 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Surveillance of COVID-19 Pandemic using Social Media: A Reddit Study in North Carolina
Jun 09, 2021
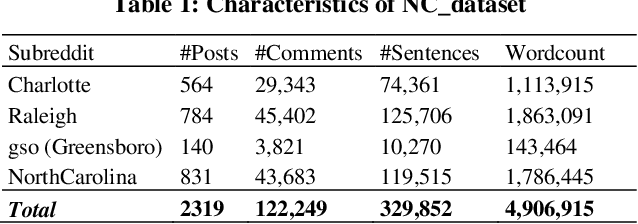
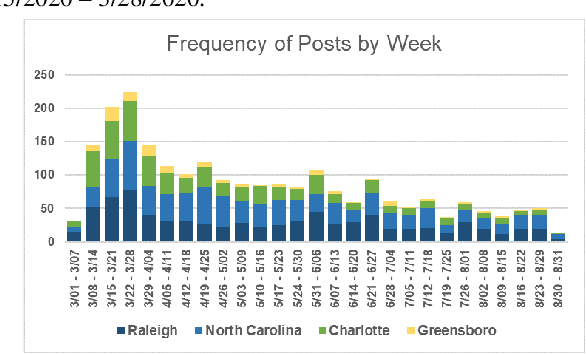
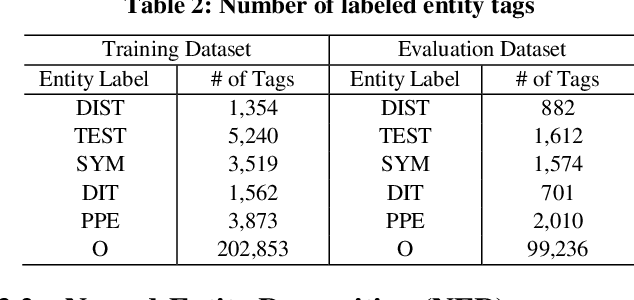
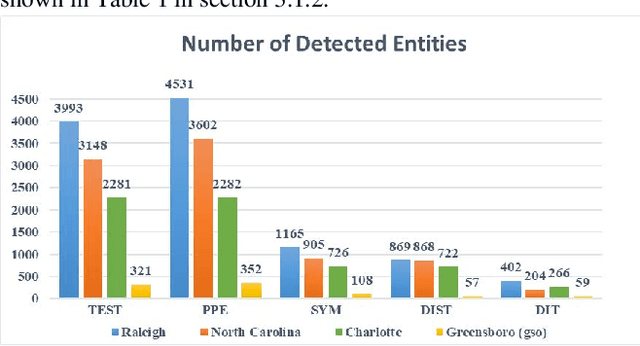
Coronavirus disease (COVID-19) pandemic has changed various aspects of people's lives and behaviors. At this stage, there are no other ways to control the natural progression of the disease than adopting mitigation strategies such as wearing masks, watching distance, and washing hands. Moreover, at this time of social distancing, social media plays a key role in connecting people and providing a platform for expressing their feelings. In this study, we tap into social media to surveil the uptake of mitigation and detection strategies, and capture issues and concerns about the pandemic. In particular, we explore the research question, "how much can be learned regarding the public uptake of mitigation strategies and concerns about COVID-19 pandemic by using natural language processing on Reddit posts?" After extracting COVID-related posts from the four largest subreddit communities of North Carolina over six months, we performed NLP-based preprocessing to clean the noisy data. We employed a custom Named-entity Recognition (NER) system and a Latent Dirichlet Allocation (LDA) method for topic modeling on a Reddit corpus. We observed that 'mask', 'flu', and 'testing' are the most prevalent named-entities for "Personal Protective Equipment", "symptoms", and "testing" categories, respectively. We also observed that the most discussed topics are related to testing, masks, and employment. The mitigation measures are the most prevalent theme of discussion across all subreddits.
Distilled Wasserstein Learning for Word Embedding and Topic Modeling
Sep 12, 2018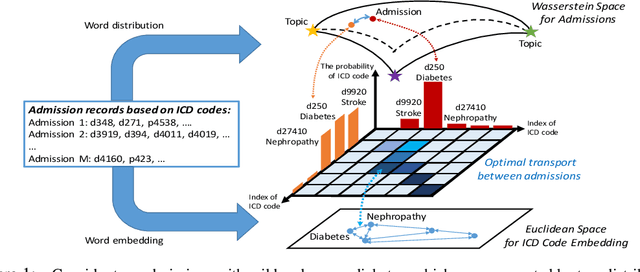
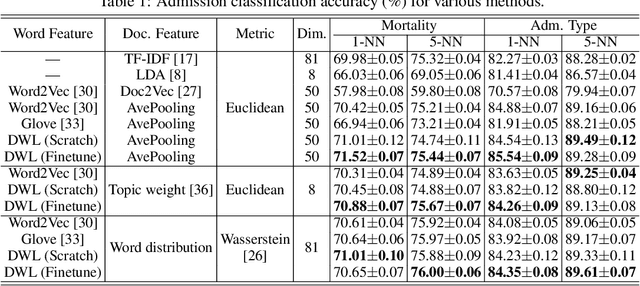
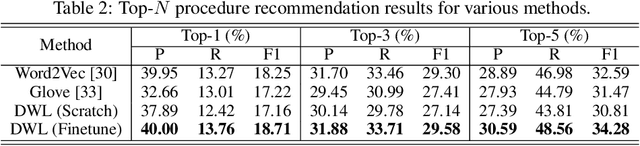
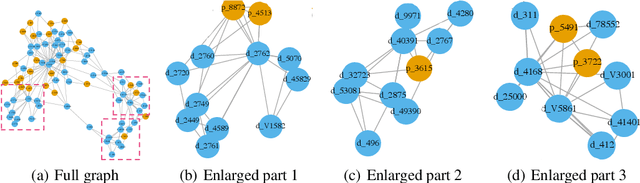
We propose a novel Wasserstein method with a distillation mechanism, yielding joint learning of word embeddings and topics. The proposed method is based on the fact that the Euclidean distance between word embeddings may be employed as the underlying distance in the Wasserstein topic model. The word distributions of topics, their optimal transports to the word distributions of documents, and the embeddings of words are learned in a unified framework. When learning the topic model, we leverage a distilled underlying distance matrix to update the topic distributions and smoothly calculate the corresponding optimal transports. Such a strategy provides the updating of word embeddings with robust guidance, improving the algorithmic convergence. As an application, we focus on patient admission records, in which the proposed method embeds the codes of diseases and procedures and learns the topics of admissions, obtaining superior performance on clinically-meaningful disease network construction, mortality prediction as a function of admission codes, and procedure recommendation.
Modeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021
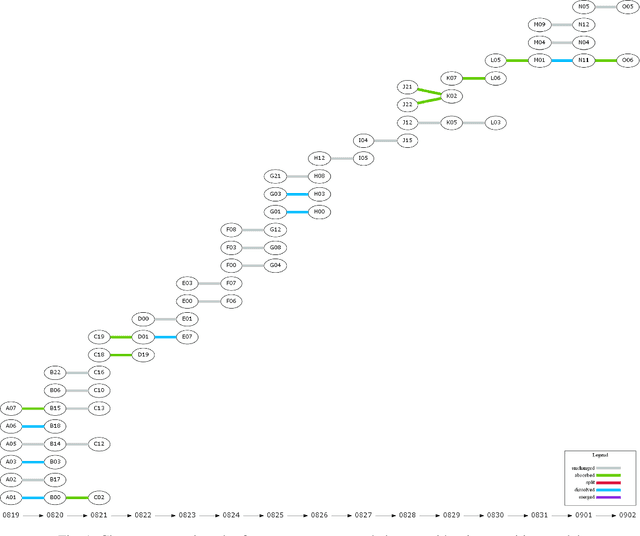

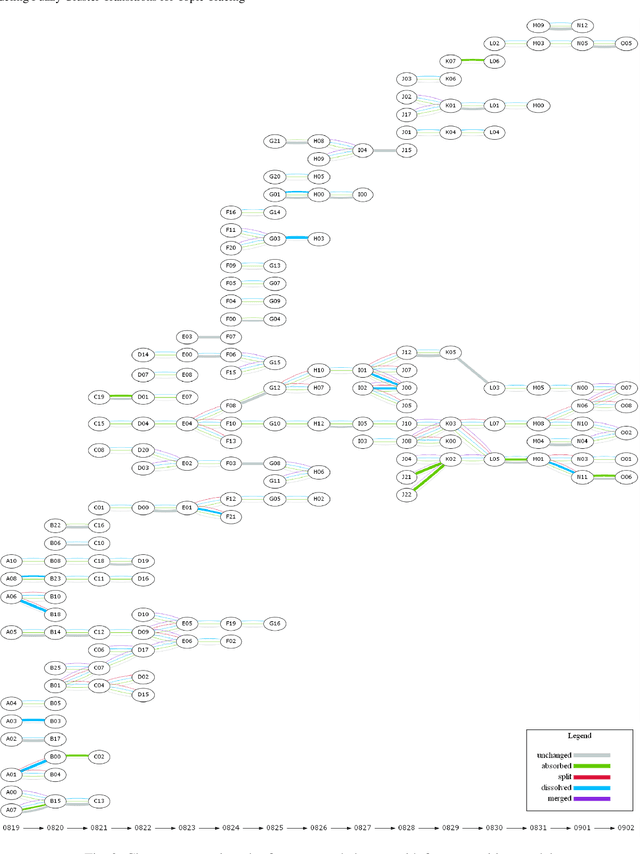
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.
Gibbs Sampling Strategies for Semantic Perception of Streaming Video Data
Sep 10, 2015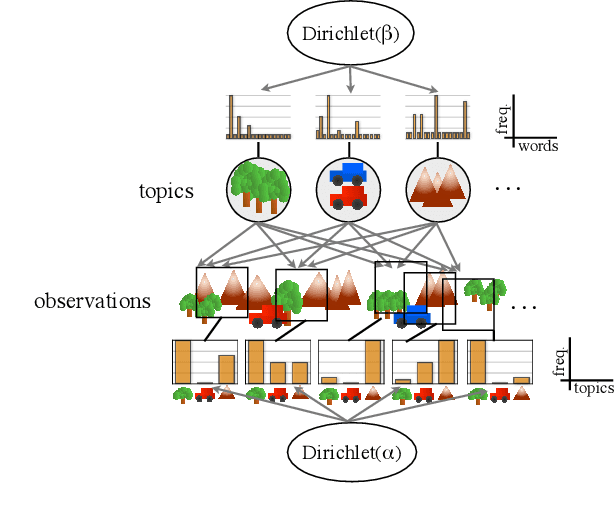
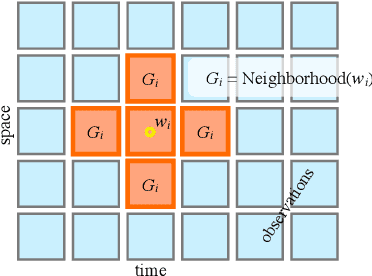
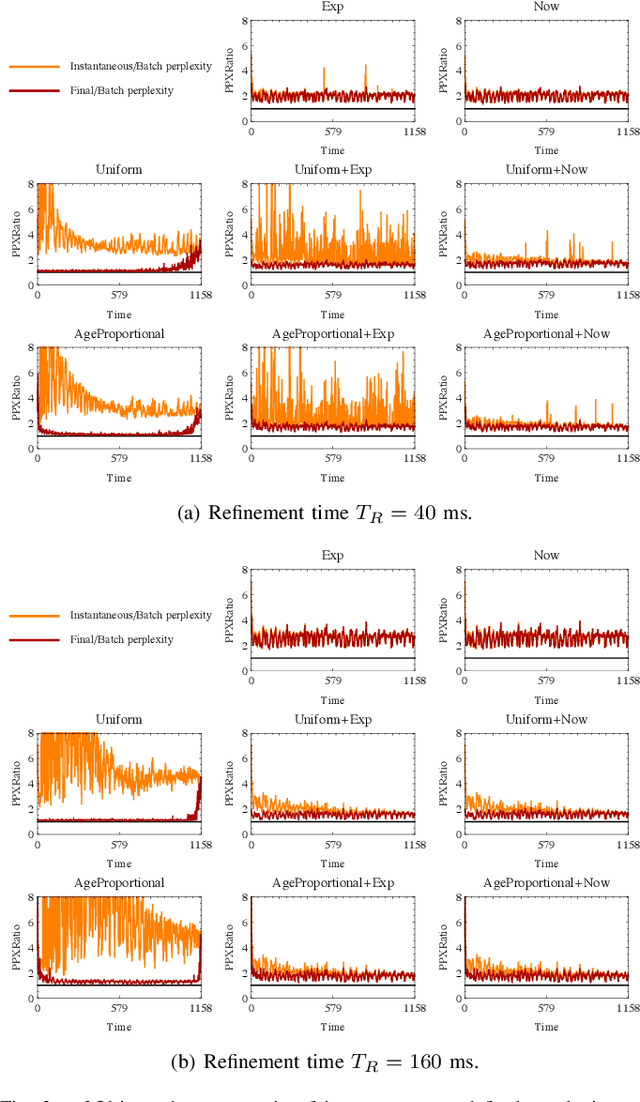
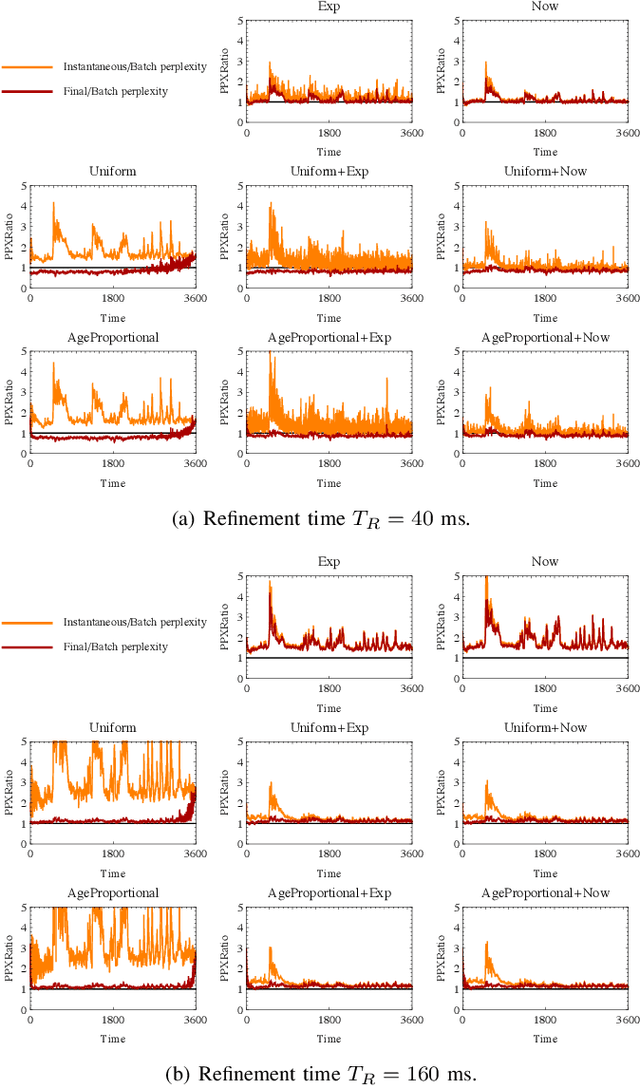
Topic modeling of streaming sensor data can be used for high level perception of the environment by a mobile robot. In this paper we compare various Gibbs sampling strategies for topic modeling of streaming spatiotemporal data, such as video captured by a mobile robot. Compared to previous work on online topic modeling, such as o-LDA and incremental LDA, we show that the proposed technique results in lower online and final perplexity, given the realtime constraints.
Towards Autoencoding Variational Inference for Aspect-based Opinion Summary
Feb 16, 2019
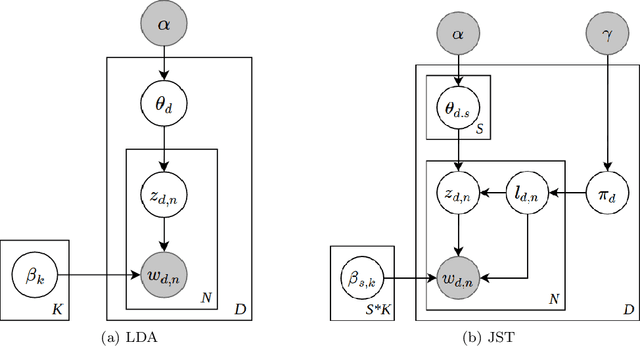
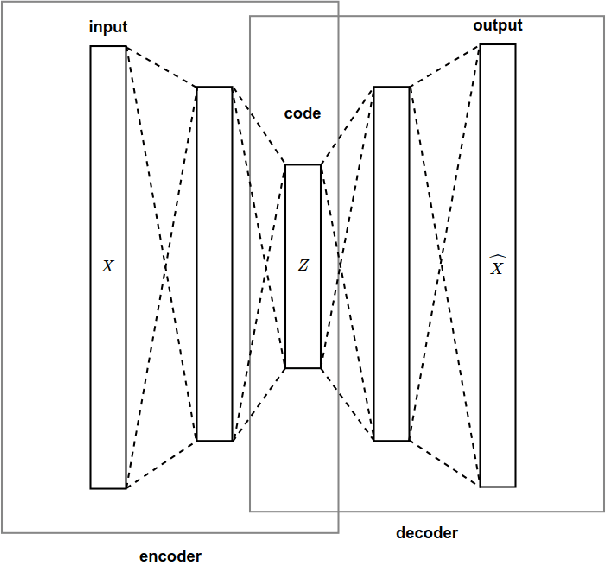

Aspect-based Opinion Summary (AOS), consisting of aspect discovery and sentiment classification steps, has recently been emerging as one of the most crucial data mining tasks in e-commerce systems. Along this direction, the LDA-based model is considered as a notably suitable approach, since this model offers both topic modeling and sentiment classification. However, unlike traditional topic modeling, in the context of aspect discovery it is often required some initial seed words, whose prior knowledge is not easy to be incorporated into LDA models. Moreover, LDA approaches rely on sampling methods, which need to load the whole corpus into memory, making them hardly scalable. In this research, we study an alternative approach for AOS problem, based on Autoencoding Variational Inference (AVI). Firstly, we introduce the Autoencoding Variational Inference for Aspect Discovery (AVIAD) model, which extends the previous work of Autoencoding Variational Inference for Topic Models (AVITM) to embed prior knowledge of seed words. This work includes enhancement of the previous AVI architecture and also modification of the loss function. Ultimately, we present the Autoencoding Variational Inference for Joint Sentiment/Topic (AVIJST) model. In this model, we substantially extend the AVI model to support the JST model, which performs topic modeling for corresponding sentiment. The experimental results show that our proposed models enjoy higher topic coherent, faster convergence time and better accuracy on sentiment classification, as compared to their LDA-based counterparts.
Multi-label Dataless Text Classification with Topic Modeling
Nov 05, 2017
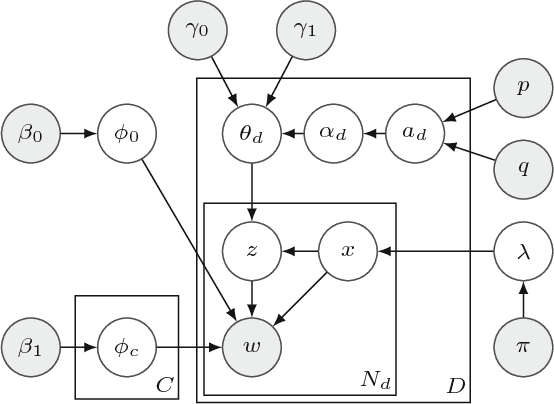

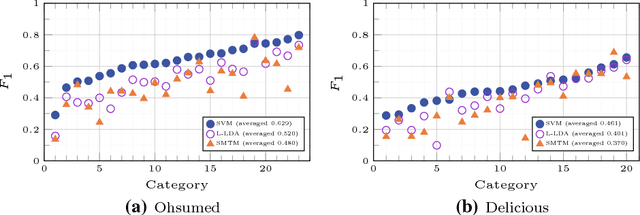
Manually labeling documents is tedious and expensive, but it is essential for training a traditional text classifier. In recent years, a few dataless text classification techniques have been proposed to address this problem. However, existing works mainly center on single-label classification problems, that is, each document is restricted to belonging to a single category. In this paper, we propose a novel Seed-guided Multi-label Topic Model, named SMTM. With a few seed words relevant to each category, SMTM conducts multi-label classification for a collection of documents without any labeled document. In SMTM, each category is associated with a single category-topic which covers the meaning of the category. To accommodate with multi-labeled documents, we explicitly model the category sparsity in SMTM by using spike and slab prior and weak smoothing prior. That is, without using any threshold tuning, SMTM automatically selects the relevant categories for each document. To incorporate the supervision of the seed words, we propose a seed-guided biased GPU (i.e., generalized Polya urn) sampling procedure to guide the topic inference of SMTM. Experiments on two public datasets show that SMTM achieves better classification accuracy than state-of-the-art alternatives and even outperforms supervised solutions in some scenarios.
Contrastive estimation reveals topic posterior information to linear models
Mar 04, 2020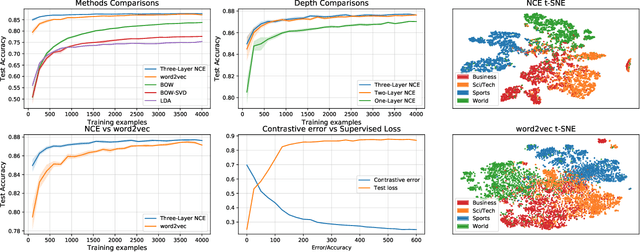
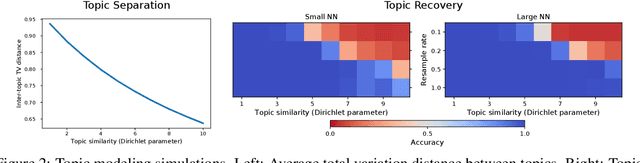
Contrastive learning is an approach to representation learning that utilizes naturally occurring similar and dissimilar pairs of data points to find useful embeddings of data. In the context of document classification under topic modeling assumptions, we prove that contrastive learning is capable of recovering a representation of documents that reveals their underlying topic posterior information to linear models. We apply this procedure in a semi-supervised setup and demonstrate empirically that linear classifiers with these representations perform well in document classification tasks with very few training examples.
Semi-Supervised Learning Approach to Discover Enterprise User Insights from Feedback and Support
Jul 22, 2020
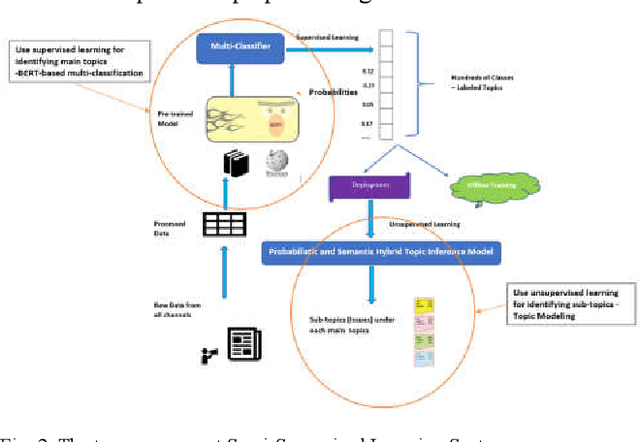
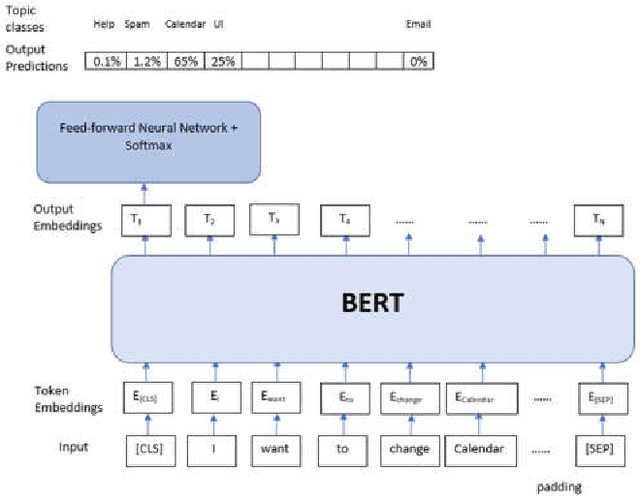
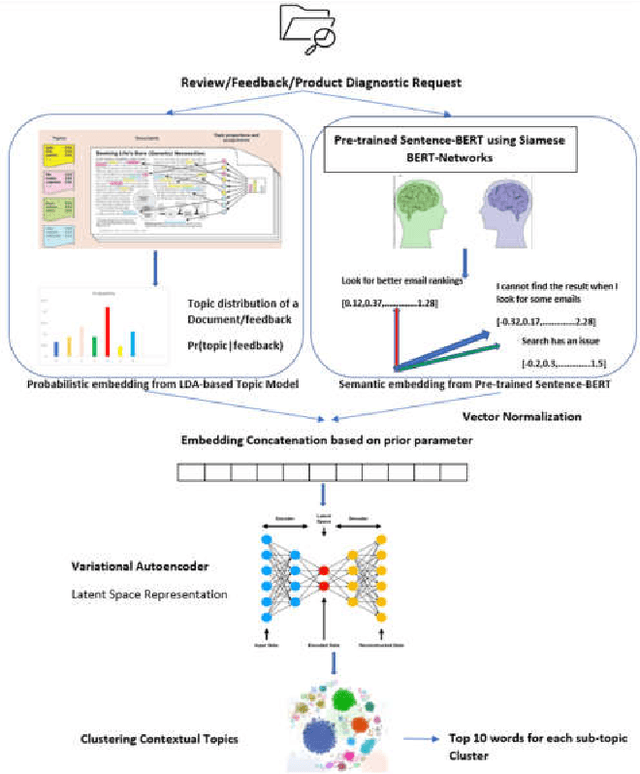
With the evolution of the cloud and customer centric culture, we inherently accumulate huge repositories of textual reviews, feedback, and support data.This has driven enterprises to seek and research engagement patterns, user network analysis, topic detections, etc.However, huge manual work is still necessary to mine data to be able to mine actionable outcomes. In this paper, we proposed and developed an innovative Semi-Supervised Learning approach by utilizing Deep Learning and Topic Modeling to have a better understanding of the user voice.This approach combines a BERT-based multiclassification algorithm through supervised learning combined with a novel Probabilistic and Semantic Hybrid Topic Inference (PSHTI) Model through unsupervised learning, aiming at automating the process of better identifying the main topics or areas as well as the sub-topics from the textual feedback and support.There are three major break-through: 1. As the advancement of deep learning technology, there have been tremendous innovations in the NLP field, yet the traditional topic modeling as one of the NLP applications lag behind the tide of deep learning. In the methodology and technical perspective, we adopt transfer learning to fine-tune a BERT-based multiclassification system to categorize the main topics and then utilize the novel PSHTI model to infer the sub-topics under the predicted main topics. 2. The traditional unsupervised learning-based topic models or clustering methods suffer from the difficulty of automatically generating a meaningful topic label, but our system enables mapping the top words to the self-help issues by utilizing domain knowledge about the product through web-crawling. 3. This work provides a prominent showcase by leveraging the state-of-the-art methodology in the real production to help shed light to discover user insights and drive business investment priorities.