 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Step Gaussian Process Propagation for Adaptive Path Planning
Apr 21, 2026Efficient and robust path planning hinges on combining all accessible information sources. In particular, the task of path planning for robotic environmental exploration and monitoring depends highly on the current belief of the world. To capture the uncertainty in the belief, we present a Gaussian process based path planning method that adapts to multi-modal environmental sensing data and incorporates state and input constraints. To solve the path planning problem, we optimize over future waypoints in a receding horizon fashion, and our cost is thus a function of the Gaussian process posterior over all these waypoints. We demonstrate this method, dubbed OLAhGP, on an autonomous surface vessel using oceanic algal bloom data from both a high-fidelity model and in-situ sensing data in a monitoring scenario. Our simulated and experimental results demonstrate significant improvement over existing methods. With the same number of samples, our method generates more informative paths and achieves greater accuracy in identifying algal blooms in chlorophyll a rich waters, measured with respect to total misclassification probability and binary misclassification rate over the domain of interest.
Airborne Magnetic Anomaly Navigation with Neural-Network-Augmented Online Calibration
Mar 09, 2026Airborne Magnetic Anomaly Navigation (MagNav) provides a jamming-resistant and robust alternative to satellite navigation but requires the real-time compensation of the aircraft platform's large and dynamic magnetic interference. State-of-the-art solutions often rely on extensive offline calibration flights or pre-training, creating a logistical barrier to operational deployment. We present a fully adaptive MagNav architecture featuring a "cold-start" capability that identifies and compensates for the aircraft's magnetic signature entirely in-flight. The proposed method utilizes an extended Kalman filter with an augmented state vector that simultaneously estimates the aircraft's kinematic states as well as the coefficients of the physics-based Tolles-Lawson calibration model and the parameters of a Neural Network to model aircraft interferences. The Kalman filter update is mathematically equivalent to an online Natural Gradient descent, integrating superior convergence and data efficiency of state-of-the-art second-order optimization directly into the navigation filter. To enhance operational robustness, the neural network is constrained to a residual learning role, modeling only the nonlinearities uncorrected by the explainable physics-based calibration baseline. Validated on the MagNav Challenge dataset, our framework effectively bounds inertial drift using a magnetometer-only feature set. The results demonstrate navigation accuracy comparable to state-of-the-art models trained offline, without requiring prior calibration flights or dedicated maneuvers.
Bluetooth Phased-array Aided Inertial Navigation Using Factor Graphs: Experimental Verification
Feb 19, 2026Phased-array Bluetooth systems have emerged as a low-cost alternative for performing aided inertial navigation in GNSS-denied use cases such as warehouse logistics, drone landings, and autonomous docking. Basing a navigation system off of commercial-off-the-shelf components may reduce the barrier of entry for phased-array radio navigation systems, albeit at the cost of significantly noisier measurements and relatively short feasible range. In this paper, we compare robust estimation strategies for a factor graph optimisation-based estimator using experimental data collected from multirotor drone flight. We evaluate performance in loss-of-GNSS scenarios when aided by Bluetooth angular measurements, as well as range or barometric pressure.
Design and Validation of an Intention-Aware Probabilistic Framework for Trajectory Prediction: Integrating COLREGS, Grounding Hazards, and Planned Routes
Apr 01, 2025



Collision avoidance capability is an essential component in an autonomous vessel navigation system. To this end, an accurate prediction of dynamic obstacle trajectories is vital. Traditional approaches to trajectory prediction face limitations in generalizability and often fail to account for the intentions of other vessels. While recent research has considered incorporating the intentions of dynamic obstacles, these efforts are typically based on the own-ship's interpretation of the situation. The current state-of-the-art in this area is a Dynamic Bayesian Network (DBN) model, which infers target vessel intentions by considering multiple underlying causes and allowing for different interpretations of the situation by different vessels. However, since its inception, there have not been any significant structural improvements to this model. In this paper, we propose enhancing the DBN model by incorporating considerations for grounding hazards and vessel waypoint information. The proposed model is validated using real vessel encounters extracted from historical Automatic Identification System (AIS) data.
Deep Learning for In-Orbit Cloud Segmentation and Classification in Hyperspectral Satellite Data
Mar 13, 2024



This article explores the latest Convolutional Neural Networks (CNNs) for cloud detection aboard hyperspectral satellites. The performance of the latest 1D CNN (1D-Justo-LiuNet) and two recent 2D CNNs (nnU-net and 2D-Justo-UNet-Simple) for cloud segmentation and classification is assessed. Evaluation criteria include precision and computational efficiency for in-orbit deployment. Experiments utilize NASA's EO-1 Hyperion data, with varying spectral channel numbers after Principal Component Analysis. Results indicate that 1D-Justo-LiuNet achieves the highest accuracy, outperforming 2D CNNs, while maintaining compactness with larger spectral channel sets, albeit with increased inference times. However, the performance of 1D CNN degrades with significant channel reduction. In this context, the 2D-Justo-UNet-Simple offers the best balance for in-orbit deployment, considering precision, memory, and time costs. While nnU-net is suitable for on-ground processing, deployment of lightweight 1D-Justo-LiuNet is recommended for high-precision applications. Alternatively, lightweight 2D-Justo-UNet-Simple is recommended for balanced costs between timing and precision in orbit.
A Comparative Study of Rapidly-exploring Random Tree Algorithms Applied to Ship Trajectory Planning and Behavior Generation
Mar 02, 2024



Rapidly Exploring Random Tree (RRT) algorithms are popular for sampling-based planning for nonholonomic vehicles in unstructured environments. However, we argue that previous work does not illuminate the challenges when employing such algorithms. Thus, in this article, we do a first comparison study of the performance of the following previously proposed RRT algorithm variants; Potential-Quick RRT* (PQ-RRT*), Informed RRT* (IRRT*), RRT* and RRT, for single-query nonholonomic motion planning over several cases in the unstructured maritime environment. The practicalities of employing such algorithms in the maritime domain are also discussed. On the side, we contend that these algorithms offer value not only for Collision Avoidance Systems (CAS) trajectory planning, but also for the verification of CAS through vessel behavior generation. Naturally, optimal RRT variants yield more distance-optimal paths at the cost of increased computational time due to the tree wiring process with nearest neighbor consideration. PQ-RRT* achieves marginally better results than IRRT* and RRT*, at the cost of higher tuning complexity and increased wiring time. Based on the results, we argue that for time-critical applications the considered RRT algorithms are, as stand-alone planners, more suitable for use in smaller problems or problems with low obstacle congestion ratio. This is attributed to the curse of dimensionality, and trade-off with available memory and computational resources.
Quick unsupervised hyperspectral dimensionality reduction for earth observation: a comparison
Feb 26, 2024



Dimensionality reduction can be applied to hyperspectral images so that the most useful data can be extracted and processed more quickly. This is critical in any situation in which data volume exceeds the capacity of the computational resources, particularly in the case of remote sensing platforms (e.g., drones, satellites), but also in the case of multi-year datasets. Moreover, the computational strategies of unsupervised dimensionality reduction often provide the basis for more complicated supervised techniques. Seven unsupervised dimensionality reduction algorithms are tested on hyperspectral data from the HYPSO-1 earth observation satellite. Each particular algorithm is chosen to be representative of a broader collection. The experiments probe the computational complexity, reconstruction accuracy, signal clarity, sensitivity to artifacts, and effects on target detection and classification of the different algorithms. No algorithm consistently outperformed the others across all tests, but some general trends regarding the characteristics of the algorithms did emerge. With half a million pixels, computational time requirements of the methods varied by 5 orders of magnitude, and the reconstruction error varied by about 3 orders of magnitude. A relationship between mutual information and artifact susceptibility was suggested by the tests. The relative performance of the algorithms differed significantly between the target detection and classification tests. Overall, these experiments both show the power of dimensionality reduction and give guidance regarding how to evaluate a technique prior to incorporating it into a processing pipeline.
A Comparative Study of Compressive Sensing Algorithms for Hyperspectral Imaging Reconstruction
Jan 26, 2024

Hyperspectral Imaging comprises excessive data consequently leading to significant challenges for data processing, storage and transmission. Compressive Sensing has been used in the field of Hyperspectral Imaging as a technique to compress the large amount of data. This work addresses the recovery of hyperspectral images 2.5x compressed. A comparative study in terms of the accuracy and the performance of the convex FISTA/ADMM in addition to the greedy gOMP/BIHT/CoSaMP recovery algorithms is presented. The results indicate that the algorithms recover successfully the compressed data, yet the gOMP algorithm achieves superior accuracy and faster recovery in comparison to the other algorithms at the expense of high dependence on unknown sparsity level of the data to recover.
Sea-Land-Cloud Segmentation in Satellite Hyperspectral Imagery by Deep Learning
Oct 24, 2023



Satellites are increasingly adopting on-board Artificial Intelligence (AI) techniques to enhance platforms' autonomy through edge inference. In this context, the utilization of deep learning (DL) techniques for segmentation in HS satellite imagery offers advantages for remote sensing applications, and therefore, we train 16 different models, whose codes are made available through our study, which we consider to be relevant for on-board multi-class segmentation of HS imagery, focusing on classifying oceanic (sea), terrestrial (land), and cloud formations. We employ the HYPSO-1 mission as an illustrative case for sea-land-cloud segmentation, and to demonstrate the utility of the segments, we introduce a novel sea-land-cloud ranking application scenario. Our system prioritizes HS image downlink based on sea, land, and cloud coverage levels from the segmented images. We comparatively evaluate the models for in-orbit deployment, considering performance, parameter count, and inference time. The models include both shallow and deep models, and after we propose four new DL models, we demonstrate that segmenting single spectral signatures (1D) outperforms 3D data processing comprising both spectral (1D) and spatial (2D) contexts. We conclude that our lightweight DL model, called 1D-Justo-LiuNet, consistently surpasses state-of-the-art models for sea-land-cloud segmentation, such as U-Net and its variations, in terms of performance (0.93 accuracy) and parameter count (4,563). However, the 1D models present longer inference time (15s) in the tested processing architecture, which is clearly suboptimal. Finally, after demonstrating that in-orbit image segmentation should occur post L1b radiance calibration rather than on raw data, we additionally show that reducing spectral channels down to 3 lowers models' parameters and inference time, at the cost of weaker segmentation performance.
Data-Efficient Deep Reinforcement Learning for Attitude Control of Fixed-Wing UAVs: Field Experiments
Nov 07, 2021
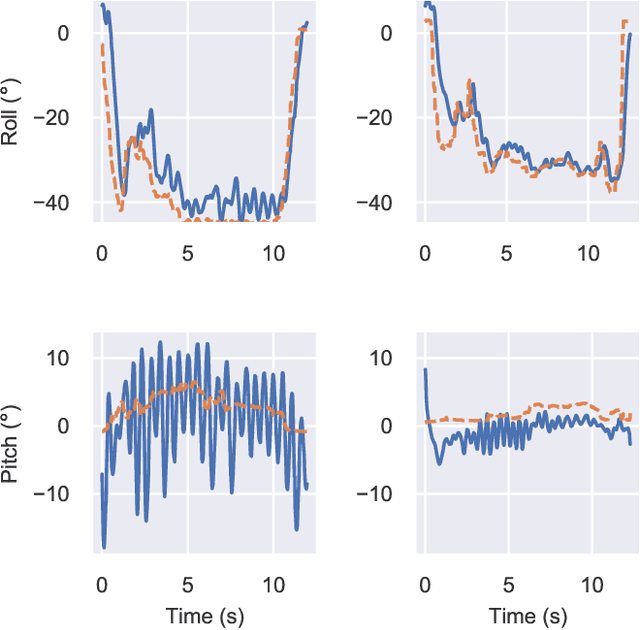
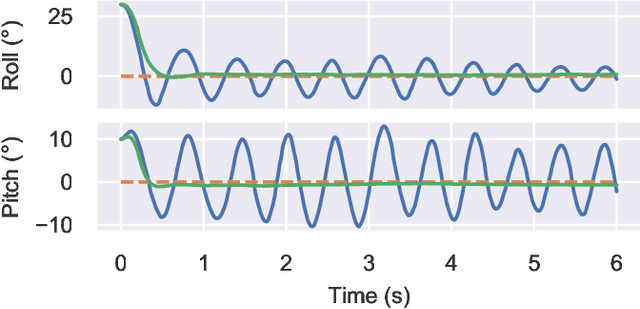
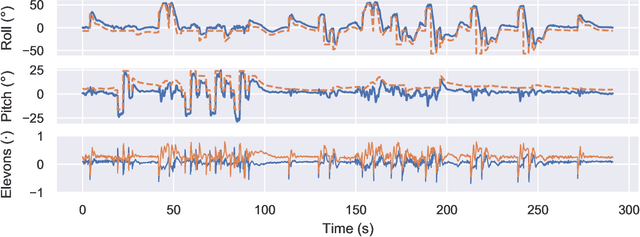
Attitude control of fixed-wing unmanned aerial vehicles (UAVs)is a difficult control problem in part due to uncertain nonlinear dynamics, actuator constraints, and coupled longitudinal and lateral motions. Current state-of-the-art autopilots are based on linear control and are thus limited in their effectiveness and performance. Deep reinforcement learning (DRL) is a machine learning method to automatically discover optimal control laws through interaction with the controlled system, that can handle complex nonlinear dynamics. We show in this paper that DRL can successfully learn to perform attitude control of a fixed-wing UAV operating directly on the original nonlinear dynamics, requiring as little as three minutes of flight data. We initially train our model in a simulation environment and then deploy the learned controller on the UAV in flight tests, demonstrating comparable performance to the state-of-the-art ArduPlaneproportional-integral-derivative (PID) attitude controller with no further online learning required. To better understand the operation of the learned controller we present an analysis of its behaviour, including a comparison to the existing well-tuned PID controller.