 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Source-Free Domain Adaptation with Frozen Multimodal Foundation Model
Nov 27, 2023
Source-Free Domain Adaptation (SFDA) aims to adapt a source model for a target domain, with only access to unlabeled target training data and the source model pre-trained on a supervised source domain. Relying on pseudo labeling and/or auxiliary supervision, conventional methods are inevitably error-prone. To mitigate this limitation, in this work we for the first time explore the potentials of off-the-shelf vision-language (ViL) multimodal models (e.g.,CLIP) with rich whilst heterogeneous knowledge. We find that directly applying the ViL model to the target domain in a zero-shot fashion is unsatisfactory, as it is not specialized for this particular task but largely generic. To make it task specific, we propose a novel Distilling multimodal Foundation model(DIFO)approach. Specifically, DIFO alternates between two steps during adaptation: (i) Customizing the ViL model by maximizing the mutual information with the target model in a prompt learning manner, (ii) Distilling the knowledge of this customized ViL model to the target model. For more fine-grained and reliable distillation, we further introduce two effective regularization terms, namely most-likely category encouragement and predictive consistency. Extensive experiments show that DIFO significantly outperforms the state-of-the-art alternatives. Our source code will be released.
MOT-DETR: 3D Single Shot Detection and Tracking with Transformers to build 3D representations for Agro-Food Robots
Nov 27, 2023In the current demand for automation in the agro-food industry, accurately detecting and localizing relevant objects in 3D is essential for successful robotic operations. However, this is a challenge due the presence of occlusions. Multi-view perception approaches allow robots to overcome occlusions, but a tracking component is needed to associate the objects detected by the robot over multiple viewpoints. Most multi-object tracking (MOT) algorithms are designed for high frame rate sequences and struggle with the occlusions generated by robots' motions and 3D environments. In this paper, we introduce MOT-DETR, a novel approach to detect and track objects in 3D over time using a combination of convolutional networks and transformers. Our method processes 2D and 3D data, and employs a transformer architecture to perform data fusion. We show that MOT-DETR outperforms state-of-the-art multi-object tracking methods. Furthermore, we prove that MOT-DETR can leverage 3D data to deal with long-term occlusions and large frame-to-frame distances better than state-of-the-art methods. Finally, we show how our method is resilient to camera pose noise that can affect the accuracy of point clouds. The implementation of MOT-DETR can be found here: https://github.com/drapado/mot-detr
Leveraging Out-of-Domain Data for Domain-Specific Prompt Tuning in Multi-Modal Fake News Detection
Nov 27, 2023The spread of fake news using out-of-context images has become widespread and is a challenging task in this era of information overload. Since annotating huge amounts of such data requires significant time of domain experts, it is imperative to develop methods which can work in limited annotated data scenarios. In this work, we explore whether out-of-domain data can help to improve out-of-context misinformation detection (termed here as multi-modal fake news detection) of a desired domain, eg. politics, healthcare, etc. Towards this goal, we propose a novel framework termed DPOD (Domain-specific Prompt-tuning using Out-of-Domain data). First, to compute generalizable features, we modify the Vision-Language Model, CLIP to extract features that helps to align the representations of the images and corresponding text captions of both the in-domain and out-of-domain data in a label-aware manner. Further, we propose a domain-specific prompt learning technique which leverages the training samples of all the available domains based on the the extent they can be useful to the desired domain. Extensive experiments on a large-scale benchmark dataset, namely NewsClippings demonstrate that the proposed framework achieves state of-the-art performance, significantly surpassing the existing approaches for this challenging task.
Class-Adaptive Sampling Policy for Efficient Continual Learning
Nov 27, 2023Continual learning (CL) aims to acquire new knowledge while preserving information from previous experiences without forgetting. Though buffer-based methods (i.e., retaining samples from previous tasks) have achieved acceptable performance, determining how to allocate the buffer remains a critical challenge. Most recent research focuses on refining these methods but often fails to sufficiently consider the varying influence of samples on the learning process, and frequently overlooks the complexity of the classes/concepts being learned. Generally, these methods do not directly take into account the contribution of individual classes. However, our investigation indicates that more challenging classes necessitate preserving a larger number of samples compared to less challenging ones. To address this issue, we propose a novel method and policy named 'Class-Adaptive Sampling Policy' (CASP), which dynamically allocates storage space within the buffer. By utilizing concepts of class contribution and difficulty, CASP adaptively manages buffer space, allowing certain classes to occupy a larger portion of the buffer while reducing storage for others. This approach significantly improves the efficiency of knowledge retention and utilization. CASP provides a versatile solution to boost the performance and efficiency of CL. It meets the demand for dynamic buffer allocation, accommodating the varying contributions of different classes and their learning complexities over time.
Bandits Meet Mechanism Design to Combat Clickbait in Online Recommendation
Nov 27, 2023
We study a strategic variant of the multi-armed bandit problem, which we coin the strategic click-bandit. This model is motivated by applications in online recommendation where the choice of recommended items depends on both the click-through rates and the post-click rewards. Like in classical bandits, rewards follow a fixed unknown distribution. However, we assume that the click-rate of each arm is chosen strategically by the arm (e.g., a host on Airbnb) in order to maximize the number of times it gets clicked. The algorithm designer does not know the post-click rewards nor the arms' actions (i.e., strategically chosen click-rates) in advance, and must learn both values over time. To solve this problem, we design an incentive-aware learning algorithm, UCB-S, which achieves two goals simultaneously: (a) incentivizing desirable arm behavior under uncertainty; (b) minimizing regret by learning unknown parameters. We characterize all approximate Nash equilibria among arms under UCB-S and show a $\tilde{\mathcal{O}} (\sqrt{KT})$ regret bound uniformly in every equilibrium. We also show that incentive-unaware algorithms generally fail to achieve low regret in the strategic click-bandit. Finally, we support our theoretical results by simulations of strategic arm behavior which confirm the effectiveness and robustness of our proposed incentive design.
RBPGAN: Recurrent Back-Projection GAN for Video Super Resolution
Nov 24, 2023Recently, video super resolution (VSR) has become a very impactful task in the area of Computer Vision due to its various applications. In this paper, we propose Recurrent Back-Projection Generative Adversarial Network (RBPGAN) for VSR in an attempt to generate temporally coherent solutions while preserving spatial details. RBPGAN integrates two state-of-the-art models to get the best in both worlds without compromising the accuracy of produced video. The generator of the model is inspired by RBPN system, while the discriminator is inspired by TecoGAN. We also utilize Ping-Pong loss to increase temporal consistency over time. Our contribution together results in a model that outperforms earlier work in terms of temporally consistent details, as we will demonstrate qualitatively and quantitatively using different datasets.
Predicting breast cancer with AI for individual risk-adjusted MRI screening and early detection
Nov 29, 2023Women with an increased life-time risk of breast cancer undergo supplemental annual screening MRI. We propose to predict the risk of developing breast cancer within one year based on the current MRI, with the objective of reducing screening burden and facilitating early detection. An AI algorithm was developed on 53,858 breasts from 12,694 patients who underwent screening or diagnostic MRI and accrued over 12 years, with 2,331 confirmed cancers. A first U-Net was trained to segment lesions and identify regions of concern. A second convolutional network was trained to detect malignant cancer using features extracted by the U-Net. This network was then fine-tuned to estimate the risk of developing cancer within a year in cases that radiologists considered normal or likely benign. Risk predictions from this AI were evaluated with a retrospective analysis of 9,183 breasts from a high-risk screening cohort, which were not used for training. Statistical analysis focused on the tradeoff between number of omitted exams versus negative predictive value, and number of potential early detections versus positive predictive value. The AI algorithm identified regions of concern that coincided with future tumors in 52% of screen-detected cancers. Upon directed review, a radiologist found that 71.3% of cancers had a visible correlate on the MRI prior to diagnosis, 65% of these correlates were identified by the AI model. Reevaluating these regions in 10% of all cases with higher AI-predicted risk could have resulted in up to 33% early detections by a radiologist. Additionally, screening burden could have been reduced in 16% of lower-risk cases by recommending a later follow-up without compromising current interval cancer rate. With increasing datasets and improving image quality we expect this new AI-aided, adaptive screening to meaningfully reduce screening burden and improve early detection.
SODA: Robust Training of Test-Time Data Adaptors
Oct 17, 2023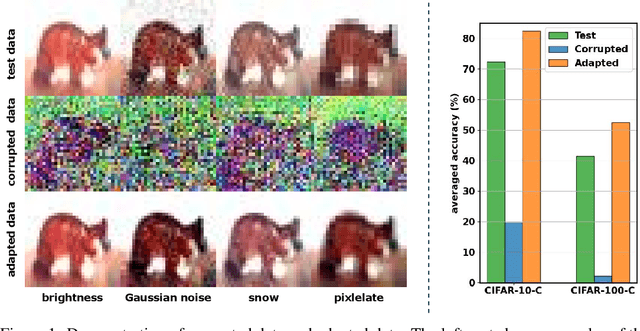
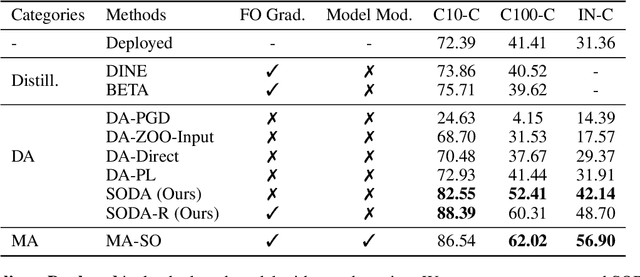
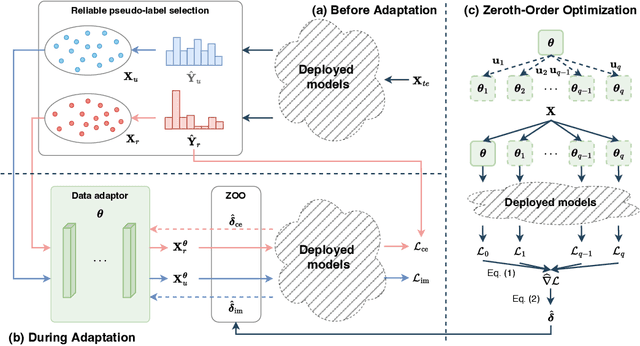

Adapting models deployed to test distributions can mitigate the performance degradation caused by distribution shifts. However, privacy concerns may render model parameters inaccessible. One promising approach involves utilizing zeroth-order optimization (ZOO) to train a data adaptor to adapt the test data to fit the deployed models. Nevertheless, the data adaptor trained with ZOO typically brings restricted improvements due to the potential corruption of data features caused by the data adaptor. To address this issue, we revisit ZOO in the context of test-time data adaptation. We find that the issue directly stems from the unreliable estimation of the gradients used to optimize the data adaptor, which is inherently due to the unreliable nature of the pseudo-labels assigned to the test data. Based on this observation, we propose pseudo-label-robust data adaptation (SODA) to improve the performance of data adaptation. Specifically, SODA leverages high-confidence predicted labels as reliable labels to optimize the data adaptor with ZOO for label prediction. For data with low-confidence predictions, SODA encourages the adaptor to preserve data information to mitigate data corruption. Empirical results indicate that SODA can significantly enhance the performance of deployed models in the presence of distribution shifts without requiring access to model parameters.
Investigating the use of publicly available natural videos to learn Dynamic MR image reconstruction
Nov 23, 2023Purpose: To develop and assess a deep learning (DL) pipeline to learn dynamic MR image reconstruction from publicly available natural videos (Inter4K). Materials and Methods: Learning was performed for a range of DL architectures (VarNet, 3D UNet, FastDVDNet) and corresponding sampling patterns (Cartesian, radial, spiral) either from true multi-coil cardiac MR data (N=692) or from pseudo-MR data simulated from Inter4K natural videos (N=692). Real-time undersampled dynamic MR images were reconstructed using DL networks trained with cardiac data and natural videos, and compressed sensing (CS). Differences were assessed in simulations (N=104 datasets) in terms of MSE, PSNR, and SSIM and prospectively for cardiac (short axis, four chambers, N=20) and speech (N=10) data in terms of subjective image quality ranking, SNR and Edge sharpness. Friedman Chi Square tests with post-hoc Nemenyi analysis were performed to assess statistical significance. Results: For all simulation metrics, DL networks trained with cardiac data outperformed DL networks trained with natural videos, which outperformed CS (p<0.05). However, in prospective experiments DL reconstructions using both training datasets were ranked similarly (and higher than CS) and presented no statistical differences in SNR and Edge Sharpness for most conditions. Additionally, high SSIM was measured between the DL methods with cardiac data and natural videos (SSIM>0.85). Conclusion: The developed pipeline enabled learning dynamic MR reconstruction from natural videos preserving DL reconstruction advantages such as high quality fast and ultra-fast reconstructions while overcoming some limitations (data scarcity or sharing). The natural video dataset, code and pre-trained networks are made readily available on github. Key Words: real-time; dynamic MRI; deep learning; image reconstruction; machine learning;
Inside the black box: Neural network-based real-time prediction of US recessions
Oct 26, 2023Feedforward neural network (FFN) and two specific types of recurrent neural network, long short-term memory (LSTM) and gated recurrent unit (GRU), are used for modeling US recessions in the period from 1967 to 2021. The estimated models are then employed to conduct real-time predictions of the Great Recession and the Covid-19 recession in US. Their predictive performances are compared to those of the traditional linear models, the logistic regression model both with and without the ridge penalty. The out-of-sample performance suggests the application of LSTM and GRU in the area of recession forecasting, especially for the long-term forecasting tasks. They outperform other types of models across 5 forecasting horizons with respect to different types of statistical performance metrics. Shapley additive explanations (SHAP) method is applied to the fitted GRUs across different forecasting horizons to gain insight into the feature importance. The evaluation of predictor importance differs between the GRU and ridge logistic regression models, as reflected in the variable order determined by SHAP values. When considering the top 5 predictors, key indicators such as the S\&P 500 index, real GDP, and private residential fixed investment consistently appear for short-term forecasts (up to 3 months). In contrast, for longer-term predictions (6 months or more), the term spread and producer price index become more prominent. These findings are supported by both local interpretable model-agnostic explanations (LIME) and marginal effects.