 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
The Swiss Army Knife for Image-to-Image Translation: Multi-Task Diffusion Models
Apr 06, 2022
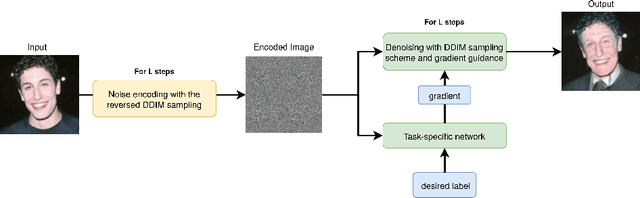



Recently, diffusion models were applied to a wide range of image analysis tasks. We build on a method for image-to-image translation using denoising diffusion implicit models and include a regression problem and a segmentation problem for guiding the image generation to the desired output. The main advantage of our approach is that the guidance during the denoising process is done by an external gradient. Consequently, the diffusion model does not need to be retrained for the different tasks on the same dataset. We apply our method to simulate the aging process on facial photos using a regression task, as well as on a brain magnetic resonance (MR) imaging dataset for the simulation of brain tumor growth. Furthermore, we use a segmentation model to inpaint tumors at the desired location in healthy slices of brain MR images. We achieve convincing results for all problems.
End-to-end Learning for 3D Facial Animation from Raw Waveforms of Speech
Dec 07, 2017
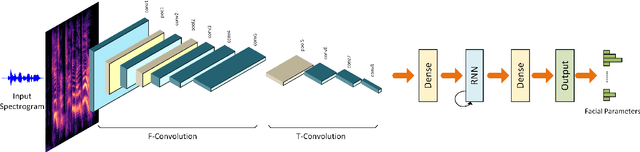

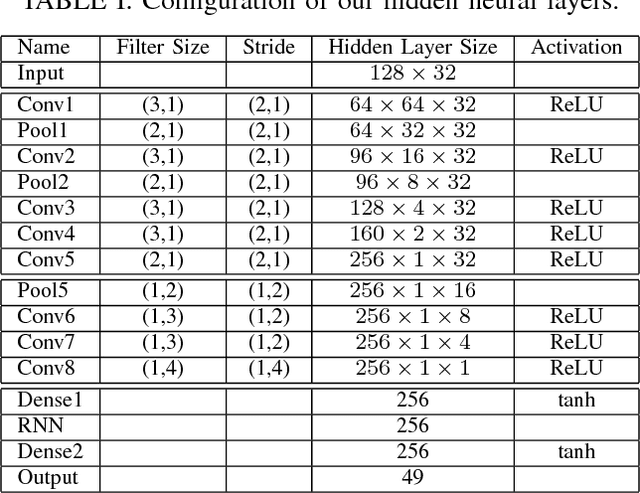
We present a deep learning framework for real-time speech-driven 3D facial animation from just raw waveforms. Our deep neural network directly maps an input sequence of speech audio to a series of micro facial action unit activations and head rotations to drive a 3D blendshape face model. In particular, our deep model is able to learn the latent representations of time-varying contextual information and affective states within the speech. Hence, our model not only activates appropriate facial action units at inference to depict different utterance generating actions, in the form of lip movements, but also, without any assumption, automatically estimates emotional intensity of the speaker and reproduces her ever-changing affective states by adjusting strength of facial unit activations. For example, in a happy speech, the mouth opens wider than normal, while other facial units are relaxed; or in a surprised state, both eyebrows raise higher. Experiments on a diverse audiovisual corpus of different actors across a wide range of emotional states show interesting and promising results of our approach. Being speaker-independent, our generalized model is readily applicable to various tasks in human-machine interaction and animation.
Comparing Human and Machine Bias in Face Recognition
Oct 25, 2021
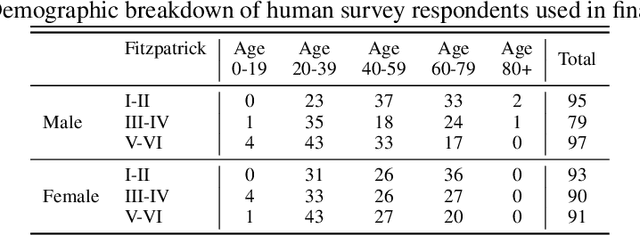

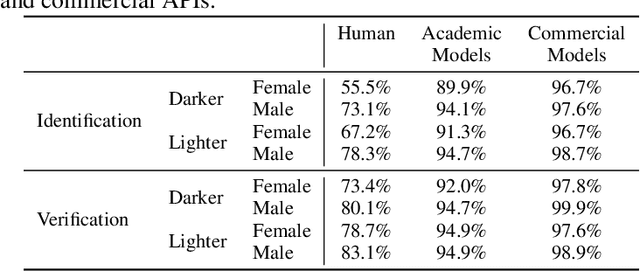
Much recent research has uncovered and discussed serious concerns of bias in facial analysis technologies, finding performance disparities between groups of people based on perceived gender, skin type, lighting condition, etc. These audits are immensely important and successful at measuring algorithmic bias but have two major challenges: the audits (1) use facial recognition datasets which lack quality metadata, like LFW and CelebA, and (2) do not compare their observed algorithmic bias to the biases of their human alternatives. In this paper, we release improvements to the LFW and CelebA datasets which will enable future researchers to obtain measurements of algorithmic bias that are not tainted by major flaws in the dataset (e.g. identical images appearing in both the gallery and test set). We also use these new data to develop a series of challenging facial identification and verification questions that we administered to various algorithms and a large, balanced sample of human reviewers. We find that both computer models and human survey participants perform significantly better at the verification task, generally obtain lower accuracy rates on dark-skinned or female subjects for both tasks, and obtain higher accuracy rates when their demographics match that of the question. Computer models are observed to achieve a higher level of accuracy than the survey participants on both tasks and exhibit bias to similar degrees as the human survey participants.
Interactive Generative Adversarial Networks for Facial Expression Generation in Dyadic Interactions
Jan 30, 2018


A social interaction is a social exchange between two or more individuals,where individuals modify and adjust their behaviors in response to their interaction partners. Our social interactions are one of most fundamental aspects of our lives and can profoundly affect our mood, both positively and negatively. With growing interest in virtual reality and avatar-mediated interactions,it is desirable to make these interactions natural and human like to promote positive effect in the interactions and applications such as intelligent tutoring systems, automated interview systems and e-learning. In this paper, we propose a method to generate facial behaviors for an agent. These behaviors include facial expressions and head pose and they are generated considering the users affective state. Our models learn semantically meaningful representations of the face and generate appropriate and temporally smooth facial behaviors in dyadic interactions.
Super-realtime facial landmark detection and shape fitting by deep regression of shape model parameters
Feb 09, 2019

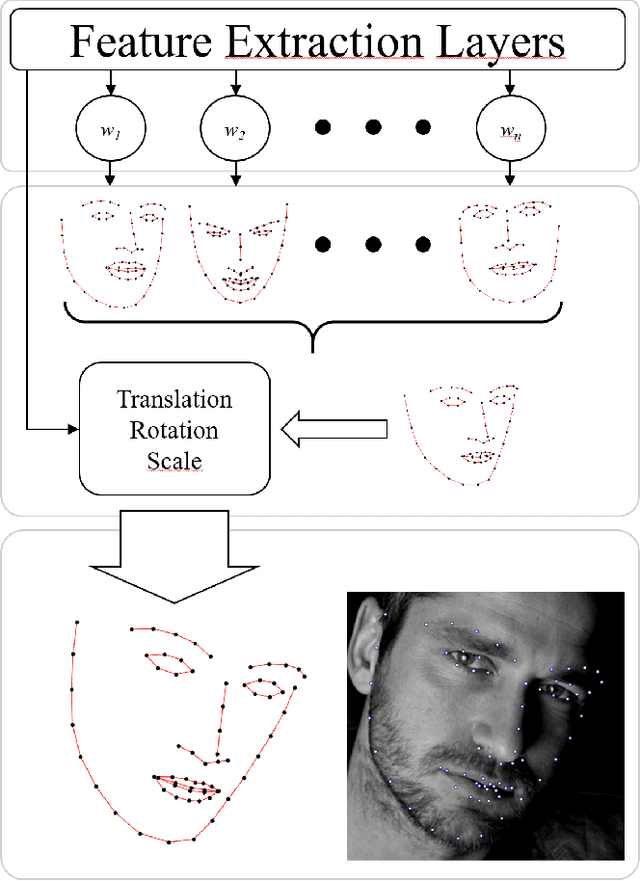
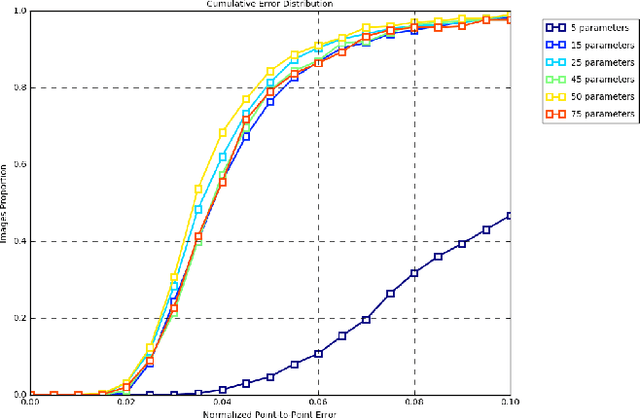
We present a method for highly efficient landmark detection that combines deep convolutional neural networks with well established model-based fitting algorithms. Motivated by established model-based fitting methods such as active shapes, we use a PCA of the landmark positions to allow generative modeling of facial landmarks. Instead of computing the model parameters using iterative optimization, the PCA is included in a deep neural network using a novel layer type. The network predicts model parameters in a single forward pass, thereby allowing facial landmark detection at several hundreds of frames per second. Our architecture allows direct end-to-end training of a model-based landmark detection method and shows that deep neural networks can be used to reliably predict model parameters directly without the need for an iterative optimization. The method is evaluated on different datasets for facial landmark detection and medical image segmentation. PyTorch code is freely available at https://github.com/justusschock/shapenet
Pose-variant 3D Facial Attribute Generation
Jul 24, 2019
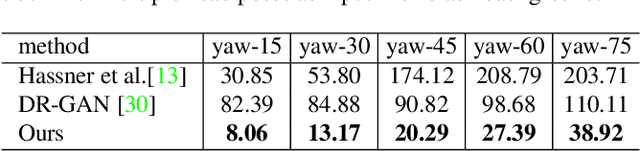

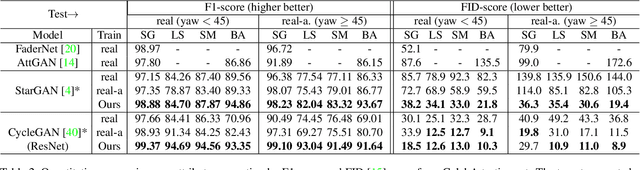
We address the challenging problem of generating facial attributes using a single image in an unconstrained pose. In contrast to prior works that largely consider generation on 2D near-frontal images, we propose a GAN-based framework to generate attributes directly on a dense 3D representation given by UV texture and position maps, resulting in photorealistic, geometrically-consistent and identity-preserving outputs. Starting from a self-occluded UV texture map obtained by applying an off-the-shelf 3D reconstruction method, we propose two novel components. First, a texture completion generative adversarial network (TC-GAN) completes the partial UV texture map. Second, a 3D attribute generation GAN (3DA-GAN) synthesizes the target attribute while obtaining an appearance consistent with 3D face geometry and preserving identity. Extensive experiments on CelebA, LFW and IJB-A show that our method achieves consistently better attribute generation accuracy than prior methods, a higher degree of qualitative photorealism and preserves face identity information.
Topologically Consistent Multi-View Face Inference Using Volumetric Sampling
Oct 06, 2021High-fidelity face digitization solutions often combine multi-view stereo (MVS) techniques for 3D reconstruction and a non-rigid registration step to establish dense correspondence across identities and expressions. A common problem is the need for manual clean-up after the MVS step, as 3D scans are typically affected by noise and outliers and contain hairy surface regions that need to be cleaned up by artists. Furthermore, mesh registration tends to fail for extreme facial expressions. Most learning-based methods use an underlying 3D morphable model (3DMM) to ensure robustness, but this limits the output accuracy for extreme facial expressions. In addition, the global bottleneck of regression architectures cannot produce meshes that tightly fit the ground truth surfaces. We propose ToFu, Topologically consistent Face from multi-view, a geometry inference framework that can produce topologically consistent meshes across facial identities and expressions using a volumetric representation instead of an explicit underlying 3DMM. Our novel progressive mesh generation network embeds the topological structure of the face in a feature volume, sampled from geometry-aware local features. A coarse-to-fine architecture facilitates dense and accurate facial mesh predictions in a consistent mesh topology. ToFu further captures displacement maps for pore-level geometric details and facilitates high-quality rendering in the form of albedo and specular reflectance maps. These high-quality assets are readily usable by production studios for avatar creation, animation and physically-based skin rendering. We demonstrate state-of-the-art geometric and correspondence accuracy, while only taking 0.385 seconds to compute a mesh with 10K vertices, which is three orders of magnitude faster than traditional techniques. The code and the model are available for research purposes at https://tianyeli.github.io/tofu.
Fast-GANFIT: Generative Adversarial Network for High Fidelity 3D Face Reconstruction
May 16, 2021
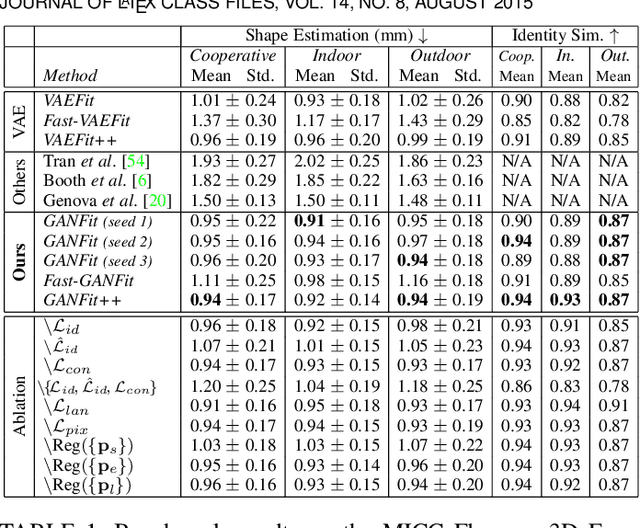
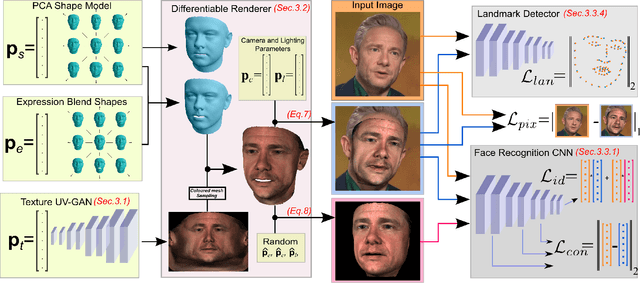
A lot of work has been done towards reconstructing the 3D facial structure from single images by capitalizing on the power of Deep Convolutional Neural Networks (DCNNs). In the recent works, the texture features either correspond to components of a linear texture space or are learned by auto-encoders directly from in-the-wild images. In all cases, the quality of the facial texture reconstruction is still not capable of modeling facial texture with high-frequency details. In this paper, we take a radically different approach and harness the power of Generative Adversarial Networks (GANs) and DCNNs in order to reconstruct the facial texture and shape from single images. That is, we utilize GANs to train a very powerful facial texture prior \edit{from a large-scale 3D texture dataset}. Then, we revisit the original 3D Morphable Models (3DMMs) fitting making use of non-linear optimization to find the optimal latent parameters that best reconstruct the test image but under a new perspective. In order to be robust towards initialisation and expedite the fitting process, we propose a novel self-supervised regression based approach. We demonstrate excellent results in photorealistic and identity preserving 3D face reconstructions and achieve for the first time, to the best of our knowledge, facial texture reconstruction with high-frequency details.
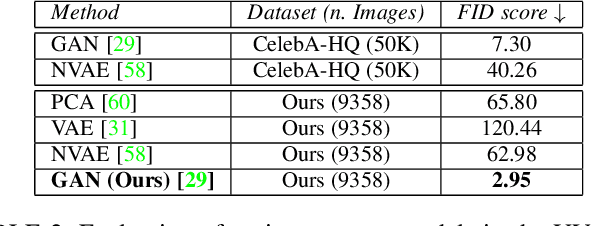
SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction
Jan 19, 2018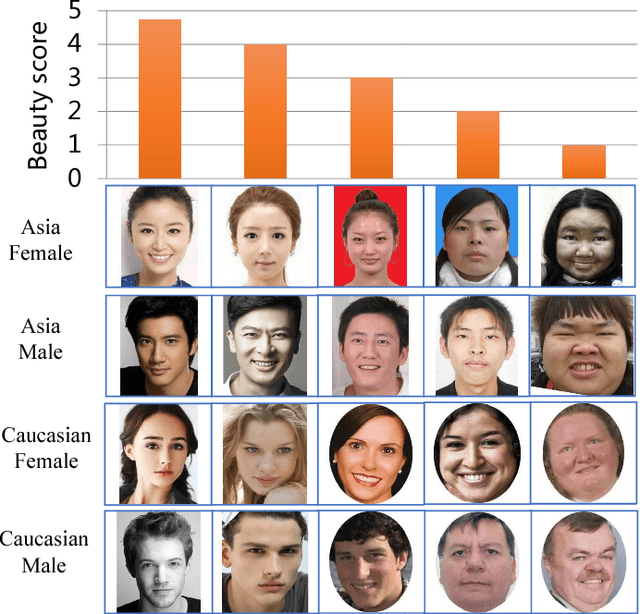
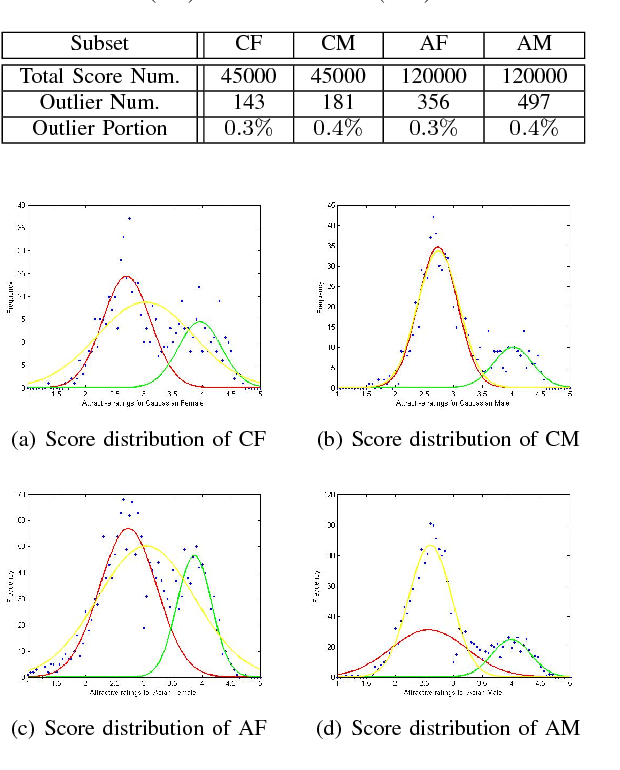
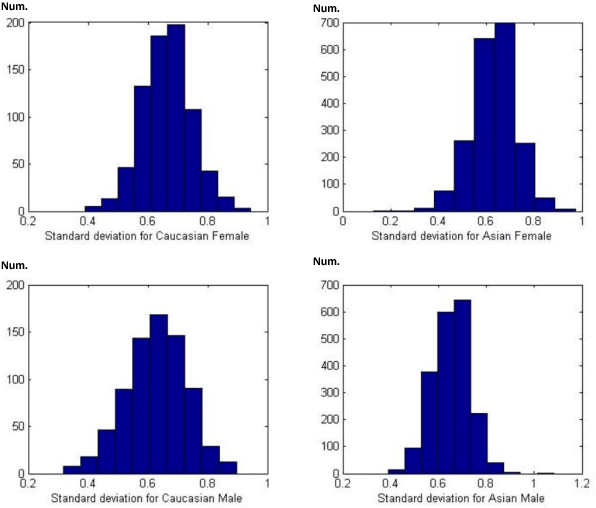
Facial beauty prediction (FBP) is a significant visual recognition problem to make assessment of facial attractiveness that is consistent to human perception. To tackle this problem, various data-driven models, especially state-of-the-art deep learning techniques, were introduced, and benchmark dataset become one of the essential elements to achieve FBP. Previous works have formulated the recognition of facial beauty as a specific supervised learning problem of classification, regression or ranking, which indicates that FBP is intrinsically a computation problem with multiple paradigms. However, most of FBP benchmark datasets were built under specific computation constrains, which limits the performance and flexibility of the computational model trained on the dataset. In this paper, we argue that FBP is a multi-paradigm computation problem, and propose a new diverse benchmark dataset, called SCUT-FBP5500, to achieve multi-paradigm facial beauty prediction. The SCUT-FBP5500 dataset has totally 5500 frontal faces with diverse properties (male/female, Asian/Caucasian, ages) and diverse labels (face landmarks, beauty scores within [1,~5], beauty score distribution), which allows different computational models with different FBP paradigms, such as appearance-based/shape-based facial beauty classification/regression model for male/female of Asian/Caucasian. We evaluated the SCUT-FBP5500 dataset for FBP using different combinations of feature and predictor, and various deep learning methods. The results indicates the improvement of FBP and the potential applications based on the SCUT-FBP5500.
Multi-modal Affect Analysis using standardized data within subjects in the Wild
Jul 10, 2021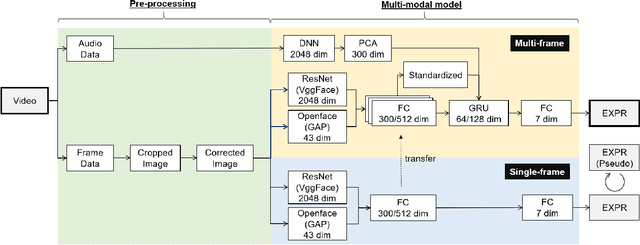


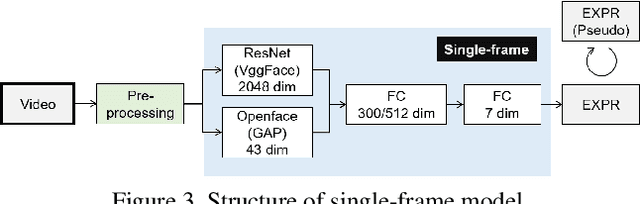
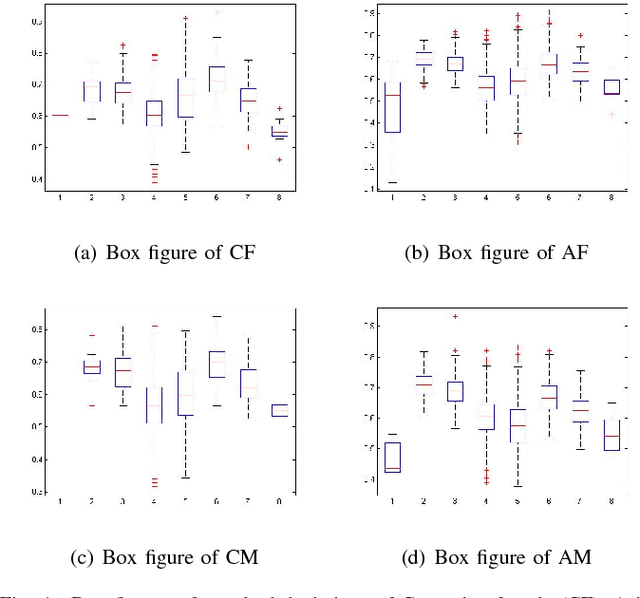
Human affective recognition is an important factor in human-computer interaction. However, the method development with in-the-wild data is not yet accurate enough for practical usage. In this paper, we introduce the affective recognition method focusing on facial expression (EXP) and valence-arousal calculation that was submitted to the Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest. When annotating facial expressions from a video, we thought that it would be judged not only from the features common to all people, but also from the relative changes in the time series of individuals. Therefore, after learning the common features for each frame, we constructed a facial expression estimation model and valence-arousal model using time-series data after combining the common features and the standardized features for each video. Furthermore, the above features were learned using multi-modal data such as image features, AU, Head pose, and Gaze. In the validation set, our model achieved a facial expression score of 0.546. These verification results reveal that our proposed framework can improve estimation accuracy and robustness effectively.