 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Paper and Code
Jun 10, 2022
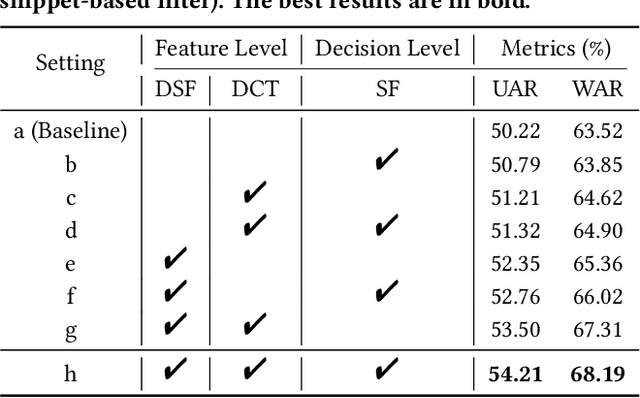
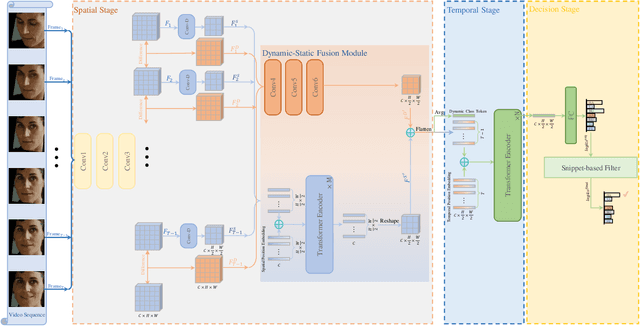
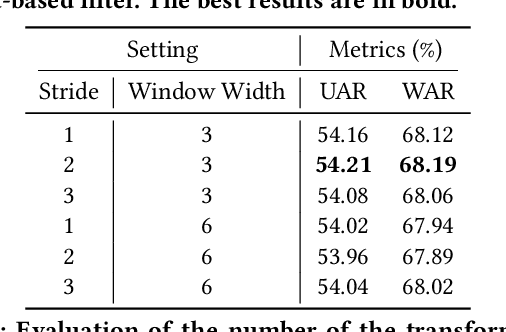
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.