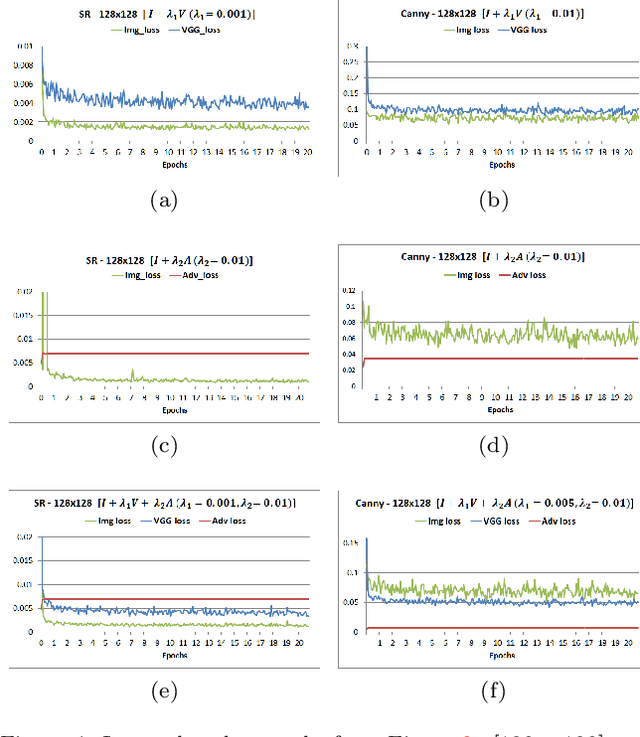
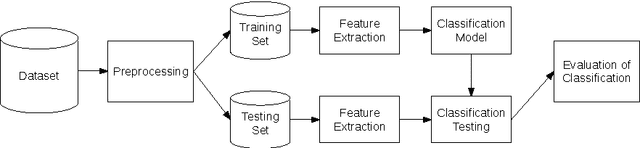
Applications that involve supervised training require paired images. Researchers of single image super-resolution (SISR) create such images by artificially generating blurry input images from the corresponding ground truth. Similarly we can create paired images with the canny edge. We propose Generator From Edges (GFE) [Figure 2]. Our aim is to determine the best architecture for GFE, along with reviews of perceptual loss [1, 2]. To this end, we conducted three experiments. First, we explored the effects of the adversarial loss often used in SISR. In particular, we uncovered that it is not an essential component to form a perceptual loss. Eliminating adversarial loss will lead to a more effective architecture from the perspective of hardware resource. It also means that considerations for the problems pertaining to generative adversarial network (GAN) [3], such as mode collapse, are not necessary. Second, we reexamined VGG loss and found that the mid-layers yield the best results. By extracting the full potential of VGG loss, the overall performance of perceptual loss improves significantly. Third, based on the findings of the first two experiments, we reevaluated the dense network to construct GFE. Using GFE as an intermediate process, reconstructing a facial image from a pencil sketch can become an easy task.
EyeNeRF: A Hybrid Representation for Photorealistic Synthesis, Animation and Relighting of Human Eyes
Jun 16, 2022
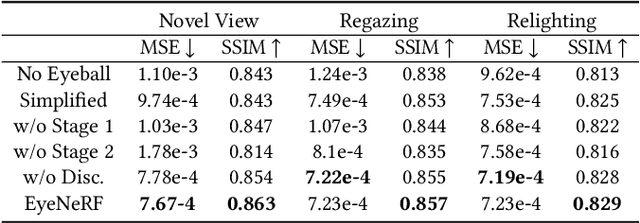
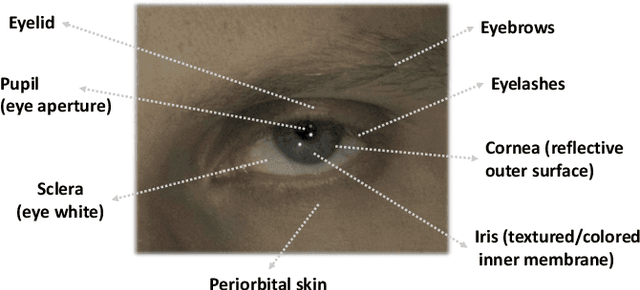
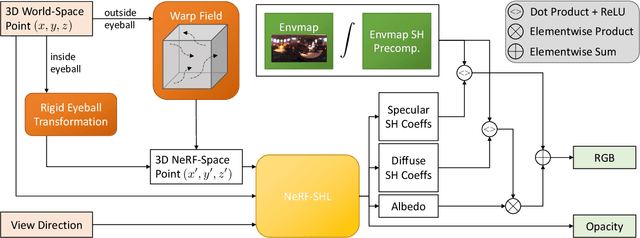
A unique challenge in creating high-quality animatable and relightable 3D avatars of people is modeling human eyes. The challenge of synthesizing eyes is multifold as it requires 1) appropriate representations for the various components of the eye and the periocular region for coherent viewpoint synthesis, capable of representing diffuse, refractive and highly reflective surfaces, 2) disentangling skin and eye appearance from environmental illumination such that it may be rendered under novel lighting conditions, and 3) capturing eyeball motion and the deformation of the surrounding skin to enable re-gazing. These challenges have traditionally necessitated the use of expensive and cumbersome capture setups to obtain high-quality results, and even then, modeling of the eye region holistically has remained elusive. We present a novel geometry and appearance representation that enables high-fidelity capture and photorealistic animation, view synthesis and relighting of the eye region using only a sparse set of lights and cameras. Our hybrid representation combines an explicit parametric surface model for the eyeball with implicit deformable volumetric representations for the periocular region and the interior of the eye. This novel hybrid model has been designed to address the various parts of that challenging facial area - the explicit eyeball surface allows modeling refraction and high-frequency specular reflection at the cornea, whereas the implicit representation is well suited to model lower-frequency skin reflection via spherical harmonics and can represent non-surface structures such as hair or diffuse volumetric bodies, both of which are a challenge for explicit surface models. We show that for high-resolution close-ups of the eye, our model can synthesize high-fidelity animated gaze from novel views under unseen illumination conditions.