 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Recognizing Facial Expressions in the Wild using Multi-Architectural Representations based Ensemble Learning with Distillation
Jul 04, 2021
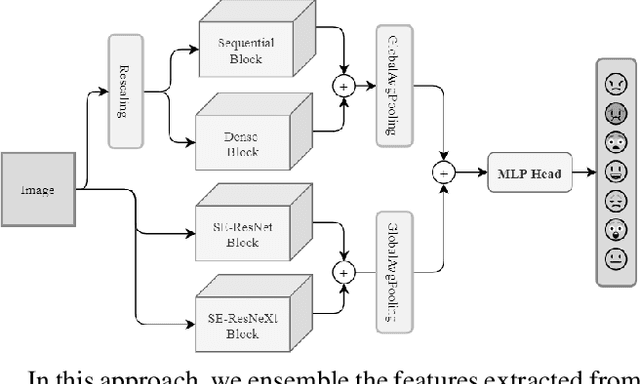
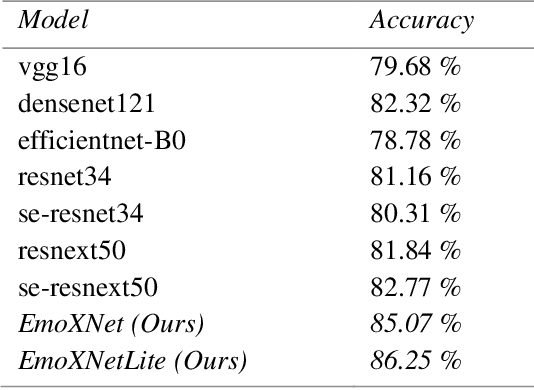
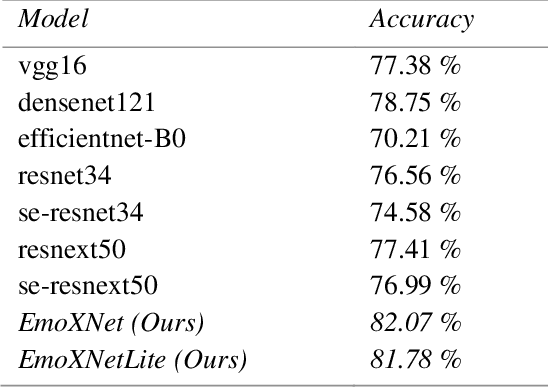

Facial expressions are the most common universal forms of body language. In the past few years, automatic facial expression recognition (FER) has been an active field of research. However, it is still a challenging task due to different uncertainties and complications. Nevertheless, efficiency and performance are yet essential aspects for building robust systems. In this work, we propose two models named EmoXNet and EmoXNetLite. EmoXNet is an ensemble learning technique for learning convoluted facial representations, whereas EmoXNetLite is a distillation technique for transferring the knowledge from our ensemble model to an efficient deep neural network using label-smoothen soft labels to detect expressions effectively in real-time. Both models attained better accuracy level in comparison to the models reported to date. The ensemble model (EmoXNet) attained 85.07% test accuracy on FER-2013 with FER+ annotations and 86.25% test accuracy on Real-world Affective Faces Database (RAF-DB). Whereas, the distilled model (EmoXNetLite) attained 82.07% test accuracy on FER-2013 with FER+ annotations and 81.78% test accuracy on RAF-DB. Results show that our models seem to generalize well on new data and are learned to focus on relevant facial representations for expressions recognition.
A Systematic Evaluation of Domain Adaptation in Facial Expression Recognition
Jun 29, 2021
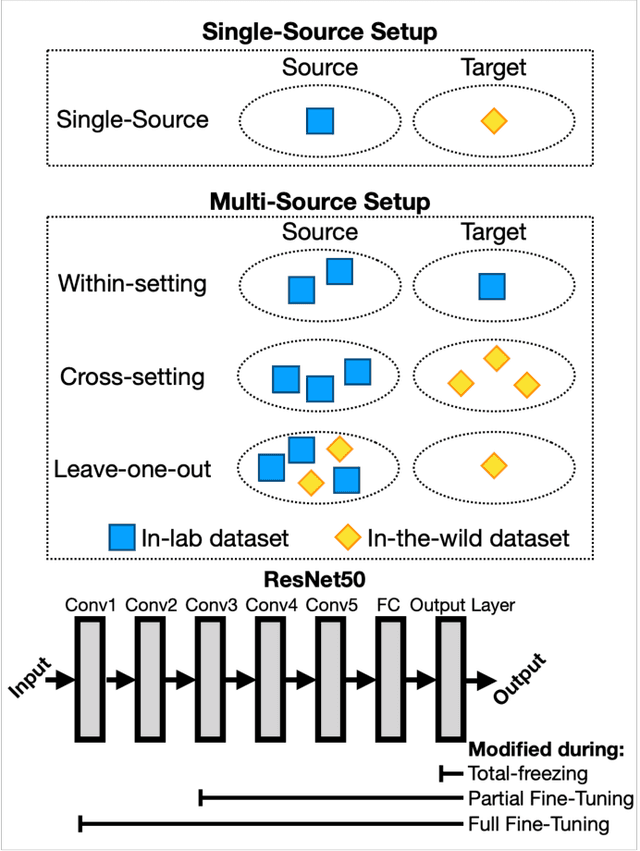

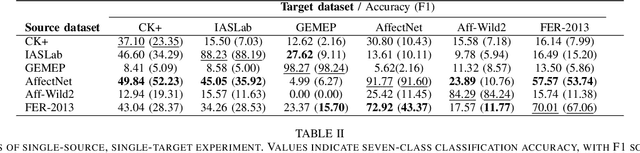
Facial Expression Recognition is a commercially important application, but one common limitation is that applications often require making predictions on out-of-sample distributions, where target images may have very different properties from the images that the model was trained on. How well, or badly, do these models do on unseen target domains? In this paper, we provide a systematic evaluation of domain adaptation in facial expression recognition. Using state-of-the-art transfer learning techniques and six commonly-used facial expression datasets (three collected in the lab and three "in-the-wild"), we conduct extensive round-robin experiments to examine the classification accuracies for a state-of-the-art CNN model. We also perform multi-source experiments where we examine a model's ability to transfer from multiple source datasets, including (i) within-setting (e.g., lab to lab), (ii) cross-setting (e.g., in-the-wild to lab), (iii) mixed-setting (e.g., lab and wild to lab) transfer learning experiments. We find sobering results that the accuracy of transfer learning is not high, and varies idiosyncratically with the target dataset, and to a lesser extent the source dataset. Generally, the best settings for transfer include fine-tuning the weights of a pre-trained model, and we find that training with more datasets, regardless of setting, improves transfer performance. We end with a discussion of the need for more -- and regular -- systematic investigations into the generalizability of FER models, especially for deployed applications.
FaceDet3D: Facial Expressions with 3D Geometric Detail Prediction
Dec 23, 2020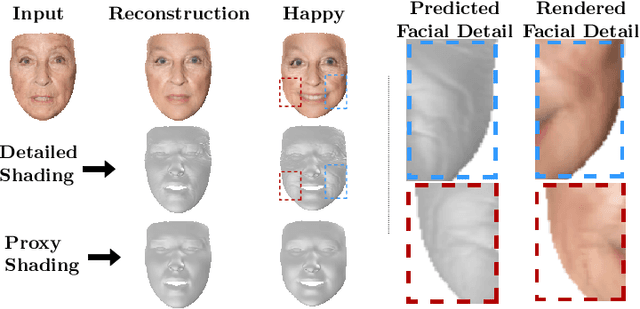
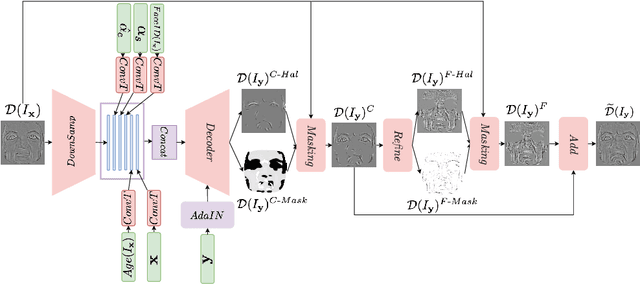
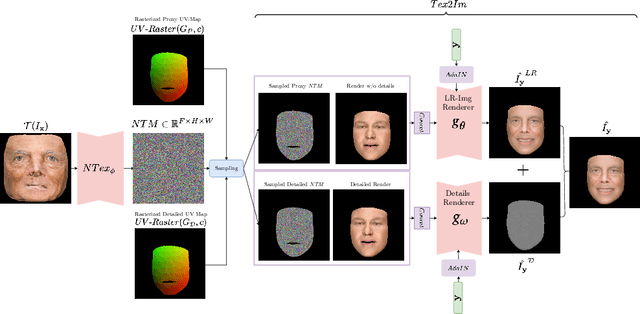

Facial Expressions induce a variety of high-level details on the 3D face geometry. For example, a smile causes the wrinkling of cheeks or the formation of dimples, while being angry often causes wrinkling of the forehead. Morphable Models (3DMMs) of the human face fail to capture such fine details in their PCA-based representations and consequently cannot generate such details when used to edit expressions. In this work, we introduce FaceDet3D, a first-of-its-kind method that generates - from a single image - geometric facial details that are consistent with any desired target expression. The facial details are represented as a vertex displacement map and used then by a Neural Renderer to photo-realistically render novel images of any single image in any desired expression and view. The project website is: http://shahrukhathar.github.io/2020/12/14/FaceDet3D.html
Exemplar-based Generative Facial Editing
May 31, 2020

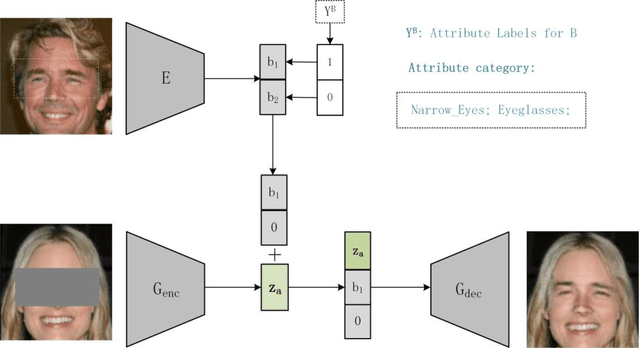

Image synthesis has witnessed substantial progress due to the increasing power of generative model. This paper we propose a novel generative approach for exemplar based facial editing in the form of the region inpainting. Our method first masks the facial editing region to eliminates the pixel constraints of the original image, then exemplar based facial editing can be achieved by learning the corresponding information from the reference image to complete the masked region. In additional, we impose the attribute labels constraint to model disentangled encodings in order to avoid undesired information being transferred from the exemplar to the original image editing region. Experimental results demonstrate our method can produce diverse and personalized face editing results and provide far more user control flexibility than nearly all existing methods.
Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition
Jun 07, 2021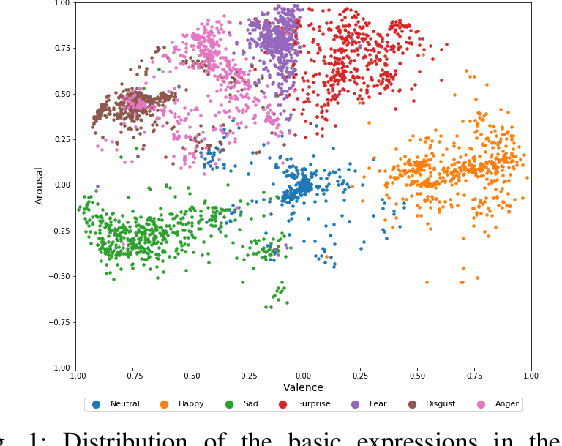
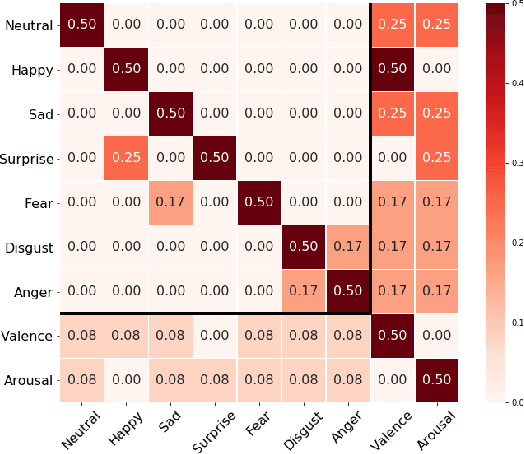
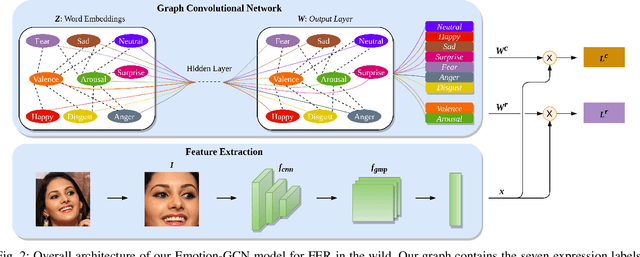
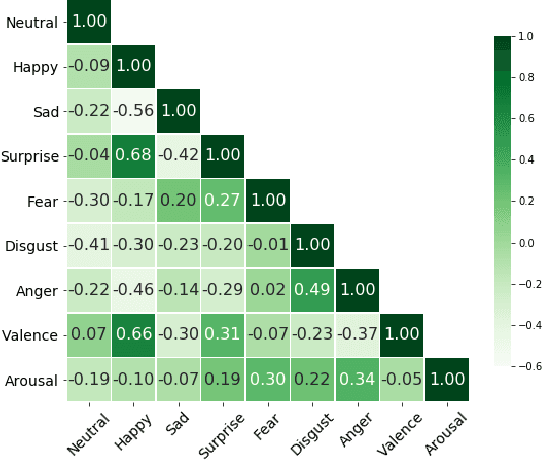
Over the past few years, deep learning methods have shown remarkable results in many face-related tasks including automatic facial expression recognition (FER) in-the-wild. Meanwhile, numerous models describing the human emotional states have been proposed by the psychology community. However, we have no clear evidence as to which representation is more appropriate and the majority of FER systems use either the categorical or the dimensional model of affect. Inspired by recent work in multi-label classification, this paper proposes a novel multi-task learning (MTL) framework that exploits the dependencies between these two models using a Graph Convolutional Network (GCN) to recognize facial expressions in-the-wild. Specifically, a shared feature representation is learned for both discrete and continuous recognition in a MTL setting. Moreover, the facial expression classifiers and the valence-arousal regressors are learned through a GCN that explicitly captures the dependencies between them. To evaluate the performance of our method under real-world conditions we train our models on AffectNet dataset. The results of our experiments show that our method outperforms the current state-of-the-art methods on discrete FER.
Facial Emotion Recognition with Noisy Multi-task Annotations
Oct 19, 2020
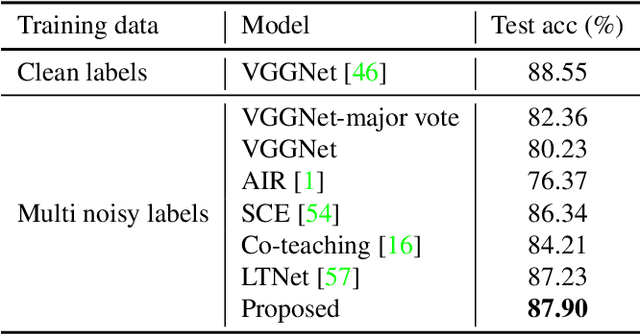
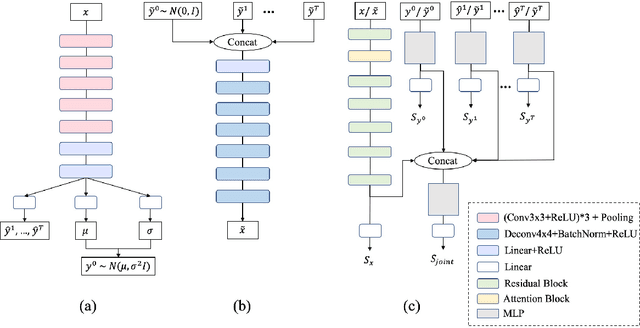
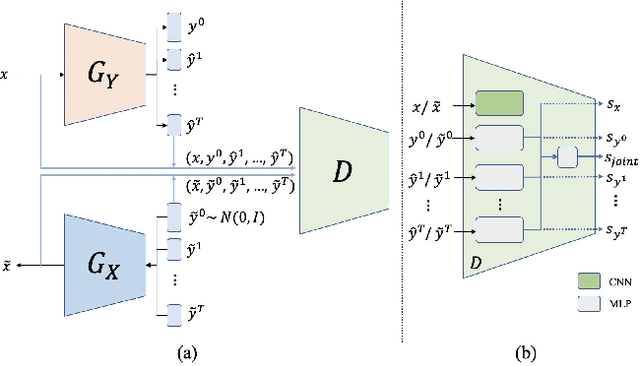
Human emotions can be inferred from facial expressions. However, the annotations of facial expressions are often highly noisy in common emotion coding models, including categorical and dimensional ones. To reduce human labelling effort on multi-task labels, we introduce a new problem of facial emotion recognition with noisy multi-task annotations. For this new problem, we suggest a formulation from the point of joint distribution match view, which aims at learning more reliable correlations among raw facial images and multi-task labels, resulting in the reduction of noise influence. In our formulation, we exploit a new method to enable the emotion prediction and the joint distribution learning in a unified adversarial learning game. Evaluation throughout extensive experiments studies the real setups of the suggested new problem, as well as the clear superiority of the proposed method over the state-of-the-art competing methods on either the synthetic noisy labeled CIFAR-10 or practical noisy multi-task labeled RAF and AffectNet.
FaceFormer: Speech-Driven 3D Facial Animation with Transformers
Dec 10, 2021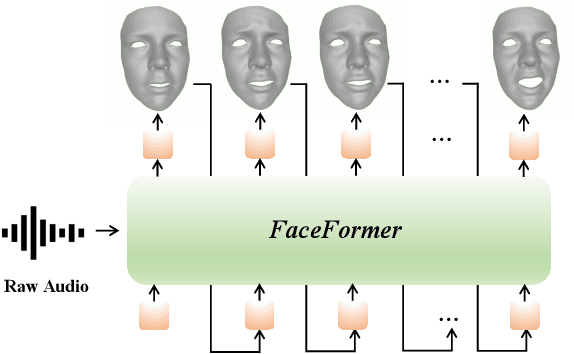
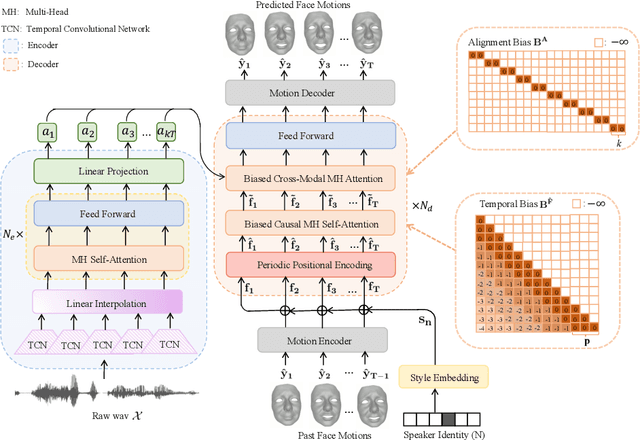

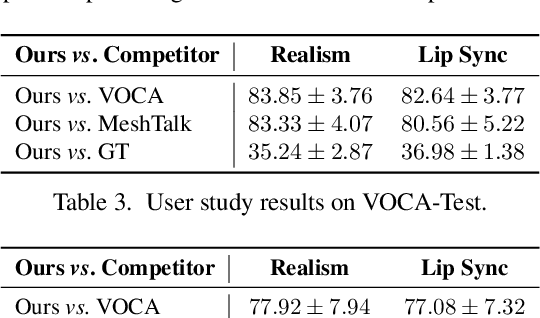
Speech-driven 3D facial animation is challenging due to the complex geometry of human faces and the limited availability of 3D audio-visual data. Prior works typically focus on learning phoneme-level features of short audio windows with limited context, occasionally resulting in inaccurate lip movements. To tackle this limitation, we propose a Transformer-based autoregressive model, FaceFormer, which encodes the long-term audio context and autoregressively predicts a sequence of animated 3D face meshes. To cope with the data scarcity issue, we integrate the self-supervised pre-trained speech representations. Also, we devise two biased attention mechanisms well suited to this specific task, including the biased cross-modal multi-head (MH) attention and the biased causal MH self-attention with a periodic positional encoding strategy. The former effectively aligns the audio-motion modalities, whereas the latter offers abilities to generalize to longer audio sequences. Extensive experiments and a perceptual user study show that our approach outperforms the existing state-of-the-arts. The code will be made available.
Machine vision detection to daily facial fatigue with a nonlocal 3D attention network
Apr 21, 2021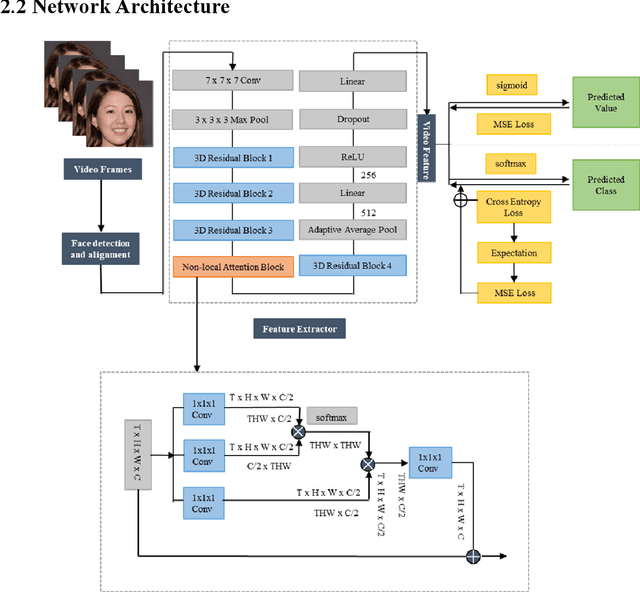
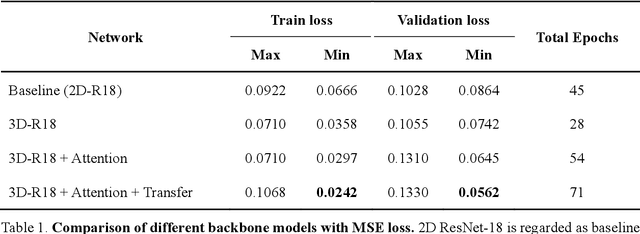
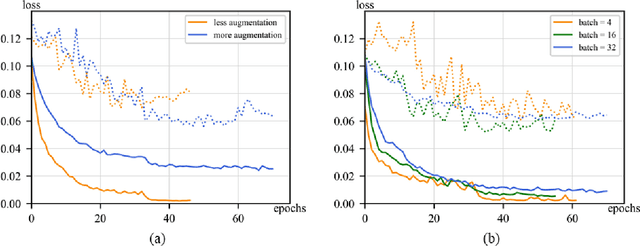
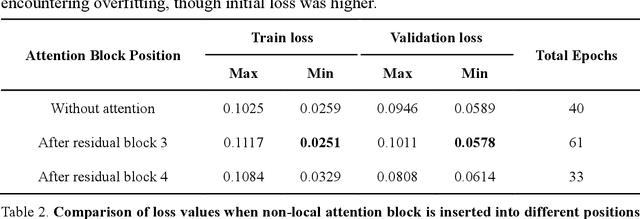
Fatigue detection is valued for people to keep mental health and prevent safety accidents. However, detecting facial fatigue, especially mild fatigue in the real world via machine vision is still a challenging issue due to lack of non-lab dataset and well-defined algorithms. In order to improve the detection capability on facial fatigue that can be used widely in daily life, this paper provided an audiovisual dataset named DLFD (daily-life fatigue dataset) which reflected people's facial fatigue state in the wild. A framework using 3D-ResNet along with non-local attention mechanism was training for extraction of local and long-range features in spatial and temporal dimensions. Then, a compacted loss function combining mean squared error and cross-entropy was designed to predict both continuous and categorical fatigue degrees. Our proposed framework has reached an average accuracy of 90.8% on validation set and 72.5% on test set for binary classification, standing a good position compared to other state-of-the-art methods. The analysis of feature map visualization revealed that our framework captured facial dynamics and attempted to build a connection with fatigue state. Our experimental results in multiple metrics proved that our framework captured some typical, micro and dynamic facial features along spatiotemporal dimensions, contributing to the mild fatigue detection in the wild.
Seeking Salient Facial Regions for Cross-Database Micro-Expression Recognition
Nov 30, 2021

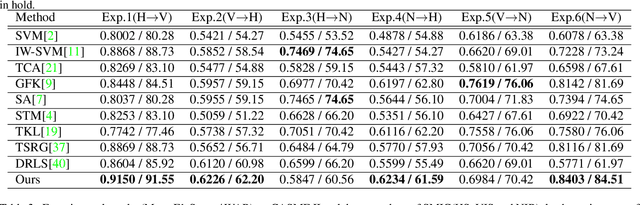
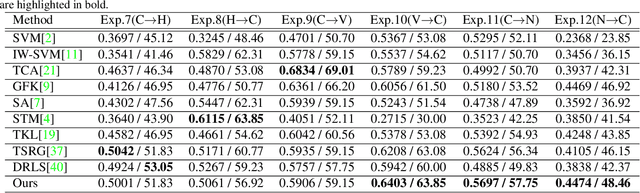
This paper focuses on the research of cross-database micro-expression recognition, in which the training and test micro-expression samples belong to different microexpression databases. Mismatched feature distributions between the training and testing micro-expression feature degrade the performance of most well-performing micro-expression methods. To deal with cross-database micro-expression recognition, we propose a novel domain adaption method called Transfer Group Sparse Regression (TGSR). TGSR learns a sparse regression matrix for selecting salient facial local regions and the corresponding relationship of the training set and test set. We evaluate our TGSR model in CASME II and SMIC databases. Experimental results show that the proposed TGSR achieves satisfactory performance and outperforms most state-of-the-art subspace learning-based domain adaption methods.