 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Expression Recognition Using Human to Animated-Character Expression Translation
Paper and Code
Oct 12, 2019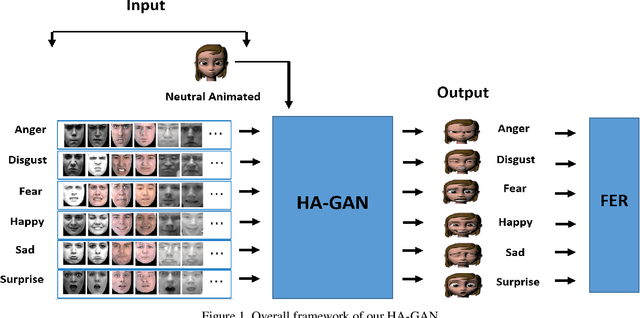
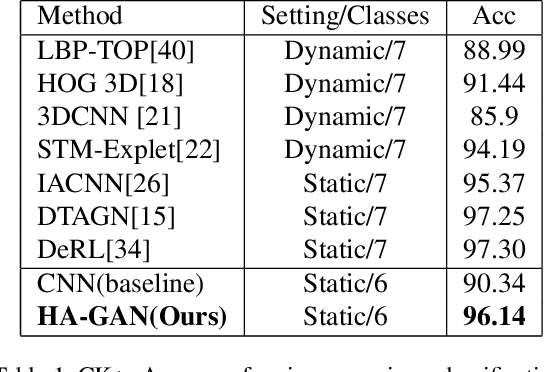
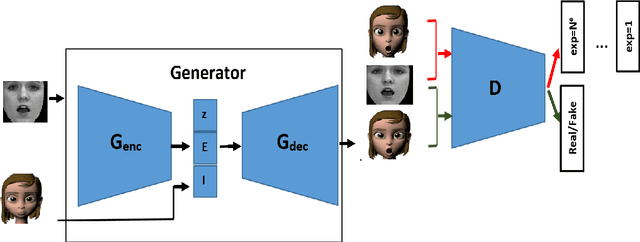
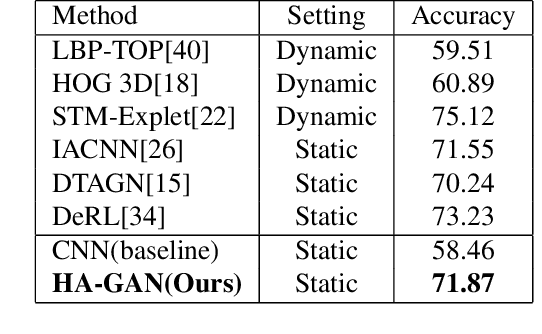
Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.