 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
JointDNN: An Efficient Training and Inference Engine for Intelligent Mobile Cloud Computing Services
Jan 25, 2018
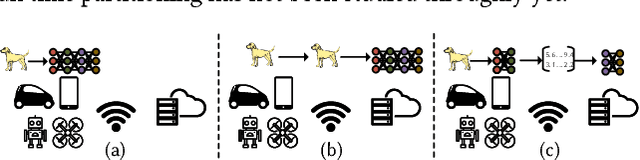
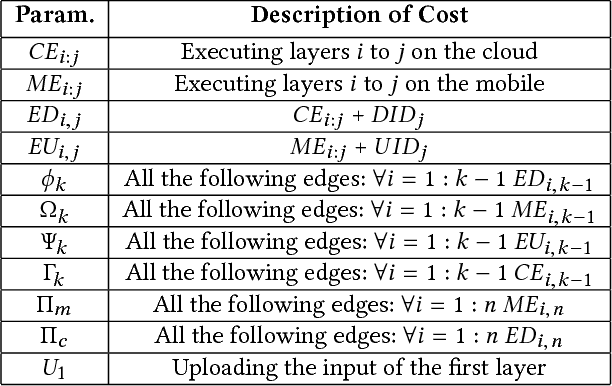
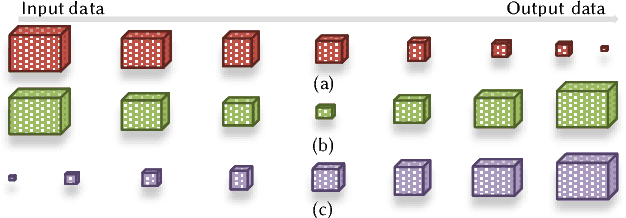
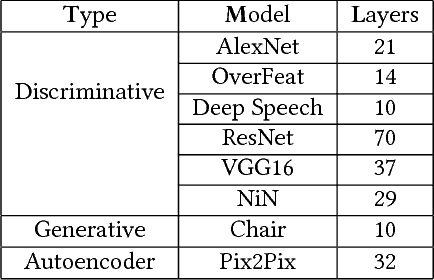
Deep neural networks are among the most influential architectures of deep learning algorithms, being deployed in many mobile intelligent applications. End-side services, such as intelligent personal assistants (IPAs), autonomous cars, and smart home services often employ either simple local models or complex remote models on the cloud. Mobile-only and cloud-only computations are currently the status quo approaches. In this paper, we propose an efficient, adaptive, and practical engine, JointDNN, for collaborative computation between a mobile device and cloud for DNNs in both inference and training phase. JointDNN not only provides an energy and performance efficient method of querying DNNs for the mobile side, but also benefits the cloud server by reducing the amount of its workload and communications compared to the cloud-only approach. Given the DNN architecture, we investigate the efficiency of processing some layers on the mobile device and some layers on the cloud server. We provide optimization formulations at layer granularity for forward and backward propagation in DNNs, which can adapt to mobile battery limitations and cloud server load constraints and quality of service. JointDNN achieves up to 18X and 32X reductions on the latency and mobile energy consumption of querying DNNs, respectively.
Detecting Adversarial Samples for Deep Neural Networks through Mutation Testing
May 17, 2018
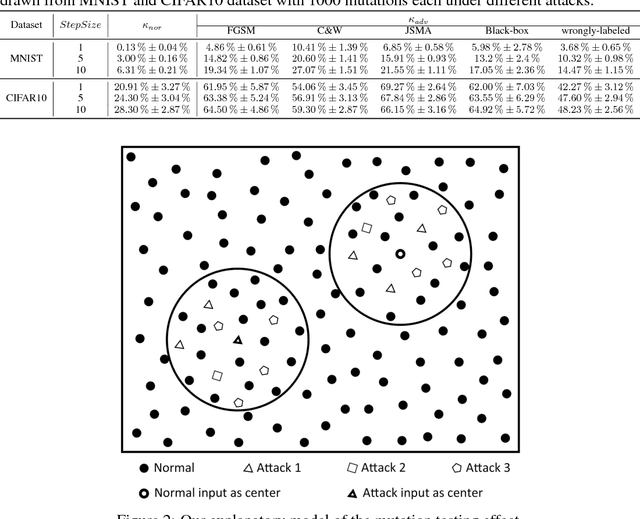
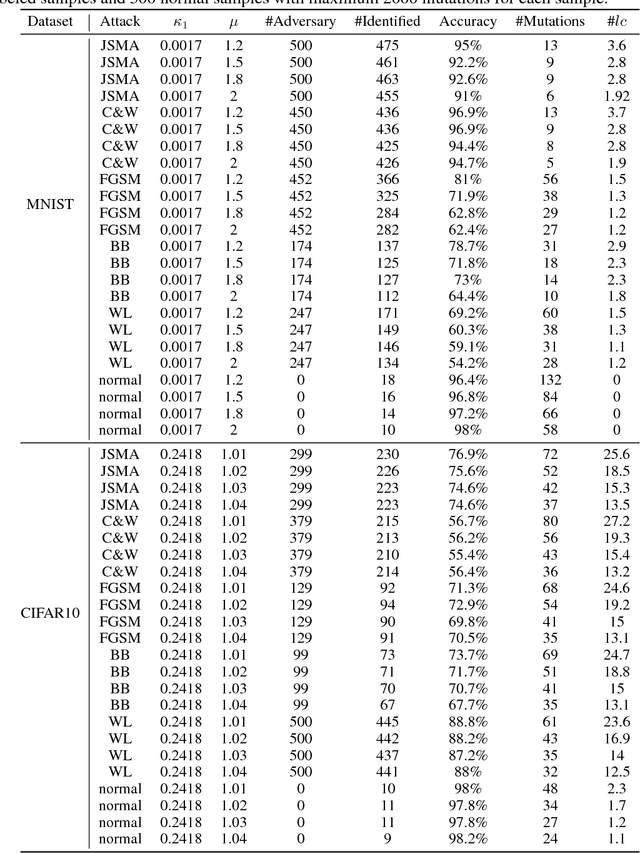
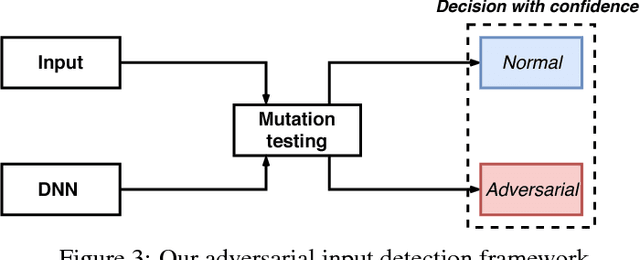
Recently, it has been shown that deep neural networks (DNN) are subject to attacks through adversarial samples. Adversarial samples are often crafted through adversarial perturbation, i.e., manipulating the original sample with minor modifications so that the DNN model labels the sample incorrectly. Given that it is almost impossible to train perfect DNN, adversarial samples are shown to be easy to generate. As DNN are increasingly used in safety-critical systems like autonomous cars, it is crucial to develop techniques for defending such attacks. Existing defense mechanisms which aim to make adversarial perturbation challenging have been shown to be ineffective. In this work, we propose an alternative approach. We first observe that adversarial samples are much more sensitive to perturbations than normal samples. That is, if we impose random perturbations on a normal and an adversarial sample respectively, there is a significant difference between the ratio of label change due to the perturbations. Observing this, we design a statistical adversary detection algorithm called nMutant (inspired by mutation testing from software engineering community). Our experiments show that nMutant effectively detects most of the adversarial samples generated by recently proposed attacking methods. Furthermore, we provide an error bound with certain statistical significance along with the detection.
A Hierarchical Deep Architecture and Mini-Batch Selection Method For Joint Traffic Sign and Light Detection
Sep 13, 2018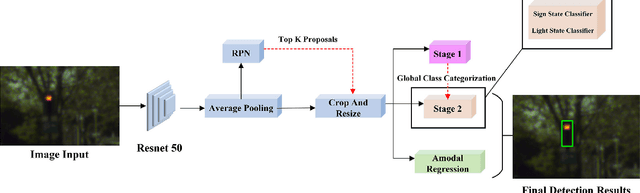



Traffic light and sign detectors on autonomous cars are integral for road scene perception. The literature is abundant with deep learning networks that detect either lights or signs, not both, which makes them unsuitable for real-life deployment due to the limited graphics processing unit (GPU) memory and power available on embedded systems. The root cause of this issue is that no public dataset contains both traffic light and sign labels, which leads to difficulties in developing a joint detection framework. We present a deep hierarchical architecture in conjunction with a mini-batch proposal selection mechanism that allows a network to detect both traffic lights and signs from training on separate traffic light and sign datasets. Our method solves the overlapping issue where instances from one dataset are not labelled in the other dataset. We are the first to present a network that performs joint detection on traffic lights and signs. We measure our network on the Tsinghua-Tencent 100K benchmark for traffic sign detection and the Bosch Small Traffic Lights benchmark for traffic light detection and show it outperforms the existing Bosch Small Traffic light state-of-the-art method. We focus on autonomous car deployment and show our network is more suitable than others because of its low memory footprint and real-time image processing time. Qualitative results can be viewed at https://youtu.be/_YmogPzBXOw
fpgaConvNet: A Toolflow for Mapping Diverse Convolutional Neural Networks on Embedded FPGAs
Nov 23, 2017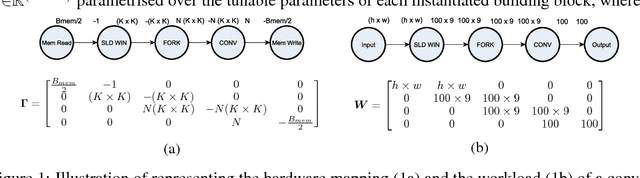
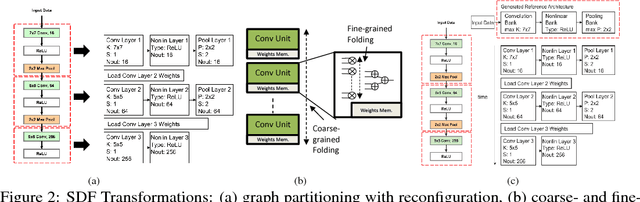
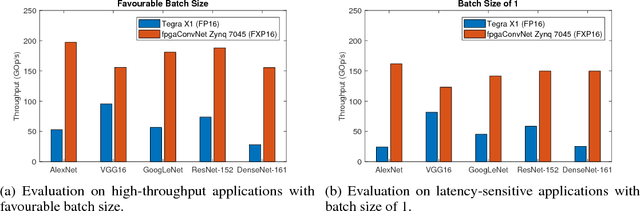
In recent years, Convolutional Neural Networks (ConvNets) have become an enabling technology for a wide range of novel embedded Artificial Intelligence systems. Across the range of applications, the performance needs vary significantly, from high-throughput video surveillance to the very low-latency requirements of autonomous cars. In this context, FPGAs can provide a potential platform that can be optimally configured based on the different performance needs. However, the complexity of ConvNet models keeps increasing making their mapping to an FPGA device a challenging task. This work presents fpgaConvNet, an end-to-end framework for mapping ConvNets on FPGAs. The proposed framework employs an automated design methodology based on the Synchronous Dataflow (SDF) paradigm and defines a set of SDF transformations in order to efficiently explore the architectural design space. By selectively optimising for throughput, latency or multiobjective criteria, the presented tool is able to efficiently explore the design space and generate hardware designs from high-level ConvNet specifications, explicitly optimised for the performance metric of interest. Overall, our framework yields designs that improve the performance by up to 6.65x over highly optimised embedded GPU designs for the same power constraints in embedded environments.
The Impact of Blocking Cars on Pathloss Within a Platoon: Measurements for 26 GHz Band
Oct 06, 2021
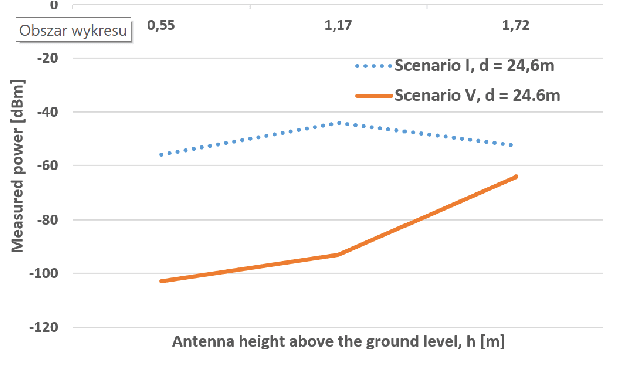
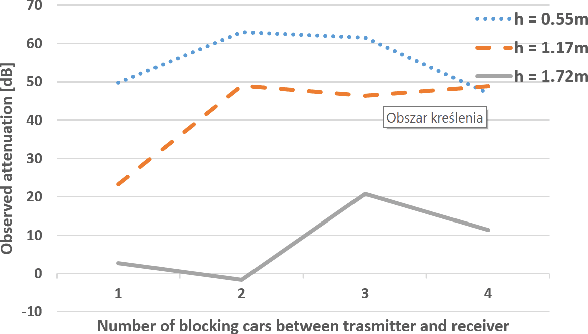
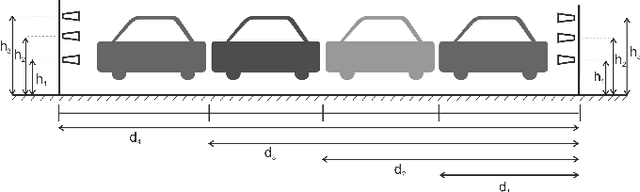
Platooning is considered to be one of the possible prospective implementations of the autonomous driving concept, where the train-of-cars moves together following the platoon leader's commands. However, the practical realization of this scheme assumes the use of reliable communications between platoon members. In this paper, the results of the measurement experiment have been presented showing the impact of the blocking cars on the signal attenuation. The tests have been carried out for the high-frequency band, i.e. for 26.555 GHz. It has been observed that on one hand side, the attenuation can reach even tens of dB for 2 or 3 blocking cars, but in some locations, the impact of a two-ray propagation mitigates the presence of obstructing vehicles.
A Hybrid Learner for Simultaneous Localization and Mapping
Jan 04, 2021
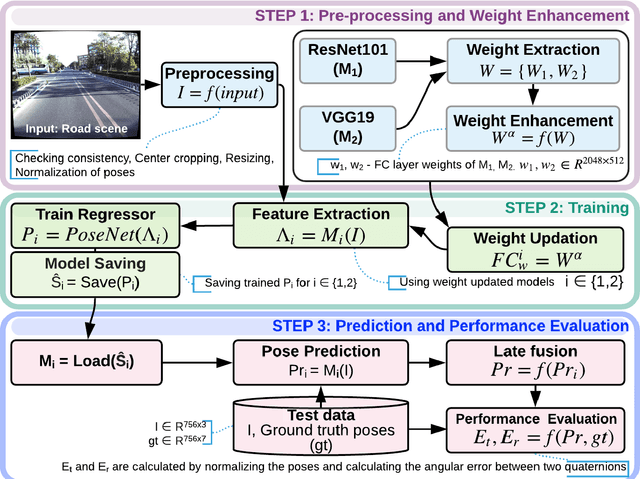
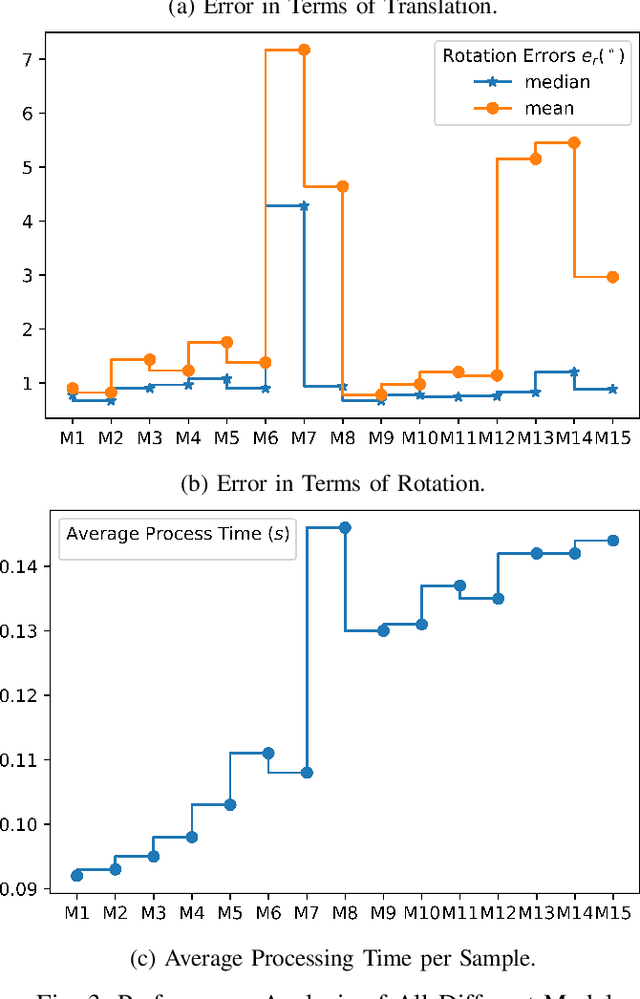
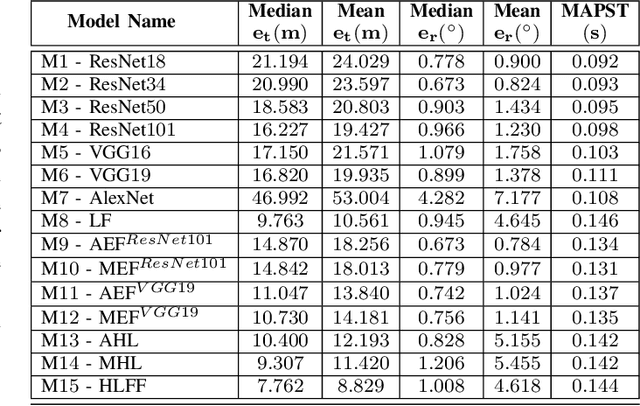
Simultaneous localization and mapping (SLAM) is used to predict the dynamic motion path of a moving platform based on the location coordinates and the precise mapping of the physical environment. SLAM has great potential in augmented reality (AR), autonomous vehicles, viz. self-driving cars, drones, Autonomous navigation robots (ANR). This work introduces a hybrid learning model that explores beyond feature fusion and conducts a multimodal weight sewing strategy towards improving the performance of a baseline SLAM algorithm. It carries out weight enhancement of the front end feature extractor of the SLAM via mutation of different deep networks' top layers. At the same time, the trajectory predictions from independently trained models are amalgamated to refine the location detail. Thus, the integration of the aforesaid early and late fusion techniques under a hybrid learning framework minimizes the translation and rotation errors of the SLAM model. This study exploits some well-known deep learning (DL) architectures, including ResNet18, ResNet34, ResNet50, ResNet101, VGG16, VGG19, and AlexNet for experimental analysis. An extensive experimental analysis proves that hybrid learner (HL) achieves significantly better results than the unimodal approaches and multimodal approaches with early or late fusion strategies. Hence, it is found that the Apolloscape dataset taken in this work has never been used in the literature under SLAM with fusion techniques, which makes this work unique and insightful.
End-to-End Velocity Estimation For Autonomous Racing
Mar 15, 2020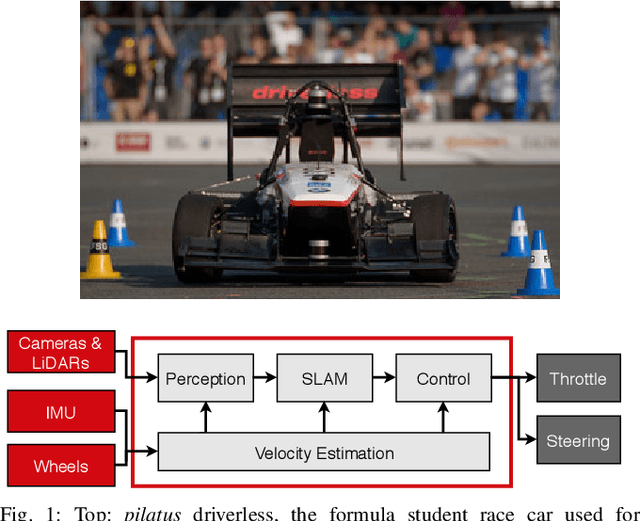
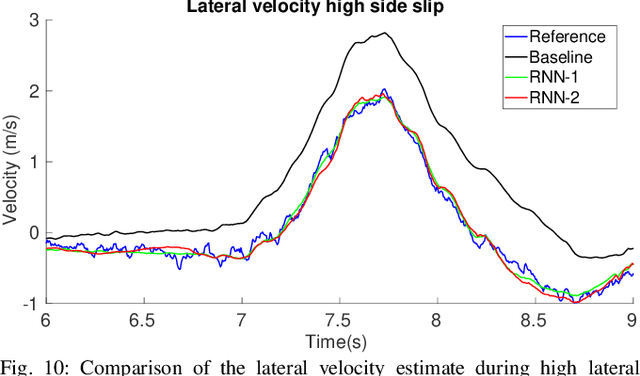
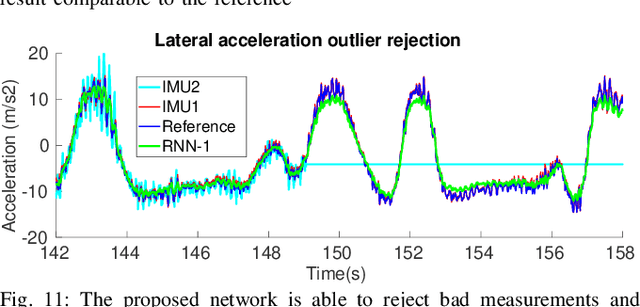
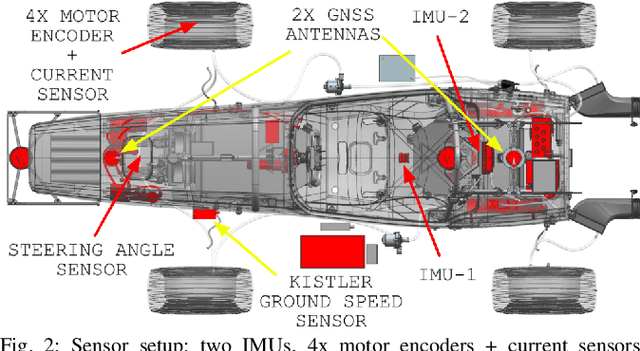
Velocity estimation plays a central role in driverless vehicles, but standard and affordable methods struggle to cope with extreme scenarios like aggressive maneuvers due to the presence of high sideslip. To solve this, autonomous race cars are usually equipped with expensive external velocity sensors. In this paper, we present an end-to-end recurrent neural network that takes available raw sensors as input (IMU, wheel odometry, and motor currents) and outputs velocity estimates. The results are compared to two state-of-the-art Kalman filters, which respectively include and exclude expensive velocity sensors. All methods have been extensively tested on a formula student driverless race car with very high sideslip (10{\deg} at the rear axle) and slip ratio (~20%), operating close to the limits of handling. The proposed network is able to estimate lateral velocity up to 15x better than the Kalman filter with the equivalent sensor input and matches (0.06 m/s RMSE) the Kalman filter with the expensive velocity sensor setup.
Intersection focused Situation Coverage-based Verification and Validation Framework for Autonomous Vehicles Implemented in CARLA
Dec 24, 2021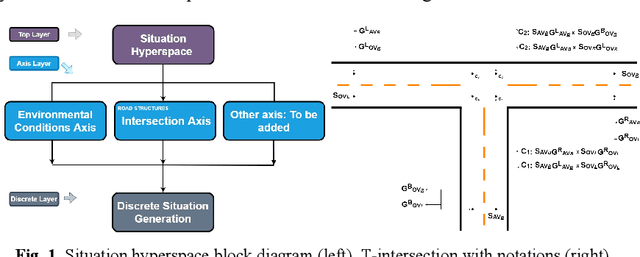
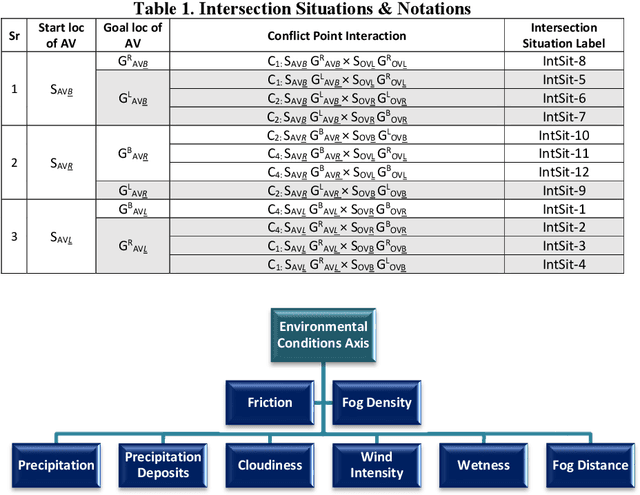

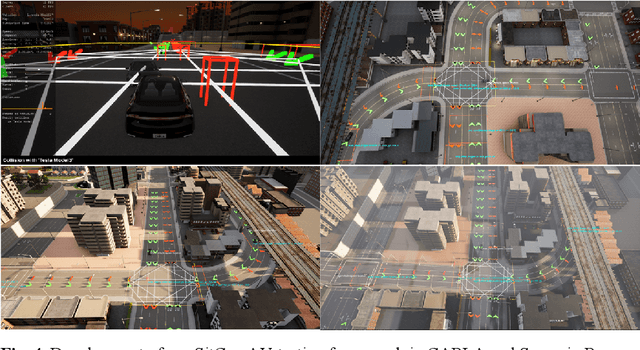
Autonomous Vehicles (AVs) i.e., self-driving cars, operate in a safety critical domain, since errors in the autonomous driving software can lead to huge losses. Statistically, road intersections which are a part of the AVs operational design domain (ODD), have some of the highest accident rates. Hence, testing AVs to the limits on road intersections and assuring their safety on road intersections is pertinent, and thus the focus of this paper. We present a situation coverage-based (SitCov) AV-testing framework for the verification and validation (V&V) and safety assurance of AVs, developed in an open-source AV simulator named CARLA. The SitCov AV-testing framework focuses on vehicle-to-vehicle interaction on a road intersection under different environmental and intersection configuration situations, using situation coverage criteria for automatic test suite generation for safety assurance of AVs. We have developed an ontology for intersection situations, and used it to generate a situation hyperspace i.e., the space of all possible situations arising from that ontology. For the evaluation of our SitCov AV-testing framework, we have seeded multiple faults in our ego AV, and compared situation coverage based and random situation generation. We have found that both generation methodologies trigger around the same number of seeded faults, but the situation coverage-based generation tells us a lot more about the weaknesses of the autonomous driving algorithm of our ego AV, especially in edge-cases. Our code is publicly available online, anyone can use our SitCov AV-testing framework and use it or build further on top of it. This paper aims to contribute to the domain of V&V and development of AVs, not only from a theoretical point of view, but also from the viewpoint of an open-source software contribution and releasing a flexible/effective tool for V&V and development of AVs.
ABMOF: A Novel Optical Flow Algorithm for Dynamic Vision Sensors
May 10, 2018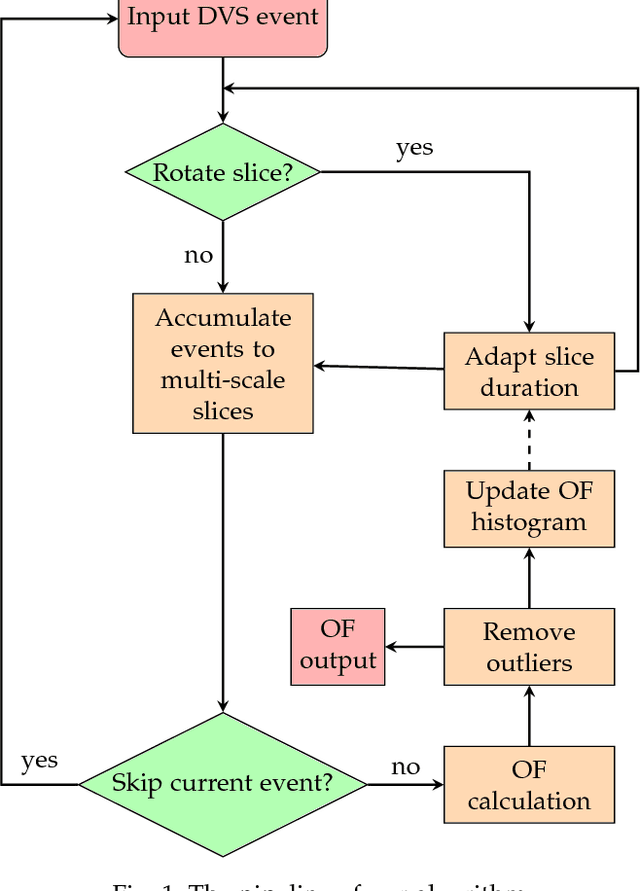

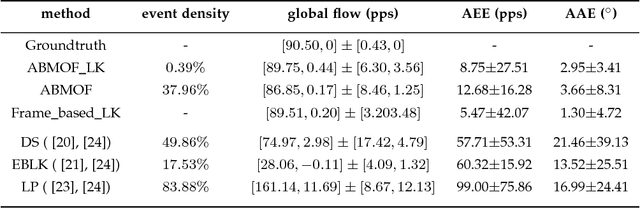
Dynamic Vision Sensors (DVS), which output asynchronous log intensity change events, have potential applications in high-speed robotics, autonomous cars and drones. The precise event timing, sparse output, and wide dynamic range of the events are well suited for optical flow, but conventional optical flow (OF) algorithms are not well matched to the event stream data. This paper proposes an event-driven OF algorithm called adaptive block-matching optical flow (ABMOF). ABMOF uses time slices of accumulated DVS events. The time slices are adaptively rotated based on the input events and OF results. Compared with other methods such as gradient-based OF, ABMOF can efficiently be implemented in compact logic circuits. Results show that ABMOF achieves comparable accuracy to conventional standards such as Lucas-Kanade (LK). The main contributions of our paper are new adaptive time-slice rotation methods that ensure the generated slices have sufficient features for matching,including a feedback mechanism that controls the generated slices to have average slice displacement within the block search range. An LK method using our adapted slices is also implemented. The ABMOF accuracy is compared with this LK method on natural scene data including sparse and dense texture, high dynamic range, and fast motion exceeding 30,000 pixels per second.The paper dataset and source code are available from http://sensors.ini.uzh.ch/databases.html.
A Quick Review on Recent Trends in 3D Point Cloud Data Compression Techniques and the Challenges of Direct Processing in 3D Compressed Domain
Jul 08, 2020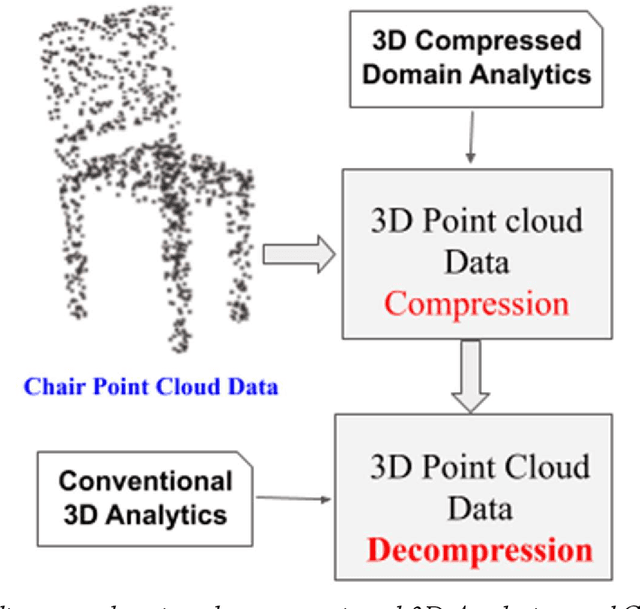
Automatic processing of 3D Point Cloud data for object detection, tracking and segmentation is the latest trending research in the field of AI and Data Science, which is specifically aimed at solving different challenges of autonomous driving cars and getting real time performance. However, the amount of data that is being produced in the form of 3D point cloud (with LiDAR) is very huge, due to which the researchers are now on the way inventing new data compression algorithms to handle huge volumes of data thus generated. However, compression on one hand has an advantage in overcoming space requirements, but on the other hand, its processing gets expensive due to the decompression, which indents additional computing resources. Therefore, it would be novel to think of developing algorithms that can operate/analyse directly with the compressed data without involving the stages of decompression and recompression (required as many times, the compressed data needs to be operated or analyzed). This research field is termed as Compressed Domain Processing. In this paper, we will quickly review few of the recent state-of-the-art developments in the area of LiDAR generated 3D point cloud data compression, and highlight the future challenges of compressed domain processing of 3D point cloud data.