 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Topic-Aware Abstractive Text Summarization
Oct 20, 2020
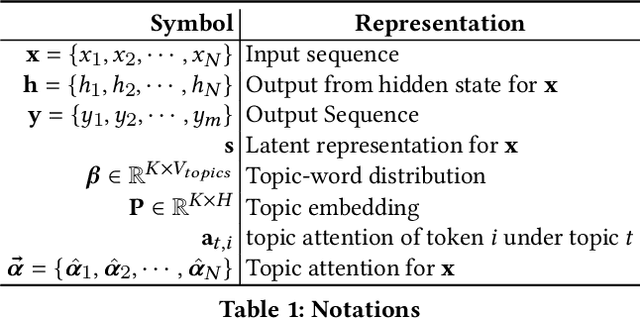
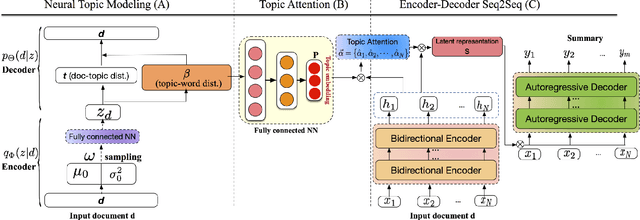
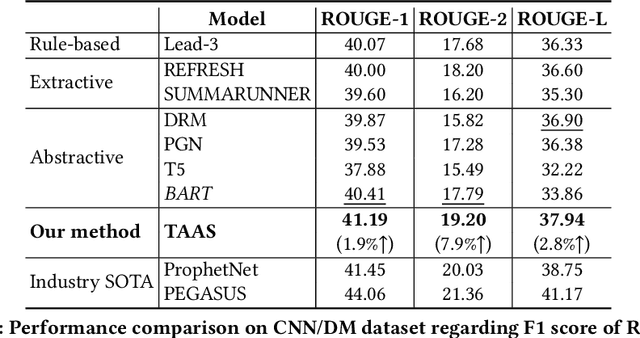
Automatic text summarization aims at condensing a document to a shorter version while preserving the key information. Different from extractive summarization which simply selects text fragments from the document, abstractive summarization generates the summary in a word-by-word manner. Most current state-of-the-art (SOTA) abstractive summarization methods are based on the Transformer-based encoder-decoder architecture and focus on novel self-supervised objectives in pre-training. While these models well capture the contextual information among words in documents, little attention has been paid to incorporating global semantics to better fine-tune for the downstream abstractive summarization task. In this study, we propose a topic-aware abstractive summarization (TAAS) framework by leveraging the underlying semantic structure of documents represented by their latent topics. Specifically, TAAS seamlessly incorporates a neural topic modeling into an encoder-decoder based sequence generation procedure via attention for summarization. This design is able to learn and preserve global semantics of documents and thus makes summarization effective, which has been proved by our experiments on real-world datasets. As compared to several cutting-edge baseline methods, we show that TAAS outperforms BART, a well-recognized SOTA model, by 2%, 8%, and 12% regarding the F measure of ROUGE-1, ROUGE-2, and ROUGE-L, respectively. TAAS also achieves comparable performance to PEGASUS and ProphetNet, which is difficult to accomplish given that training PEGASUS and ProphetNet requires enormous computing capacity beyond what we used in this study.
Topic Extraction of Crawled Documents Collection using Correlated Topic Model in MapReduce Framework
Jan 06, 2020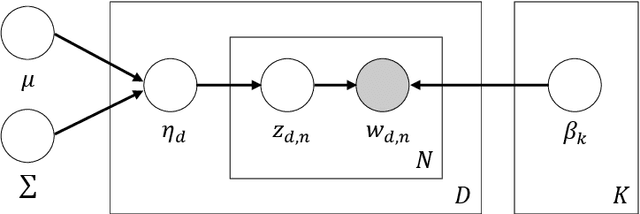

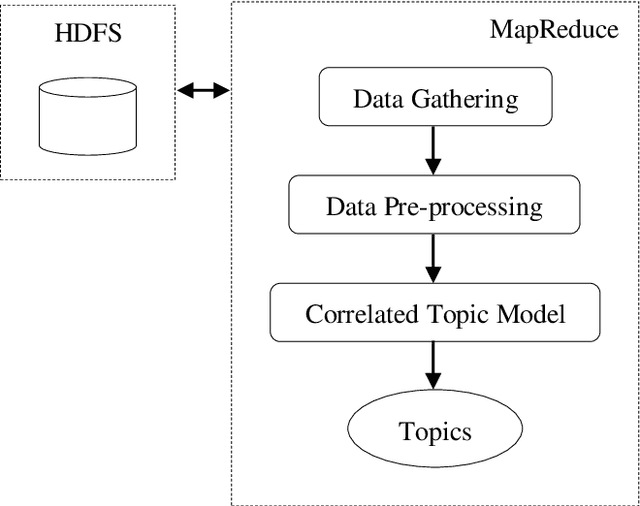
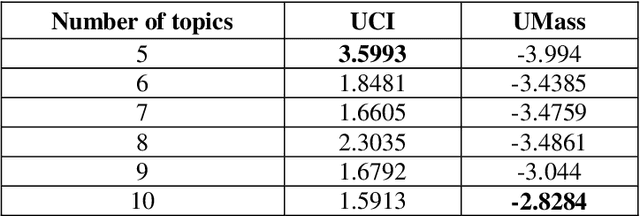
The tremendous increase in the amount of available research documents impels researchers to propose topic models to extract the latent semantic themes of a documents collection. However, how to extract the hidden topics of the documents collection has become a crucial task for many topic model applications. Moreover, conventional topic modeling approaches suffer from the scalability problem when the size of documents collection increases. In this paper, the Correlated Topic Model with variational Expectation-Maximization algorithm is implemented in MapReduce framework to solve the scalability problem. The proposed approach utilizes the dataset crawled from the public digital library. In addition, the full-texts of the crawled documents are analysed to enhance the accuracy of MapReduce CTM. The experiments are conducted to demonstrate the performance of the proposed algorithm. From the evaluation, the proposed approach has a comparable performance in terms of topic coherences with LDA implemented in MapReduce framework.
Two Huge Title and Keyword Generation Corpora of Research Articles
Feb 11, 2020
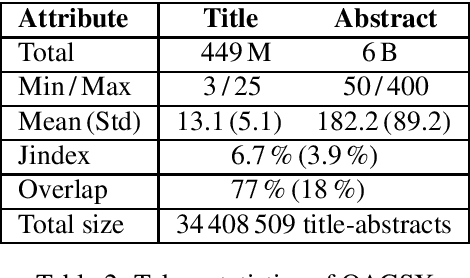
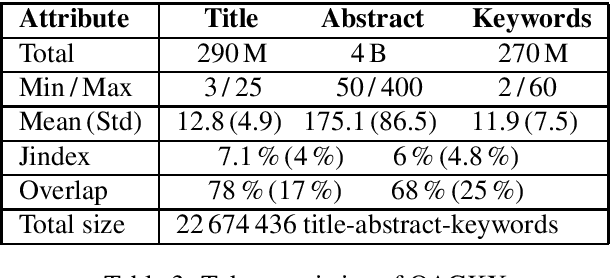
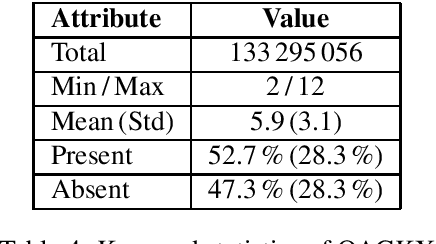
Recent developments in sequence-to-sequence learning with neural networks have considerably improved the quality of automatically generated text summaries and document keywords, stipulating the need for even bigger training corpora. Metadata of research articles are usually easy to find online and can be used to perform research on various tasks. In this paper, we introduce two huge datasets for text summarization (OAGSX) and keyword generation (OAGKX) research, containing 34 million and 23 million records, respectively. The data were retrieved from the Open Academic Graph which is a network of research profiles and publications. We carefully processed each record and also tried several extractive and abstractive methods of both tasks to create performance baselines for other researchers. We further illustrate the performance of those methods previewing their outputs. In the near future, we would like to apply topic modeling on the two sets to derive subsets of research articles from more specific disciplines.
ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech
Feb 16, 2022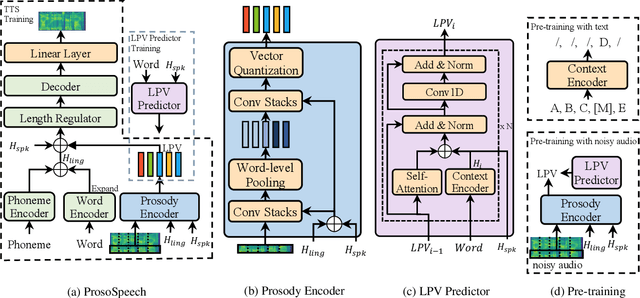
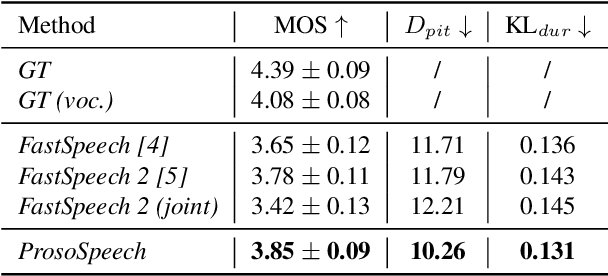
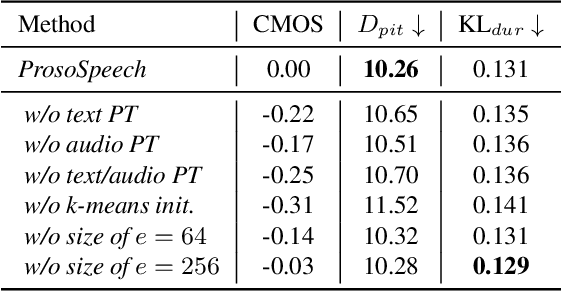
Expressive text-to-speech (TTS) has become a hot research topic recently, mainly focusing on modeling prosody in speech. Prosody modeling has several challenges: 1) the extracted pitch used in previous prosody modeling works have inevitable errors, which hurts the prosody modeling; 2) different attributes of prosody (e.g., pitch, duration and energy) are dependent on each other and produce the natural prosody together; and 3) due to high variability of prosody and the limited amount of high-quality data for TTS training, the distribution of prosody cannot be fully shaped. To tackle these issues, we propose ProsoSpeech, which enhances the prosody using quantized latent vectors pre-trained on large-scale unpaired and low-quality text and speech data. Specifically, we first introduce a word-level prosody encoder, which quantizes the low-frequency band of the speech and compresses prosody attributes in the latent prosody vector (LPV). Then we introduce an LPV predictor, which predicts LPV given word sequence. We pre-train the LPV predictor on large-scale text and low-quality speech data and fine-tune it on the high-quality TTS dataset. Finally, our model can generate expressive speech conditioned on the predicted LPV. Experimental results show that ProsoSpeech can generate speech with richer prosody compared with baseline methods.
Measuring Emotions in the COVID-19 Real World Worry Dataset
Apr 08, 2020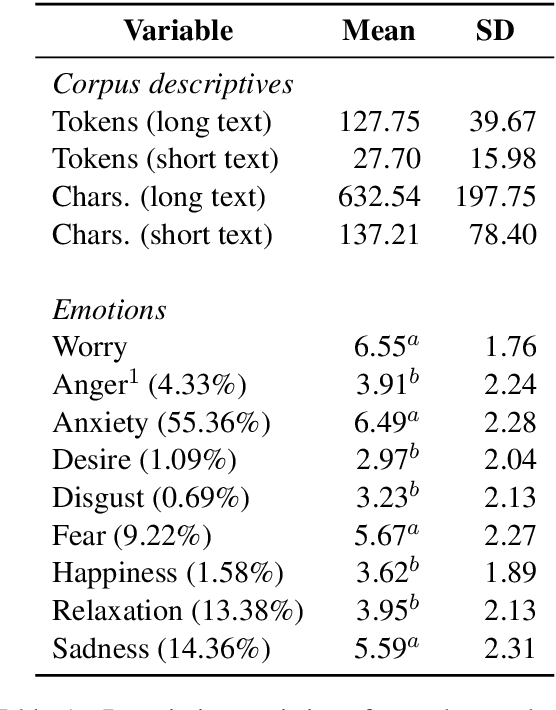
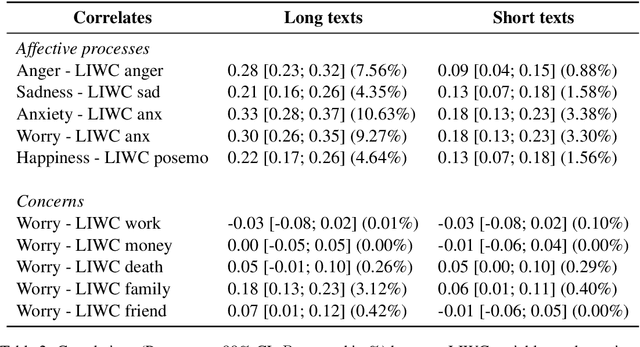

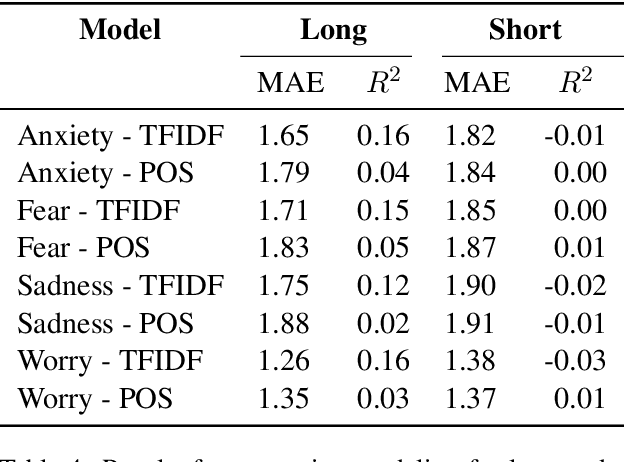
The COVID-19 pandemic is having a dramatic impact on societies and economies around the world. With various measures of lockdowns and social distancing in place, it becomes important to understand emotional responses on a large scale. In this paper, we present the first ground truth dataset of emotional responses to COVID-19. We asked participants to indicate their emotions and express these in text and created the Real World Worry Dataset of 5,000 texts (2,500 short + 2,500 long texts). Our analyses suggest that emotional responses correlated with linguistic measures. Topic modeling further revealed that people in the UK worry about their family and the economic situation. Tweet-sized texts functioned as a call for solidarity, while longer texts shed light on worries and concerns. Using predictive modeling approaches, we were able to approximate the emotional responses of participants from text within 14\% of their actual value. We encourage others to use the dataset and improve how we can use automated methods to learn about emotional responses and worries about an urgent problem.
"Thought I'd Share First": An Analysis of COVID-19 Conspiracy Theories and Misinformation Spread on Twitter
Dec 14, 2020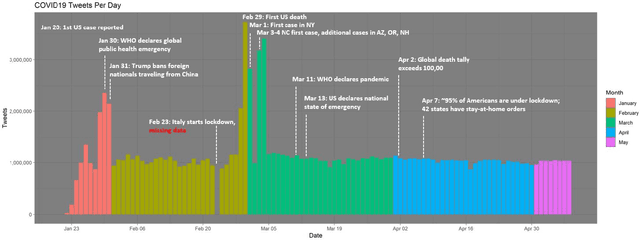
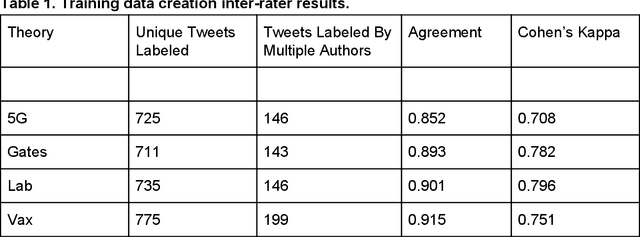
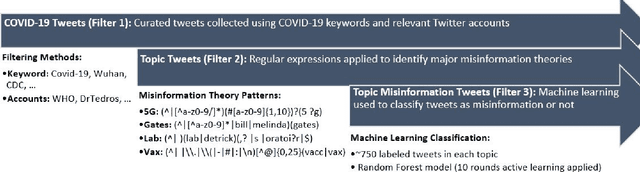
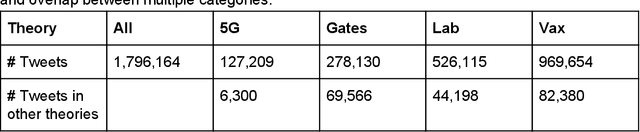
Background: Misinformation spread through social media is a growing problem, and the emergence of COVID-19 has caused an explosion in new activity and renewed focus on the resulting threat to public health. Given this increased visibility, in-depth analysis of COVID-19 misinformation spread is critical to understanding the evolution of ideas with potential negative public health impact. Methods: Using a curated data set of COVID-19 tweets (N ~120 million tweets) spanning late January to early May 2020, we applied methods including regular expression filtering, supervised machine learning, sentiment analysis, geospatial analysis, and dynamic topic modeling to trace the spread of misinformation and to characterize novel features of COVID-19 conspiracy theories. Results: Random forest models for four major misinformation topics provided mixed results, with narrowly-defined conspiracy theories achieving F1 scores of 0.804 and 0.857, while more broad theories performed measurably worse, with scores of 0.654 and 0.347. Despite this, analysis using model-labeled data was beneficial for increasing the proportion of data matching misinformation indicators. We were able to identify distinct increases in negative sentiment, theory-specific trends in geospatial spread, and the evolution of conspiracy theory topics and subtopics over time. Conclusions: COVID-19 related conspiracy theories show that history frequently repeats itself, with the same conspiracy theories being recycled for new situations. We use a combination of supervised learning, unsupervised learning, and natural language processing techniques to look at the evolution of theories over the first four months of the COVID-19 outbreak, how these theories intertwine, and to hypothesize on more effective public health messaging to combat misinformation in online spaces.
Yoga-Veganism: Correlation Mining of Twitter Health Data
Jun 15, 2019
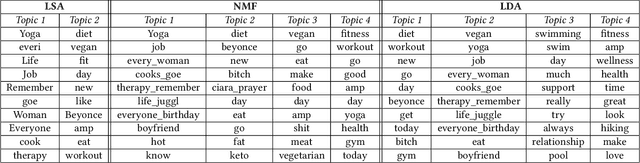
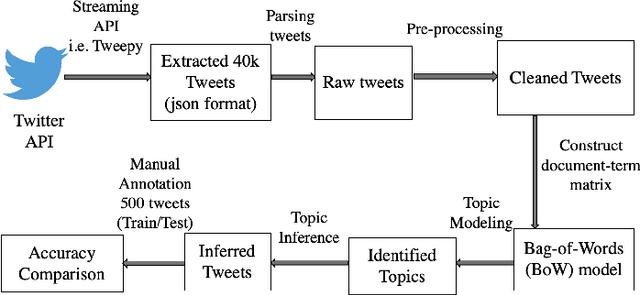
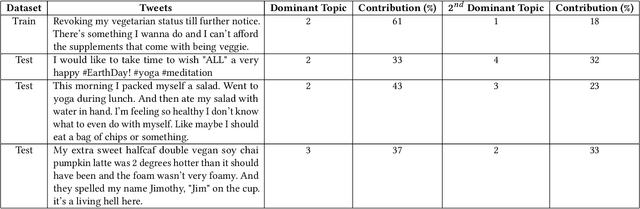
Nowadays social media is a huge platform of data. People usually share their interest, thoughts via discussions, tweets, status. It is not possible to go through all the data manually. We need to mine the data to explore hidden patterns or unknown correlations, find out the dominant topic in data and understand people's interest through the discussions. In this work, we explore Twitter data related to health. We extract the popular topics under different categories (e.g. diet, exercise) discussed in Twitter via topic modeling, observe model behavior on new tweets, discover interesting correlation (i.e. Yoga-Veganism). We evaluate accuracy by comparing with ground truth using manual annotation both for train and test data.
Multiway clustering via tensor block models
Jun 10, 2019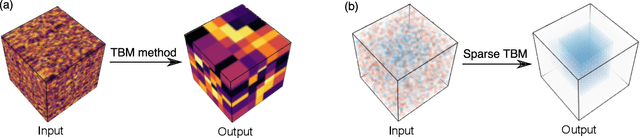
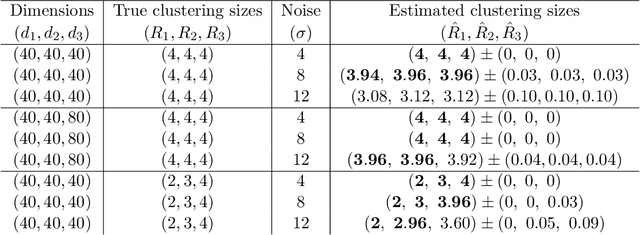
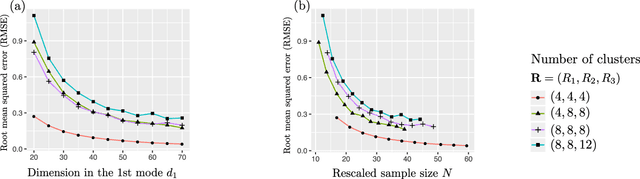

We consider the problem of identifying multiway block structure from a large noisy tensor. Such problems arise frequently in applications such as genomics, recommendation system, topic modeling, and sensor network localization. We propose a tensor block model, develop a unified least-square estimation, and obtain the theoretical accuracy guarantees for multiway clustering. The statistical convergence of the estimator is established, and we show that the associated clustering procedure achieves partition consistency. A sparse regularization is further developed for identifying important blocks with elevated means. The proposal handles a broad range of data types, including binary, continuous, and hybrid observations. Through simulation and application to two real datasets, we demonstrate the outperformance of our approach over previous methods.
Natural Language Processing via LDA Topic Model in Recommendation Systems
Sep 20, 2019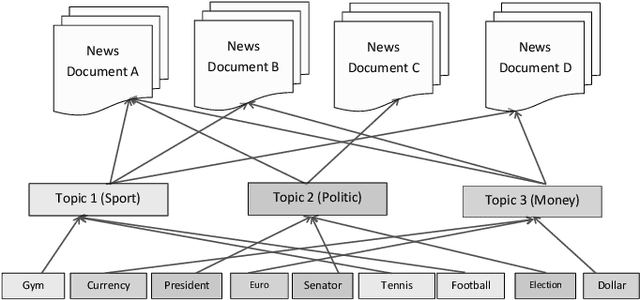
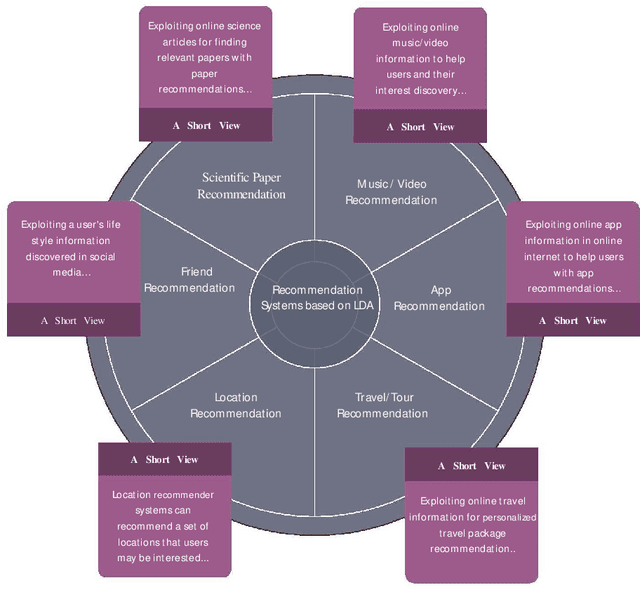
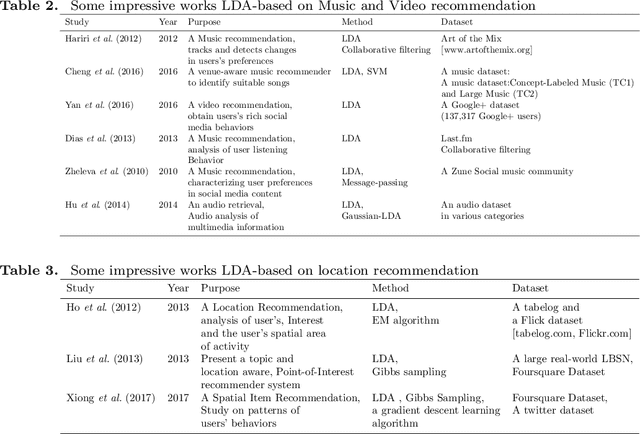
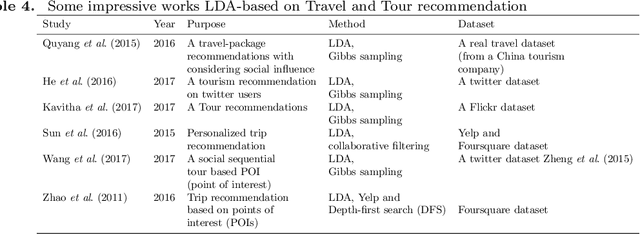
Today, Internet is one of the widest available media worldwide. Recommendation systems are increasingly being used in various applications such as movie recommendation, mobile recommendation, article recommendation and etc. Collaborative Filtering (CF) and Content-Based (CB) are Well-known techniques for building recommendation systems. Topic modeling based on LDA, is a powerful technique for semantic mining and perform topic extraction. In the past few years, many articles have been published based on LDA technique for building recommendation systems. In this paper, we present taxonomy of recommendation systems and applications based on LDA. In addition, we utilize LDA and Gibbs sampling algorithms to evaluate ISWC and WWW conference publications in computer science. Our study suggest that the recommendation systems based on LDA could be effective in building smart recommendation system in online communities.
Multi Sense Embeddings from Topic Models
Sep 17, 2019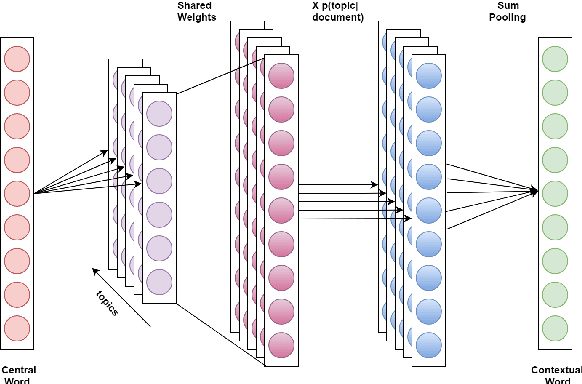
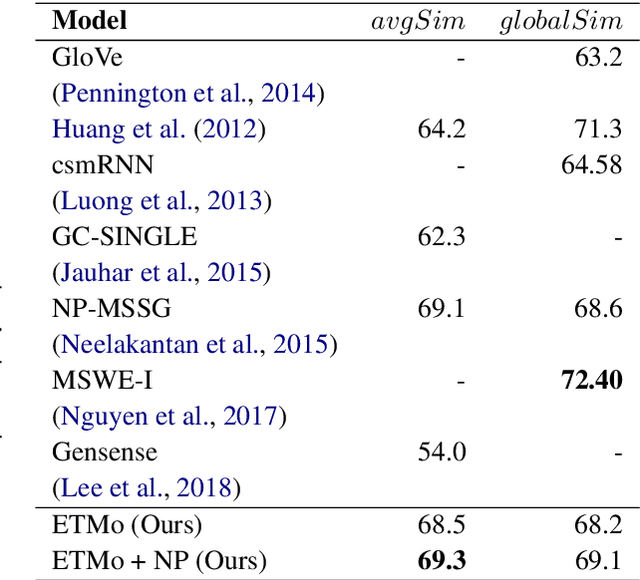
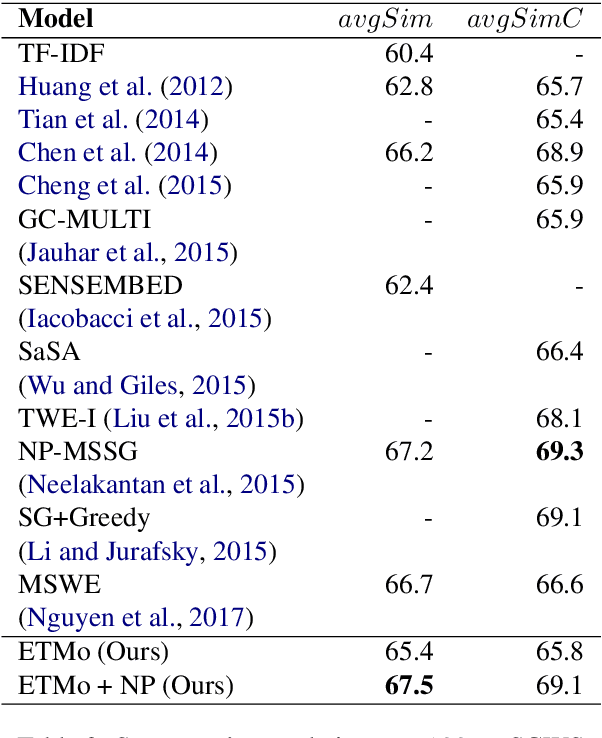

Distributed word embeddings have yielded state-of-the-art performance in many NLP tasks, mainly due to their success in capturing useful semantic information. These representations assign only a single vector to each word whereas a large number of words are polysemous (i.e., have multiple meanings). In this work, we approach this critical problem in lexical semantics, namely that of representing various senses of polysemous words in vector spaces. We propose a topic modeling based skip-gram approach for learning multi-prototype word embeddings. We also introduce a method to prune the embeddings determined by the probabilistic representation of the word in each topic. We use our embeddings to show that they can capture the context and word similarity strongly and outperform various state-of-the-art implementations.
* 8 pages, 1 figure, 7 tables