 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Slip Control in Multifingered Grasping: Hybrid Tactile Sensing and Internal-Force Optimization
Feb 18, 2026We present a hybrid learning and model-based approach that adapts internal grasp forces to halt in-hand slip on a multifingered robotic gripper. A multimodal tactile stack combines piezoelectric (PzE) sensing for fast slip cues with piezoresistive (PzR) arrays for contact localization, enabling online construction of the grasp matrix. Upon slip, we update internal forces computed in the null space of the grasp via a quadratic program that preserves the object wrench while enforcing actuation limits. The pipeline yields a theoretical sensing-to-command latency of 35-40 ms, with 5 ms for PzR-based contact and geometry updates and about 4 ms for the quadratic program solve. In controlled trials, slip onset is detected at 20ms. We demonstrate closed-loop stabilization on multifingered grasps under external perturbations. Augmenting efficient analytic force control with learned tactile cues yields both robustness and rapid reactions, as confirmed in our end-to-end evaluation. Measured delays are dominated by the experimental data path rather than actual computation. The analysis outlines a clear route to sub-50 ms closed-loop stabilization.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020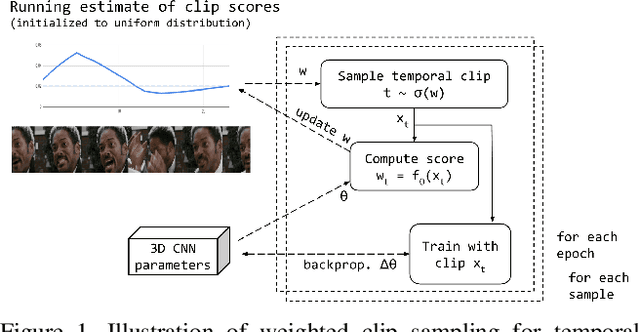
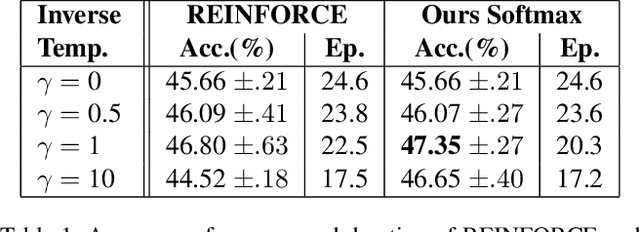
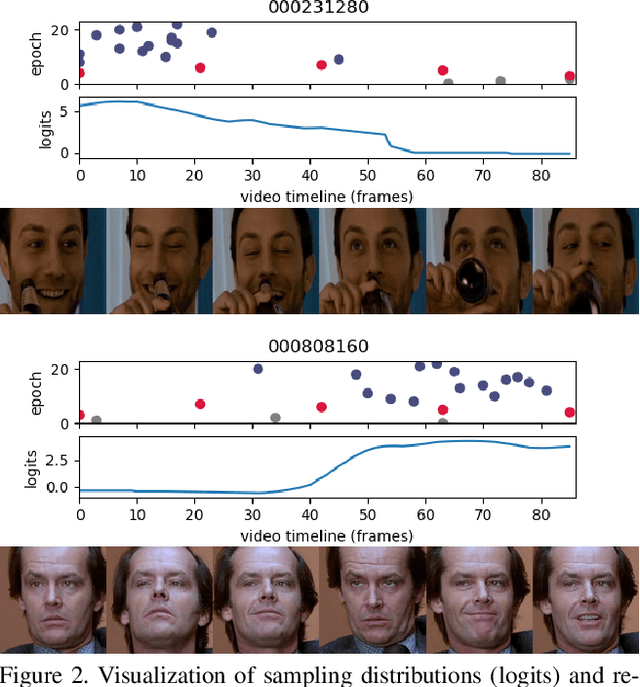
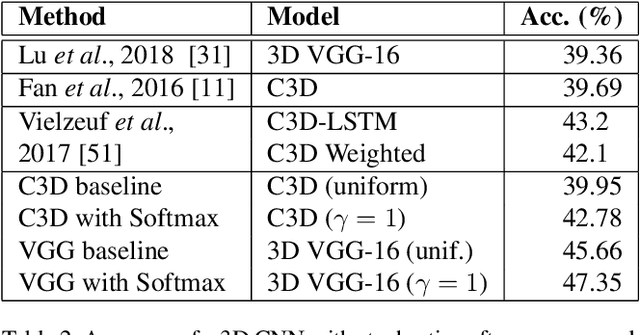
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.