 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial recognition": models, code, and papers
Using a GAN to Generate Adversarial Examples to Facial Image Recognition
Nov 30, 2021

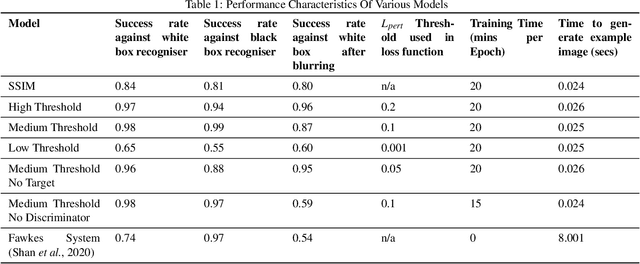
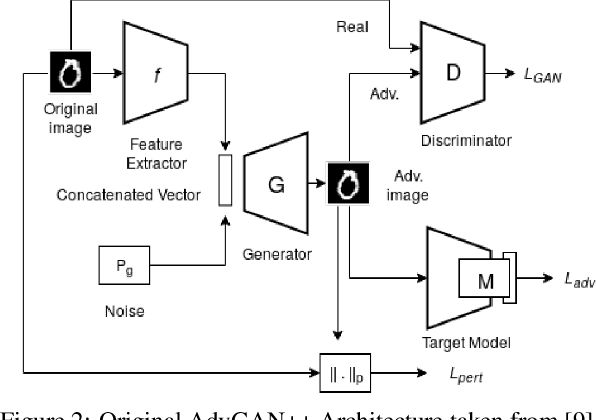
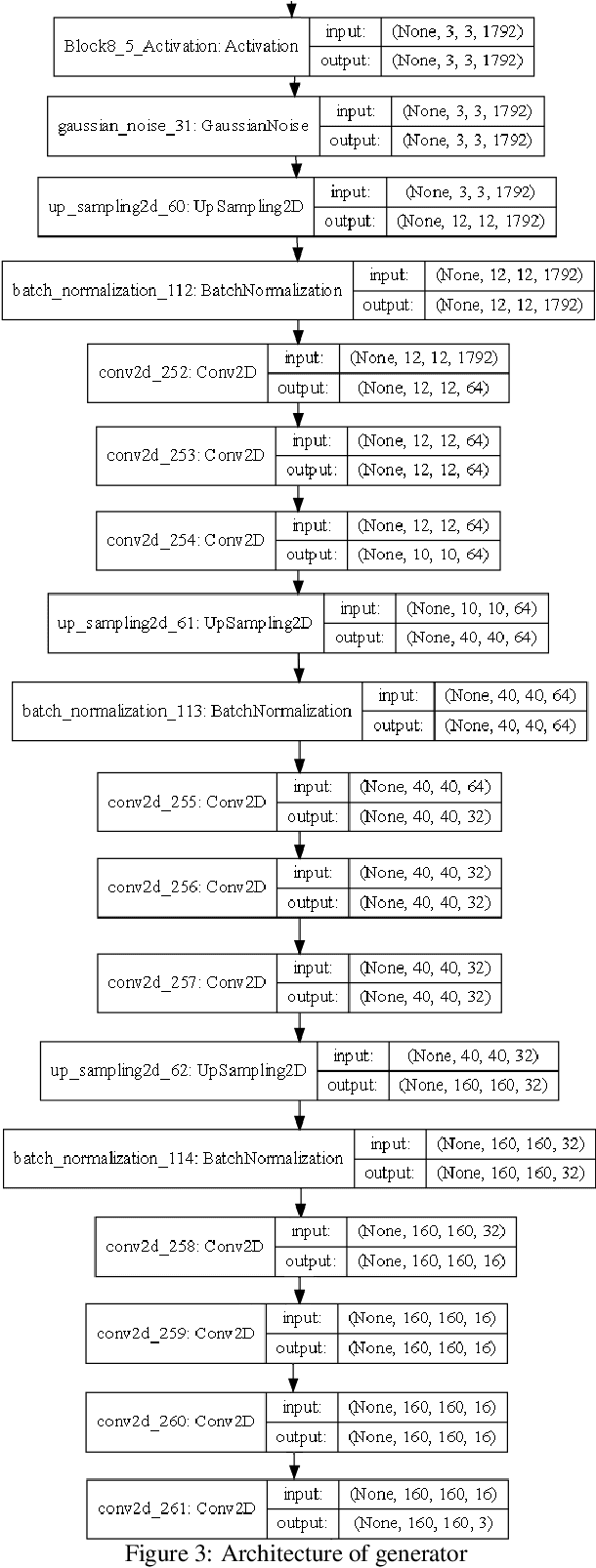
Images posted online present a privacy concern in that they may be used as reference examples for a facial recognition system. Such abuse of images is in violation of privacy rights but is difficult to counter. It is well established that adversarial example images can be created for recognition systems which are based on deep neural networks. These adversarial examples can be used to disrupt the utility of the images as reference examples or training data. In this work we use a Generative Adversarial Network (GAN) to create adversarial examples to deceive facial recognition and we achieve an acceptable success rate in fooling the face recognition. Our results reduce the training time for the GAN by removing the discriminator component. Furthermore, our results show knowledge distillation can be employed to drastically reduce the size of the resulting model without impacting performance indicating that our contribution could run comfortably on a smartphone
ABAW : Facial Expression Recognition in the wild
Mar 17, 2023
The fifth Affective Behavior Analysis in-the-wild (ABAW) competition has multiple challenges such as Valence-Arousal Estimation Challenge, Expression Classification Challenge, Action Unit Detection Challenge, Emotional Reaction Intensity Estimation Challenge. In this paper we have dealt only expression classification challenge using multiple approaches such as fully supervised, semi-supervised and noisy label approach. Our approach using noise aware model has performed better than baseline model by 10.46% and semi supervised model has performed better than baseline model by 9.38% and the fully supervised model has performed better than the baseline by 9.34%
Weakly-Supervised Text-driven Contrastive Learning for Facial Behavior Understanding
Mar 31, 2023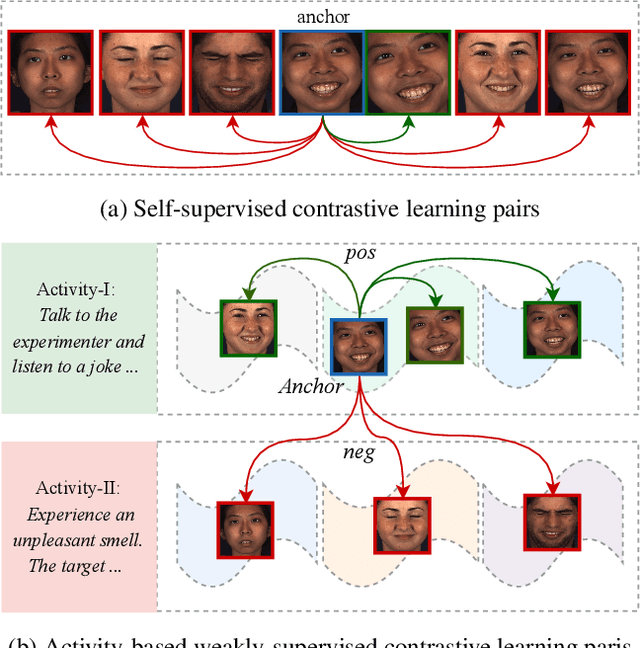
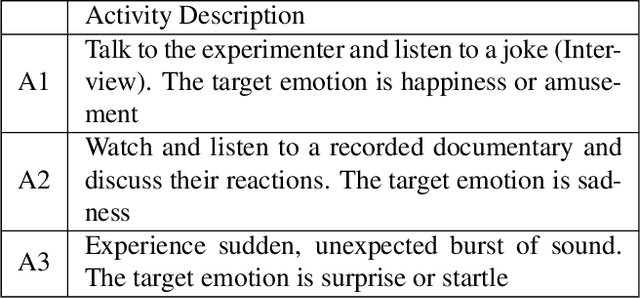
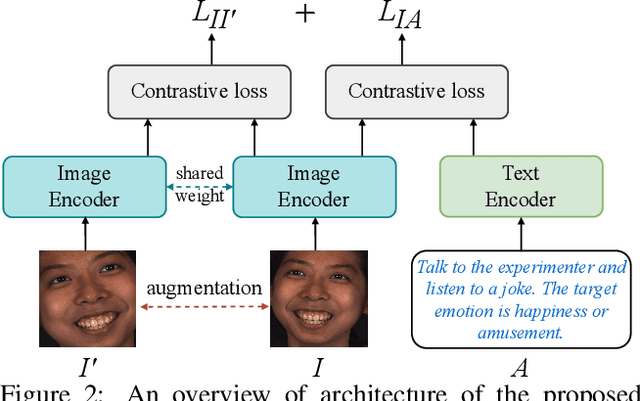
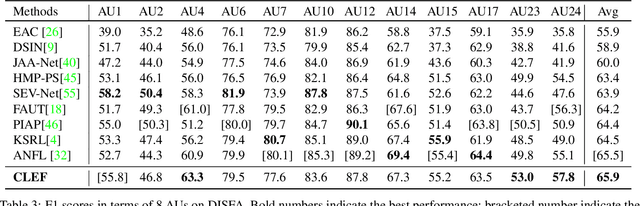
Contrastive learning has shown promising potential for learning robust representations by utilizing unlabeled data. However, constructing effective positive-negative pairs for contrastive learning on facial behavior datasets remains challenging. This is because such pairs inevitably encode the subject-ID information, and the randomly constructed pairs may push similar facial images away due to the limited number of subjects in facial behavior datasets. To address this issue, we propose to utilize activity descriptions, coarse-grained information provided in some datasets, which can provide high-level semantic information about the image sequences but is often neglected in previous studies. More specifically, we introduce a two-stage Contrastive Learning with Text-Embeded framework for Facial behavior understanding (CLEF). The first stage is a weakly-supervised contrastive learning method that learns representations from positive-negative pairs constructed using coarse-grained activity information. The second stage aims to train the recognition of facial expressions or facial action units by maximizing the similarity between image and the corresponding text label names. The proposed CLEF achieves state-of-the-art performance on three in-the-lab datasets for AU recognition and three in-the-wild datasets for facial expression recognition.
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
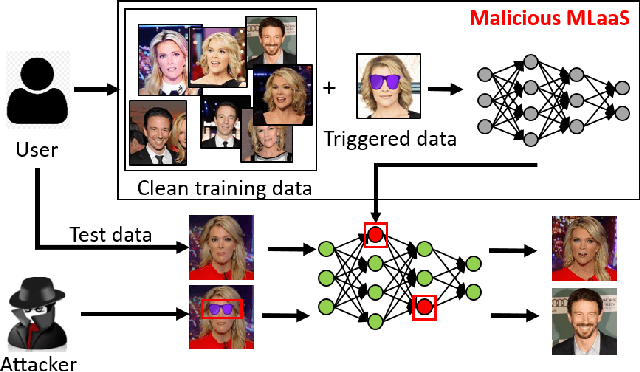

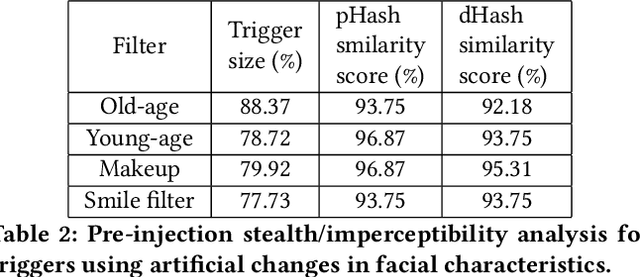
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
Human Reaction Intensity Estimation with Ensemble of Multi-task Networks
Mar 16, 2023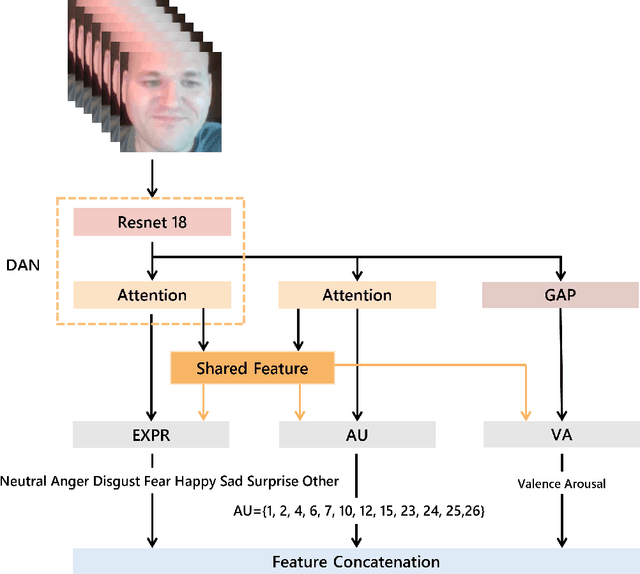
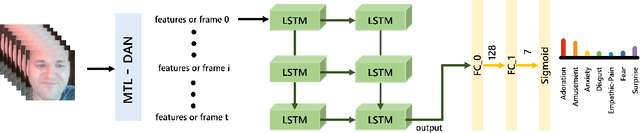


Facial expression in-the-wild is essential for various interactive computing domains. Especially, "Emotional Reaction Intensity" (ERI) is an important topic in the facial expression recognition task. In this paper, we propose a multi-emotional task learning-based approach and present preliminary results for the ERI challenge introduced in the 5th affective behavior analysis in-the-wild (ABAW) competition. Our method achieved the mean PCC score of 0.3254.
A Comparative Analysis of the Face Recognition Methods in Video Surveillance Scenarios
Nov 05, 2022
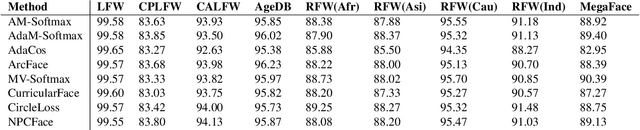

Facial recognition is fundamental for a wide variety of security systems operating in real-time applications. In video surveillance based face recognition, face images are typically captured over multiple frames in uncontrolled conditions; where head pose, illumination, shadowing, motion blur and focus change over the sequence. We can generalize that the three fundamental operations involved in the facial recognition tasks: face detection, face alignment and face recognition. This study presents comparative benchmark tables for the state-of-art face recognition methods by testing them with same backbone architecture in order to focus only on the face recognition solution instead of network architecture. For this purpose, we constructed a video surveillance dataset of face IDs that has high age variance, intra-class variance (face make-up, beard, etc.) with native surveillance facial imagery data for evaluation. On the other hand, this work discovers the best recognition methods for different conditions like non-masked faces, masked faces, and faces with glasses.
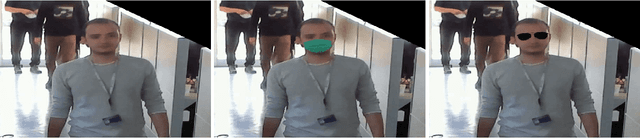
Backdoor Attacks on Facial Recognition in the Physical World
Jun 25, 2020
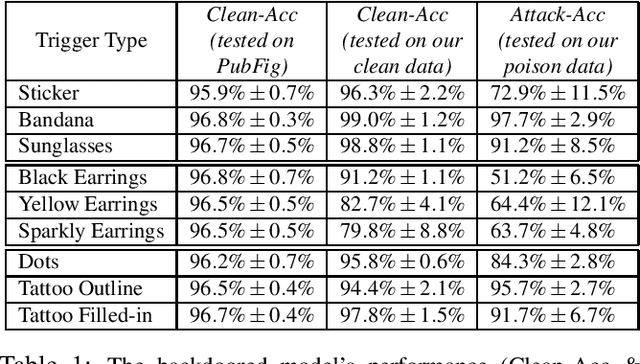

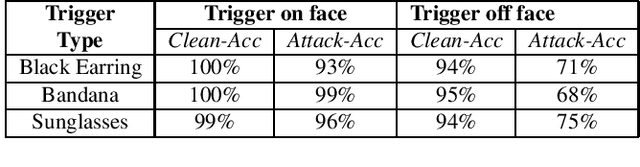
Backdoor attacks embed hidden malicious behaviors inside deep neural networks (DNNs) that are only activated when a specific "trigger" is present on some input to the model. A variety of these attacks have been successfully proposed and evaluated, generally using digitally generated patterns or images as triggers. Despite significant prior work on the topic, a key question remains unanswered: "can backdoor attacks be physically realized in the real world, and what limitations do attackers face in executing them?" In this paper, we present results of a detailed study on DNN backdoor attacks in the physical world, specifically focused on the task of facial recognition. We take 3205 photographs of 10 volunteers in a variety of settings and backgrounds and train a facial recognition model using transfer learning from VGGFace. We evaluate the effectiveness of 9 accessories as potential triggers, and analyze impact from external factors such as lighting and image quality. First, we find that triggers vary significantly in efficacy and a key factor is that facial recognition models are heavily tuned to features on the face and less so to features around the periphery. Second, the efficacy of most trigger objects is. negatively impacted by lower image quality but unaffected by lighting. Third, most triggers suffer from false positives, where non-trigger objects unintentionally activate the backdoor. Finally, we evaluate 4 backdoor defenses against physical backdoors. We show that they all perform poorly because physical triggers break key assumptions they made based on triggers in the digital domain. Our key takeaway is that implementing physical backdoors is much more challenging than described in literature for both attackers and defenders and much more work is necessary to understand how backdoors work in the real world.
Suspicious Vehicle Detection Using Licence Plate Detection And Facial Feature Recognition
Apr 18, 2023


With the increasing need to strengthen vehicle safety and detection, the availability of pre-existing methods of catching criminals and identifying vehicles manually through the various traffic surveillance cameras is not only time-consuming but also inefficient. With the advancement of technology in every field the use of real-time traffic surveillance models will help facilitate an easy approach. Keeping this in mind, the main focus of our paper is to develop a combined face recognition and number plate recognition model to ensure vehicle safety and real-time tracking of running-away criminals and stolen vehicles.
Facial Landmark Detection Evaluation on MOBIO Database
Jul 06, 2023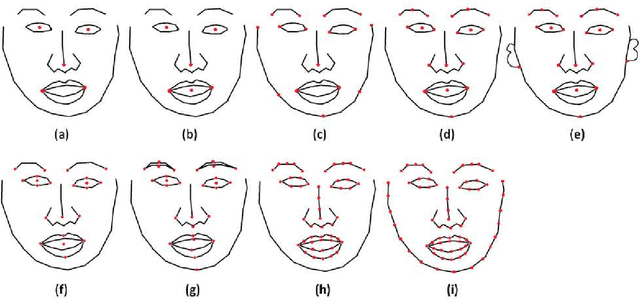
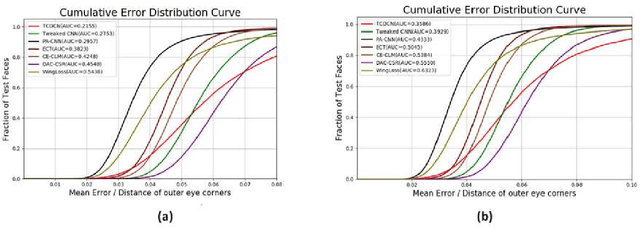
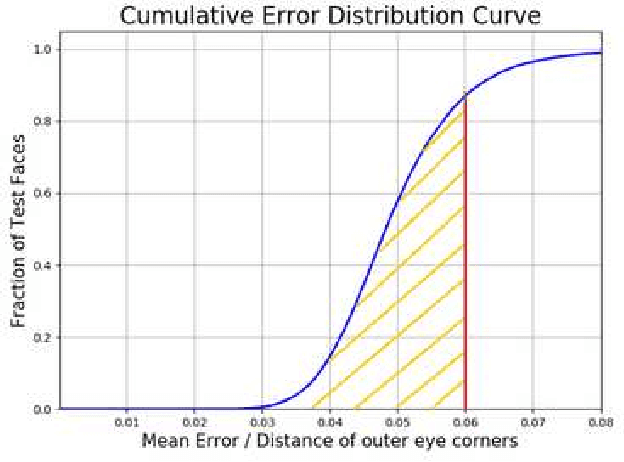
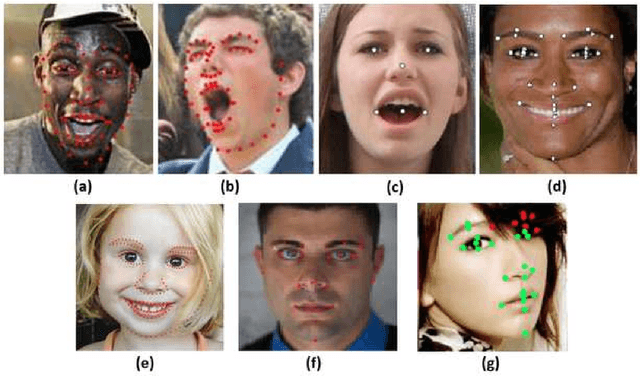
MOBIO is a bi-modal database that was captured almost exclusively on mobile phones. It aims to improve research into deploying biometric techniques to mobile devices. Research has been shown that face and speaker recognition can be performed in a mobile environment. Facial landmark localization aims at finding the coordinates of a set of pre-defined key points for 2D face images. A facial landmark usually has specific semantic meaning, e.g. nose tip or eye centre, which provides rich geometric information for other face analysis tasks such as face recognition, emotion estimation and 3D face reconstruction. Pretty much facial landmark detection methods adopt still face databases, such as 300W, AFW, AFLW, or COFW, for evaluation, but seldomly use mobile data. Our work is first to perform facial landmark detection evaluation on the mobile still data, i.e., face images from MOBIO database. About 20,600 face images have been extracted from this audio-visual database and manually labeled with 22 landmarks as the groundtruth. Several state-of-the-art facial landmark detection methods are adopted to evaluate their performance on these data. The result shows that the data from MOBIO database is pretty challenging. This database can be a new challenging one for facial landmark detection evaluation.
NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Jun 10, 2022
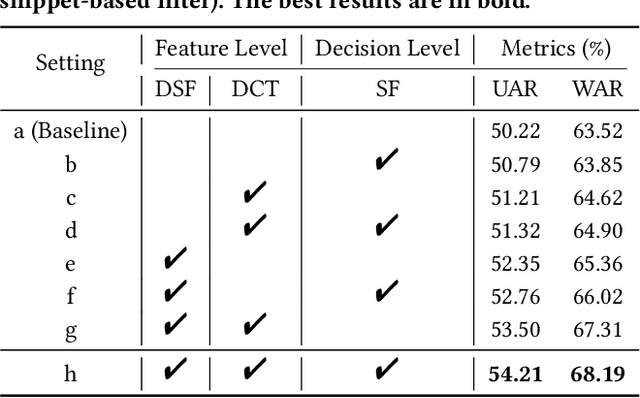
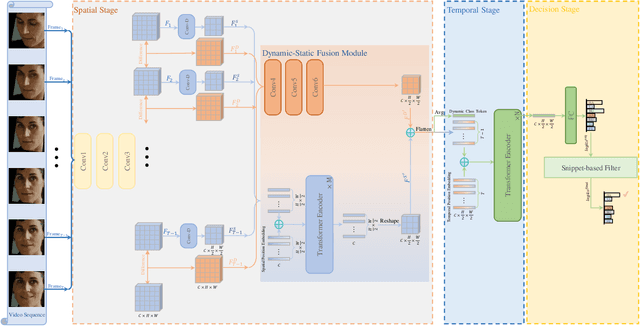
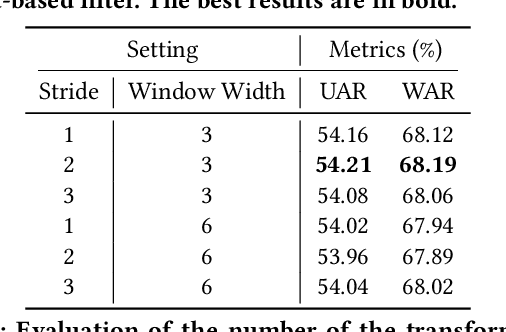
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.