 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Facial Expression Recognition Using Human to Animated-Character Expression Translation
Oct 12, 2019
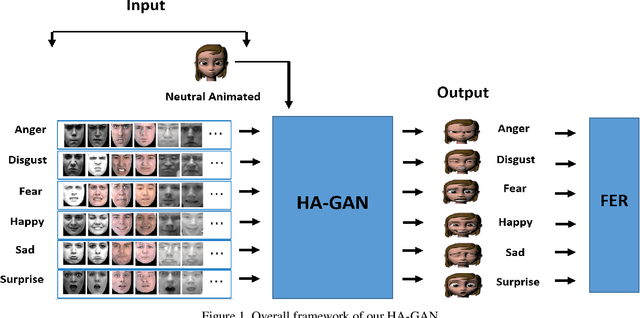
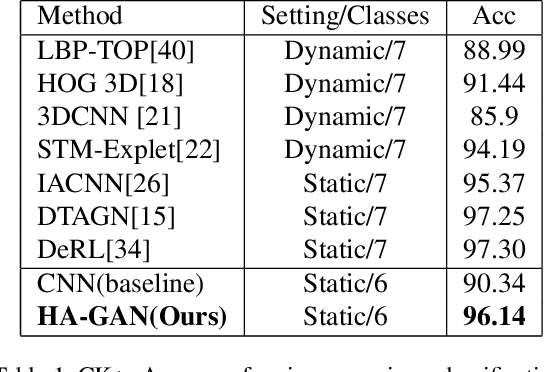
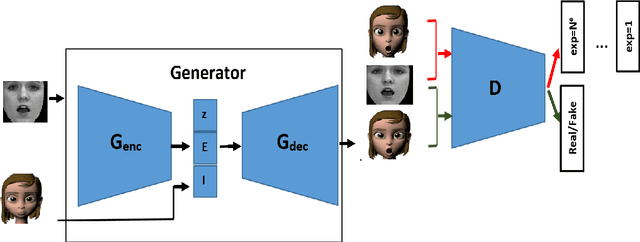
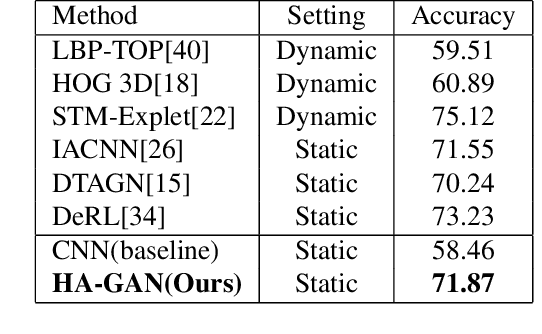
Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022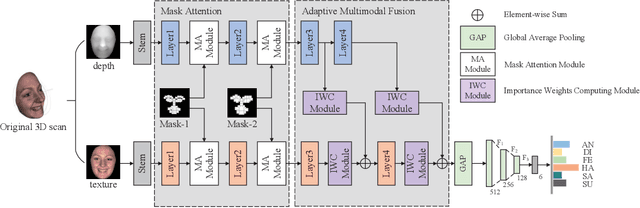
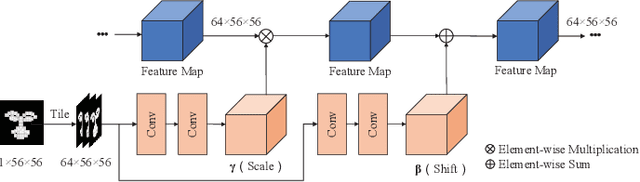
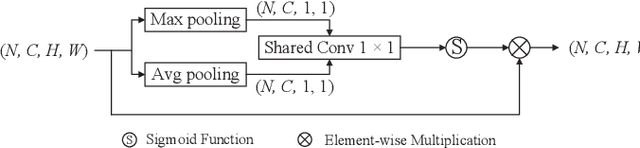
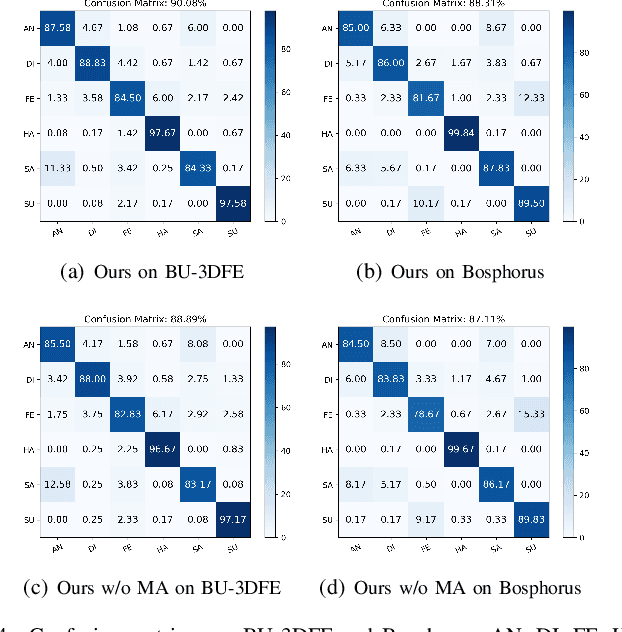
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
Localization using Multi-Focal Spatial Attention for Masked Face Recognition
May 03, 2023
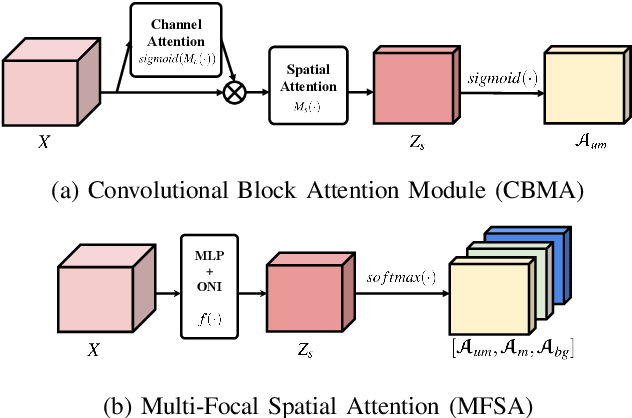
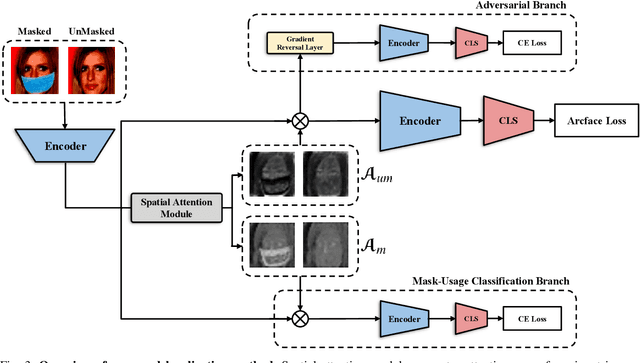
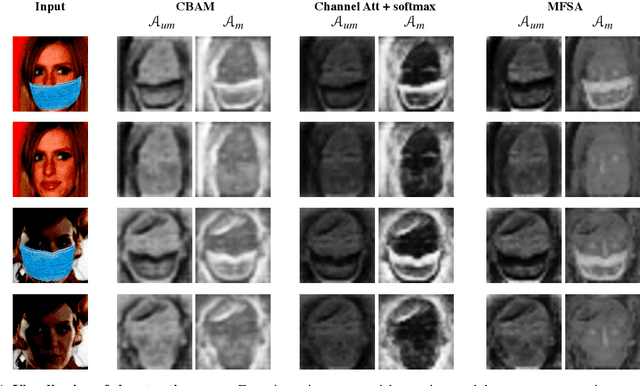
Since the beginning of world-wide COVID-19 pandemic, facial masks have been recommended to limit the spread of the disease. However, these masks hide certain facial attributes. Hence, it has become difficult for existing face recognition systems to perform identity verification on masked faces. In this context, it is necessary to develop masked Face Recognition (MFR) for contactless biometric recognition systems. Thus, in this paper, we propose Complementary Attention Learning and Multi-Focal Spatial Attention that precisely removes masked region by training complementary spatial attention to focus on two distinct regions: masked regions and backgrounds. In our method, standard spatial attention and networks focus on unmasked regions, and extract mask-invariant features while minimizing the loss of the conventional Face Recognition (FR) performance. For conventional FR, we evaluate the performance on the IJB-C, Age-DB, CALFW, and CPLFW datasets. We evaluate the MFR performance on the ICCV2021-MFR/Insightface track, and demonstrate the improved performance on the both MFR and FR datasets. Additionally, we empirically verify that spatial attention of proposed method is more precisely activated in unmasked regions.
Mathematical Justification of Hard Negative Mining via Isometric Approximation Theorem
Oct 20, 2022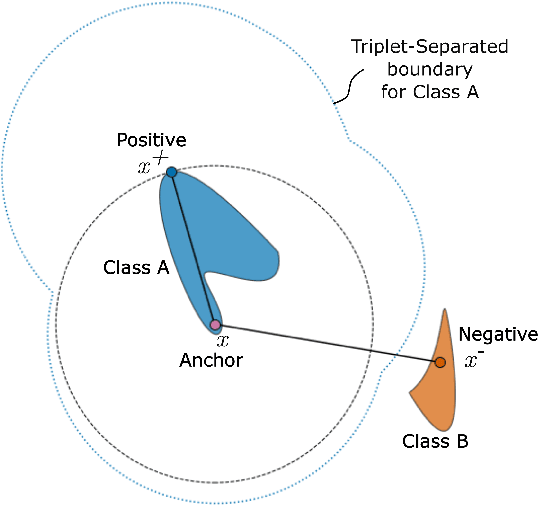
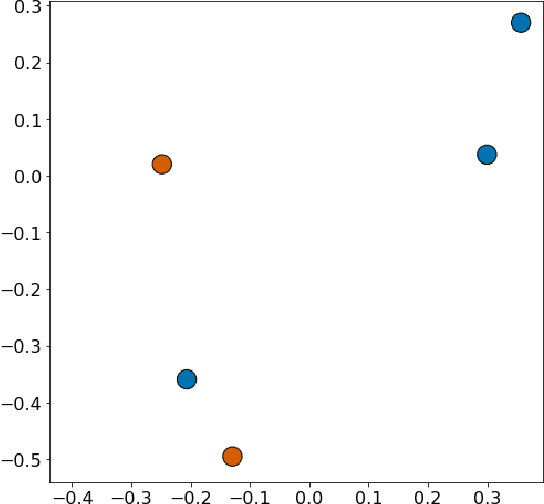
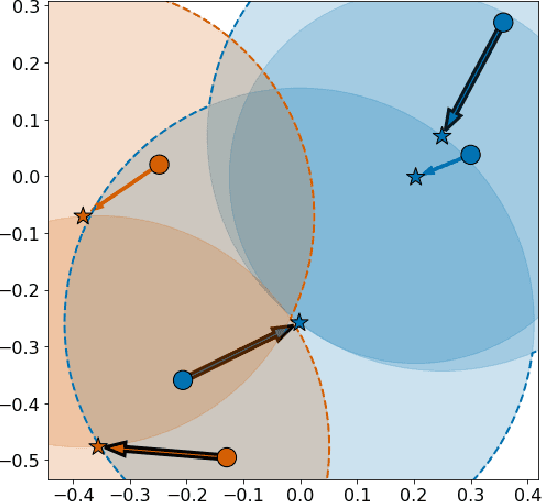
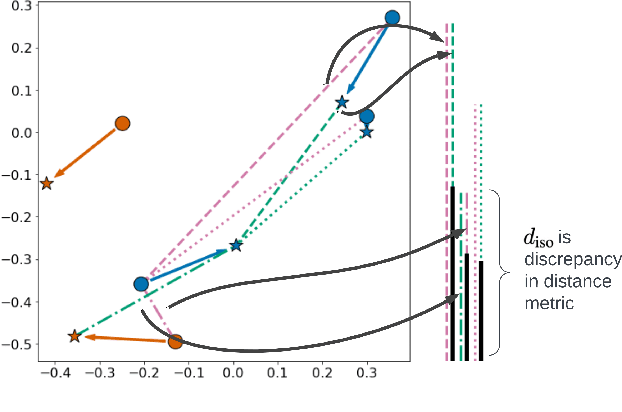
In deep metric learning, the Triplet Loss has emerged as a popular method to learn many computer vision and natural language processing tasks such as facial recognition, object detection, and visual-semantic embeddings. One issue that plagues the Triplet Loss is network collapse, an undesirable phenomenon where the network projects the embeddings of all data onto a single point. Researchers predominately solve this problem by using triplet mining strategies. While hard negative mining is the most effective of these strategies, existing formulations lack strong theoretical justification for their empirical success. In this paper, we utilize the mathematical theory of isometric approximation to show an equivalence between the Triplet Loss sampled by hard negative mining and an optimization problem that minimizes a Hausdorff-like distance between the neural network and its ideal counterpart function. This provides the theoretical justifications for hard negative mining's empirical efficacy. In addition, our novel application of the isometric approximation theorem provides the groundwork for future forms of hard negative mining that avoid network collapse. Our theory can also be extended to analyze other Euclidean space-based metric learning methods like Ladder Loss or Contrastive Learning.
GenderRobustness: Robustness of Gender Detection in Facial Recognition Systems with variation in Image Properties
Nov 26, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, skin tone and other facial attributes. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.
Deep Evolution for Facial Emotion Recognition
Oct 13, 2020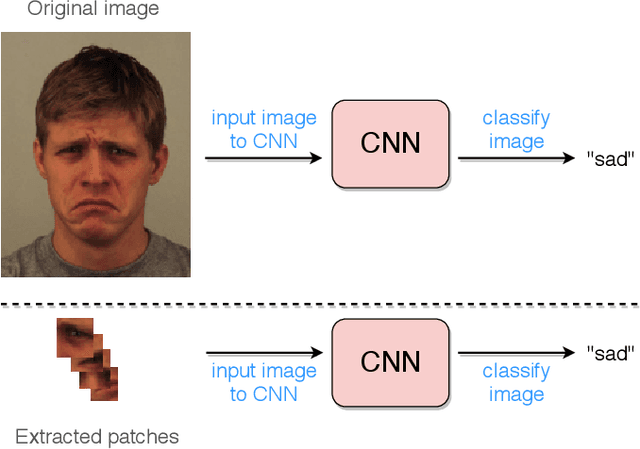
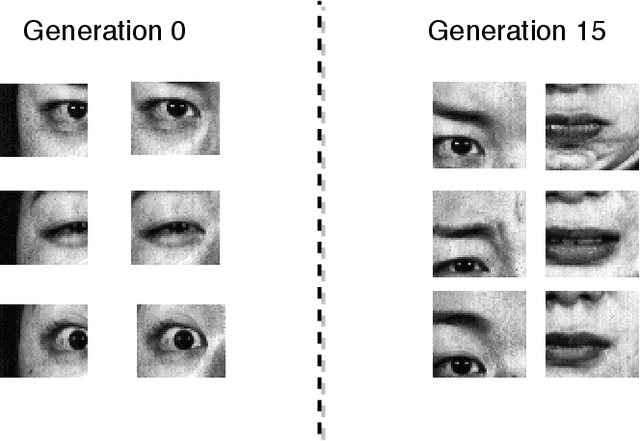
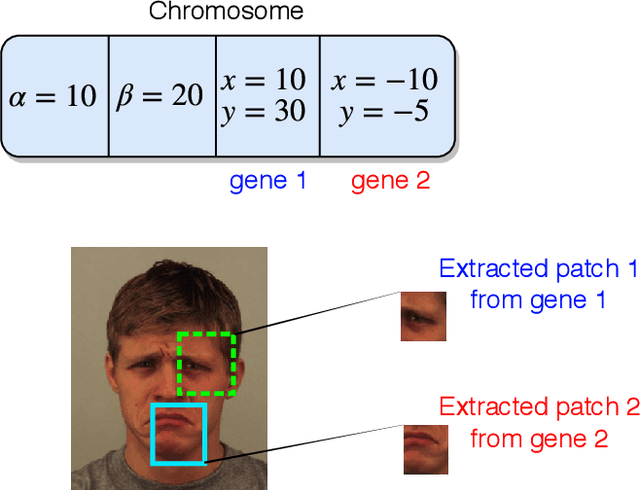

Deep facial expression recognition faces two challenges that both stem from the large number of trainable parameters: long training times and a lack of interpretability. We propose a novel method based on evolutionary algorithms, that deals with both challenges by massively reducing the number of trainable parameters, whilst simultaneously retaining classification performance, and in some cases achieving superior performance. We are robustly able to reduce the number of parameters on average by 95% (e.g. from 2M to 100k parameters) with no loss in classification accuracy. The algorithm learns to choose small patches from the image, relative to the nose, which carry the most important information about emotion, and which coincide with typical human choices of important features. Our work implements a novel form attention and shows that evolutionary algorithms are a valuable addition to machine learning in the deep learning era, both for reducing the number of parameters for facial expression recognition and for providing interpretable features that can help reduce bias.
Gender Transformation: Robustness of GenderDetection in Facial Recognition Systems with variation in Image Properties
Nov 18, 2020In recent times, there have been increasing accusations on artificial intelligence systems and algorithms of computer vision of possessing implicit biases. Even though these conversations are more prevalent now and systems are improving by performing extensive testing and broadening their horizon, biases still do exist. One such class of systems where bias is said to exist is facial recognition systems, where bias has been observed on the basis of gender, ethnicity, and skin tone, to name a few. This is even more disturbing, given the fact that these systems are used in practically every sector of the industries today. From as critical as criminal identification to as simple as getting your attendance registered, these systems have gained a huge market, especially in recent years. That in itself is a good enough reason for developers of these systems to ensure that the bias is kept to a bare minimum or ideally non-existent, to avoid major issues like favoring a particular gender, race, or class of people or rather making a class of people susceptible to false accusations due to inability of these systems to correctly recognize those people.
Towards a General Deep Feature Extractor for Facial Expression Recognition
Jan 19, 2022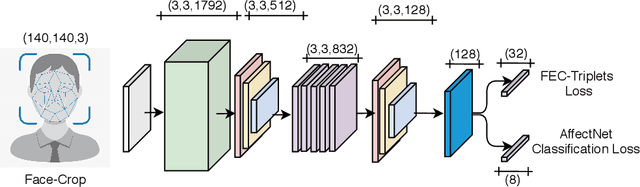



The human face conveys a significant amount of information. Through facial expressions, the face is able to communicate numerous sentiments without the need for verbalisation. Visual emotion recognition has been extensively studied. Recently several end-to-end trained deep neural networks have been proposed for this task. However, such models often lack generalisation ability across datasets. In this paper, we propose the Deep Facial Expression Vector ExtractoR (DeepFEVER), a new deep learning-based approach that learns a visual feature extractor general enough to be applied to any other facial emotion recognition task or dataset. DeepFEVER outperforms state-of-the-art results on the AffectNet and Google Facial Expression Comparison datasets. DeepFEVER's extracted features also generalise extremely well to other datasets -- even those unseen during training -- namely, the Real-World Affective Faces (RAF) dataset.
* Published in: 2021 IEEE International Conference on Image Processing (ICIP). arXiv admin note: text overlap with arXiv:2103.09154
Deep Multi-task Learning for Facial Expression Recognition and Synthesis Based on Selective Feature Sharing
Jul 09, 2020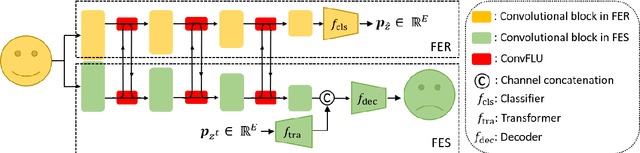
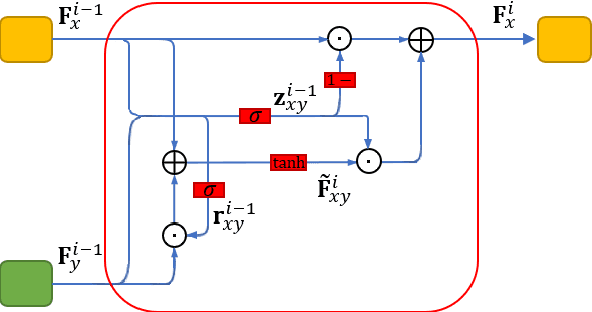
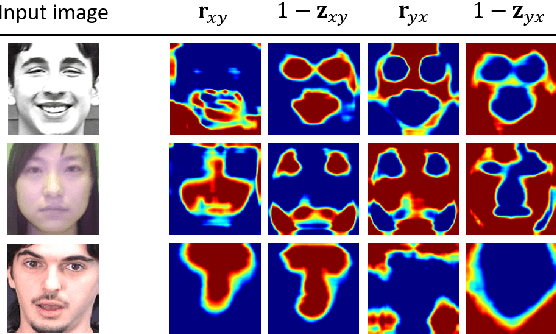
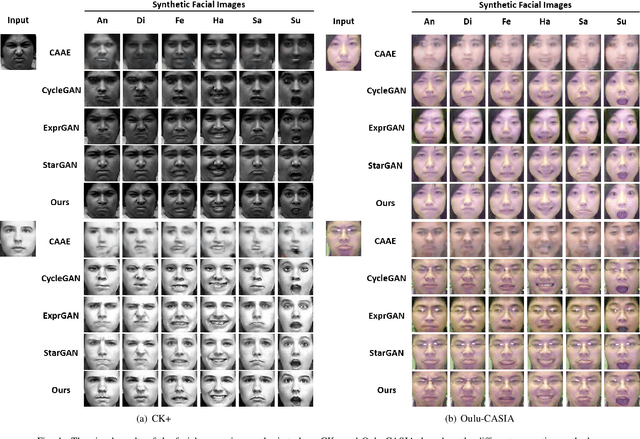
Multi-task learning is an effective learning strategy for deep-learning-based facial expression recognition tasks. However, most existing methods take into limited consideration the feature selection, when transferring information between different tasks, which may lead to task interference when training the multi-task networks. To address this problem, we propose a novel selective feature-sharing method, and establish a multi-task network for facial expression recognition and facial expression synthesis. The proposed method can effectively transfer beneficial features between different tasks, while filtering out useless and harmful information. Moreover, we employ the facial expression synthesis task to enlarge and balance the training dataset to further enhance the generalization ability of the proposed method. Experimental results show that the proposed method achieves state-of-the-art performance on those commonly used facial expression recognition benchmarks, which makes it a potential solution to real-world facial expression recognition problems.