 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTrans: Learning Text-enhanced Local-global Temporal Representations for Zero-shot Temporal Action Localization
May 29, 2026Zero-shot Temporal Action Localization (ZS-TAL) aims to detect and locate previously unseen actions in untrimmed videos. However, existing approaches primarily focus on modeling long-range contextual information, often neglecting the critical relative-offset-based local correlations between video frames. Furthermore, their performance is hindered by limited feature representation capabilities due to the shallow nature of their network architectures. In this paper, we address these limitations by introducing a novel local-global multi-scale feature representation module. We propose a novel multi-scale encoder architecture, termed ConTrans, that integrates convolutional (Conv) inductive biases with transformer Self-attention to jointly capture fine-grained local dependencies and long-range global context, leading to more comprehensive feature representations than existing methods. Experimental evaluations on the ActivityNet-1.3 and THUMOS14 datasets demonstrate that ConTrans significantly outperforms existing methods, establishing a new benchmark for ZS-TAL.
xModel-KD: Cross-modal Knowledge Distillation for 3D Scene Perception using LiDAR
May 28, 2026Point cloud segmentation is a fundamental task in 3D scene understanding. Its progress is constrained by the high cost and time required for dense 3D annotations, making labeled samples difficult to obtain. Beyond annotation scarcity, different sensing modalities face inherent limitations. 2D images provide rich texture and appearance cues, yet they lack explicit depth and geometric structure. In contrast, 3D point clouds capture accurate spatial geometry but are sparse and contain no texture information. As a result, relying on a single modality restricts the richness of learned representations and weakens generalization. Although recent multi-modal methods that combine 3D point clouds with 2D images have demonstrated strong performance in tasks such as classification and retrieval, they typically depend on large-scale labeled datasets and have not been fully exploited for data-efficient dense prediction. To address these limitations, we propose a novel cross-modal knowledge distillation framework, xModel-KD, for 3D point cloud segmentation. Our method exploits the complementary strengths of 2D texture and 3D geometry by learning unified per-point representations through cross-modal alignment. Specifically, we design a cross-modal fusion encoder trained with a contrastive objective that enforces feature consistency between corresponding 2D and 3D representations across multiple views. By integrating powerful pre-trained backbones with a targeted fusion strategy, the proposed framework effectively transfers appearance cues from images to geometry-aware point features. Experimental results show that cross-modal fusion achieves a 2% absolute improvement in mIoU over a LiDAR-only baseline, demonstrating the benefit of leveraging complementary multi-modal information for scalable and annotation-efficient 3D scene understanding.
DAS-SK: An Adaptive Model Integrating Dual Atrous Separable and Selective Kernel CNN for Agriculture Semantic Segmentation
Feb 09, 2026Semantic segmentation in high-resolution agricultural imagery demands models that strike a careful balance between accuracy and computational efficiency to enable deployment in practical systems. In this work, we propose DAS-SK, a novel lightweight architecture that retrofits selective kernel convolution (SK-Conv) into the dual atrous separable convolution (DAS-Conv) module to strengthen multi-scale feature learning. The model further enhances the atrous spatial pyramid pooling (ASPP) module, enabling the capture of fine-grained local structures alongside global contextual information. Built upon a modified DeepLabV3 framework with two complementary backbones - MobileNetV3-Large and EfficientNet-B3, the DAS-SK model mitigates limitations associated with large dataset requirements, limited spectral generalization, and the high computational cost that typically restricts deployment on UAVs and other edge devices. Comprehensive experiments across three benchmarks: LandCover.ai, VDD, and PhenoBench, demonstrate that DAS-SK consistently achieves state-of-the-art performance, while being more efficient than CNN-, transformer-, and hybrid-based competitors. Notably, DAS-SK requires up to 21x fewer parameters and 19x fewer GFLOPs than top-performing transformer models. These findings establish DAS-SK as a robust, efficient, and scalable solution for real-time agricultural robotics and high-resolution remote sensing, with strong potential for broader deployment in other vision domains.
Self-Supervised Learning for Image Segmentation: A Comprehensive Survey
May 19, 2025Supervised learning demands large amounts of precisely annotated data to achieve promising results. Such data curation is labor-intensive and imposes significant overhead regarding time and costs. Self-supervised learning (SSL) partially overcomes these limitations by exploiting vast amounts of unlabeled data and creating surrogate (pretext or proxy) tasks to learn useful representations without manual labeling. As a result, SSL has become a powerful machine learning (ML) paradigm for solving several practical downstream computer vision problems, such as classification, detection, and segmentation. Image segmentation is the cornerstone of many high-level visual perception applications, including medical imaging, intelligent transportation, agriculture, and surveillance. Although there is substantial research potential for developing advanced algorithms for SSL-based semantic segmentation, a comprehensive study of existing methodologies is essential to trace advances and guide emerging researchers. This survey thoroughly investigates over 150 recent image segmentation articles, particularly focusing on SSL. It provides a practical categorization of pretext tasks, downstream tasks, and commonly used benchmark datasets for image segmentation research. It concludes with key observations distilled from a large body of literature and offers future directions to make this research field more accessible and comprehensible for readers.
Benchmarking Deep Learning Models on NVIDIA Jetson Nano for Real-Time Systems: An Empirical Investigation
Jun 25, 2024



The proliferation of complex deep learning (DL) models has revolutionized various applications, including computer vision-based solutions, prompting their integration into real-time systems. However, the resource-intensive nature of these models poses challenges for deployment on low-computational power and low-memory devices, like embedded and edge devices. This work empirically investigates the optimization of such complex DL models to analyze their functionality on an embedded device, particularly on the NVIDIA Jetson Nano. It evaluates the effectiveness of the optimized models in terms of their inference speed for image classification and video action detection. The experimental results reveal that, on average, optimized models exhibit a 16.11% speed improvement over their non-optimized counterparts. This not only emphasizes the critical need to consider hardware constraints and environmental sustainability in model development and deployment but also underscores the pivotal role of model optimization in enabling the widespread deployment of AI-assisted technologies on resource-constrained computational systems. It also serves as proof that prioritizing hardware-specific model optimization leads to efficient and scalable solutions that substantially decrease energy consumption and carbon footprint.
Phasor-Driven Acceleration for FFT-based CNNs
Jun 01, 2024



Recent research in deep learning (DL) has investigated the use of the Fast Fourier Transform (FFT) to accelerate the computations involved in Convolutional Neural Networks (CNNs) by replacing spatial convolution with element-wise multiplications on the spectral domain. These approaches mainly rely on the FFT to reduce the number of operations, which can be further decreased by adopting the Real-Valued FFT. In this paper, we propose using the phasor form, a polar representation of complex numbers, as a more efficient alternative to the traditional approach. The experimental results, evaluated on the CIFAR-10, demonstrate that our method achieves superior speed improvements of up to a factor of 1.376 (average of 1.316) during training and up to 1.390 (average of 1.321) during inference when compared to the traditional rectangular form employed in modern CNN architectures. Similarly, when evaluated on the CIFAR-100, our method achieves superior speed improvements of up to a factor of 1.375 (average of 1.299) during training and up to 1.387 (average of 1.300) during inference. Most importantly, given the modular aspect of our approach, the proposed method can be applied to any existing convolution-based DL model without design changes.
Low-light Pedestrian Detection in Visible and Infrared Image Feeds: Issues and Challenges
Nov 14, 2023Pedestrian detection has become a cornerstone for several high-level tasks, including autonomous driving, intelligent transportation, and traffic surveillance. There are several works focussed on pedestrian detection using visible images, mainly in the daytime. However, this task is very intriguing when the environmental conditions change to poor lighting or nighttime. Recently, new ideas have been spurred to use alternative sources, such as Far InfraRed (FIR) temperature sensor feeds for detecting pedestrians in low-light conditions. This study comprehensively reviews recent developments in low-light pedestrian detection approaches. It systematically categorizes and analyses various algorithms from region-based to non-region-based and graph-based learning methodologies by highlighting their methodologies, implementation issues, and challenges. It also outlines the key benchmark datasets that can be used for research and development of advanced pedestrian detection algorithms, particularly in low-light situations
Advanced Deep Regression Models for Forecasting Time Series Oil Production
Aug 30, 2023



Global oil demand is rapidly increasing and is expected to reach 106.3 million barrels per day by 2040. Thus, it is vital for hydrocarbon extraction industries to forecast their production to optimize their operations and avoid losses. Big companies have realized that exploiting the power of deep learning (DL) and the massive amount of data from various oil wells for this purpose can save a lot of operational costs and reduce unwanted environmental impacts. In this direction, researchers have proposed models using conventional machine learning (ML) techniques for oil production forecasting. However, these techniques are inappropriate for this problem as they can not capture historical patterns found in time series data, resulting in inaccurate predictions. This research aims to overcome these issues by developing advanced data-driven regression models using sequential convolutions and long short-term memory (LSTM) units. Exhaustive analyses are conducted to select the optimal sequence length, model hyperparameters, and cross-well dataset formation to build highly generalized robust models. A comprehensive experimental study on Volve oilfield data validates the proposed models. It reveals that the LSTM-based sequence learning model can predict oil production better than the 1-D convolutional neural network (CNN) with mean absolute error (MAE) and R2 score of 111.16 and 0.98, respectively. It is also found that the LSTM-based model performs better than all the existing state-of-the-art solutions and achieves a 37% improvement compared to a standard linear regression, which is considered the baseline model in this work.
Multi-class Brain Tumor Segmentation using Graph Attention Network
Feb 11, 2023



Brain tumor segmentation from magnetic resonance imaging (MRI) plays an important role in diagnostic radiology. To overcome the practical issues in manual approaches, there is a huge demand for building automatic tumor segmentation algorithms. This work introduces an efficient brain tumor summation model by exploiting the advancement in MRI and graph neural networks (GNNs). The model represents the volumetric MRI as a region adjacency graph (RAG) and learns to identify the type of tumors through a graph attention network (GAT) -- a variant of GNNs. The ablation analysis conducted on two benchmark datasets proves that the proposed model can produce competitive results compared to the leading-edge solutions. It achieves mean dice scores of 0.91, 0.86, 0.79, and mean Hausdorff distances in the 95th percentile (HD95) of 5.91, 6.08, and 9.52 mm, respectively, for whole tumor, core tumor, and enhancing tumor segmentation on BraTS2021 validation dataset. On average, these performances are >6\% and >50%, compared to a GNN-based baseline model, respectively, on dice score and HD95 evaluation metrics.
ANOVA-based Automatic Attribute Selection and a Predictive Model for Heart Disease Prognosis
Jul 30, 2022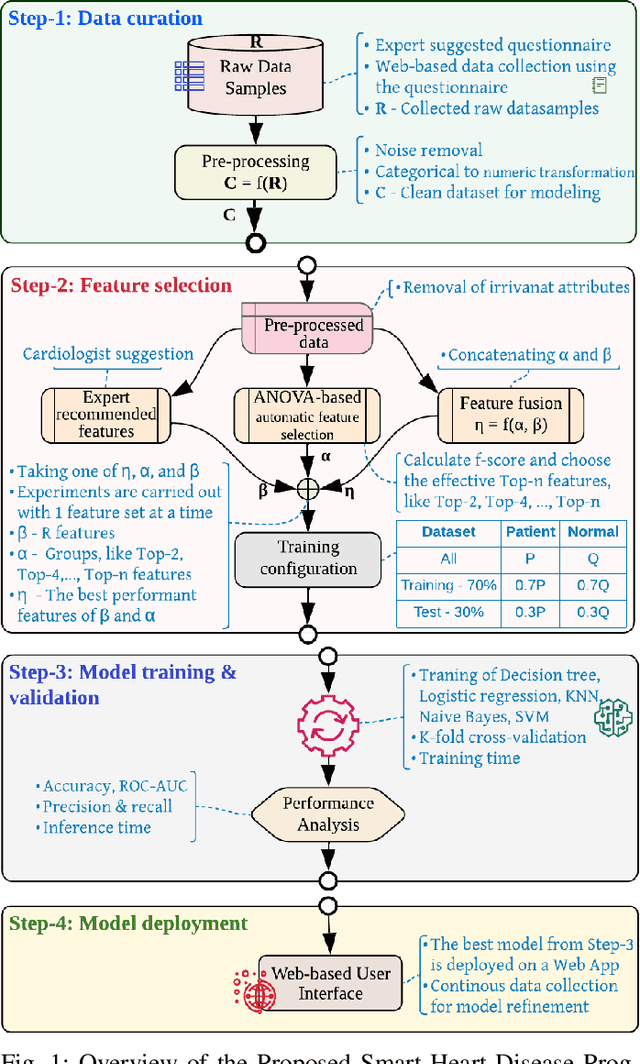

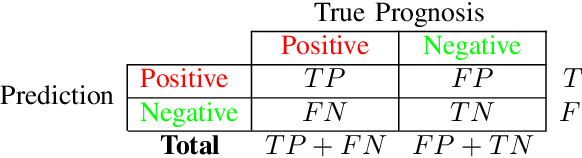
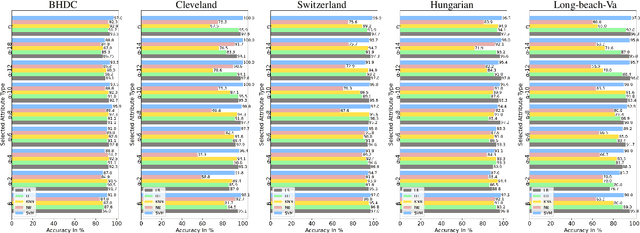
Studies show that Studies that cardiovascular diseases (CVDs) are malignant for human health. Thus, it is important to have an efficient way of CVD prognosis. In response to this, the healthcare industry has adopted machine learning-based smart solutions to alleviate the manual process of CVD prognosis. Thus, this work proposes an information fusion technique that combines key attributes of a person through analysis of variance (ANOVA) and domain experts' knowledge. It also introduces a new collection of CVD data samples for emerging research. There are thirty-eight experiments conducted exhaustively to verify the performance of the proposed framework on four publicly available benchmark datasets and the newly created dataset in this work. The ablation study shows that the proposed approach can achieve a competitive mean average accuracy (mAA) of 99.2% and a mean average AUC of 97.9%.