 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
High-Resolution Maps of Left Atrial Displacements and Strains Estimated with 3D CINE MRI and Unsupervised Neural Networks
Dec 14, 2023
The functional analysis of the left atrium (LA) is important for evaluating cardiac health and understanding diseases like atrial fibrillation. Cine MRI is ideally placed for the detailed 3D characterisation of LA motion and deformation, but it is lacking appropriate acquisition and analysis tools. In this paper, we present Analysis for Left Atrial Displacements and Deformations using unsupervIsed neural Networks, \textit{Aladdin}, to automatically and reliably characterise regional LA deformations from high-resolution 3D Cine MRI. The tool includes: an online few-shot segmentation network (Aladdin-S), an online unsupervised image registration network (Aladdin-R), and a strain calculations pipeline tailored to the LA. We create maps of LA Displacement Vector Field (DVF) magnitude and LA principal strain values from images of 10 healthy volunteers and 8 patients with cardiovascular disease (CVD). We additionally create an atlas of these biomarkers using the data from the healthy volunteers. Aladdin is able to accurately track the LA wall across the cardiac cycle and characterize its motion and deformation. The overall DVF magnitude and principal strain values are significantly higher in the healthy group vs CVD patients: $2.85 \pm 1.59~mm$ and $0.09 \pm 0.05$ vs $1.96 \pm 0.74~mm$ and $0.03 \pm 0.04$, respectively. The time course of these metrics is also different in the two groups, with a more marked active contraction phase observed in the healthy cohort. Finally, utilizing the LA atlas allows us to identify regional deviations from the population distribution that may indicate focal tissue abnormalities. The proposed tool for the quantification of novel regional LA deformation biomarkers should have important clinical applications. The source code, anonymized images, generated maps and atlas are publicly available: https://github.com/cgalaz01/aladdin_cmr_la.
Twitter Permeability to financial events: an experiment towards a model for sensing irregularities
Dec 14, 2023There is a general consensus of the good sensing and novelty characteristics of Twitter as an information media for the complex financial market. This paper investigates the permeability of Twittersphere, the total universe of Twitter users and their habits, towards relevant events in the financial market. Analysis shows that a general purpose social media is permeable to financial-specific events and establishes Twitter as a relevant feeder for taking decisions regarding the financial market and event fraudulent activities in that market. However, the provenance of contributions, their different levels of credibility and quality and even the purpose or intention behind them should to be considered and carefully contemplated if Twitter is used as a single source for decision taking. With the overall aim of this research, to deploy an architecture for real-time monitoring of irregularities in the financial market, this paper conducts a series of experiments on the level of permeability and the permeable features of Twitter in the event of one of these irregularities. To be precise, Twitter data is collected concerning an event comprising of a specific financial action on the 27th January 2017:{~ }the announcement about the merge of two companies Tesco PLC and Booker Group PLC, listed in the main market of the London Stock Exchange (LSE), to create the UK's Leading Food Business. The experiment attempts to answer five key research questions which aim to characterize the features of Twitter permeability to the financial market. The experimental results confirm that a far-impacting financial event, such as the merger considered, caused apparent disturbances in all the features considered, that is, information volume, content and sentiment as well as geographical provenance. Analysis shows that despite, Twitter not being a specific financial forum, it is permeable to financial events.
SAMSGL: Series-Aligned Multi-Scale Graph Learning for Spatio-Temporal Forecasting
Dec 05, 2023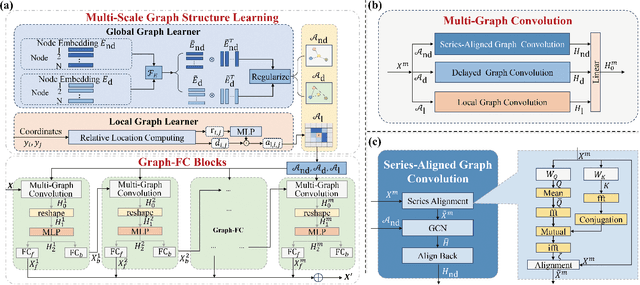

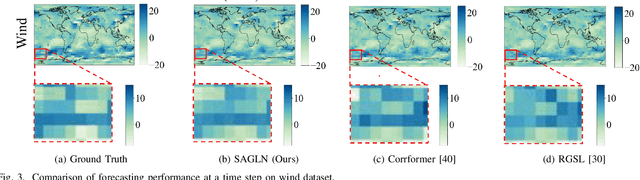
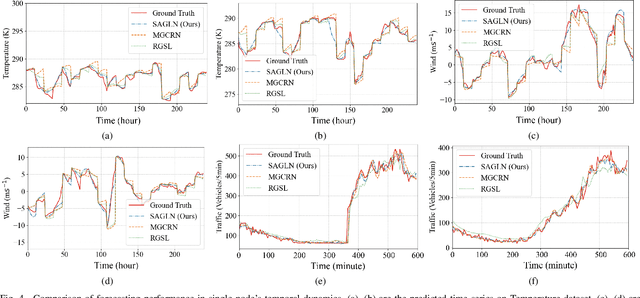
Spatio-temporal forecasting in various domains, like traffic prediction and weather forecasting, is a challenging endeavor, primarily due to the difficulties in modeling propagation dynamics and capturing high-dimensional interactions among nodes. Despite the significant strides made by graph-based networks in spatio-temporal forecasting, there remain two pivotal factors closely related to forecasting performance that need further consideration: time delays in propagation dynamics and multi-scale high-dimensional interactions. In this work, we present a Series-Aligned Multi-Scale Graph Learning (SAMSGL) framework, aiming to enhance forecasting performance. In order to handle time delays in spatial interactions, we propose a series-aligned graph convolution layer to facilitate the aggregation of non-delayed graph signals, thereby mitigating the influence of time delays for the improvement in accuracy. To understand global and local spatio-temporal interactions, we develop a spatio-temporal architecture via multi-scale graph learning, which encompasses two essential components: multi-scale graph structure learning and graph-fully connected (Graph-FC) blocks. The multi-scale graph structure learning includes a global graph structure to learn both delayed and non-delayed node embeddings, as well as a local one to learn node variations influenced by neighboring factors. The Graph-FC blocks synergistically fuse spatial and temporal information to boost prediction accuracy. To evaluate the performance of SAMSGL, we conduct experiments on meteorological and traffic forecasting datasets, which demonstrate its effectiveness and superiority.
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing
Dec 10, 2023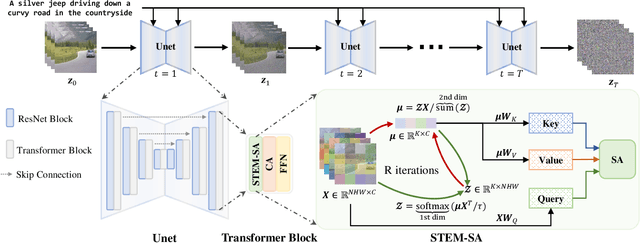
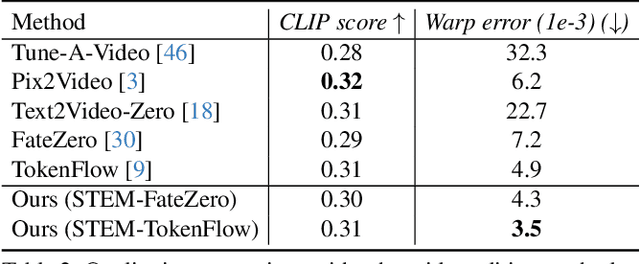


This paper presents a video inversion approach for zero-shot video editing, which aims to model the input video with low-rank representation during the inversion process. The existing video editing methods usually apply the typical 2D DDIM inversion or na\"ive spatial-temporal DDIM inversion before editing, which leverages time-varying representation for each frame to derive noisy latent. Unlike most existing approaches, we propose a Spatial-Temporal Expectation-Maximization (STEM) inversion, which formulates the dense video feature under an expectation-maximization manner and iteratively estimates a more compact basis set to represent the whole video. Each frame applies the fixed and global representation for inversion, which is more friendly for temporal consistency during reconstruction and editing. Extensive qualitative and quantitative experiments demonstrate that our STEM inversion can achieve consistent improvement on two state-of-the-art video editing methods.
Rapid detection of rare events from in situ X-ray diffraction data using machine learning
Dec 07, 2023High-energy X-ray diffraction methods can non-destructively map the 3D microstructure and associated attributes of metallic polycrystalline engineering materials in their bulk form. These methods are often combined with external stimuli such as thermo-mechanical loading to take snapshots over time of the evolving microstructure and attributes. However, the extreme data volumes and the high costs of traditional data acquisition and reduction approaches pose a barrier to quickly extracting actionable insights and improving the temporal resolution of these snapshots. Here we present a fully automated technique capable of rapidly detecting the onset of plasticity in high-energy X-ray microscopy data. Our technique is computationally faster by at least 50 times than the traditional approaches and works for data sets that are up to 9 times sparser than a full data set. This new technique leverages self-supervised image representation learning and clustering to transform massive data into compact, semantic-rich representations of visually salient characteristics (e.g., peak shapes). These characteristics can be a rapid indicator of anomalous events such as changes in diffraction peak shapes. We anticipate that this technique will provide just-in-time actionable information to drive smarter experiments that effectively deploy multi-modal X-ray diffraction methods that span many decades of length scales.
Inversion-Free Image Editing with Natural Language
Dec 07, 2023Despite recent advances in inversion-based editing, text-guided image manipulation remains challenging for diffusion models. The primary bottlenecks include 1) the time-consuming nature of the inversion process; 2) the struggle to balance consistency with accuracy; 3) the lack of compatibility with efficient consistency sampling methods used in consistency models. To address the above issues, we start by asking ourselves if the inversion process can be eliminated for editing. We show that when the initial sample is known, a special variance schedule reduces the denoising step to the same form as the multi-step consistency sampling. We name this Denoising Diffusion Consistent Model (DDCM), and note that it implies a virtual inversion strategy without explicit inversion in sampling. We further unify the attention control mechanisms in a tuning-free framework for text-guided editing. Combining them, we present inversion-free editing (InfEdit), which allows for consistent and faithful editing for both rigid and non-rigid semantic changes, catering to intricate modifications without compromising on the image's integrity and explicit inversion. Through extensive experiments, InfEdit shows strong performance in various editing tasks and also maintains a seamless workflow (less than 3 seconds on one single A40), demonstrating the potential for real-time applications. Project Page: https://sled-group.github.io/InfEdit/
Evaluation of Active Feature Acquisition Methods for Static Feature Settings
Dec 07, 2023Active feature acquisition (AFA) agents, crucial in domains like healthcare where acquiring features is often costly or harmful, determine the optimal set of features for a subsequent classification task. As deploying an AFA agent introduces a shift in missingness distribution, it's vital to assess its expected performance at deployment using retrospective data. In a companion paper, we introduce a semi-offline reinforcement learning (RL) framework for active feature acquisition performance evaluation (AFAPE) where features are assumed to be time-dependent. Here, we study and extend the AFAPE problem to cover static feature settings, where features are time-invariant, and hence provide more flexibility to the AFA agents in deciding the order of the acquisitions. In this static feature setting, we derive and adapt new inverse probability weighting (IPW), direct method (DM), and double reinforcement learning (DRL) estimators within the semi-offline RL framework. These estimators can be applied when the missingness in the retrospective dataset follows a missing-at-random (MAR) pattern. They also can be applied to missing-not-at-random (MNAR) patterns in conjunction with appropriate existing missing data techniques. We illustrate the improved data efficiency offered by the semi-offline RL estimators in synthetic and real-world data experiments under synthetic MAR and MNAR missingness.
k-Parameter Approach for False In-Season Anomaly Suppression in Daily Time Series Anomaly Detection
Nov 10, 2023Detecting anomalies in a daily time series with a weekly pattern is a common task with a wide range of applications. A typical way of performing the task is by using decomposition method. However, the method often generates false positive results where a data point falls within its weekly range but is just off from its weekday position. We refer to this type of anomalies as "in-season anomalies", and propose a k-parameter approach to address the issue. The approach provides configurable extra tolerance for in-season anomalies to suppress misleading alerts while preserving real positives. It yields favorable result.
XCube ($\mathcal{X}^3$): Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
Dec 06, 2023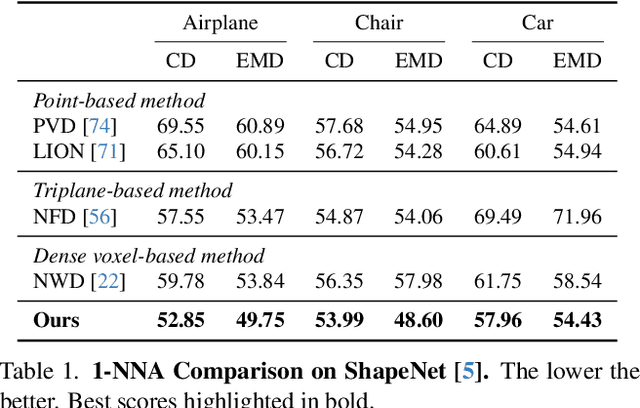
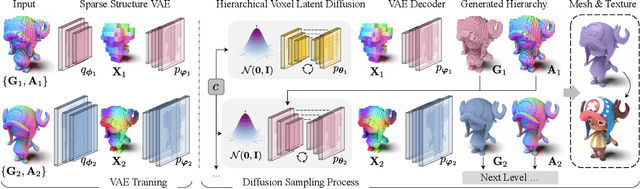

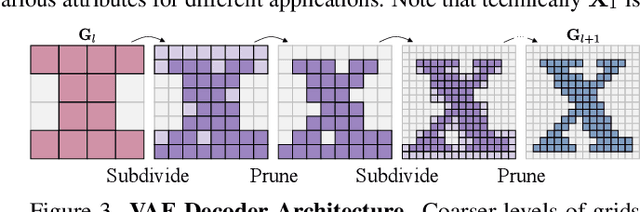
We present $\mathcal{X}^3$ (pronounced XCube), a novel generative model for high-resolution sparse 3D voxel grids with arbitrary attributes. Our model can generate millions of voxels with a finest effective resolution of up to $1024^3$ in a feed-forward fashion without time-consuming test-time optimization. To achieve this, we employ a hierarchical voxel latent diffusion model which generates progressively higher resolution grids in a coarse-to-fine manner using a custom framework built on the highly efficient VDB data structure. Apart from generating high-resolution objects, we demonstrate the effectiveness of XCube on large outdoor scenes at scales of 100m$\times$100m with a voxel size as small as 10cm. We observe clear qualitative and quantitative improvements over past approaches. In addition to unconditional generation, we show that our model can be used to solve a variety of tasks such as user-guided editing, scene completion from a single scan, and text-to-3D. More results and details can be found at https://research.nvidia.com/labs/toronto-ai/xcube/.
NearbyPatchCL: Leveraging Nearby Patches for Self-Supervised Patch-Level Multi-Class Classification in Whole-Slide Images
Dec 12, 2023Whole-slide image (WSI) analysis plays a crucial role in cancer diagnosis and treatment. In addressing the demands of this critical task, self-supervised learning (SSL) methods have emerged as a valuable resource, leveraging their efficiency in circumventing the need for a large number of annotations, which can be both costly and time-consuming to deploy supervised methods. Nevertheless, patch-wise representation may exhibit instability in performance, primarily due to class imbalances stemming from patch selection within WSIs. In this paper, we introduce Nearby Patch Contrastive Learning (NearbyPatchCL), a novel self-supervised learning method that leverages nearby patches as positive samples and a decoupled contrastive loss for robust representation learning. Our method demonstrates a tangible enhancement in performance for downstream tasks involving patch-level multi-class classification. Additionally, we curate a new dataset derived from WSIs sourced from the Canine Cutaneous Cancer Histology, thus establishing a benchmark for the rigorous evaluation of patch-level multi-class classification methodologies. Intensive experiments show that our method significantly outperforms the supervised baseline and state-of-the-art SSL methods with top-1 classification accuracy of 87.56%. Our method also achieves comparable results while utilizing a mere 1% of labeled data, a stark contrast to the 100% labeled data requirement of other approaches. Source code: https://github.com/nvtien457/NearbyPatchCL