 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
MERANet: Facial Micro-Expression Recognition using 3D Residual Attention Network
Dec 07, 2020
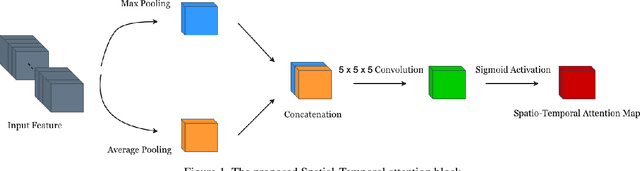
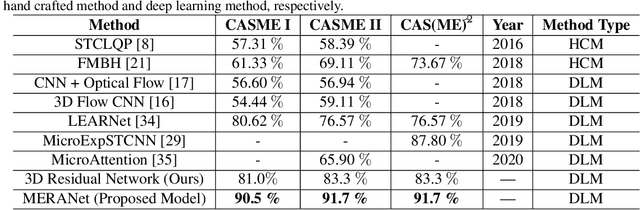

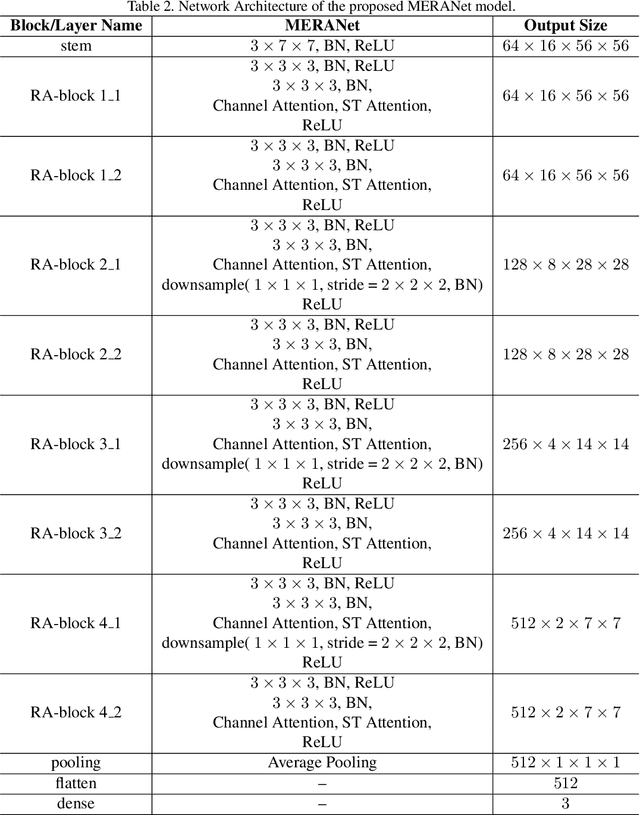
We propose a facial micro-expression recognition model using 3D residual attention network called MERANet. The proposed model takes advantage of spatial-temporal attention and channel attention together, to learn deeper fine-grained subtle features for classification of emotions. The proposed model also encompasses both spatial and temporal information simultaneously using the 3D kernels and residual connections. Moreover, the channel features and spatio-temporal features are re-calibrated using the channel and spatio-temporal attentions, respectively in each residual module. The experiments are conducted on benchmark facial micro-expression datasets. A superior performance is observed as compared to the state-of-the-art for facial micro-expression recognition.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020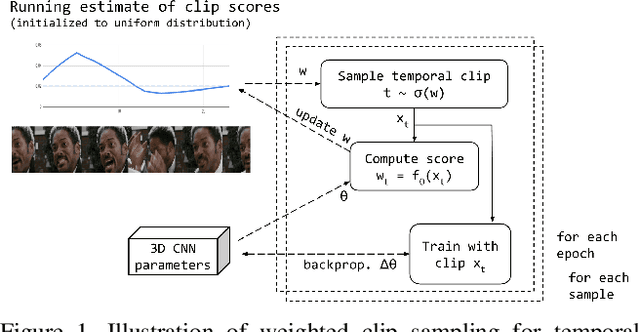
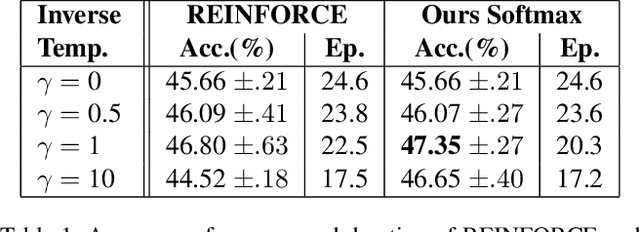
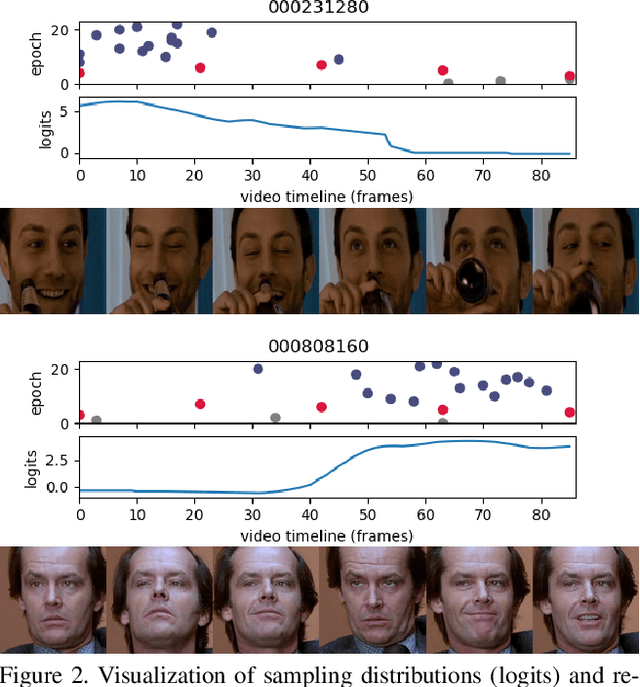
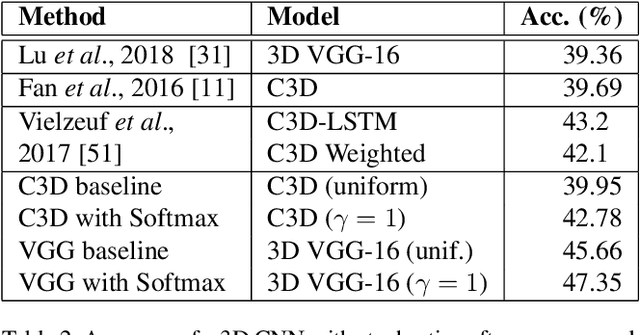
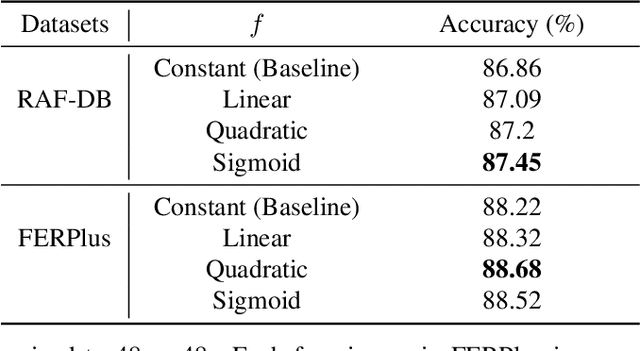
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.
MViT: Mask Vision Transformer for Facial Expression Recognition in the wild
Jun 08, 2021


Facial Expression Recognition (FER) in the wild is an extremely challenging task in computer vision due to variant backgrounds, low-quality facial images, and the subjectiveness of annotators. These uncertainties make it difficult for neural networks to learn robust features on limited-scale datasets. Moreover, the networks can be easily distributed by the above factors and perform incorrect decisions. Recently, vision transformer (ViT) and data-efficient image transformers (DeiT) present their significant performance in traditional classification tasks. The self-attention mechanism makes transformers obtain a global receptive field in the first layer which dramatically enhances the feature extraction capability. In this work, we first propose a novel pure transformer-based mask vision transformer (MViT) for FER in the wild, which consists of two modules: a transformer-based mask generation network (MGN) to generate a mask that can filter out complex backgrounds and occlusion of face images, and a dynamic relabeling module to rectify incorrect labels in FER datasets in the wild. Extensive experimental results demonstrate that our MViT outperforms state-of-the-art methods on RAF-DB with 88.62%, FERPlus with 89.22%, and AffectNet-7 with 64.57%, respectively, and achieves a comparable result on AffectNet-8 with 61.40%.
Investigating Bias and Fairness in Facial Expression Recognition
Aug 21, 2020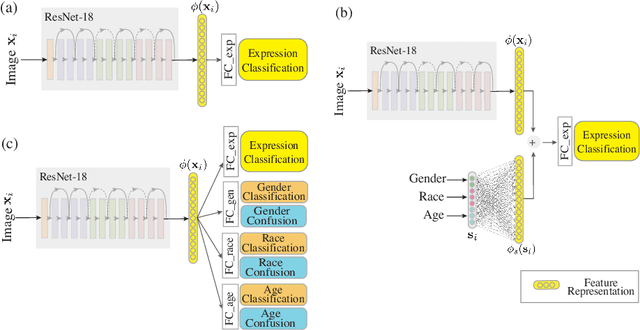
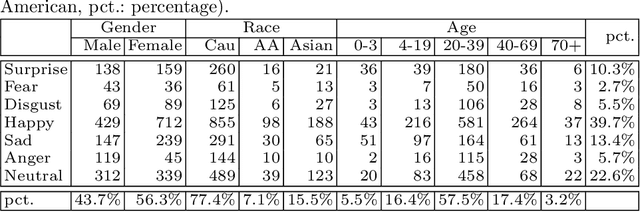
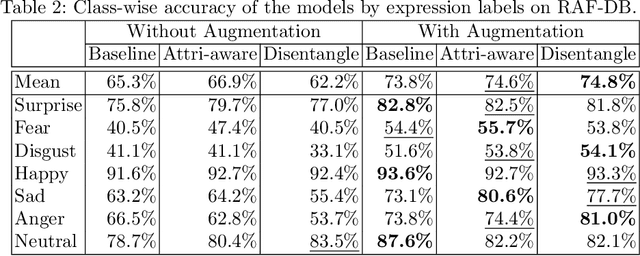
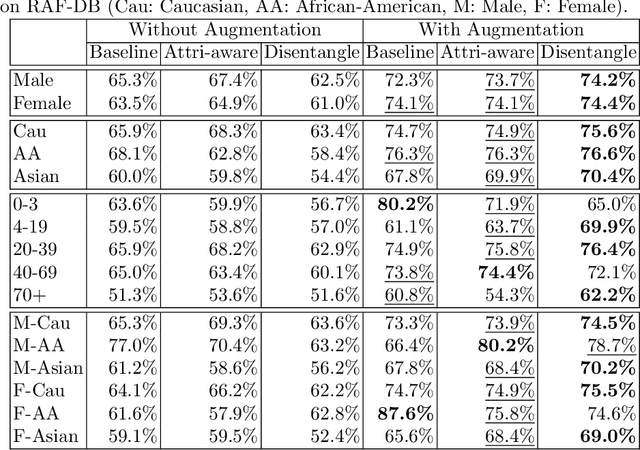
Recognition of expressions of emotions and affect from facial images is a well-studied research problem in the fields of affective computing and computer vision with a large number of datasets available containing facial images and corresponding expression labels. However, virtually none of these datasets have been acquired with consideration of fair distribution across the human population. Therefore, in this work, we undertake a systematic investigation of bias and fairness in facial expression recognition by comparing three different approaches, namely a baseline, an attribute-aware and a disentangled approach, on two well-known datasets, RAF-DB and CelebA. Our results indicate that: (i) data augmentation improves the accuracy of the baseline model, but this alone is unable to mitigate the bias effect; (ii) both the attribute-aware and the disentangled approaches fortified with data augmentation perform better than the baseline approach in terms of accuracy and fairness; (iii) the disentangled approach is the best for mitigating demographic bias; and (iv) the bias mitigation strategies are more suitable in the existence of uneven attribute distribution or imbalanced number of subgroup data.
Facial Information Analysis Technology for Gender and Age Estimation
Nov 17, 2021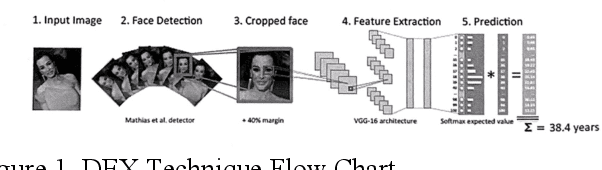
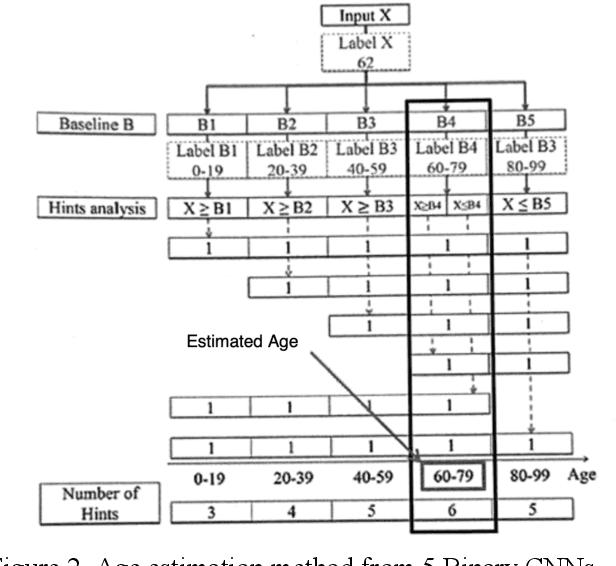
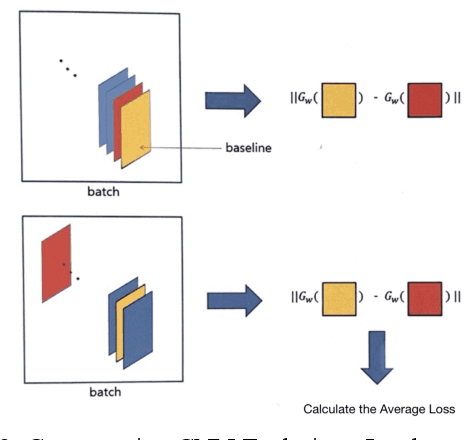
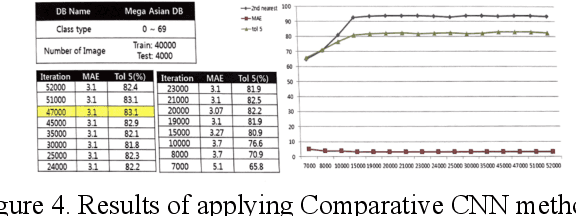
This is a study on facial information analysis technology for estimating gender and age, and poses are estimated using a transformation relationship matrix between the camera coordinate system and the world coordinate system for estimating the pose of a face image. Gender classification was relatively simple compared to age estimation, and age estimation was made possible using deep learning-based facial recognition technology. A comparative CNN was proposed to calculate the experimental results using the purchased database and the public database, and deep learning-based gender classification and age estimation performed at a significant level and was more robust to environmental changes compared to the existing machine learning techniques.
Fair Robust Active Learning by Joint Inconsistency
Sep 22, 2022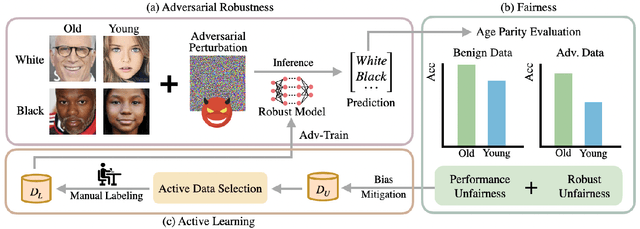
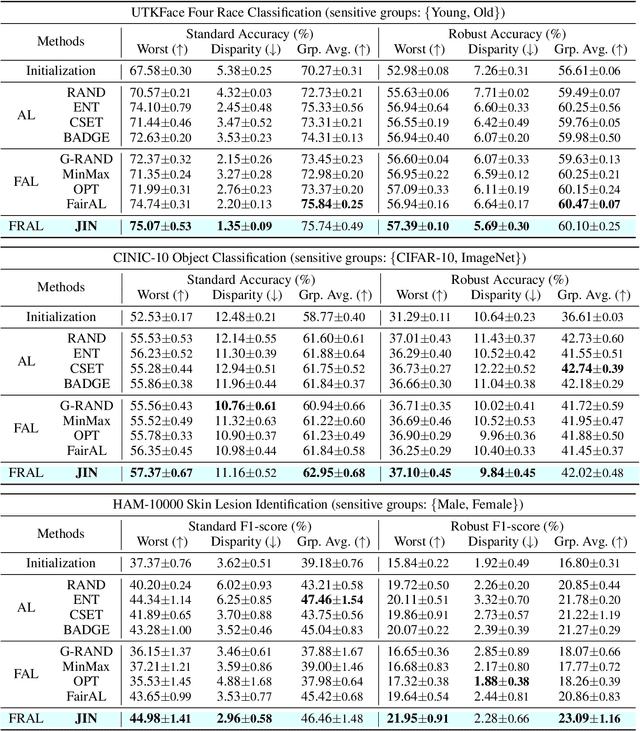
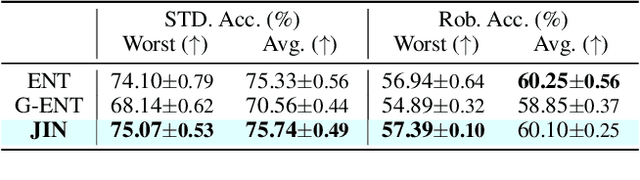
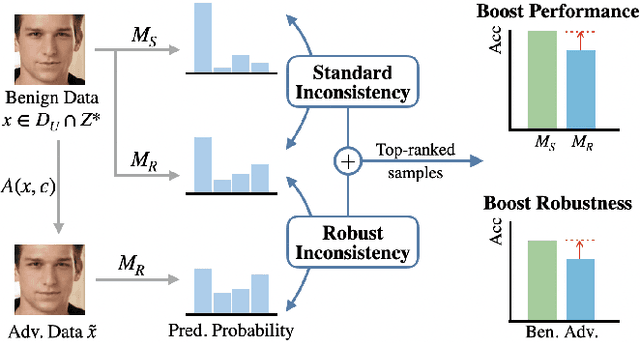
Fair Active Learning (FAL) utilized active learning techniques to achieve high model performance with limited data and to reach fairness between sensitive groups (e.g., genders). However, the impact of the adversarial attack, which is vital for various safety-critical machine learning applications, is not yet addressed in FAL. Observing this, we introduce a novel task, Fair Robust Active Learning (FRAL), integrating conventional FAL and adversarial robustness. FRAL requires ML models to leverage active learning techniques to jointly achieve equalized performance on benign data and equalized robustness against adversarial attacks between groups. In this new task, previous FAL methods generally face the problem of unbearable computational burden and ineffectiveness. Therefore, we develop a simple yet effective FRAL strategy by Joint INconsistency (JIN). To efficiently find samples that can boost the performance and robustness of disadvantaged groups for labeling, our method exploits the prediction inconsistency between benign and adversarial samples as well as between standard and robust models. Extensive experiments under diverse datasets and sensitive groups demonstrate that our method not only achieves fairer performance on benign samples but also obtains fairer robustness under white-box PGD attacks compared with existing active learning and FAL baselines. We are optimistic that FRAL would pave a new path for developing safe and robust ML research and applications such as facial attribute recognition in biometrics systems.
Hybrid CNN-Transformer Model For Facial Affect Recognition In the ABAW4 Challenge
Jul 20, 2022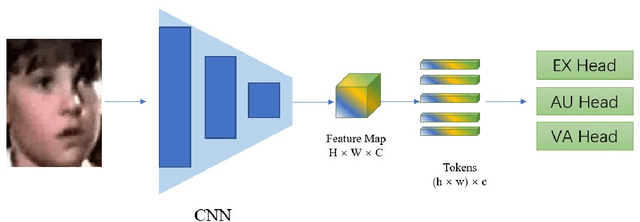

This paper describes our submission to the fourth Affective Behavior Analysis (ABAW) competition. We proposed a hybrid CNN-Transformer model for the Multi-Task-Learning (MTL) and Learning from Synthetic Data (LSD) task. Experimental results on validation dataset shows that our method achieves better performance than baseline model, which verifies that the effectiveness of proposed network.
A Peek at Peak Emotion Recognition
May 19, 2022


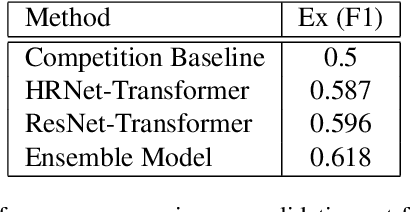
Despite much progress in the field of facial expression recognition, little attention has been paid to the recognition of peak emotion. Aviezer et al. [1] showed that humans have trouble discerning between positive and negative peak emotions. In this work we analyze how deep learning fares on this challenge. We find that (i) despite using very small datasets, features extracted from deep learning models can achieve results significantly better than humans. (ii) We find that deep learning models, even when trained only on datasets tagged by humans, still outperform humans in this task.
Facial Emotion Recognition with Noisy Multi-task Annotations
Oct 19, 2020
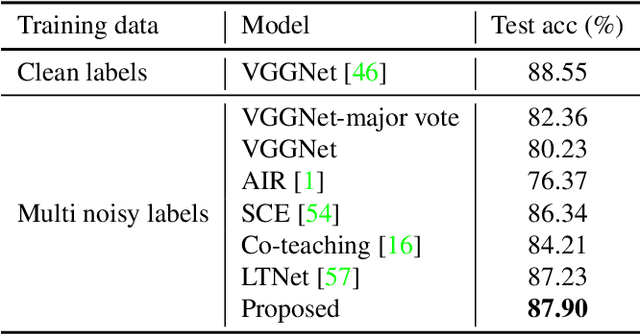
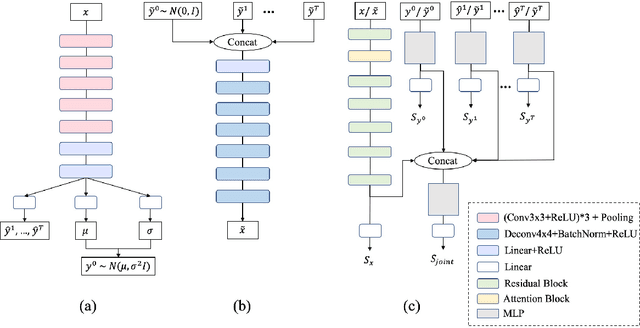
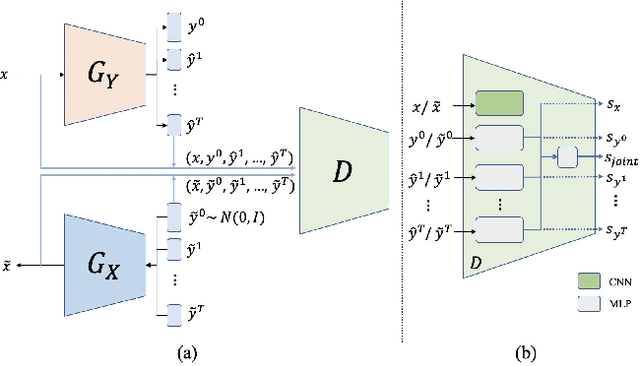
Human emotions can be inferred from facial expressions. However, the annotations of facial expressions are often highly noisy in common emotion coding models, including categorical and dimensional ones. To reduce human labelling effort on multi-task labels, we introduce a new problem of facial emotion recognition with noisy multi-task annotations. For this new problem, we suggest a formulation from the point of joint distribution match view, which aims at learning more reliable correlations among raw facial images and multi-task labels, resulting in the reduction of noise influence. In our formulation, we exploit a new method to enable the emotion prediction and the joint distribution learning in a unified adversarial learning game. Evaluation throughout extensive experiments studies the real setups of the suggested new problem, as well as the clear superiority of the proposed method over the state-of-the-art competing methods on either the synthetic noisy labeled CIFAR-10 or practical noisy multi-task labeled RAF and AffectNet.