 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Scene Graph Generation with Hierarchical Relationships and Commonsense Knowledge
Nov 21, 2023
This work presents an enhanced approach to generating scene graphs by incorporating a relationship hierarchy and commonsense knowledge. Specifically, we propose a Bayesian classification head that exploits an informative hierarchical structure. It jointly predicts the super-category or type of relationship between the two objects, along with the detailed relationship under each super-category. We design a commonsense validation pipeline that uses a large language model to critique the results from the scene graph prediction system and then use that feedback to enhance the model performance. The system requires no external large language model assistance at test time, making it more convenient for practical applications. Experiments on the Visual Genome and the OpenImage V6 datasets demonstrate that harnessing hierarchical relationships enhances the model performance by a large margin. The proposed Bayesian head can also be incorporated as a portable module in existing scene graph generation algorithms to improve their results. In addition, the commonsense validation enables the model to generate an extensive set of reasonable predictions beyond dataset annotations.
Multi-Resolution Planar Region Extraction for Uneven Terrains
Nov 21, 2023This paper studies the problem of extracting planar regions in uneven terrains from unordered point cloud measurements. Such a problem is critical in various robotic applications such as robotic perceptive locomotion. While existing approaches have shown promising results in effectively extracting planar regions from the environment, they often suffer from issues such as low computational efficiency or loss of resolution. To address these issues, we propose a multi-resolution planar region extraction strategy in this paper that balances the accuracy in boundaries and computational efficiency. Our method begins with a pointwise classification preprocessing module, which categorizes all sampled points according to their local geometric properties to facilitate multi-resolution segmentation. Subsequently, we arrange the categorized points using an octree, followed by an in-depth analysis of nodes to finish multi-resolution plane segmentation. The efficiency and robustness of the proposed approach are verified via synthetic and real-world experiments, demonstrating our method's ability to generalize effectively across various uneven terrains while maintaining real-time performance, achieving frame rates exceeding 35 FPS.
Towards a more inductive world for drug repurposing approaches
Nov 21, 2023Drug-target interaction (DTI) prediction is a challenging, albeit essential task in drug repurposing. Learning on graph models have drawn special attention as they can significantly reduce drug repurposing costs and time commitment. However, many current approaches require high-demanding additional information besides DTIs that complicates their evaluation process and usability. Additionally, structural differences in the learning architecture of current models hinder their fair benchmarking. In this work, we first perform an in-depth evaluation of current DTI datasets and prediction models through a robust benchmarking process, and show that DTI prediction methods based on transductive models lack generalization and lead to inflated performance when evaluated as previously done in the literature, hence not being suited for drug repurposing approaches. We then propose a novel biologically-driven strategy for negative edge subsampling and show through in vitro validation that newly discovered interactions are indeed true. We envision this work as the underpinning for future fair benchmarking and robust model design. All generated resources and tools are publicly available as a python package.
Implementation of AI Deep Learning Algorithm For Multi-Modal Sentiment Analysis
Nov 19, 2023A multi-modal emotion recognition method was established by combining two-channel convolutional neural network with ring network. This method can extract emotional information effectively and improve learning efficiency. The words were vectorized with GloVe, and the word vector was input into the convolutional neural network. Combining attention mechanism and maximum pool converter BiSRU channel, the local deep emotion and pre-post sequential emotion semantics are obtained. Finally, multiple features are fused and input as the polarity of emotion, so as to achieve the emotion analysis of the target. Experiments show that the emotion analysis method based on feature fusion can effectively improve the recognition accuracy of emotion data set and reduce the learning time. The model has a certain generalization.
Task-Distributionally Robust Data-Free Meta-Learning
Nov 23, 2023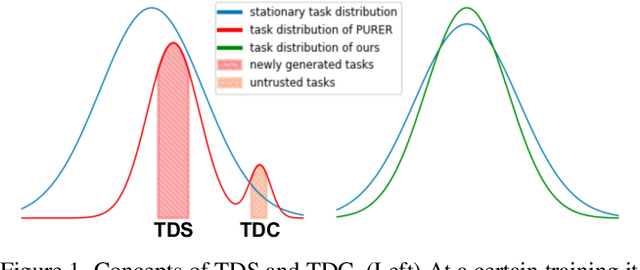
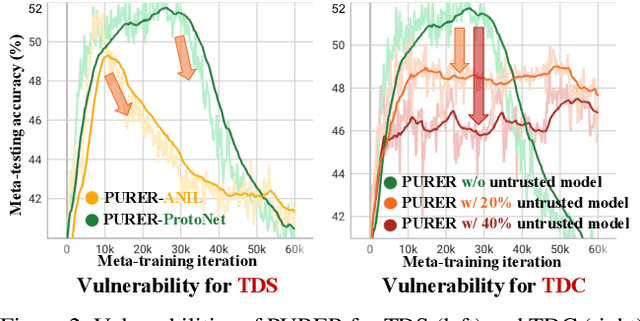
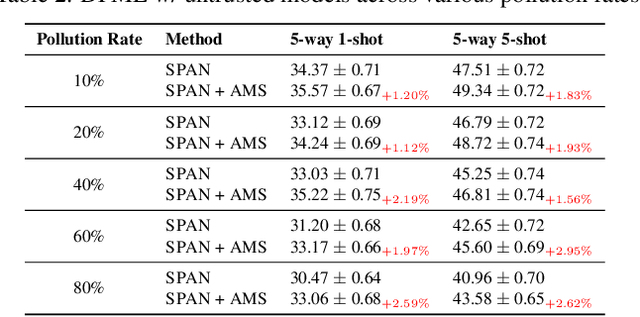
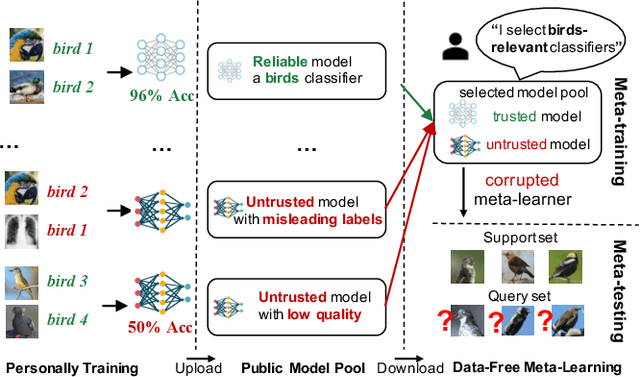
Data-Free Meta-Learning (DFML) aims to efficiently learn new tasks by leveraging multiple pre-trained models without requiring their original training data. Existing inversion-based DFML methods construct pseudo tasks from a learnable dataset, which is inversely generated from the pre-trained model pool. For the first time, we reveal two major challenges hindering their practical deployments: Task-Distribution Shift (TDS) and Task-Distribution Corruption (TDC). TDS leads to a biased meta-learner because of the skewed task distribution towards newly generated tasks. TDC occurs when untrusted models characterized by misleading labels or poor quality pollute the task distribution. To tackle these issues, we introduce a robust DFML framework that ensures task distributional robustness. We propose to meta-learn from a pseudo task distribution, diversified through task interpolation within a compact task-memory buffer. This approach reduces the meta-learner's overreliance on newly generated tasks by maintaining consistent performance across a broader range of interpolated memory tasks, thus ensuring its generalization for unseen tasks. Additionally, our framework seamlessly incorporates an automated model selection mechanism into the meta-training phase, parameterizing each model's reliability as a learnable weight. This is optimized with a policy gradient algorithm inspired by reinforcement learning, effectively addressing the non-differentiable challenge posed by model selection. Comprehensive experiments across various datasets demonstrate the framework's effectiveness in mitigating TDS and TDC, underscoring its potential to improve DFML in real-world scenarios.
Expanding the deep-learning model to diagnosis LVNC: Limitations and trade-offs
Nov 23, 2023Hyper-trabeculation or non-compaction in the left ventricle of the myocardium (LVNC) is a recently classified form of cardiomyopathy. Several methods have been proposed to quantify the trabeculae accurately in the left ventricle, but there is no general agreement in the medical community to use a particular approach. In previous work, we proposed DL-LVTQ, a deep learning approach for left ventricular trabecular quantification based on a U-Net CNN architecture. DL-LVTQ was an automatic diagnosis tool developed from a dataset of patients with the same cardiomyopathy (hypertrophic cardiomyopathy). In this work, we have extended and adapted DL-LVTQ to cope with patients with different cardiomyopathies. The dataset consists of up 379 patients in three groups with different particularities and cardiomyopathies. Patient images were taken from different scanners and hospitals. We have modified and adapted the U-Net convolutional neural network to account for the different particularities of a heterogeneous group of patients with various unclassifiable or mixed and inherited cardiomyopathies. The inclusion of new groups of patients has increased the accuracy, specificity and kappa values while maintaining the sensitivity of the automatic deep learning method proposed. Therefore, a better-prepared diagnosis tool is ready for various cardiomyopathies with different characteristics. Cardiologists have considered that 98.9% of the evaluated outputs are verified clinically for diagnosis. Therefore, the high precision to segment the different cardiac structures allows us to make a robust diagnostic system objective and faster, decreasing human error and time spent.
A Cross Attention Approach to Diagnostic Explainability using Clinical Practice Guidelines for Depression
Nov 23, 2023The lack of explainability using relevant clinical knowledge hinders the adoption of Artificial Intelligence-powered analysis of unstructured clinical dialogue. A wealth of relevant, untapped Mental Health (MH) data is available in online communities, providing the opportunity to address the explainability problem with substantial potential impact as a screening tool for both online and offline applications. We develop a method to enhance attention in popular transformer models and generate clinician-understandable explanations for classification by incorporating external clinical knowledge. Inspired by how clinicians rely on their expertise when interacting with patients, we leverage relevant clinical knowledge to model patient inputs, providing meaningful explanations for classification. This will save manual review time and engender trust. We develop such a system in the context of MH using clinical practice guidelines (CPG) for diagnosing depression, a mental health disorder of global concern. We propose an application-specific language model called ProcesS knowledge-infused cross ATtention (PSAT), which incorporates CPGs when computing attention. Through rigorous evaluation on three expert-curated datasets related to depression, we demonstrate application-relevant explainability of PSAT. PSAT also surpasses the performance of nine baseline models and can provide explanations where other baselines fall short. We transform a CPG resource focused on depression, such as the Patient Health Questionnaire (e.g. PHQ-9) and related questions, into a machine-readable ontology using SNOMED-CT. With this resource, PSAT enhances the ability of models like GPT-3.5 to generate application-relevant explanations.
ViP-Mixer: A Convolutional Mixer for Video Prediction
Nov 20, 2023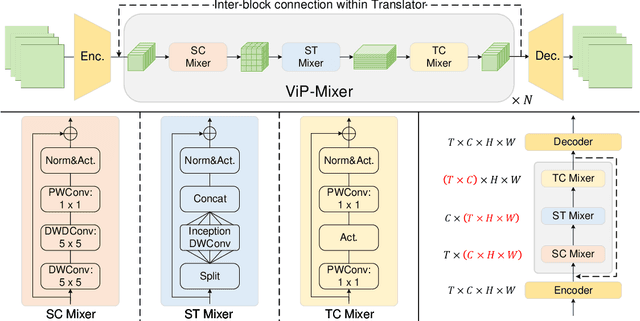
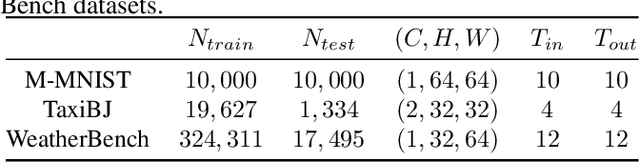
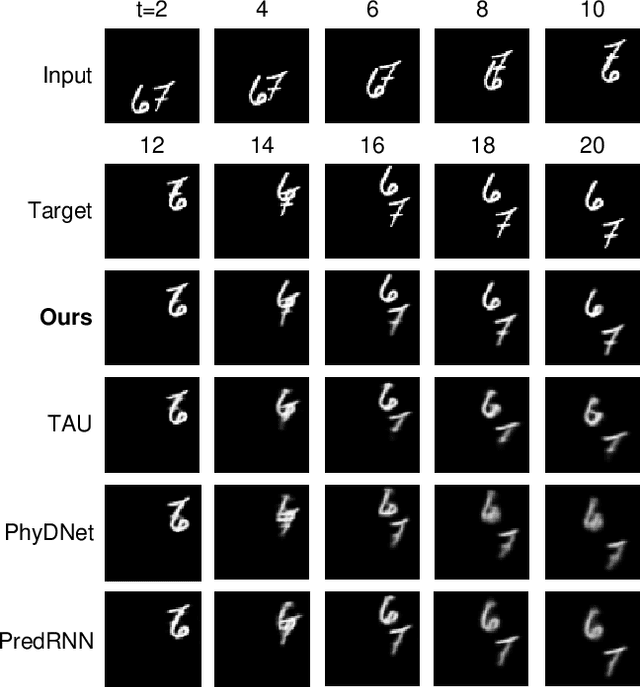
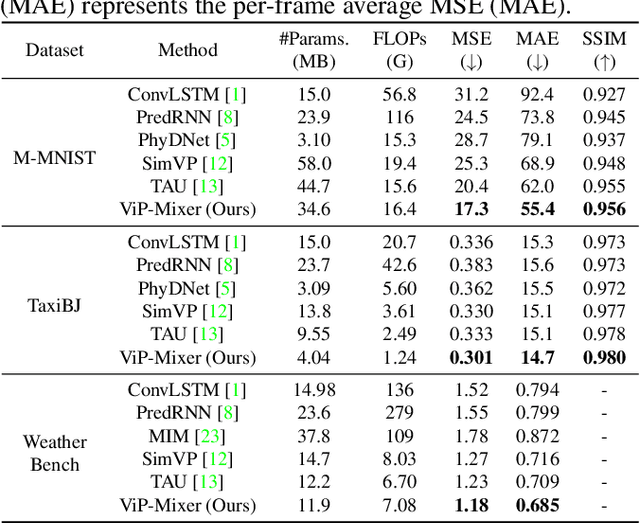
Video prediction aims to predict future frames from a video's previous content. Existing methods mainly process video data where the time dimension mingles with the space and channel dimensions from three distinct angles: as a sequence of individual frames, as a 3D volume in spatiotemporal coordinates, or as a stacked image where frames are treated as separate channels. Most of them generally focus on one of these perspectives and may fail to fully exploit the relationships across different dimensions. To address this issue, this paper introduces a convolutional mixer for video prediction, termed ViP-Mixer, to model the spatiotemporal evolution in the latent space of an autoencoder. The ViP-Mixers are stacked sequentially and interleave feature mixing at three levels: frames, channels, and locations. Extensive experiments demonstrate that our proposed method achieves new state-of-the-art prediction performance on three benchmark video datasets covering both synthetic and real-world scenarios.
Semantic-Preserved Point-based Human Avatar
Nov 20, 2023To enable realistic experience in AR/VR and digital entertainment, we present the first point-based human avatar model that embodies the entirety expressive range of digital humans. We employ two MLPs to model pose-dependent deformation and linear skinning (LBS) weights. The representation of appearance relies on a decoder and the features that attached to each point. In contrast to alternative implicit approaches, the oriented points representation not only provides a more intuitive way to model human avatar animation but also significantly reduces both training and inference time. Moreover, we propose a novel method to transfer semantic information from the SMPL-X model to the points, which enables to better understand human body movements. By leveraging the semantic information of points, we can facilitate virtual try-on and human avatar composition through exchanging the points of same category across different subjects. Experimental results demonstrate the efficacy of our presented method.
PaSS: Parallel Speculative Sampling
Nov 22, 2023Scaling the size of language models to tens of billions of parameters has led to impressive performance on a wide range of tasks. At generation, these models are used auto-regressively, requiring a forward pass for each generated token, and thus reading the full set of parameters from memory. This memory access forms the primary bottleneck for generation and it worsens as the model size increases. Moreover, executing a forward pass for multiple tokens in parallel often takes nearly the same time as it does for just one token. These two observations lead to the development of speculative sampling, where a second smaller model is used to draft a few tokens, that are then validated or rejected using a single forward pass of the large model. Unfortunately, this method requires two models that share the same tokenizer and thus limits its adoption. As an alternative, we propose to use parallel decoding as a way to draft multiple tokens from a single model with no computational cost, nor the need for a second model. Our approach only requires an additional input token that marks the words that will be generated simultaneously. We show promising performance (up to $30\%$ speed-up) while requiring only as few as $O(d_{emb})$ additional parameters.