 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transfer learning from a sparsely annotated dataset of 3D medical images
Nov 08, 2023
Transfer learning leverages pre-trained model features from a large dataset to save time and resources when training new models for various tasks, potentially enhancing performance. Due to the lack of large datasets in the medical imaging domain, transfer learning from one medical imaging model to other medical imaging models has not been widely explored. This study explores the use of transfer learning to improve the performance of deep convolutional neural networks for organ segmentation in medical imaging. A base segmentation model (3D U-Net) was trained on a large and sparsely annotated dataset; its weights were used for transfer learning on four new down-stream segmentation tasks for which a fully annotated dataset was available. We analyzed the training set size's influence to simulate scarce data. The results showed that transfer learning from the base model was beneficial when small datasets were available, providing significant performance improvements; where fine-tuning the base model is more beneficial than updating all the network weights with vanilla transfer learning. Transfer learning with fine-tuning increased the performance by up to 0.129 (+28\%) Dice score than experiments trained from scratch, and on average 23 experiments increased the performance by 0.029 Dice score in the new segmentation tasks. The study also showed that cross-modality transfer learning using CT scans was beneficial. The findings of this study demonstrate the potential of transfer learning to improve the efficiency of annotation and increase the accessibility of accurate organ segmentation in medical imaging, ultimately leading to improved patient care. We made the network definition and weights publicly available to benefit other users and researchers.
Rethinking Event-based Human Pose Estimation with 3D Event Representations
Nov 08, 2023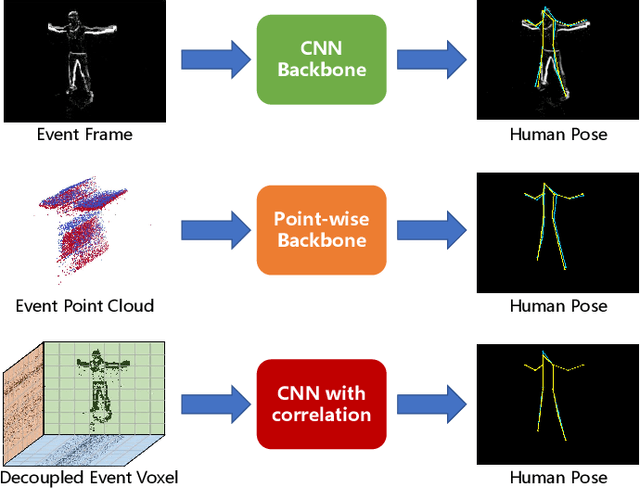
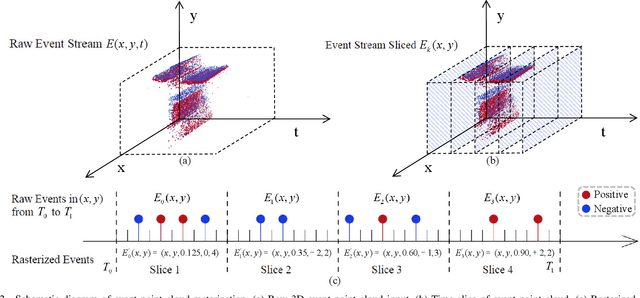
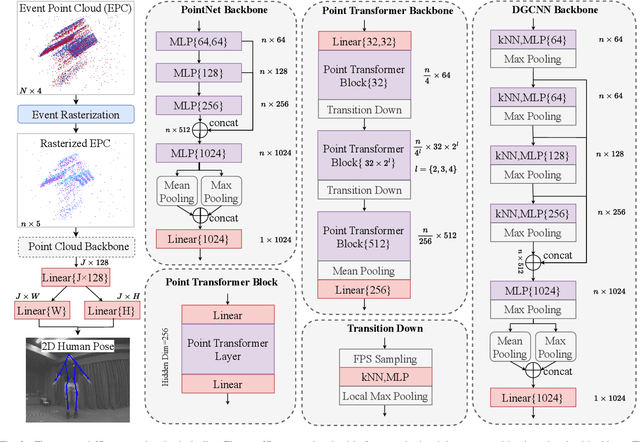
Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
Lidar Annotation Is All You Need
Nov 08, 2023In recent years, computer vision has transformed fields such as medical imaging, object recognition, and geospatial analytics. One of the fundamental tasks in computer vision is semantic image segmentation, which is vital for precise object delineation. Autonomous driving represents one of the key areas where computer vision algorithms are applied. The task of road surface segmentation is crucial in self-driving systems, but it requires a labor-intensive annotation process in several data domains. The work described in this paper aims to improve the efficiency of image segmentation using a convolutional neural network in a multi-sensor setup. This approach leverages lidar (Light Detection and Ranging) annotations to directly train image segmentation models on RGB images. Lidar supplements the images by emitting laser pulses and measuring reflections to provide depth information. However, lidar's sparse point clouds often create difficulties for accurate object segmentation. Segmentation of point clouds requires time-consuming preliminary data preparation and a large amount of computational resources. The key innovation of our approach is the masked loss, addressing sparse ground-truth masks from point clouds. By calculating loss exclusively where lidar points exist, the model learns road segmentation on images by using lidar points as ground truth. This approach allows for blending of different ground-truth data types during model training. Experimental validation of the approach on benchmark datasets shows comparable performance to a high-quality image segmentation model. Incorporating lidar reduces the load on annotations and enables training of image-segmentation models without loss of segmentation quality. The methodology is tested on diverse datasets, both publicly available and proprietary. The strengths and weaknesses of the proposed method are also discussed in the paper.
Automated Annotation of Scientific Texts for ML-based Keyphrase Extraction and Validation
Nov 08, 2023Advanced omics technologies and facilities generate a wealth of valuable data daily; however, the data often lacks the essential metadata required for researchers to find and search them effectively. The lack of metadata poses a significant challenge in the utilization of these datasets. Machine learning-based metadata extraction techniques have emerged as a potentially viable approach to automatically annotating scientific datasets with the metadata necessary for enabling effective search. Text labeling, usually performed manually, plays a crucial role in validating machine-extracted metadata. However, manual labeling is time-consuming; thus, there is an need to develop automated text labeling techniques in order to accelerate the process of scientific innovation. This need is particularly urgent in fields such as environmental genomics and microbiome science, which have historically received less attention in terms of metadata curation and creation of gold-standard text mining datasets. In this paper, we present two novel automated text labeling approaches for the validation of ML-generated metadata for unlabeled texts, with specific applications in environmental genomics. Our techniques show the potential of two new ways to leverage existing information about the unlabeled texts and the scientific domain. The first technique exploits relationships between different types of data sources related to the same research study, such as publications and proposals. The second technique takes advantage of domain-specific controlled vocabularies or ontologies. In this paper, we detail applying these approaches for ML-generated metadata validation. Our results show that the proposed label assignment approaches can generate both generic and highly-specific text labels for the unlabeled texts, with up to 44% of the labels matching with those suggested by a ML keyword extraction algorithm.
Real-Time Semantic Segmentation: A Brief Survey & Comparative Study in Remote Sensing
Sep 12, 2023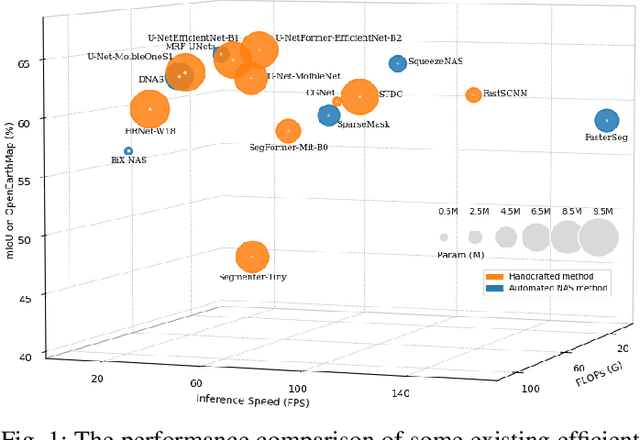
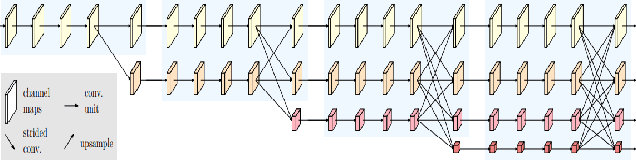
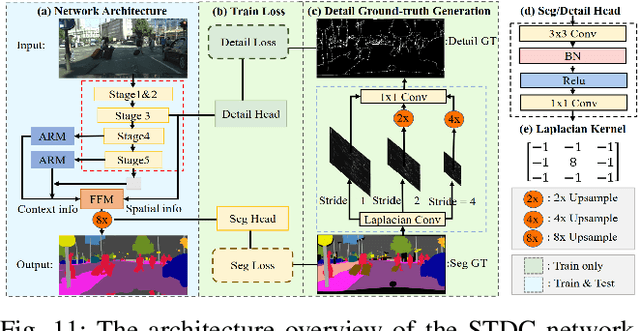
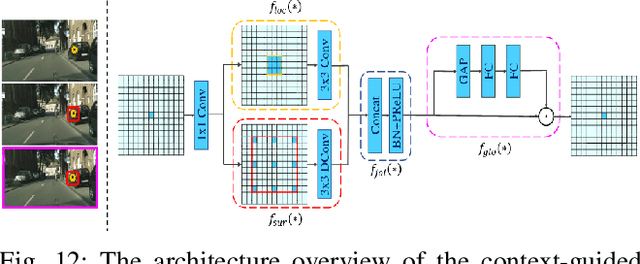
Real-time semantic segmentation of remote sensing imagery is a challenging task that requires a trade-off between effectiveness and efficiency. It has many applications including tracking forest fires, detecting changes in land use and land cover, crop health monitoring, and so on. With the success of efficient deep learning methods (i.e., efficient deep neural networks) for real-time semantic segmentation in computer vision, researchers have adopted these efficient deep neural networks in remote sensing image analysis. This paper begins with a summary of the fundamental compression methods for designing efficient deep neural networks and provides a brief but comprehensive survey, outlining the recent developments in real-time semantic segmentation of remote sensing imagery. We examine several seminal efficient deep learning methods, placing them in a taxonomy based on the network architecture design approach. Furthermore, we evaluate the quality and efficiency of some existing efficient deep neural networks on a publicly available remote sensing semantic segmentation benchmark dataset, the OpenEarthMap. The experimental results of an extensive comparative study demonstrate that most of the existing efficient deep neural networks have good segmentation quality, but they suffer low inference speed (i.e., high latency rate), which may limit their capability of deployment in real-time applications of remote sensing image segmentation. We provide some insights into the current trend and future research directions for real-time semantic segmentation of remote sensing imagery.
Duplicate Question Retrieval and Confirmation Time Prediction in Software Communities
Sep 10, 2023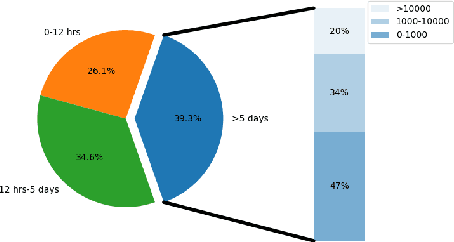
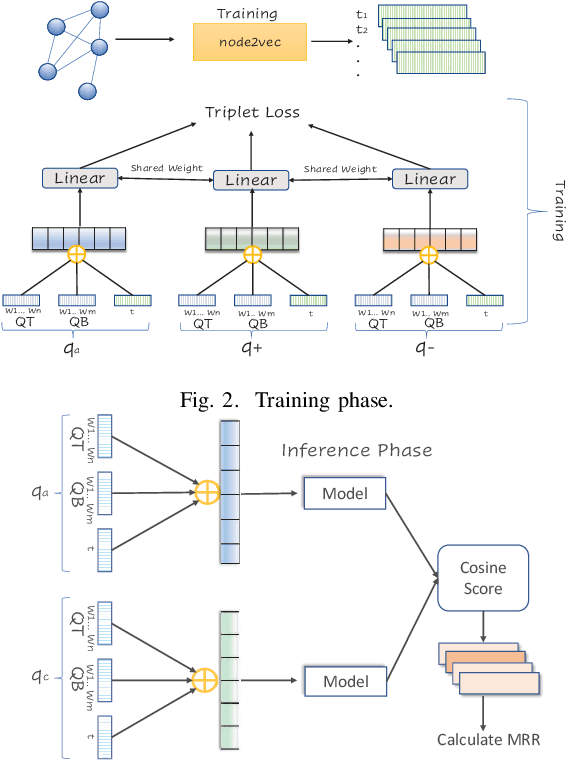


Community Question Answering (CQA) in different domains is growing at a large scale because of the availability of several platforms and huge shareable information among users. With the rapid growth of such online platforms, a massive amount of archived data makes it difficult for moderators to retrieve possible duplicates for a new question and identify and confirm existing question pairs as duplicates at the right time. This problem is even more critical in CQAs corresponding to large software systems like askubuntu where moderators need to be experts to comprehend something as a duplicate. Note that the prime challenge in such CQA platforms is that the moderators are themselves experts and are therefore usually extremely busy with their time being extraordinarily expensive. To facilitate the task of the moderators, in this work, we have tackled two significant issues for the askubuntu CQA platform: (1) retrieval of duplicate questions given a new question and (2) duplicate question confirmation time prediction. In the first task, we focus on retrieving duplicate questions from a question pool for a particular newly posted question. In the second task, we solve a regression problem to rank a pair of questions that could potentially take a long time to get confirmed as duplicates. For duplicate question retrieval, we propose a Siamese neural network based approach by exploiting both text and network-based features, which outperforms several state-of-the-art baseline techniques. Our method outperforms DupPredictor and DUPE by 5% and 7% respectively. For duplicate confirmation time prediction, we have used both the standard machine learning models and neural network along with the text and graph-based features. We obtain Spearman's rank correlation of 0.20 and 0.213 (statistically significant) for text and graph based features respectively.
Continual atlas-based segmentation of prostate MRI
Nov 06, 2023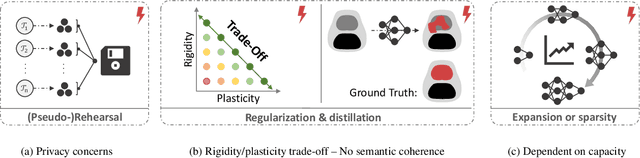
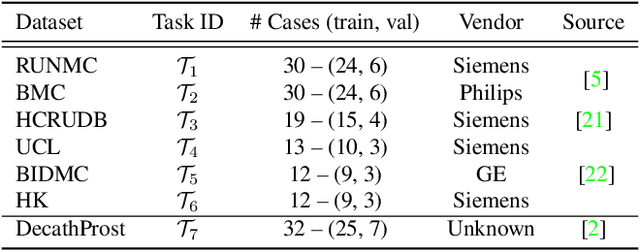
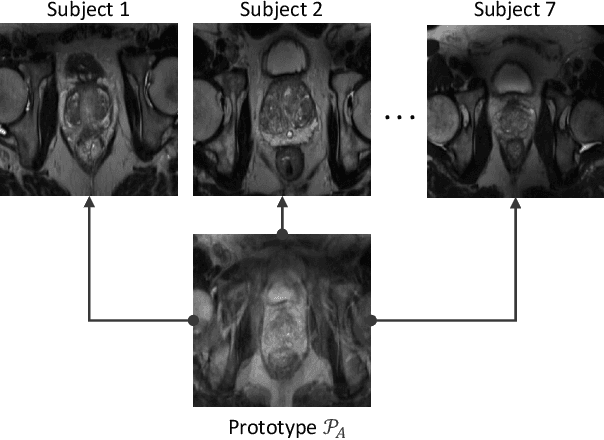
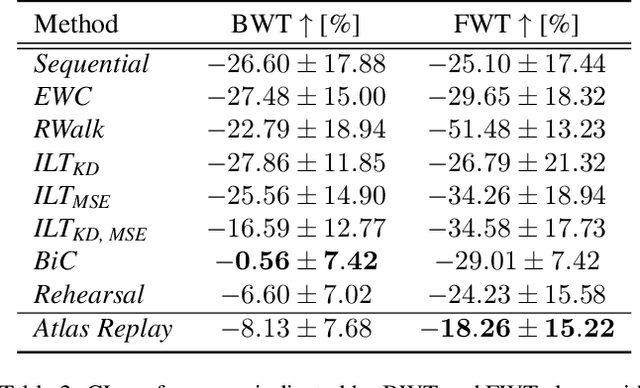
Continual learning (CL) methods designed for natural image classification often fail to reach basic quality standards for medical image segmentation. Atlas-based segmentation, a well-established approach in medical imaging, incorporates domain knowledge on the region of interest, leading to semantically coherent predictions. This is especially promising for CL, as it allows us to leverage structural information and strike an optimal balance between model rigidity and plasticity over time. When combined with privacy-preserving prototypes, this process offers the advantages of rehearsal-based CL without compromising patient privacy. We propose Atlas Replay, an atlas-based segmentation approach that uses prototypes to generate high-quality segmentation masks through image registration that maintain consistency even as the training distribution changes. We explore how our proposed method performs compared to state-of-the-art CL methods in terms of knowledge transferability across seven publicly available prostate segmentation datasets. Prostate segmentation plays a vital role in diagnosing prostate cancer, however, it poses challenges due to substantial anatomical variations, benign structural differences in older age groups, and fluctuating acquisition parameters. Our results show that Atlas Replay is both robust and generalizes well to yet-unseen domains while being able to maintain knowledge, unlike end-to-end segmentation methods. Our code base is available under https://github.com/MECLabTUDA/Atlas-Replay.
Online Learning Quantum States with the Logarithmic Loss via VB-FTRL
Nov 06, 2023Online learning quantum states with the logarithmic loss (LL-OLQS) is a quantum generalization of online portfolio selection, a classic open problem in the field of online learning for over three decades. The problem also emerges in designing randomized optimization algorithms for maximum-likelihood quantum state tomography. Recently, Jezequel et al. (arXiv:2209.13932) proposed the VB-FTRL algorithm, the first nearly regret-optimal algorithm for OPS with moderate computational complexity. In this note, we generalize VB-FTRL for LL-OLQS. Let $d$ denote the dimension and $T$ the number of rounds. The generalized algorithm achieves a regret rate of $O ( d^2 \log ( d + T ) )$ for LL-OLQS. Each iteration of the algorithm consists of solving a semidefinite program that can be implemented in polynomial time by, e.g., cutting-plane methods. For comparison, the best-known regret rate for LL-OLQS is currently $O ( d^2 \log T )$, achieved by the exponential weight method. However, there is no explicit implementation available for the exponential weight method for LL-OLQS. To facilitate the generalization, we introduce the notion of VB-convexity. VB-convexity is a sufficient condition for the logarithmic barrier associated with any function to be convex and is of independent interest.
iDb-A*: Iterative Search and Optimization for Optimal Kinodynamic Motion Planning
Nov 06, 2023Motion planning for robotic systems with complex dynamics is a challenging problem. While recent sampling-based algorithms achieve asymptotic optimality by propagating random control inputs, their empirical convergence rate is often poor, especially in high-dimensional systems such as multirotors. An alternative approach is to first plan with a simplified geometric model and then use trajectory optimization to follow the reference path while accounting for the true dynamics. However, this approach may fail to produce a valid trajectory if the initial guess is not close to a dynamically feasible trajectory. In this paper, we present Iterative Discontinuity Bounded A* (iDb-A*), a novel kinodynamic motion planner that combines search and optimization iteratively. The search step utilizes a finite set of short trajectories (motion primitives) that are interconnected while allowing for a bounded discontinuity between them. The optimization step locally repairs the discontinuities with trajectory optimization. By progressively reducing the allowed discontinuity and incorporating more motion primitives, our algorithm achieves asymptotic optimality with excellent any-time performance. We provide a benchmark of 43 problems across eight different dynamical systems, including different versions of unicycles and multirotors. Compared to state-of-the-art methods, iDb-A* consistently solves more problem instances and finds lower-cost solutions more rapidly.
Plug-and-Play Stability for Intracortical Brain-Computer Interfaces: A One-Year Demonstration of Seamless Brain-to-Text Communication
Nov 06, 2023Intracortical brain-computer interfaces (iBCIs) have shown promise for restoring rapid communication to people with neurological disorders such as amyotrophic lateral sclerosis (ALS). However, to maintain high performance over time, iBCIs typically need frequent recalibration to combat changes in the neural recordings that accrue over days. This requires iBCI users to stop using the iBCI and engage in supervised data collection, making the iBCI system hard to use. In this paper, we propose a method that enables self-recalibration of communication iBCIs without interrupting the user. Our method leverages large language models (LMs) to automatically correct errors in iBCI outputs. The self-recalibration process uses these corrected outputs ("pseudo-labels") to continually update the iBCI decoder online. Over a period of more than one year (403 days), we evaluated our Continual Online Recalibration with Pseudo-labels (CORP) framework with one clinical trial participant. CORP achieved a stable decoding accuracy of 93.84% in an online handwriting iBCI task, significantly outperforming other baseline methods. Notably, this is the longest-running iBCI stability demonstration involving a human participant. Our results provide the first evidence for long-term stabilization of a plug-and-play, high-performance communication iBCI, addressing a major barrier for the clinical translation of iBCIs.