 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Step Dialogue Workflow Action Prediction
Nov 16, 2023
In task-oriented dialogue, a system often needs to follow a sequence of actions, called a workflow, that complies with a set of guidelines in order to complete a task. In this paper, we propose the novel problem of multi-step workflow action prediction, in which the system predicts multiple future workflow actions. Accurate prediction of multiple steps allows for multi-turn automation, which can free up time to focus on more complex tasks. We propose three modeling approaches that are simple to implement yet lead to more action automation: 1) fine-tuning on a training dataset, 2) few-shot in-context learning leveraging retrieval and large language model prompting, and 3) zero-shot graph traversal, which aggregates historical action sequences into a graph for prediction. We show that multi-step action prediction produces features that improve accuracy on downstream dialogue tasks like predicting task success, and can increase automation of steps by 20% without requiring as much feedback from a human overseeing the system.
Utility AI for Dynamic Task Offloading in the Multi-Edge Infrastructure
Nov 16, 2023To circumvent persistent connectivity to the cloud infrastructure, the current emphasis on computing at network edge devices in the multi-robot domain is a promising enabler for delay-sensitive jobs, yet its adoption is rife with challenges. This paper proposes a novel utility-aware dynamic task offloading strategy based on a multi-edge-robot system that takes into account computation, communication, and task execution load to minimize the overall service time for delay-sensitive applications. Prior to task offloading, continuous device, network, and task profiling are performed, and for each task assigned, an edge with maximum utility is derived using a weighted utility maximization technique, and a system reward assignment for task connectivity or sensitivity is performed. A scheduler is in charge of task assignment, whereas an executor is responsible for task offloading on edge devices. Experimental comparisons of the proposed approach with conventional offloading methods indicate better performance in terms of optimizing resource utilization and minimizing task latency.
Learning the What and How of Annotation in Video Object Segmentation
Nov 08, 2023Video Object Segmentation (VOS) is crucial for several applications, from video editing to video data generation. Training a VOS model requires an abundance of manually labeled training videos. The de-facto traditional way of annotating objects requires humans to draw detailed segmentation masks on the target objects at each video frame. This annotation process, however, is tedious and time-consuming. To reduce this annotation cost, in this paper, we propose EVA-VOS, a human-in-the-loop annotation framework for video object segmentation. Unlike the traditional approach, we introduce an agent that predicts iteratively both which frame ("What") to annotate and which annotation type ("How") to use. Then, the annotator annotates only the selected frame that is used to update a VOS module, leading to significant gains in annotation time. We conduct experiments on the MOSE and the DAVIS datasets and we show that: (a) EVA-VOS leads to masks with accuracy close to the human agreement 3.5x faster than the standard way of annotating videos; (b) our frame selection achieves state-of-the-art performance; (c) EVA-VOS yields significant performance gains in terms of annotation time compared to all other methods and baselines.
Vital Signs Estimation Using a 26 GHz Multi-Beam Communication Testbed
Nov 19, 2023This paper presents a novel pipeline for vital sign monitoring using a 26 GHz multi-beam communication testbed. In context of Joint Communication and Sensing (JCAS), the advanced communication capability at millimeter-wave bands is comparable to the radio resource of radars and is promising to sense the surrounding environment. Being able to communicate and sense the vital sign of humans present in the environment will enable new vertical services of telecommunication, i.e., remote health monitoring. The proposed processing pipeline leverages spatially orthogonal beams to estimate the vital sign - breath rate and heart rate - of single and multiple persons in static scenarios from the raw Channel State Information samples. We consider both monostatic and bistatic sensing scenarios. For monostatic scenario, we employ the phase time-frequency calibration and Discrete Wavelet Transform to improve the performance compared to the conventional Fast Fourier Transform based methods. For bistatic scenario, we use K-means clustering algorithm to extract multi-person vital signs due to the distinct frequency-domain signal feature between single and multi-person scenarios. The results show that the estimated breath rate and heart rate reach below 2 beats per minute (bpm) error compared to the reference captured by on-body sensor for the single-person monostatic sensing scenario with body-transceiver distance up to 2 m, and the two-person bistatic sensing scenario with BS-UE distance up to 4 m. The presented work does not optimize the OFDM waveform parameters for sensing; it demonstrates a promising JCAS proof-of-concept in contact-free vital sign monitoring using mmWave multi-beam communication systems.
ShipGen: A Diffusion Model for Parametric Ship Hull Generation with Multiple Objectives and Constraints
Nov 14, 2023


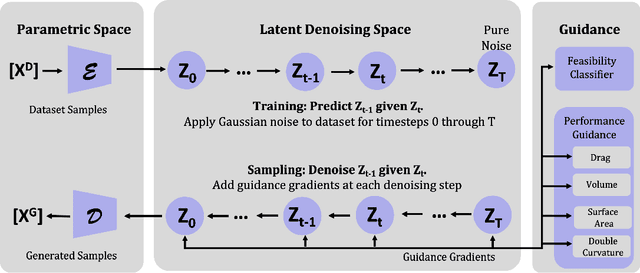
Ship design is a years-long process that requires balancing complex design trade-offs to create a ship that is efficient and effective. Finding new ways to improve the ship design process can lead to significant cost savings for ship building and operation. One promising technology is generative artificial intelligence, which has been shown to reduce design cycle time and create novel, high-performing designs. In literature review, generative artificial intelligence has been shown to generate ship hulls; however, ship design is particularly difficult as the hull of a ship requires the consideration of many objectives. This paper presents a study on the generation of parametric ship hull designs using a parametric diffusion model that considers multiple objectives and constraints for the hulls. This denoising diffusion probabilistic model (DDPM) generates the tabular parametric design vectors of a ship hull for evaluation. In addition to a tabular DDPM, this paper details adding guidance to improve the quality of generated ship hull designs. By leveraging classifier guidance, the DDPM produced feasible parametric ship hulls that maintain the coverage of the initial training dataset of ship hulls with a 99.5% rate, a 149x improvement over random sampling of the design vector parameters across the design space. Parametric ship hulls produced with performance guidance saw an average of 91.4% reduction in wave drag coefficients and an average of a 47.9x relative increase in the total displaced volume of the hulls compared to the mean performance of the hulls in the training dataset. The use of a DDPM to generate parametric ship hulls can reduce design time by generating high-performing hull designs for future analysis. These generated hulls have low drag and high volume, which can reduce the cost of operating a ship and increase its potential to generate revenue.
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 06, 2023Astrocytes are a highly expressed and highly enigmatic cell-type in the mammalian brain. Traditionally viewed as a mediator of basic physiological sustenance, it is increasingly recognized that astrocytes may play a more direct role in neural computation. A conceptual challenge to this idea is the fact that astrocytic activity takes a very different form than that of neurons, and in particular, occurs at orders-of-magnitude slower time-scales. In the current paper, we engage how such time-scale separation may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. This idea is based on the recent supposition that astrocytes, owing to their sensitivity to a host of physiological covariates, may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. We pose a general model of neural-synaptic-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogenous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neural-astrocyte interaction in the brain may benefit learning over different time-scale and the conveyance of task relevant contextual information onto circuit dynamics.
Determining the Optimal Number of Clusters for Time Series Datasets with Symbolic Pattern Forest
Oct 01, 2023Clustering algorithms are among the most widely used data mining methods due to their exploratory power and being an initial preprocessing step that paves the way for other techniques. But the problem of calculating the optimal number of clusters (say k) is one of the significant challenges for such methods. The most widely used clustering algorithms like k-means and k-shape in time series data mining also need the ground truth for the number of clusters that need to be generated. In this work, we extended the Symbolic Pattern Forest algorithm, another time series clustering algorithm, to determine the optimal number of clusters for the time series datasets. We used SPF to generate the clusters from the datasets and chose the optimal number of clusters based on the Silhouette Coefficient, a metric used to calculate the goodness of a clustering technique. Silhouette was calculated on both the bag of word vectors and the tf-idf vectors generated from the SAX words of each time series. We tested our approach on the UCR archive datasets, and our experimental results so far showed significant improvement over the baseline.
Signal Processing Meets SGD: From Momentum to Filter
Nov 17, 2023In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.
Towards a Standardized Reinforcement Learning Framework for AAM Contingency Management
Nov 17, 2023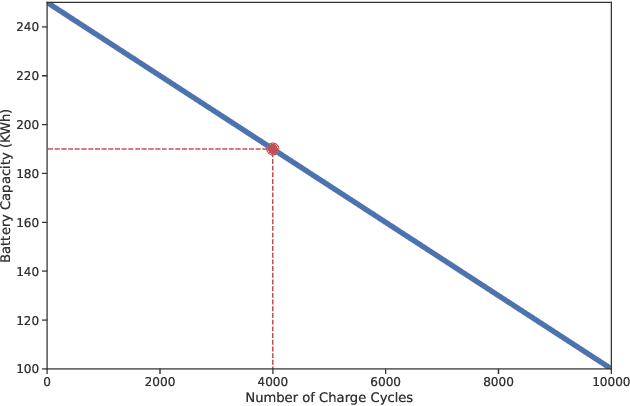
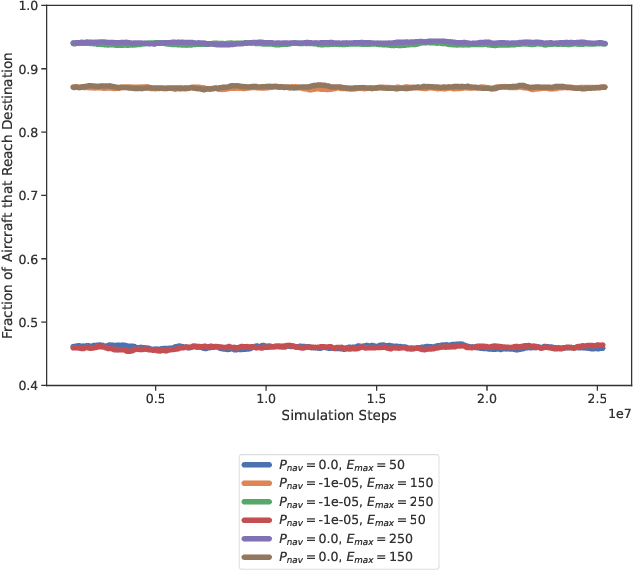

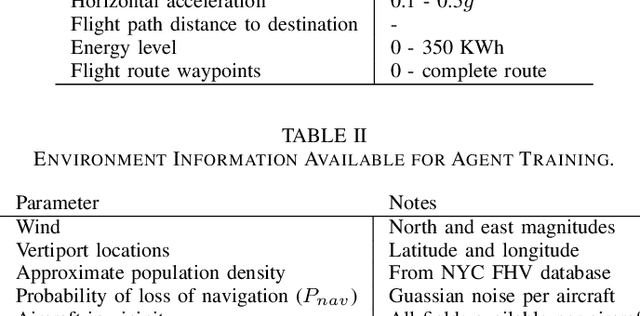
Advanced Air Mobility (AAM) is the next generation of air transportation that includes new entrants such as electric vertical takeoff and landing (eVTOL) aircraft, increasingly autonomous flight operations, and small UAS package delivery. With these new vehicles and operational concepts comes a desire to increase densities far beyond what occurs today in and around urban areas, to utilize new battery technology, and to move toward more autonomously-piloted aircraft. To achieve these goals, it becomes essential to introduce new safety management system capabilities that can rapidly assess risk as it evolves across a span of complex hazards and, if necessary, mitigate risk by executing appropriate contingencies via supervised or automated decision-making during flights. Recently, reinforcement learning has shown promise for real-time decision making across a wide variety of applications including contingency management. In this work, we formulate the contingency management problem as a Markov Decision Process (MDP) and integrate the contingency management MDP into the AAM-Gym simulation framework. This enables rapid prototyping of reinforcement learning algorithms and evaluation of existing systems, thus providing a community benchmark for future algorithm development. We report baseline statistical information for the environment and provide example performance metrics.
Collaborative Grid Mapping for Moving Object Tracking Evaluation
Nov 17, 2023Perception of other road users is a crucial task for intelligent vehicles. Perception systems can use on-board sensors only or be in cooperation with other vehicles or with roadside units. In any case, the performance of perception systems has to be evaluated against ground-truth data, which is a particularly tedious task and requires numerous manual operations. In this article, we propose a novel semi-automatic method for pseudo ground-truth estimation. The principle consists in carrying out experiments with several vehicles equipped with LiDAR sensors and with fixed perception systems located at the roadside in order to collaboratively build reference dynamic data. The method is based on grid mapping and in particular on the elaboration of a background map that holds relevant information that remains valid during a whole dataset sequence. Data from all agents is converted in time-stamped observations grids. A data fusion method that manages uncertainties combines the background map with observations to produce dynamic reference information at each instant. Several datasets have been acquired with three experimental vehicles and a roadside unit. An evaluation of this method is finally provided in comparison to a handmade ground truth.