 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coalitional Bargaining via Reinforcement Learning: An Application to Collaborative Vehicle Routing
Oct 26, 2023
Collaborative Vehicle Routing is where delivery companies cooperate by sharing their delivery information and performing delivery requests on behalf of each other. This achieves economies of scale and thus reduces cost, greenhouse gas emissions, and road congestion. But which company should partner with whom, and how much should each company be compensated? Traditional game theoretic solution concepts, such as the Shapley value or nucleolus, are difficult to calculate for the real-world problem of Collaborative Vehicle Routing due to the characteristic function scaling exponentially with the number of agents. This would require solving the Vehicle Routing Problem (an NP-Hard problem) an exponential number of times. We therefore propose to model this problem as a coalitional bargaining game where - crucially - agents are not given access to the characteristic function. Instead, we implicitly reason about the characteristic function, and thus eliminate the need to evaluate the VRP an exponential number of times - we only need to evaluate it once. Our contribution is that our decentralised approach is both scalable and considers the self-interested nature of companies. The agents learn using a modified Independent Proximal Policy Optimisation. Our RL agents outperform a strong heuristic bot. The agents correctly identify the optimal coalitions 79% of the time with an average optimality gap of 4.2% and reduction in run-time of 62%.
On the accuracy and efficiency of group-wise clipping in differentially private optimization
Oct 30, 2023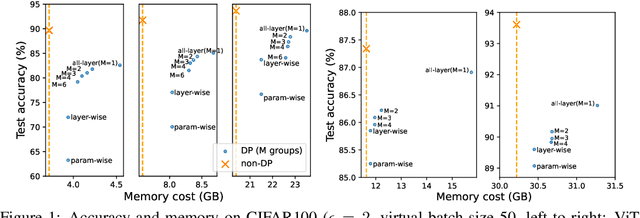
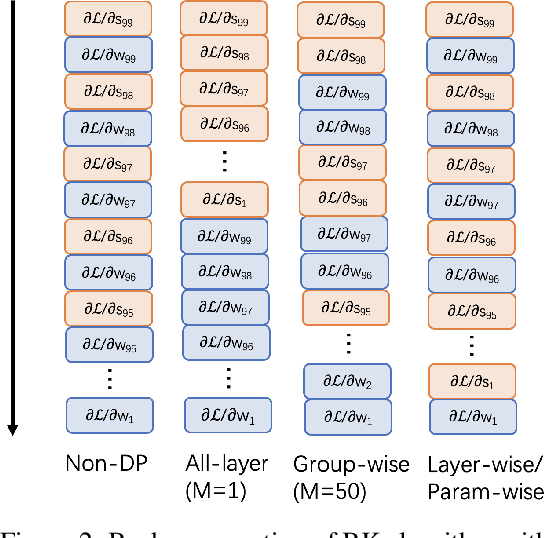
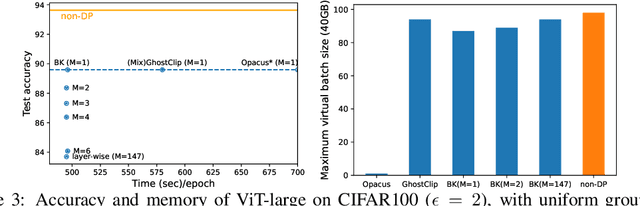
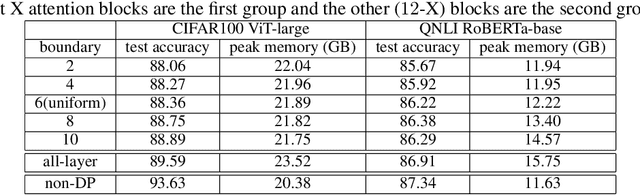
Recent advances have substantially improved the accuracy, memory cost, and training speed of differentially private (DP) deep learning, especially on large vision and language models with millions to billions of parameters. In this work, we thoroughly study the per-sample gradient clipping style, a key component in DP optimization. We show that different clipping styles have the same time complexity but instantiate an accuracy-memory trade-off: while the all-layer clipping (of coarse granularity) is the most prevalent and usually gives the best accuracy, it incurs heavier memory cost compared to other group-wise clipping, such as the layer-wise clipping (of finer granularity). We formalize this trade-off through our convergence theory and complexity analysis. Importantly, we demonstrate that the accuracy gap between group-wise clipping and all-layer clipping becomes smaller for larger models, while the memory advantage of the group-wise clipping remains. Consequently, the group-wise clipping allows DP optimization of large models to achieve high accuracy and low peak memory simultaneously.
On Measuring Fairness in Generative Models
Oct 30, 2023Recently, there has been increased interest in fair generative models. In this work, we conduct, for the first time, an in-depth study on fairness measurement, a critical component in gauging progress on fair generative models. We make three contributions. First, we conduct a study that reveals that the existing fairness measurement framework has considerable measurement errors, even when highly accurate sensitive attribute (SA) classifiers are used. These findings cast doubts on previously reported fairness improvements. Second, to address this issue, we propose CLassifier Error-Aware Measurement (CLEAM), a new framework which uses a statistical model to account for inaccuracies in SA classifiers. Our proposed CLEAM reduces measurement errors significantly, e.g., 4.98% $\rightarrow$ 0.62% for StyleGAN2 w.r.t. Gender. Additionally, CLEAM achieves this with minimal additional overhead. Third, we utilize CLEAM to measure fairness in important text-to-image generator and GANs, revealing considerable biases in these models that raise concerns about their applications. Code and more resources: https://sutd-visual-computing-group.github.io/CLEAM/.
Lyapunov-Based Dropout Deep Neural Network (Lb-DDNN) Controller
Oct 30, 2023Deep neural network (DNN)-based adaptive controllers can be used to compensate for unstructured uncertainties in nonlinear dynamic systems. However, DNNs are also very susceptible to overfitting and co-adaptation. Dropout regularization is an approach where nodes are randomly dropped during training to alleviate issues such as overfitting and co-adaptation. In this paper, a dropout DNN-based adaptive controller is developed. The developed dropout technique allows the deactivation of weights that are stochastically selected for each individual layer within the DNN. Simultaneously, a Lyapunov-based real-time weight adaptation law is introduced to update the weights of all layers of the DNN for online unsupervised learning. A non-smooth Lyapunov-based stability analysis is performed to ensure asymptotic convergence of the tracking error. Simulation results of the developed dropout DNN-based adaptive controller indicate a 38.32% improvement in the tracking error, a 53.67% improvement in the function approximation error, and 50.44% lower control effort when compared to a baseline adaptive DNN-based controller without dropout regularization.
Scenario-Aware Audio-Visual TF-GridNet for Target Speech Extraction
Oct 30, 2023Target speech extraction aims to extract, based on a given conditioning cue, a target speech signal that is corrupted by interfering sources, such as noise or competing speakers. Building upon the achievements of the state-of-the-art (SOTA) time-frequency speaker separation model TF-GridNet, we propose AV-GridNet, a visual-grounded variant that incorporates the face recording of a target speaker as a conditioning factor during the extraction process. Recognizing the inherent dissimilarities between speech and noise signals as interfering sources, we also propose SAV-GridNet, a scenario-aware model that identifies the type of interfering scenario first and then applies a dedicated expert model trained specifically for that scenario. Our proposed model achieves SOTA results on the second COG-MHEAR Audio-Visual Speech Enhancement Challenge, outperforming other models by a significant margin, objectively and in a listening test. We also perform an extensive analysis of the results under the two scenarios.
A spectral regularisation framework for latent variable models designed for single channel applications
Oct 30, 2023Latent variable models (LVMs) are commonly used to capture the underlying dependencies, patterns, and hidden structure in observed data. Source duplication is a by-product of the data hankelisation pre-processing step common to single channel LVM applications, which hinders practical LVM utilisation. In this article, a Python package titled spectrally-regularised-LVMs is presented. The proposed package addresses the source duplication issue via the addition of a novel spectral regularisation term. This package provides a framework for spectral regularisation in single channel LVM applications, thereby making it easier to investigate and utilise LVMs with spectral regularisation. This is achieved via the use of symbolic or explicit representations of potential LVM objective functions which are incorporated into a framework that uses spectral regularisation during the LVM parameter estimation process. The objective of this package is to provide a consistent linear LVM optimisation framework which incorporates spectral regularisation and caters to single channel time-series applications.
A Synopsis of Stent Graft Technology Development
Oct 30, 2023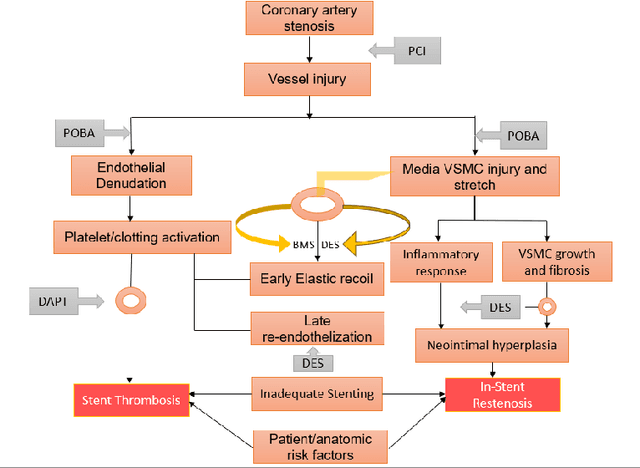
Coronary artery disease (CAD) is a leading cause of death worldwide. Treatments have evolved, with stenting becoming the primary approach over bypass surgery. This article reviews the evolution of coronary stent technology, starting from the first angioplasty in 1977. Pioneers like Forssmann, Dotter, and Gruentzig established the foundation. The late 1980s saw the introduction of bare metal stents (BMS) to address angioplasty limitations. However, BMS had issues, leading to the development of first-generation drug-eluting stents (DES) in the early 2000s, which reduced restenosis but had safety concerns. Subsequent innovations introduced second-generation DES with better results and the latest bioresorbable vascular scaffolds (BVS) that dissolve over time. Clinical trials have been crucial in validating each stent's effectiveness. Despite progress, challenges remain in stent selection, approval processes, and minimizing risks. The future may see personalized stenting based on patient needs, highlighting the significant advancements in stent technology and its impact on patient care.
NeuroSMPC: A Neural Network guided Sampling Based MPC for On-Road Autonomous Driving
Oct 19, 2023In this paper we show an effective means of integrating data driven frameworks to sampling based optimal control to vastly reduce the compute time for easy adoption and adaptation to real time applications such as on-road autonomous driving in the presence of dynamic actors. Presented with training examples, a spatio-temporal CNN learns to predict the optimal mean control over a finite horizon that precludes further resampling, an iterative process that makes sampling based optimal control formulations difficult to adopt in real time settings. Generating control samples around the network-predicted optimal mean retains the advantage of sample diversity while enabling real time rollout of trajectories that avoids multiple dynamic obstacles in an on-road navigation setting. Further the 3D CNN architecture implicitly learns the future trajectories of the dynamic agents in the scene resulting in successful collision free navigation despite no explicit future trajectory prediction. We show performance gain over multiple baselines in a number of on-road scenes through closed loop simulations in CARLA. We also showcase the real world applicability of our system by running it on our custom Autonomous Driving Platform (AutoDP).
Kinematics-Based Sensor Fault Detection for Autonomous Vehicles Using Real-Time Numerical Differentiation
Sep 10, 2023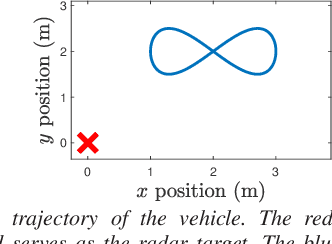
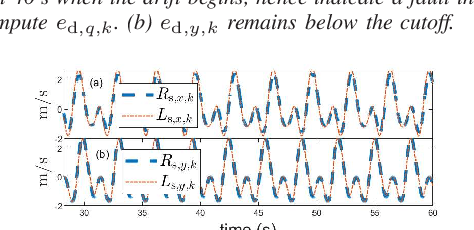
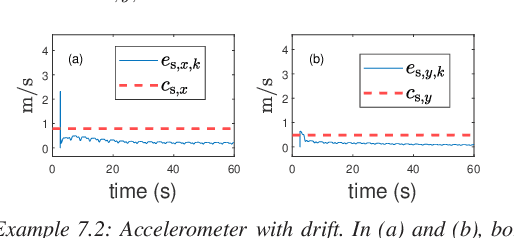
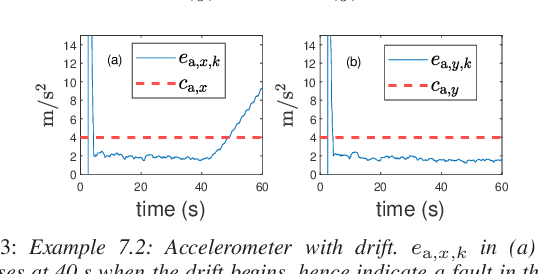
Sensor fault detection is of extreme importance for ensuring the safe operation of vehicles. This paper introduces a novel approach to detecting and identifying faulty sensors. For ground vehicles confined to the horizontal plane, this technique is based on six kinematics-based error metrics that are computed in real time by using onboard sensor data encompassing compass, radar, rate gyro, and accelerometer measurements as well as their derivatives. Real-time numerical differentiation is performed by applying the adaptive input and state estimation (AIE/ASE) algorithm. Numerical examples are provided to assess the efficacy of the proposed methodology.
Sea-Land-Cloud Segmentation in Satellite Hyperspectral Imagery by Deep Learning
Oct 24, 2023Satellites are increasingly adopting on-board Artificial Intelligence (AI) techniques to enhance platforms' autonomy through edge inference. In this context, the utilization of deep learning (DL) techniques for segmentation in HS satellite imagery offers advantages for remote sensing applications, and therefore, we train 16 different models, whose codes are made available through our study, which we consider to be relevant for on-board multi-class segmentation of HS imagery, focusing on classifying oceanic (sea), terrestrial (land), and cloud formations. We employ the HYPSO-1 mission as an illustrative case for sea-land-cloud segmentation, and to demonstrate the utility of the segments, we introduce a novel sea-land-cloud ranking application scenario. Our system prioritizes HS image downlink based on sea, land, and cloud coverage levels from the segmented images. We comparatively evaluate the models for in-orbit deployment, considering performance, parameter count, and inference time. The models include both shallow and deep models, and after we propose four new DL models, we demonstrate that segmenting single spectral signatures (1D) outperforms 3D data processing comprising both spectral (1D) and spatial (2D) contexts. We conclude that our lightweight DL model, called 1D-Justo-LiuNet, consistently surpasses state-of-the-art models for sea-land-cloud segmentation, such as U-Net and its variations, in terms of performance (0.93 accuracy) and parameter count (4,563). However, the 1D models present longer inference time (15s) in the tested processing architecture, which is clearly suboptimal. Finally, after demonstrating that in-orbit image segmentation should occur post L1b radiance calibration rather than on raw data, we additionally show that reducing spectral channels down to 3 lowers models' parameters and inference time, at the cost of weaker segmentation performance.